L'espace du monde environnant est rempli d'événements individuels et de leurs chaînes - ces événements se reflètent dans les médias, dans les récits des blogueurs et des gens ordinaires sur les réseaux sociaux. Une image de la réalité environnante, revendiquant un certain degré d'objectivité, ne peut être obtenue que si l'on recueille différents points de vue sur le même problème. Le catégoriseur d'événements est l'outil qui «recueille» les informations collectées: versions de la description des événements. Ensuite, donnez accès aux informations sur les événements aux utilisateurs grâce à des outils de recherche, des recommandations et des représentations visuelles des séquences temporelles des événements.
Aujourd'hui, nous parlerons de notre système, plus précisément de son cœur de logiciel, sous le nom de code "Varya" - en l'honneur du développeur principal.
Nous ne pouvons pas encore mentionner le nom de notre startup, à la demande de l'administration Habrahabr, nous avons maintenant déposé une candidature pour nous attribuer le statut de Startup. Cependant, nous pouvons vous parler de la fonctionnalité et de nos idées maintenant. Notre système garantit la pertinence des informations sur les événements pour l'utilisateur et la gestion des données compétente - dans le système, chaque utilisateur détermine lui-même les éléments à regarder et à lire, contrôle la recherche et les recommandations.
Notre projet est une startup avec une équipe de 8 personnes avec des compétences dans la conception de systèmes techniquement et algorithmiquement complexes, la programmation, le marketing et la gestion.
Ensemble, chaque jour, l'équipe travaille sur le projet - des algorithmes de catégorisation, de recherche et de présentation des informations ont déjà été mis en œuvre. La mise en œuvre d'algorithmes liés aux recommandations pour l'utilisateur est toujours en avance: basée sur la relation des événements, des personnes et l'analyse de l'activité et des intérêts de l'utilisateur.
Quelles tâches résolvons-nous et pourquoi en parlons-nous? Nous aidons les gens à obtenir des informations détaillées sur les événements de toute envergure, peu importe où et quand ils se sont produits.
Le projet offre aux utilisateurs une plate-forme pour discuter des événements dans un cercle de personnes partageant les mêmes idées, vous permet de partager un commentaire ou votre propre version de ce qui s'est passé. La plateforme de médias sociaux a été créée pour ceux qui veulent connaître «au-dessus de la moyenne» et avoir une opinion personnelle sur les principaux événements du passé, du présent et du futur.
Les utilisateurs eux-mêmes trouvent et créent du contenu utile dans l'espace multimédia et surveillent sa fiabilité. Nous gardons un souvenir des événements de leur vie.
Maintenant que le projet est au stade MVP, nous testons des hypothèses sur la fonctionnalité et le travail du catégoriseur afin de déterminer la bonne direction pour un développement ultérieur. Dans cet article, nous parlerons des technologies avec lesquelles nous résolvons nos tâches et partageons nos meilleures pratiques.
La tâche du traitement de texte machine est résolue par les moteurs de recherche: Yandex, Google, Bing, etc. Un système idéal pour travailler avec les flux d'informations et en isoler les événements pourrait ressembler à ceci.
Une infrastructure similaire à Yandex et Google est construite pour le système, tout Internet est analysé en temps réel pour les mises à jour, puis les noyaux d'événements se distinguent dans le flux d'informations, autour duquel se forment les agglomérations de leurs versions et du contenu associé. L'implémentation logicielle du service est basée sur un réseau neuronal d'apprentissage profond et / ou une solution basée sur la bibliothèque Yandex - CatBoost.
Cool Cependant, nous n'avons pas encore un tel volume de données, et il n'y a pas de ressources informatiques correspondantes pour l'assimilation.
La classification par sujet est une tâche populaire, il existe de nombreux algorithmes pour sa solution: classificateurs Bayes naïfs, placement Dirichlet latent, boosting sur les arbres de décision et les réseaux de neurones. Comme, probablement, dans tous les problèmes d'apprentissage automatique, lors de l'utilisation des algorithmes décrits, deux problèmes se posent:
Tout d'abord, où obtenir un grand nombre de données?
Deuxièmement, comment les placer à moindre coût et avec colère?
Quelle approche avons-nous choisie pour un système basé sur les événements?
Notre produit fonctionne avec les événements. Les événements sont quelque peu différents des articles réguliers.
Pour surmonter le «démarrage à froid», nous avons décidé d'utiliser deux projets WikiMedia: Wikipedia et Wikinews. Un article de Wikipédia peut décrire plusieurs événements (par exemple, l'histoire du développement de Sun Microsystems, une biographie de Mayakovsky ou le cours de la Grande Guerre patriotique).
Les autres sources d'informations sur les événements sont les flux RSS. Les nouvelles se produisent de différentes manières: les grands articles analytiques contiennent plusieurs événements, comme les textes de Wikipédia, et de courts messages d'information provenant de diverses sources représentent le même événement.
Ainsi, l'article et les événements forment des relations plusieurs à plusieurs. Mais au stade MVP, nous faisons l'hypothèse qu'un article est un événement.
En regardant l'interface de Google ou Yandex, vous pourriez penser que les moteurs de recherche ne recherchent que des mots clés. Ce n'est que pour les détaillants en ligne très simples. La plupart des moteurs de recherche sont multicritères et le moteur de notre projet ne fait pas exception. De plus, loin de tous les paramètres pris en compte lors de la recherche sont affichés dans l'interface utilisateur. Notre projet dispose d'une liste de paramètres que l'utilisateur sélectionne, tels que:
sujets et mots clés -
"quoi?" ; emplacement -
"où?" ; date -
"quand?" ;
Ceux qui écrivent des moteurs de recherche savent que les mots clés à eux seuls causent beaucoup de problèmes. Eh bien, le reste des options n'est pas aussi simple.
Le sujet de l'événement est une chose très difficile. Le cerveau humain est conçu pour qu'il aime tout catégoriser, et le monde réel est fortement en désaccord avec cela. Les articles entrants veulent former leurs propres groupes de sujets, et ce ne sont pas du tout ceux dans lesquels nous et nos utilisateurs enthousiastes les distribuons.
Nous avons maintenant 15 thèmes principaux d'événements, et cette liste a été révisée plusieurs fois et, au minimum, elle s'allongera.
Les lieux et les dates sont arrangés un peu plus formellement, mais ici il y a des pièges.
Nous avons donc un ensemble de critères formalisés et de données brutes que nous devons mapper à ces critères. Et voici comment nous procédons.
Araignée
La tâche de l'araignée est de plier les articles entrants afin qu'ils puissent être rapidement recherchés. Pour ce faire, l'araignée doit être en mesure d'attribuer le sujet, l'emplacement et la date aux articles, ainsi que certains autres paramètres nécessaires au classement. Notre araignée d'entrée reçoit un modèle de texte de l'article construit par le robot. Un modèle de texte est une liste de parties d'un article et de leurs textes correspondants. Par exemple, presque tous les articles ont au moins un titre et un corps de texte. En fait, elle a toujours le premier paragraphe, un ensemble de catégories auxquelles ce texte fait référence à sa source, et une liste de champs de boîte d'informations (pour Wikipedia et les sources qui ont de telles balises de métadonnées). Il y a encore une date de publication. Pour le classement dans un moteur de recherche, il sera important pour nous de savoir si, par exemple, une date se trouve dans l'en-tête ou quelque part à la fin du texte. Un modèle de texte est utilisé pour créer un modèle de rubrique, un modèle d'emplacement et un modèle de date, puis le résultat est ajouté à l'index. Un article séparé peut être écrit sur chacun de ces modèles, donc ici nous ne décrirons que brièvement les approches.
Thème
Déterminer le sujet des documents est une tâche courante. Les sujets peuvent être attribués manuellement par l'auteur du document ou déterminés automatiquement. Bien sûr, nous avons des sujets que les sources d'informations et Wikipedia ont attribués à nos documents, mais ces sujets ne concernent pas les événements. Trouvez-vous souvent le sujet «Vacances» dans les fils de nouvelles? Vous rencontrerez plutôt le thème de la «société». Nous l'avons également eu dans l'une des premières éditions. Nous n'avons pas pu déterminer ce qui devait s'y rapporter et nous avons été contraints de le supprimer. Et en plus, toutes les sources ont leur propre ensemble de sujets.
Nous voulons gérer la liste des sujets qui sont affichés à nos utilisateurs dans l'interface, donc pour nous la tâche de déterminer le sujet du document est la tâche de classification floue. La tâche de classification nécessite des exemples étiquetés, c'est-à-dire une liste de documents auxquels nos sujets souhaités ont déjà été attribués. Notre liste est similaire à toutes les listes de sujets similaires, mais ne coïncide pas avec eux, nous n'avions donc pas d'échantillon étiqueté. Vous pouvez également l'obtenir manuellement ou automatiquement, mais si notre liste de sujets change (et ce sera le cas!), Alors manuellement n'est pas une option.
Si vous n'avez pas d'échantillon étiqueté, vous pouvez utiliser le placement de Dirichlet latent et d'autres algorithmes de modélisation thématique, cependant, l'ensemble de ceux que vous obtiendrez sera celui qui s'est avéré, et non celui que vous vouliez.
Ici, nous devons mentionner un autre point: nos articles proviennent de différentes sources. Tous les modèles thématiques sont construits d'une manière ou d'une autre sur le vocabulaire utilisé. Pour les actualités et Wikipédia, ce sont des fréquences hautes différentes, voire tamisées.
Ainsi, nous avons été confrontés à deux tâches:
1. Trouvez un moyen de disposer rapidement nos documents en mode semi-automatique.
2. Construisez un modèle extensible de nos sujets basé sur ces documents.
Pour les résoudre, nous avons créé un algorithme hybride contenant les étapes automatisées et manuelles illustrées sur la figure.
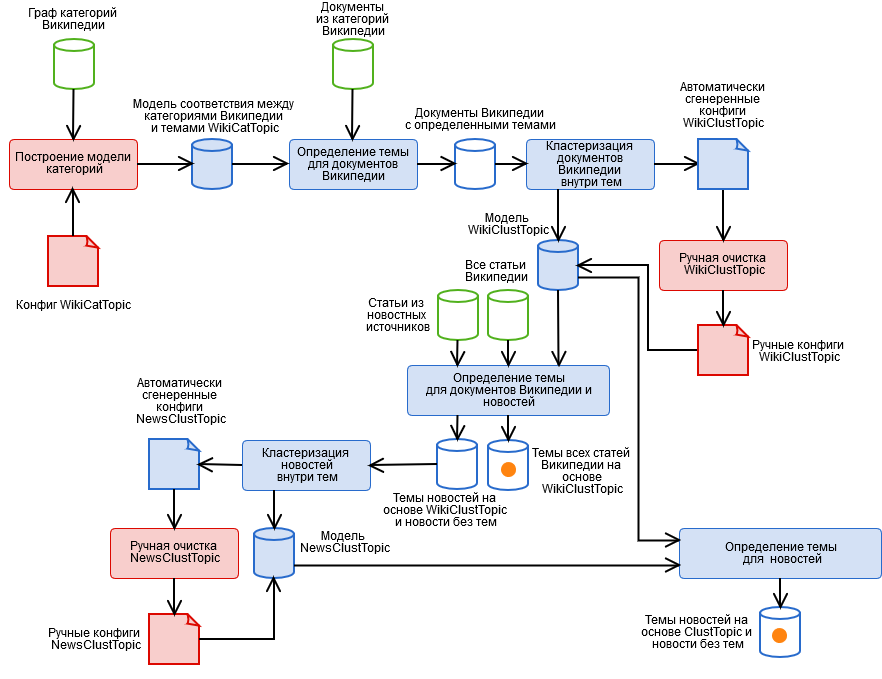
- Balisage manuel des catégories Wikipédia et obtention d'un modèle de thème catégoriel WikiCatTopic. À ce stade, une configuration est construite qui attribue un sous-graphique des catégories WT de Wikipedia à chacun de nos sujets T. Wikipédia est une pseudo-ontologie. Cela signifie que si quelque chose tombe dans la catégorie «Science», il ne s'agit peut-être pas du tout de science, par exemple, de la sous-catégorie inoffensive «Technologies de l'information», vous pouvez réellement consulter n'importe quel article de Wikipédia. Un article séparé est nécessaire sur la façon de vivre avec cela.
- Détectez automatiquement les sujets des documents Wikipédia basés sur WikiCatTopic. Le document se voit attribuer le thème T s'il appartient à l'une des catégories du graphe CT. Notez que cette méthode s'applique uniquement aux articles Wikipedia. Pour généraliser la définition des sujets à du texte arbitraire, il a été possible de construire un sac de mots de chaque sujet et de considérer la distance cosinusoïdale par rapport au sujet (et nous avons essayé, rien de bon), mais ici trois choses doivent être prises en compte.
- Ces sujets contiennent des articles très divers, de sorte que l'image du sujet dans l'espace de mots ne sera pas cohérente, ce qui signifie que la «confiance» d'un tel modèle pour déterminer le sujet est très faible (après tout, l'article est similaire à un petit ensemble d'articles, mais pas au reste).
- Un texte arbitraire, principalement des nouvelles, diffère dans sa composition lexicale de Wikipédia, ce qui n'ajoute pas non plus un modèle de «certitude». De plus, certains sujets ne peuvent pas être créés sur Wikipédia.
- L'étape 1 est un travail très laborieux et tout le monde est trop paresseux pour le faire.
- Regroupement de documents dans des rubriques sur la base des résultats du paragraphe 2 à l'aide de la méthode k-means et obtention d'un modèle de cluster du thème WikiClustTopic. Un mouvement assez simple, qui nous a permis de résoudre en grande partie deux des trois problèmes du paragraphe 2. Pour les clusters, nous construisons un sac de mots, et appartenir à un sujet est défini comme le maximum des distances cosinus à ses clusters. Le modèle est décrit dans nos fichiers de configuration de correspondance entre clusters et documents Wikipedia.
- Nettoyage manuel du modèle WikiClustTopic, activer-désactiver-transférer des clusters. Ici, nous sommes également revenus à l'étape 1, lorsque des clusters complètement incorrects ont été découverts.
- Détectez automatiquement les sujets WikiClustTopic pour les documents et actualités Wikipédia.
- Regroupement des actualités dans les rubriques sur la base des résultats du paragraphe 5 à l'aide de la méthode k-means, ainsi que des actualités qui n'ont pas reçu de rubriques, et obtention d'un modèle de grappe de la rubrique NewsClustTopic. Nous avons maintenant un modèle de thème qui prend en compte les spécificités de l'actualité (ainsi que des informations précieuses sur la qualité du travail du robot).
- Nettoyage manuel du modèle NewsClustTopic.
- Remappage des sujets d'actualité basés sur le modèle intégré ClustTopic = WikiClustTopic + NewsClustTopic. Sur la base de ce modèle, les thèmes des nouveaux documents sont déterminés.
Emplacements
La détermination automatique de l'emplacement est un cas particulier de la tâche de recherche d'entités nommées. Les caractéristiques des emplacements sont les suivantes:
- Toutes les listes d'emplacements sont différentes et ne s'emboîtent pas bien. Nous avons construit notre propre, hybride, qui prend en compte non seulement la hiérarchie (la Russie comprend la région de Novossibirsk), mais aussi les changements de nom historiques (par exemple, le RSFSR est devenu la Russie) en fonction de: Geonames, Wikidata et d'autres sources ouvertes. Cependant, nous devions encore écrire un convertisseur de géolocalisation avec Google Maps :)
- Certains emplacements se composent de plusieurs mots, par exemple, Nizhny Novgorod, et vous devez pouvoir les collecter.
- Les lieux sont similaires à d'autres mots, en particulier les noms de ceux en l'honneur desquels ils sont nommés: Kirov, Zhukov, Vladimir. C'est l'homonymie. Pour remédier à cela, nous avons collecté des statistiques sur des articles de Wikipédia décrivant les colonies, dans quels contextes les noms des emplacements sont trouvés, et avons également essayé de construire une liste de ces homonymes à l'aide des dictionnaires Open Corpora.
- L'humanité n'a pas mis à rude épreuve l'imagination et de nombreux endroits portent le même nom. Notre exemple préféré: Karasuk au Kazakhstan et en Russie, près de Novossibirsk. Il s'agit d'homonymie au sein de la classe d'emplacements. Nous le résolvons, en considérant quels autres emplacements se trouvent avec celui-ci, et s'ils sont parents ou enfants pour l'un des homonymes. Cette heuristique n'est pas universelle, mais elle fonctionne bien.
Les dates
Dates - l'incarnation de la formalité par rapport aux thèmes et lieux. Nous avons fait un analyseur extensible pour eux sur les expressions régulières, et nous pouvons analyser non seulement le jour, le mois et l'année, mais aussi toutes sortes de choses plus intéressantes, comme «la fin de l'hiver 1941», «dans les années 90 du XIXe siècle» et «le mois dernier». », En tenant compte de l'ère et de la date de base du document, ainsi qu'en essayant de restaurer l'année manquante. À propos des dates, vous devez savoir que toutes ne sont pas bonnes. Par exemple, à la fin d'un article sur une bataille de la Seconde Guerre mondiale, il peut y avoir une ouverture du mémorial quarante ans plus tard, pour traiter de tels cas, vous devez couper l'article en événements, mais nous ne le faisons pas encore. Nous ne considérons donc que les dates les plus importantes: du titre et des premiers paragraphes.
Moteur de recherche
Le moteur de recherche est un gadget qui, d'une part, recherche les documents sur demande, et d'autre part, les organise par ordre décroissant de pertinence pour la requête, c'est-à-dire par pertinence décroissante. Pour calculer la pertinence, nous utilisons de nombreux paramètres, bien plus qu'une simple trivialité:
Degré auquel le document appartient au sujet.
Le degré de propriété du document de localisation (combien de fois et dans quelles parties du document se trouve l'emplacement sélectionné).
Le degré auquel le document correspond à la date (prend en compte le nombre de jours à l'intersection de l'intervalle de la demande et les dates du document, ainsi que le nombre de jours à l'intersection moins l'union).
La longueur du document. Les articles longs devraient être plus élevés.
La présence de l'image. Tout le monde aime les photos, il devrait y en avoir plus!
Type d'article Wikipedia. Nous pouvons séparer les articles avec des descriptions des événements, et ils devraient «apparaître» dans l'échantillon.
Source de l'article. Les actualités et les articles personnalisés devraient être supérieurs à Wikipedia.
En tant que moteur de recherche, nous utilisons Apache Lucene.
Crawler
La tâche du robot est de collecter des articles pour l'araignée. Dans notre cas, nous incluons ici également le nettoyage primaire du texte et la construction d'un modèle de texte du document. Crawler mérite un article séparé.
PS Nous apprécions tout commentaire, nous vous invitons à tester notre projet - pour recevoir un lien, écrire des messages personnels (nous ne pouvons pas publier ici). Laissez vos commentaires sous l'article, ou si vous accédez à notre service - juste là, via le formulaire de commentaires.