Les gens veulent depuis longtemps enseigner à une machine à comprendre une personne. Cependant, ce n'est que maintenant que nous sommes un peu plus près des intrigues des films de science-fiction: nous pouvons demander à Alice de baisser le volume, Google Assistant - commandez un taxi ou Siri - déclenche une alarme. Les technologies de traitement du langage sont recherchées dans les développements liés à la construction de l'intelligence artificielle: dans les moteurs de recherche, pour extraire des faits, évaluer la tonalité du texte, la traduction automatique et le dialogue.
Nous allons parler des deux derniers domaines: ils ont une histoire riche et ont eu un impact significatif sur le traitement de la langue. De plus, nous traiterons des possibilités de base du traitement du langage naturel lors de la création d'un chat bot avec la conférencière de notre cours
AI Weekend, la linguiste informatique Anna Vlasova.
Comment tout a commencé?
Le premier discours sur le traitement du langage naturel avec un ordinateur a commencé dans les années 30 du 20e siècle avec le raisonnement philosophique d'Ayer - il a proposé de distinguer une personne intelligente d'une machine stupide à l'aide d'un test empirique. En 1950, Alan Turing dans la revue philosophique
Mind propose un test où le juge doit déterminer avec qui il parle: une personne ou un ordinateur. En utilisant le test, des critères ont été fixés pour évaluer le travail de l'intelligence artificielle, la possibilité de le construire n'a pas été mise en doute. Le test présente de nombreuses limites et inconvénients, mais il a eu un impact significatif sur le développement des robots de chat.
Le premier domaine où le traitement linguistique a été appliqué avec succès a été la traduction automatique. En 1954, l'Université de Georgetown et IBM ont démontré un programme de traduction automatique du russe vers l'anglais, qui a fonctionné sur la base d'un dictionnaire de 250 mots et d'un ensemble de 6 règles de grammaire. Le programme était loin de ce qu'on pourrait vraiment appeler la traduction automatique et a traduit 49 offres présélectionnées lors d'une démonstration. Jusqu'au milieu des années 60, de nombreuses tentatives ont été faites pour créer un programme de traduction pleinement fonctionnel, mais en 1966, la Commission consultative sur le traitement automatique du langage
(ALPAC) a déclaré que la traduction automatique était une direction futile. Les subventions de l'État ont cessé pendant un certain temps, l'intérêt du public pour la traduction automatique a diminué, mais la recherche ne s'est pas arrêtée là.

Parallèlement aux tentatives d'enseigner à un ordinateur à traduire du texte, des scientifiques et des universités entières ont pensé à créer un robot capable d'imiter le comportement de la parole humaine. La première implémentation réussie du chatbot a été l'interlocuteur virtuel ELIZA, écrit en 1966 par Joseph Weizenbaum. Eliza a parodié le comportement du psychothérapeute, extrayant des mots significatifs de la phrase de l'interlocuteur et posant une contre-question. Nous pouvons supposer que ce fut le premier bot de chat basé sur des règles (bot basé sur des règles), et il a jeté les bases de toute une classe de tels systèmes. Des enquêteurs comme Cleverbot, WeChat Xiaoice, Eugene Goostman - ont officiellement passé le test de Turing en 2014 - et même Siri, Jarvis et Alexa ne seraient pas apparus sans Eliza.
En 1968, Terry Grapes a développé le programme SHRDLU dans LISP. Elle a déplacé des objets simples sur commande: des cônes, des cubes, des boules et pourrait soutenir le contexte - elle a compris quel élément devait être déplacé, si cela était mentionné plus tôt. La prochaine étape dans le développement des robots de discussion a été le programme ALICE, pour lequel Richard Wallace a développé un langage de balisage spécial - AIML
(English Artificial Intelligence Markup Language) . Puis, en 1995, les attentes du chatbot étaient surestimées: ils pensaient qu'ALICE serait encore plus intelligente qu'une personne. Bien sûr, le chatbot n'a pas réussi à être plus intelligent, et pendant un certain temps, l'activité dans les chatbots a été déçue, et les investisseurs ont longtemps ignoré le sujet des assistants virtuels.
Questions linguistiques
Aujourd'hui, les chatbots fonctionnent toujours sur la base d'un ensemble de règles et de scénarios comportementaux, cependant, un langage naturel est flou et ambigu, une pensée peut avoir de nombreuses façons de présenter, par conséquent, le succès commercial des systèmes de dialogue dépend de la résolution des problèmes de traitement du langage. La machine doit apprendre à classer clairement toute la variété des questions entrantes et à les interpréter clairement.
Toutes les langues sont organisées différemment, ce qui est très important pour l'analyse. Du point de vue de la composition morphologique, les éléments significatifs du mot peuvent rejoindre la racine séquentiellement, comme, par exemple, dans les langues turques, ou ils peuvent briser la racine, comme en arabe et en hébreu. Du point de vue de la syntaxe, certaines langues autorisent l'ordre libre des mots dans une phrase, tandis que d'autres sont organisées de manière plus rigide. Dans les systèmes classiques, l'ordre des mots joue un rôle essentiel. Pour les méthodes statistiques modernes de la PNL, il n'a pas une telle valeur, car le traitement ne se produit pas au niveau des mots, mais des phrases entières.
D'autres difficultés dans le développement des chat bots surviennent en lien avec le développement de la communication multilingue. Maintenant, les gens ne communiquent souvent pas dans leur langue maternelle, ils utilisent des mots de manière incorrecte. Par exemple, dans la phrase «J'ai expédié il y a deux jours, mais les marchandises ne sont pas venues», du point de vue du vocabulaire, nous devrions parler de la livraison d'objets physiques, par exemple des marchandises, et non de la transaction de monnaie électronique, qui est décrite par ces mots par une personne qui ne parle pas. dans la langue maternelle. Mais dans une vraie communication, une personne comprendra correctement l'interlocuteur et le bot de chat peut avoir des problèmes. Dans certains sujets, tels que les investissements, la banque ou l'informatique, les gens passent souvent à d'autres langues. Mais le chatbot est peu susceptible de comprendre ce qui est en jeu, car il est très probablement formé dans une langue.
Histoire de réussite: traducteurs automatiques
Avant l'avènement des assistants vocaux et la diffusion généralisée des chatbots, la traduction automatique était la tâche intellectuelle la plus demandée, qui nécessitait le traitement d'un langage naturel. Les discussions sur les réseaux de neurones et l'apprentissage profond remontent aux années 90, et le premier neuro-ordinateur Mark-1 est apparu en général en 1958. Mais partout, il n'a pas été possible de les utiliser en raison de la faible performance des ordinateurs et du manque de corpus linguistique suffisant. Seules de grandes équipes de recherche pouvaient se permettre de faire des recherches dans le domaine des réseaux de neurones.
Les traducteurs automatiques au milieu du 20e siècle étaient loin de Google Translate et Yandex.Translator, mais avec chaque nouvelle méthode de traduction, des idées sont apparues qui ont été appliquées sous une forme ou une autre, même aujourd'hui.
1970 La traduction automatique basée sur des
règles (RBMT) a été la première tentative d'apprendre à une machine à traduire. La traduction a été obtenue comme dans une cinquième niveleuse avec un dictionnaire, mais sous une forme ou une autre, les règles pour un traducteur automatique ou un chat bot sont toujours utilisées.
1984 La traduction automatique basée sur des
exemples (EBMT) était capable de traduire même des langues complètement différentes les unes des autres, où il était inutile de fixer des règles. Tous les traducteurs automatiques et robots de discussion modernes utilisent des exemples et des modèles prêts à l'emploi.
1990. La traduction automatique statistique
(SMT en anglais) à l'ère du développement d'Internet a permis d'utiliser non seulement des corps linguistiques tout faits, mais aussi des livres et des articles librement traduits. Plus de données disponibles ont augmenté la qualité de la traduction. Les méthodes statistiques sont désormais activement utilisées dans le traitement du langage.
Réseaux de neurones au service de la PNL
Avec le développement du traitement du langage naturel, de nombreux problèmes ont été résolus par des méthodes statistiques classiques et de nombreuses règles, mais cela n'a pas résolu le problème de flou et d'ambiguïté dans le langage. Si nous disons «s'incliner» sans aucun contexte, alors même un interlocuteur vivant est peu susceptible de comprendre ce qui est dit. La sémantique du mot dans le texte est déterminée par les mots voisins. Mais comment expliquer cela à une machine si elle ne comprend qu'une représentation numérique? Ainsi est née la méthode d'analyse statistique de texte
word2vec (mot anglais en vecteur) .
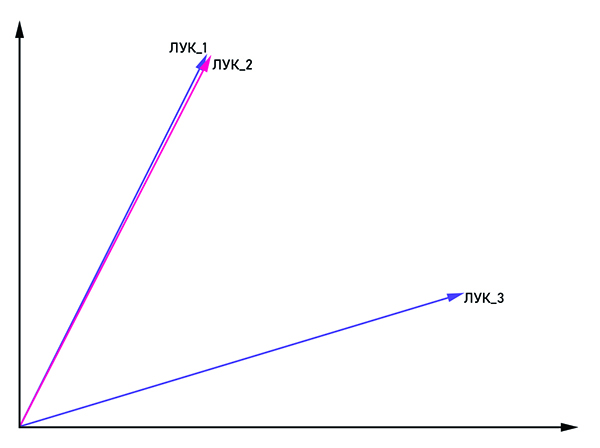 Les vecteurs bow_1 et bow_2 sont parallèles, c'est donc un mot et bow_3 est un homonyme.
Les vecteurs bow_1 et bow_2 sont parallèles, c'est donc un mot et bow_3 est un homonyme.L'idée est assez évidente du nom: présenter le mot sous la forme d'un vecteur avec des coordonnées (x
1 , x
2 , ..., x
n ). Pour lutter contre l'homonymie, les mêmes mots sont associés à la balise: "bow_1", "bow_2" et ainsi de suite. Si les vecteurs bow_n et bow_m sont parallèles, alors ils peuvent être considérés comme un seul mot. Sinon, ces mots sont des homonymes. En sortie, chaque mot a sa propre représentation vectorielle dans l'espace multidimensionnel (la dimension de l'espace vectoriel peut varier de 50 à 1000).

La question reste de savoir quel type de réseau de neurones utiliser pour former un bot de conversation conditionnel. La cohérence est importante dans le discours humain: nous tirons des conclusions et prenons des décisions sur la base de ce qui a été mentionné dans la phrase précédente ou même dans le paragraphe. Un réseau neuronal récurrent (RNN) est parfait pour ces critères, cependant, comme la distance entre les parties connectées du texte augmente, la taille du RNN doit être augmentée, ce qui entraîne une diminution de la qualité du traitement de l'information. Ce problème est résolu par le réseau LSTM
(mémoire anglaise à court terme) . Il a une caractéristique importante - l'état de la cellule, qui peut rester constant ou changer si nécessaire. Ainsi, les informations de la chaîne ne sont pas perdues, ce qui est essentiel pour le traitement du langage naturel.
Aujourd'hui, il existe un grand nombre de bibliothèques pour le traitement du langage naturel. Si nous parlons du langage Python, qui est souvent utilisé pour l'analyse des données, ce sont
NLTK et
Spacy . Les grandes entreprises participent également au développement de bibliothèques pour la PNL, telles que
NLP Architect d'Intel ou
PyTorch de chercheurs de Facebook et Uber. Malgré un tel intérêt pour les grandes entreprises dans les méthodes de traitement du langage du réseau neuronal, des dialogues cohérents sont construits principalement sur la base des méthodes classiques, et le réseau neuronal joue un rôle de soutien dans la résolution des problèmes de prétraitement et de classification de la parole.
Comment la PNL peut-elle être utilisée en entreprise?
Les applications les plus évidentes pour le traitement du langage naturel comprennent les traducteurs automatiques, les robots de discussion et les assistants vocaux - quelque chose que nous rencontrons tous les jours. La plupart des employés des centres d'appels peuvent être remplacés par des assistants virtuels, car environ 80% des demandes des clients aux banques concernent des problèmes assez typiques. Le chatbot fera également face sereinement à l'entretien initial du candidat et l'enregistrera lors d'une réunion «en direct». Curieusement, la jurisprudence est une direction assez précise, donc même ici, le chat bot peut devenir un consultant efficace.

La direction b2c n'est pas la seule où les robots de discussion peuvent être utilisés. Dans les grandes entreprises, la rotation des employés est assez active, donc tout le monde doit aider à s'adapter au nouvel environnement. Étant donné que les questions du nouvel employé sont assez typiques, l'ensemble du processus est facilement automatisé. Il n'est pas nécessaire de rechercher une personne qui vous expliquera comment faire le plein de l'imprimante, qui contacter en cas de problème. Le bot de chat interne de l'entreprise s'en sortira très bien.
Grâce à la PNL, vous pouvez mesurer avec précision la satisfaction des utilisateurs avec un nouveau produit en analysant les avis sur Internet. Si le programme a identifié l'examen comme négatif, le rapport est automatiquement envoyé au service approprié, où des personnes vivantes y travaillent déjà.
Les possibilités de traitement linguistique ne feront que s'élargir, et avec elles la portée de son application. Si 40 personnes travaillent dans le centre d'appels de votre entreprise, cela vaut la peine d'envisager: peut-être vaut-il mieux les remplacer par une équipe de programmeurs qui mettront en place un chat bot pour vous?
Vous pouvez en savoir plus sur les possibilités de traitement du langage sur notre cours
AI Weekend , où Anna Vlasova parlera en détail des robots de chat dans le cadre du sujet de l'intelligence artificielle.