Avez-vous déjà analysé des postes vacants?
Ils ont posé la question: dans quelles technologies la demande du marché du travail est-elle la plus courante? Il y a un mois? Il y a un an?
À quelle fréquence les nouvelles offres d'emploi Java ouvrent-elles dans une zone spécifique de votre ville et à quelle fréquence se ferment-elles?
Dans cet article, je vais vous expliquer comment vous pouvez obtenir le résultat souhaité et créer un système de reporting sur un sujet qui nous intéresse. C'est parti!
(Source de l'image)Beaucoup d'entre vous sont probablement familiers et ont même utilisé une ressource telle que
Headhunter.ru . Des milliers de nouveaux postes vacants dans divers domaines sont affichés quotidiennement sur ce site. HeadHunter dispose également d'une API qui permet au développeur d'interagir avec les données de cette ressource.
Boîte à outils
En utilisant un exemple simple, nous considérons la construction d'un processus d'obtention de données pour un système de reporting, qui est basé sur le travail avec l'API du site Headhunter.ru. En tant que stockage intermédiaire d'informations, nous utiliserons le SGBD SQLite intégré, les données traitées seront stockées dans la base de données NoSQL de MongoDB, Python 3.4 comme langue principale.
API HHLes capacités de l'API HeadHunter sont assez étendues et bien décrites dans la documentation officielle sur
GitHib . Tout d'abord, c'est la possibilité d'envoyer des demandes anonymes qui ne nécessitent pas d'autorisation pour recevoir des informations sur le travail au format JSON. Récemment, un certain nombre de méthodes sont devenues payantes (méthodes de l'employeur), mais elles ne seront pas prises en compte dans cette tâche.
Chaque poste vacant est suspendu sur le site pendant 30 jours, après quoi, s'il n'est pas renouvelé, il sera archivé. Si le poste était archivé avant l'expiration d'un délai de 30 jours, il était alors fermé par l' employeur.
L'API HeadHunter (ci-après dénommée API HH) vous permet de recevoir une série d'offres d'emploi publiées pour n'importe quelle date au cours des 30 derniers jours, que nous utiliserons - nous collecterons quotidiennement les offres publiées pour chaque jour.
Implémentation
- Connecter SQLite DB
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor()
- Tableau de stockage des modifications de l'état du travail
Pour plus de commodité, nous enregistrerons l'historique du changement d'état de la vacance (disponibilité par date) dans un tableau spécial de la base de données SQLite. Grâce à la table vacancy_history, nous serons informés de la disponibilité des vacances sur le site à toute date de déchargement, c'est-à-dire à quelles dates elle était active.
c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''')
- Filtrage des vacances
Il y a une restriction qu'une demande ne peut pas renvoyer plus de 2000 collections, et comme il peut y avoir beaucoup plus de postes vacants publiés sur le site en une journée, nous mettrons un filtre dans le corps de la demande, par exemple: postes vacants uniquement à Saint-Pétersbourg (zone = 2) , par spécialisation informatique (spécialisation = 1)
path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to))
- Conditions de sélection supplémentaires
Le marché du travail croît rapidement et même en tenant compte du filtre, le nombre de postes vacants peut dépasser 2000, nous allons donc fixer une limite supplémentaire sous la forme d'un lancement distinct pour chaque jour: postes vacants pour la première moitié de la journée et postes vacants pour la seconde moitié de la journée
def get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ...
Premier cas d'utilisationSupposons que nous soyons confrontés à la tâche d'identifier les postes vacants qui ont été fermés pour un certain intervalle de temps, par exemple, pour juillet 2018. Ceci est résolu comme suit: le résultat d'une simple requête SQL vers la table vacancy_history renverra les données dont nous avons besoin, qui peuvent être transmises au DataFrame pour une analyse plus approfondie:
c.execute(""" select a.id_vacancy, date(a.date_load) as date_last_load, date(a.date_from) as date_publish, ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close from ( select vh1.id_vacancy, vh1.date_load, vh1.date_from, min(vh2.date_load) as date_next from vacancy_history vh1 left join vacancy_history vh2 on vh1.id_vacancy = vh2.id_vacancy and vh1.date_load < vh2.date_load where date(vh1.date_load) between :date_in and :date_out group by vh1.id_vacancy, vh1.date_load, vh1.date_from ) as a where a.date_next is null """, {"date_in" : date_in, "date_out" : date_out}) date_in = dt.datetime(2018, 7, 1) date_out = dt.datetime(2018, 7, 31) closed_vacancies = get_closed_by_period(date_in, date_out) df = pd.DataFrame(closed_vacancies, columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close']) df.head()
On obtient le résultat de ce type:
Si nous voulons analyser à l'aide d'outils Excel ou d'outils de BI tiers, nous pouvons télécharger la table vacancy_history dans un fichier csv pour une analyse plus approfondie:
Artillerie lourde
Mais que se passe-t-il si nous devons effectuer une analyse de données plus complexe? Ici, la
base de données NoSQL orientée document de
MongoDB vient à la rescousse, ce qui vous permet de stocker des données au format JSON.
Les actions susmentionnées de collecte des postes vacants sont lancées quotidiennement, il n'est donc pas nécessaire de consulter tous les postes vacants à chaque fois et de recevoir des informations détaillées pour chacun d'eux. Nous ne prendrons que ceux qui ont été reçus au cours des cinq derniers jours.
- Obtention d'un tableau d'offres d'emploi pour les 5 derniers jours à partir d'une base de données SQLite:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items
- Obtenir un éventail d'emplois pour les cinq derniers jours de MongoDB:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo
- Il reste à trouver la différence entre les deux tableaux, pour les postes vacants qui ne sont pas dans MongoDB, obtenez des informations détaillées et écrivez-les dans la base de données:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_pro = [] s = set(mongo_list) vac_for_pro = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_pro[x: x + 500] for x in range(0, len(vac_for_pro), 500)]
- Nous avons donc un tableau avec de nouveaux postes vacants qui ne sont pas encore disponibles dans MongoDB, pour chacun d'eux, nous recevrons des informations détaillées en utilisant une demande dans l'API HH, avant de les traiter directement dans MongoDB, nous traiterons chaque document:
- Nous portons le montant du salaire à l'équivalent en roubles;
- Ajouter une graduation d'un niveau de spécialiste à chaque poste vacant (Junior / Moyen / Senior, etc.)
Tout cela est implémenté dans la fonction vacancies_processing:
from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt)
- Obtention d'informations détaillées en accédant à l'API HH, pré-traitement reçu
MongoDB réalisera les données et les insérera dans plusieurs flux, avec 500 postes vacants dans chacun:
t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
La collection peuplée dans MongoDB ressemble à ceci:
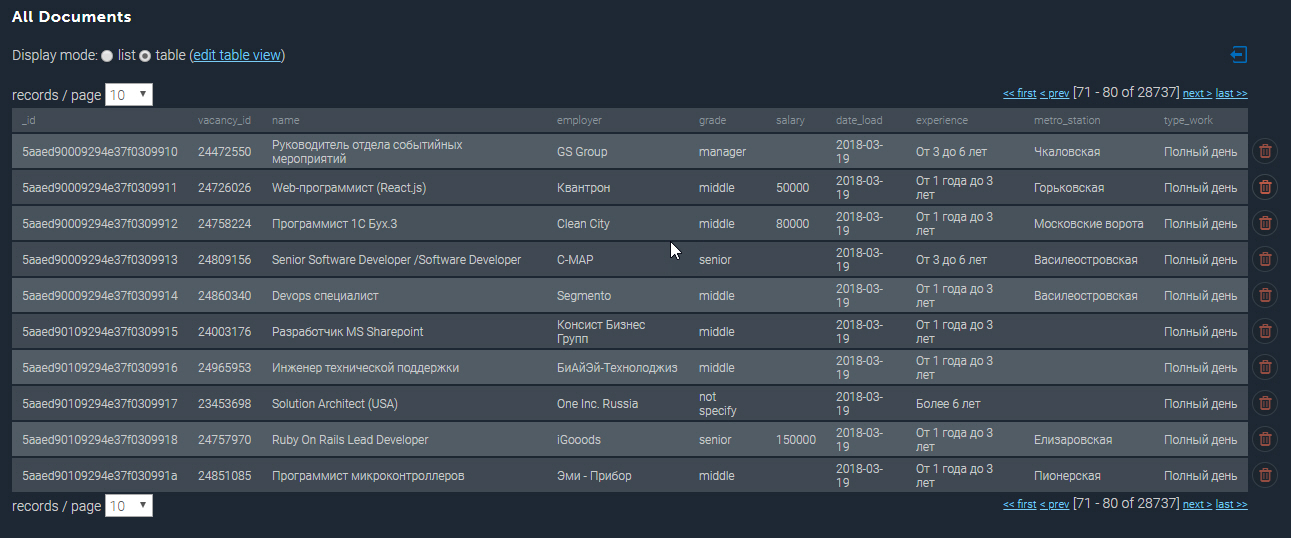
Quelques exemples supplémentaires
Ayant à notre disposition la base de données collectée, nous pouvons réaliser différents échantillons analytiques. Je vais donc faire ressortir le Top 10 des offres d'emploi les plus rémunérées des développeurs Python à Saint-Pétersbourg:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}}) df_mongo = pd.DataFrame(list(cursor_mongo)) del df_mongo['_id'] pd.concat([df_mongo.drop(['employer'], axis=1), df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade', 'name', 'salary_processed' ]].sort_values('salary_processed', ascending=False)[:10]
Top 10 des emplois les mieux payés de Python| grade | nom | nom | salaire_procédé |
|---|
| senior | Chef d'équipe Web / Architecte (Python / Django / React) | Investex ltd | 293901.0 |
| senior | Développeur Python senior au Monténégro | Betmaster | 277141.0 |
| senior | Développeur Python senior au Monténégro | Betmaster | 275289.0 |
| milieu | Développeur Web Back-End (Python) | Soshace | 250000.0 |
| milieu | Développeur Web Back-End (Python) | Soshace | 250000.0 |
| senior | Lead Python Engineer pour une startup suisse | Assaia International AG | 250000.0 |
| milieu | Développeur Web Back-End (Python) | Soshace | 250000.0 |
| milieu | Développeur Web Back-End (Python) | Soshace | 250000.0 |
| senior | Teamlead Python | Digitalhr | 230000.0 |
| senior | Développeur principal (Python, PHP, Javascript) | GROUPE IK | 220231.0 |
Voyons maintenant quelle station de métro a la plus forte concentration de postes vacants pour les développeurs Java. En utilisant une expression régulière, je filtre par titre de poste «Java», et ne sélectionne également que les emplois dont l'adresse est spécifiée:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}}) df_mongo = pd.DataFrame(list(cursor_mongo)) df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name'] if x['address']['metro'] is not None else None, axis = 1) df_mongo.groupby('metro')['_id'] \ .count() \ .reset_index(name='count') \ .sort_values(['count'], ascending=False) \ [:10]
Emplois pour les développeurs Java dans les stations de métro| métro | compter |
|---|
| Vasileostrovskaya | 87 |
| Petrogradskaya | 68 |
| Vyborg | 46 |
| Place Lénine | 45 |
| Gorkovskaya | 45 |
| Chkalovskaya | 43 |
| Narva | 32 |
| Place du soulèvement | 29 |
| Vieux village | 29 |
| Elizarovskaya | 27 |
Résumé
Ainsi, les capacités analytiques du système développé sont vraiment étendues et peuvent être utilisées pour planifier un démarrage ou ouvrir une nouvelle direction d'activité.
Je note que jusqu'à présent, seule la fonctionnalité de base du système est présentée, à l'avenir, il est prévu de la développer dans le sens d'une analyse par coordonnées géographiques et de prédire l'apparition de vacances dans une zone particulière de la ville.
Le code source complet de cet article se trouve sur le lien vers mon
GitHub .
PS Les commentaires sur l'article sont les bienvenus, je serai heureux de répondre à toutes vos questions et de connaître votre avis. Je vous remercie!