Lorsque les internautes recherchent une image ou une vidéo sur Internet, ils ajoutent souvent l'expression «de bonne qualité». La qualité se réfère généralement à la résolution - les utilisateurs veulent que l'image soit grande et en même temps belle sur l'écran d'un ordinateur, d'un smartphone ou d'un téléviseur moderne. Mais que faire si la source de bonne qualité n'existe tout simplement pas?
Aujourd'hui, nous expliquerons aux lecteurs de Habr comment, grâce à des réseaux de neurones, nous pouvons augmenter la résolution de la vidéo en temps réel. Vous apprendrez également en quoi l'approche théorique pour résoudre ce problème diffère de l'approche pratique. Si vous n'êtes pas intéressé par les détails techniques, vous pouvez faire défiler le message en toute sécurité - à la fin, vous trouverez des exemples de notre travail.

Il y a beaucoup de contenu vidéo sur Internet en basse qualité et résolution. Il peut s'agir de films tournés il y a des décennies ou de chaînes de télévision diffusées qui, pour diverses raisons, ne sont pas de la meilleure qualité. Lorsque les utilisateurs étendent une telle vidéo en plein écran, l'image devient trouble et floue. Une solution idéale pour les vieux films serait de trouver le film original, de le numériser avec un équipement moderne et de le restaurer manuellement, mais ce n'est pas toujours possible. Les émissions sont encore plus compliquées - elles doivent être traitées en direct. À cet égard, l'option la plus acceptable pour nous de travailler est d'augmenter la résolution et de nettoyer les artefacts en utilisant la technologie de vision par ordinateur.
Dans l'industrie, la tâche d'augmenter les images et les vidéos sans perte de qualité est appelée le terme super-résolution. De nombreux articles ont déjà été écrits sur ce sujet, mais les réalités de l'application «combat» se sont avérées beaucoup plus compliquées et intéressantes. En bref sur les principaux problèmes que nous avons dû résoudre dans notre propre technologie DeepHD:
- Vous devez pouvoir restaurer des détails qui n'étaient pas sur la vidéo d'origine en raison de sa faible résolution et de sa qualité, pour les «terminer».
- Les solutions de la zone de super-résolution restaurent les détails, mais elles rendent clairs et détaillés non seulement les objets de la vidéo, mais aussi les artefacts de compression, ce qui provoque une aversion pour le public.
- Il y a un problème avec la collecte de l'échantillon d'apprentissage - un grand nombre de paires sont nécessaires dans lesquelles la même vidéo est présente à la fois en basse résolution et en qualité, et en haute. En réalité, il n'y a généralement pas de paire de qualité pour un contenu médiocre.
- La solution devrait fonctionner en temps réel.
Sélection de technologies
Au cours des dernières années, l'utilisation des réseaux de neurones a conduit à un succès significatif dans la résolution de presque toutes les tâches de vision par ordinateur, et la tâche de super-résolution ne fait pas exception. Nous avons trouvé les solutions les plus prometteuses basées sur les GAN (Generative Adversarial Networks, générative rival networks). Ils vous permettent d'obtenir des images photoréalistes haute définition, en les complétant avec les détails manquants, par exemple en dessinant des cheveux et des cils sur les images des personnes.

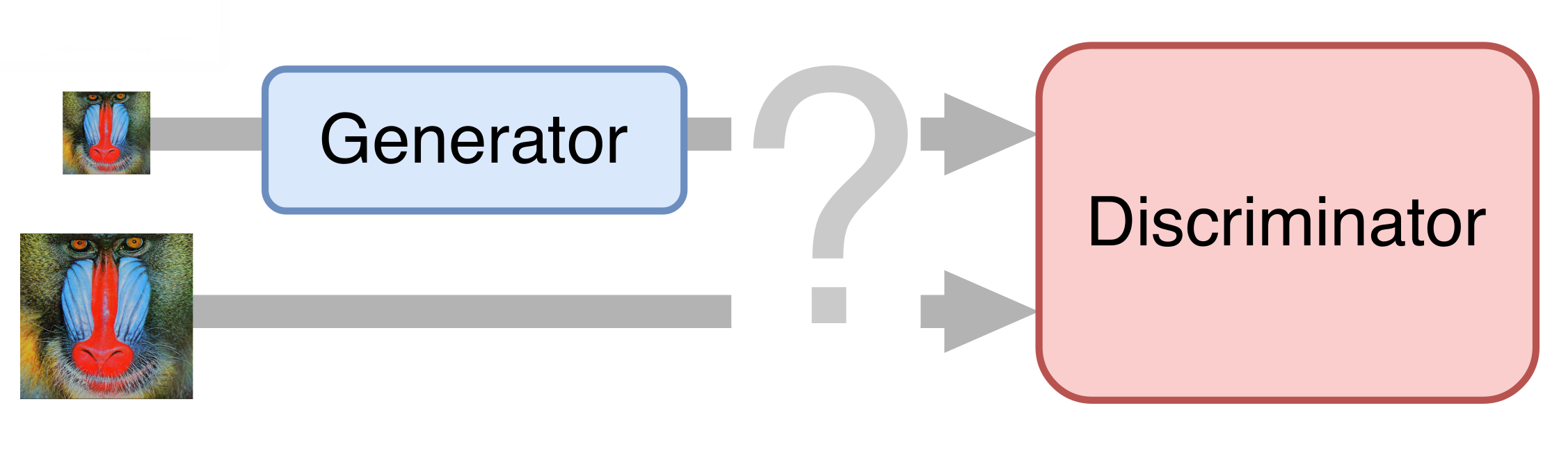
Dans le cas le plus simple, un réseau de neurones se compose de deux parties. La première partie - le générateur - prend une image d'entrée et retourne un grossissement doublé. La deuxième partie - le discriminateur - reçoit l'image générée et «réelle» en entrée, et essaie de la distinguer les unes des autres.
Préparation du set d'entraînement
Pour la formation, nous avons collecté des dizaines de clips en qualité UltraHD. Tout d'abord, nous les avons réduits à une résolution de 1080p, obtenant ainsi des exemples de référence. Ensuite, nous avons réduit de moitié ces vidéos, en les compressant à un débit différent en cours de route pour obtenir quelque chose de similaire à une vraie vidéo de faible qualité. Nous avons divisé les vidéos résultantes en images et les avons utilisées de manière à former le réseau neuronal.
Déblocage
Bien sûr, nous voulions obtenir une solution de bout en bout: former le réseau neuronal à générer une vidéo et une qualité haute résolution directement à partir de l'original. Cependant, les GAN se sont avérés très capricieux et ont constamment essayé d'affiner les artefacts de compression, plutôt que de les éliminer. J'ai donc dû diviser le processus en plusieurs étapes. Le premier est la suppression des artefacts de compression vidéo, également appelés déblocage.
Un exemple d'une des méthodes de publication:

À ce stade, nous avons minimisé l'écart type entre le cadre généré et le cadre d'origine. Ainsi, bien que nous ayons augmenté la résolution de l'image, nous n'avons pas obtenu une réelle augmentation de la résolution en raison de la régression vers la moyenne: le réseau neuronal, ne sachant pas dans quels pixels spécifiques une bordure particulière de l'image passe, a été forcé de faire la moyenne de plusieurs options, obtenant un résultat flou. La principale chose que nous avons réalisée à ce stade est l'élimination des artefacts de compression vidéo, de sorte que le réseau générateur à l'étape suivante n'avait besoin que d'augmenter la clarté et d'ajouter les petits détails manquants, les textures. Après des centaines d'expériences, nous avons sélectionné l'architecture optimale en termes de performances et de qualité, rappelant vaguement l'architecture
DRCN :
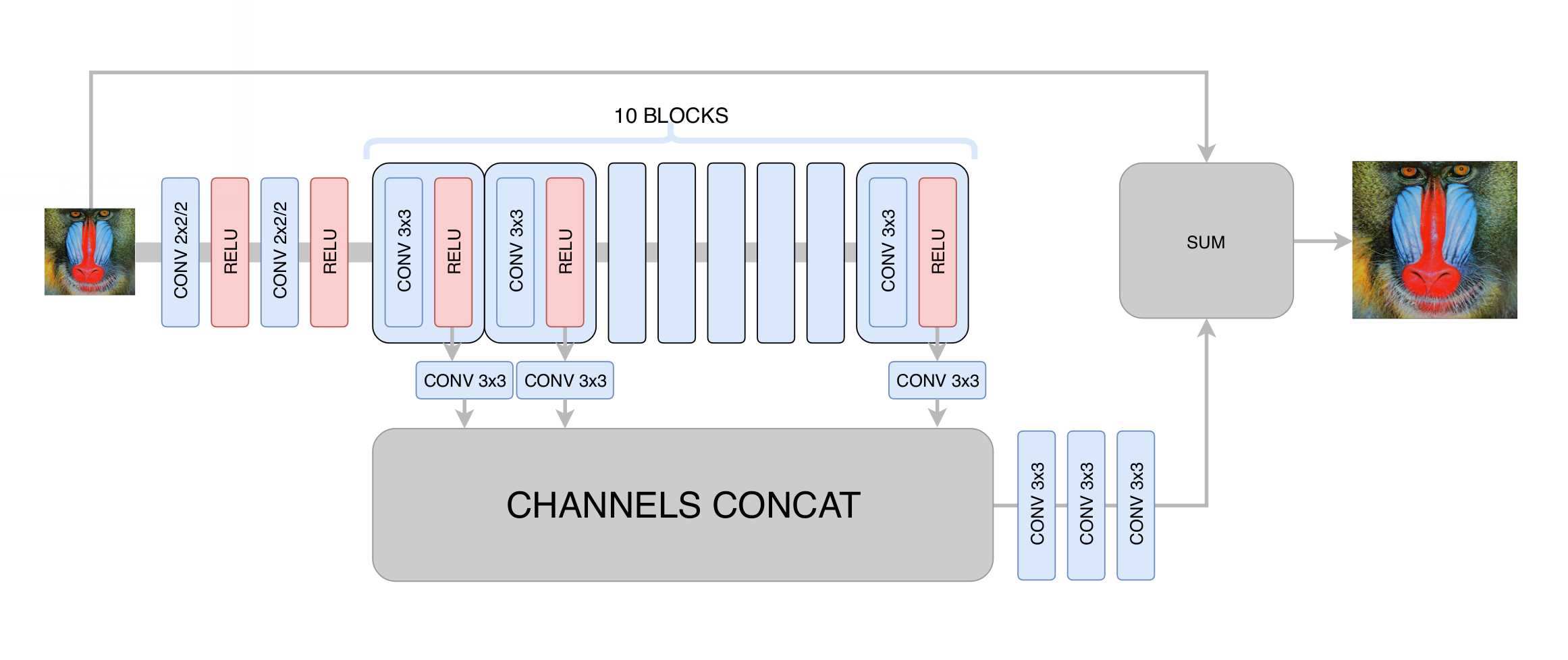
L'idée principale d'une telle architecture est le désir d'obtenir l'architecture la plus profonde, sans avoir de problèmes de convergence dans sa formation. D'une part, chaque couche convolutionnelle suivante extrait des caractéristiques de plus en plus complexes de l'image d'entrée, ce qui vous permet de déterminer quel type d'objet se trouve à un point donné de l'image et de restaurer des parties complexes et gravement endommagées. En revanche, la distance dans le graphe d'un réseau neuronal de n'importe laquelle de ses couches à la sortie reste faible, ce qui améliore la convergence du réseau neuronal et permet d'utiliser un grand nombre de couches.
Formation réseau générative
Nous avons pris l'architecture
SRGAN comme base d'un réseau neuronal pour augmenter la résolution. Avant de former un réseau compétitif, vous devez pré-entraîner le générateur - entraînez-le de la même manière qu'au stade du déblocage. Sinon, au début de la formation, le générateur ne retournera que du bruit, le discriminateur commencera immédiatement à "gagner" - il apprendra facilement à distinguer le bruit des images réelles, et aucune formation ne fonctionnera.

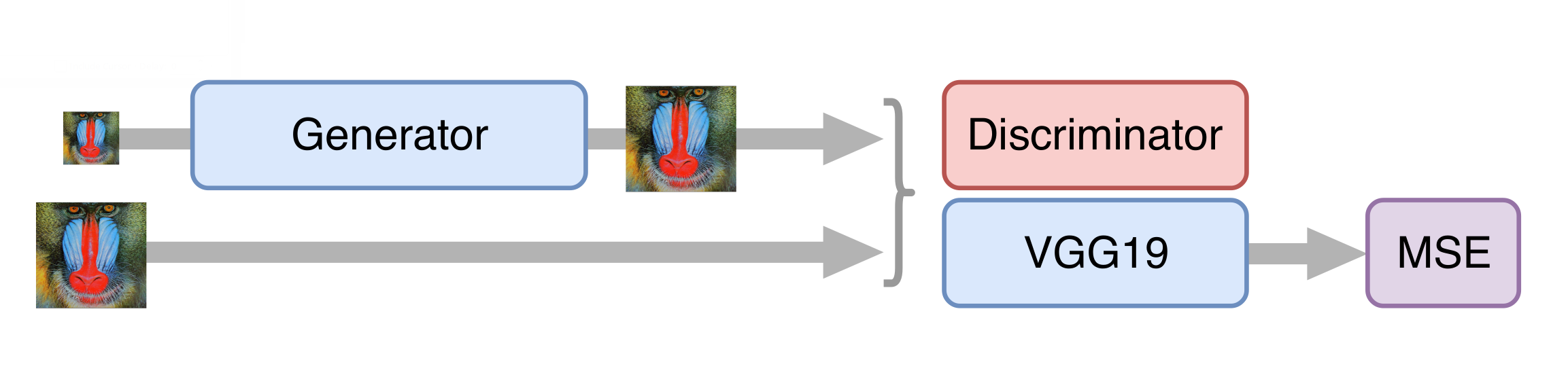
Ensuite, nous formons le GAN, mais il y a quelques nuances. Il est important pour nous que le générateur crée non seulement des images photoréalistes, mais stocke également les informations disponibles à leur sujet. Pour ce faire, nous ajoutons la fonction de perte de contenu à l'architecture GAN classique. Il représente plusieurs couches du réseau neuronal VGG19 entraînées sur l'ensemble de données ImageNet standard. Ces couches transforment l'image en une carte d'entités qui contient des informations sur le contenu de l'image. La fonction de perte minimise la distance entre ces cartes obtenues à partir des trames générées et originales. De plus, la présence d'une telle fonction de perte vous permet de ne pas gâcher le générateur dans les premières étapes de la formation, lorsque le discriminateur n'est pas encore formé et fournit des informations inutiles.
Accélération du réseau neuronal
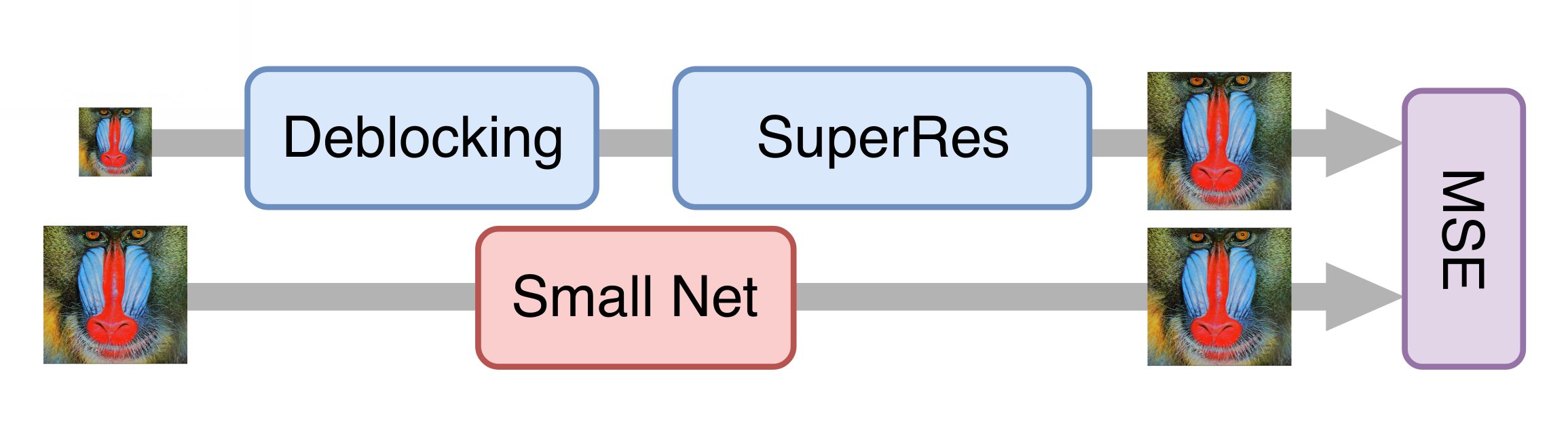
Tout s'est bien passé, et après une série d'expériences, nous avons obtenu un bon modèle qui pouvait déjà être appliqué aux vieux films. Cependant, il était encore trop lent pour traiter la vidéo en streaming. Il s'est avéré qu'il est impossible de simplement réduire le générateur sans perte significative de qualité du modèle final. Puis l'approche de la distillation des connaissances est venue à notre aide. Cette méthode consiste à entraîner un modèle plus léger afin qu'il répète les résultats d'un modèle plus lourd. Nous avons pris beaucoup de vraies vidéos en basse qualité, les avons traitées avec le réseau neuronal génératif obtenu à l'étape précédente et formé le réseau plus léger pour obtenir le même résultat à partir des mêmes images. En raison de cette technique, nous avons obtenu un réseau qui n'est pas très inférieur en qualité à celui d'origine, mais dix fois plus rapide que lui: pour traiter une chaîne de télévision en résolution 576p, une carte NVIDIA Tesla V100 est requise.
Évaluation de la qualité des solutions
Le moment peut-être le plus difficile lorsque l'on travaille avec des réseaux génératifs est l'évaluation de la qualité des modèles résultants. Il n'y a pas de fonction d'erreur claire, comme, par exemple, lors de la résolution du problème de classification. Au lieu de cela, nous ne connaissons que l'exactitude du discriminateur, ce qui ne reflète pas la qualité du générateur qui nous intéresse (un lecteur qui connaît bien ce domaine pourrait suggérer d'utiliser
la métrique Wasserstein , mais, malheureusement, cela a donné un résultat sensiblement pire).
Les gens nous ont aidés à résoudre ce problème. Nous avons montré aux utilisateurs des paires d'images du service
Yandex.Tolok , dont l'une était la source et l'autre traitées par un réseau de neurones, ou les deux ont été traitées par différentes versions de nos solutions. Moyennant un supplément, les utilisateurs ont choisi une meilleure vidéo à partir d'une paire, nous avons donc obtenu une comparaison statistiquement significative des versions, même avec des changements difficiles à voir à l'œil nu. Nos modèles finaux gagnent dans plus de 70% des cas, ce qui est beaucoup, étant donné que les utilisateurs ne passent que quelques secondes à évaluer quelques vidéos.
Un résultat intéressant a également été le fait que la vidéo en résolution 576p, augmentée par la technologie DeepHD à 720p, surpasse la même vidéo originale avec une résolution 720p dans 60% des cas - c'est-à-dire Le traitement augmente non seulement la résolution de la vidéo, mais améliore également sa perception visuelle.
Des exemples
Au printemps, nous avons testé la technologie DeepHD sur plusieurs vieux films qui peuvent être visionnés sur KinoPoisk: «
Rainbow » de Mark Donskoy (1943), «
Cranes are Flying » de Mikhail Kalatozov (1957), «
My Dear Man » de Joseph Kheifits (1958), «
The Fate of a Man » Sergei Bondarchuk (1959), «
Ivan Childhood » d'Andrei Tarkovsky (1962), «
Father of a Soldier » Rezo Chkheidze (1964) et «
Tango of Our Childhood » d'Albert Mkrtchyan (1985).

La différence entre les versions avant et après le traitement est particulièrement visible si vous examinez les détails: étudiez les expressions faciales des héros en gros plan, considérez la texture des vêtements ou un motif de tissu. Il a été possible de compenser certaines des lacunes de la numérisation: par exemple, pour supprimer la surexposition sur les visages ou pour rendre les objets plus visibles placés dans l'ombre.
Plus tard, la technologie DeepHD a commencé à être utilisée pour améliorer la qualité des émissions de
certaines chaînes du service Yandex.Air. La reconnaissance d'un tel contenu est facile grâce à la balise
dHD .
Maintenant
sur Yandex en qualité améliorée, vous pouvez regarder "The Snow Queen", "Bremen Town Musicians", "Golden Antelope" et d'autres dessins animés populaires du studio de cinéma Soyuzmultfilm. Quelques exemples de dynamique peuvent être vus dans la vidéo:
Pour les téléspectateurs exigeants, la différence sera particulièrement visible: l'image est devenue plus nette, les feuilles des arbres, les flocons de neige, les étoiles dans le ciel nocturne sur la jungle et d'autres petits détails sont plus visibles.
Plus c'est plus.
Liens utiles
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee Réseau convolutionnel profondément récursif pour la super-résolution d'images [
arXiv: 1511.04491 ].
Christian Ledig et al. Super-résolution d'image unique photo-réaliste utilisant un réseau
contradictoire génératif [
arXiv: 1609.04802 ].
Mehdi SM Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: super-résolution d'image unique par synthèse de texture automatisée [
arXiv: 1612.07919 ].