Il s'agit d'une brève digression dans la série d'articles actuelle sur la façon d'éviter l'introduction de services pour diverses entités. Une conversation intéressante au dîner a conduit à des réflexions que j'ai décidé d'écrire.
La loi d'Amdahl
En 1967, Gene Amdahl a plaidé contre l'informatique parallèle. Il a fait valoir que la croissance de la productivité est limitée car seule une partie de la tâche peut être parallélisée. La taille du reste de la "partie séquentielle" diffère selon les tâches, mais elle est toujours là. Cet argument est devenu connu sous le nom de loi d'Amdal.
Si vous créez un graphique "d'accélération" de la tâche en fonction du nombre de processeurs parallèles qui lui sont alloués, vous verrez ce qui suit:
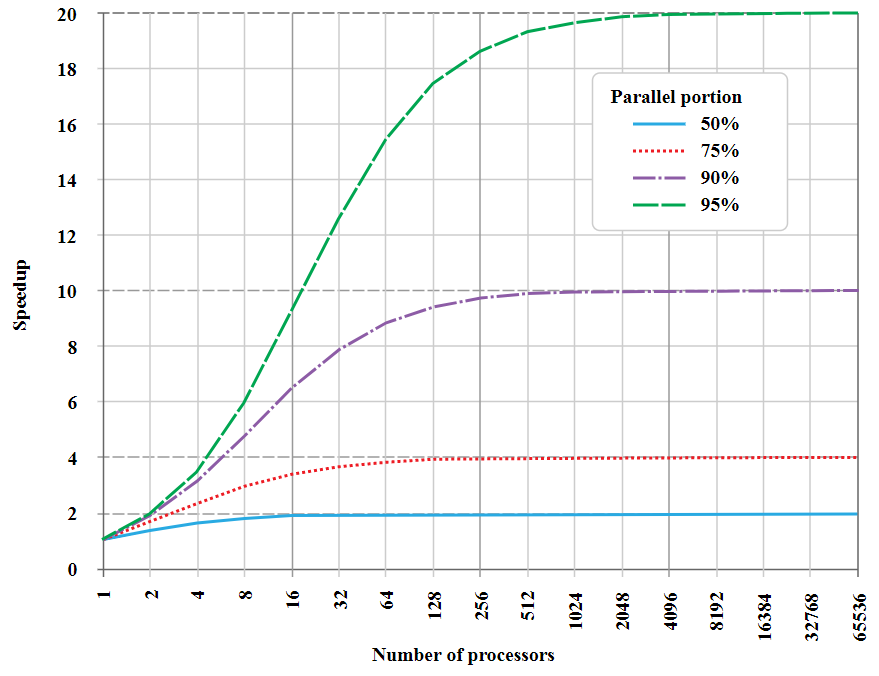 Il s'agit d'un graphe asymptotique pour un fragment qui ne peut pas être parallélisé (la "partie séquentielle"), donc il y a une limite supérieure à l'accélération maximale
Il s'agit d'un graphe asymptotique pour un fragment qui ne peut pas être parallélisé (la "partie séquentielle"), donc il y a une limite supérieure à l'accélération maximaleD'Amdal à USL
La chose intéressante à propos de la loi d'Amdal est qu'en 1969, il y avait en fait très peu de systèmes multiprocesseurs. La formule est basée sur un autre principe: si la partie séquentielle de la tâche est égale à zéro, alors ce n'est pas une tâche, mais plusieurs.
Neil Gunther a étendu la loi d'Amdahl sur la base des observations des mesures de performances de nombreuses machines et a dérivé la loi universelle d'évolutivité (USL). Il utilise deux paramètres: un pour la «concurrence» (qui est similaire à la partie séquentielle) et le second pour «l'incohérence» (incohérence). L'incohérence est liée au temps passé à restaurer la cohérence, c'est-à-dire une vue générale du monde des différents processeurs.
Dans un processeur, la surcharge de négociation se produit en raison de la mise en cache. Lorsqu'un cœur modifie une ligne de cache, il indique aux autres noyaux de récupérer cette ligne dans le cache. Si tout le monde a besoin de la même ligne, ils passent du temps à la charger depuis la mémoire principale. (Il s'agit d'une description légèrement simplifiée ... mais dans une formulation plus précise, il y a toujours le coût de la négociation).
Tous les nœuds de base de données entraînent des coûts de coordination en raison des algorithmes de correspondance et de l'enregistrement de la séquence de données. La pénalité est payée lors du changement de données (comme dans le cas des bases de données transactionnelles) ou lors de la lecture des données dans le cas de référentiels finalement convenus.
Effet USL
Si vous créez un graphique USL en fonction du nombre de processeurs, une ligne verte apparaît:
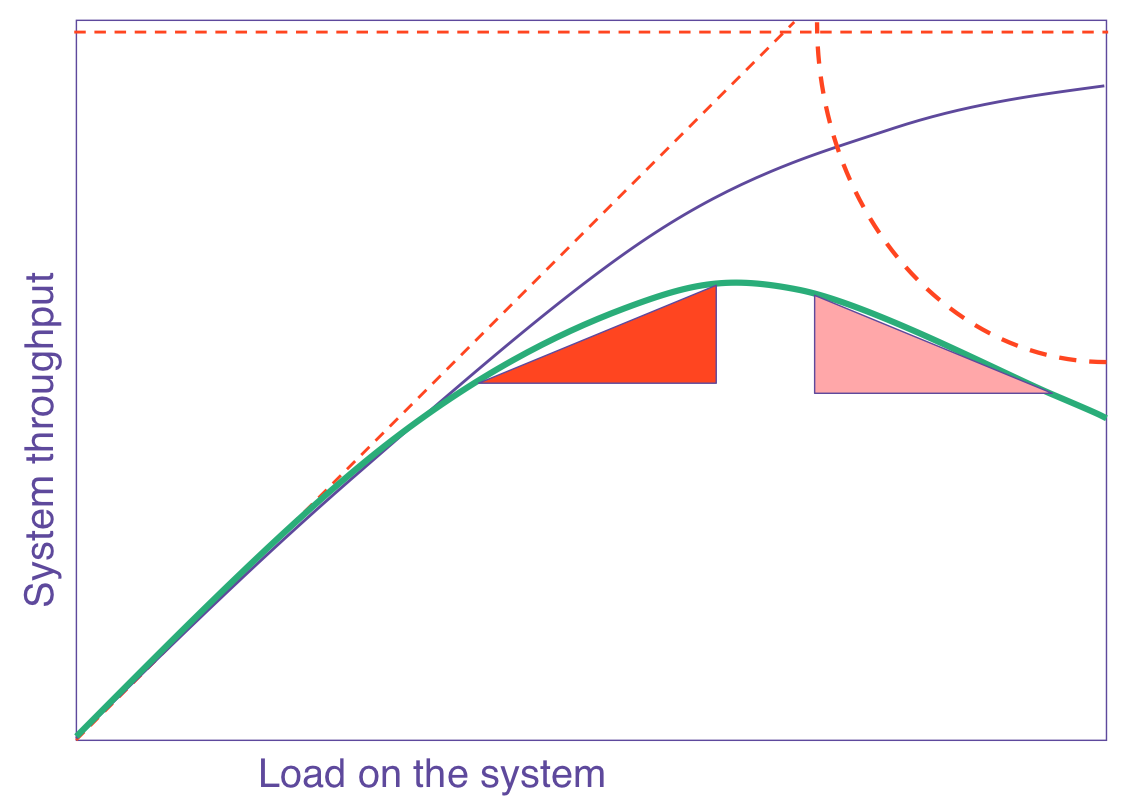 La ligne violette indique que la loi d'Amdahl prédirait
La ligne violette indique que la loi d'Amdahl prédiraitNotez que la ligne verte atteint un pic puis diminue. Cela signifie qu'il existe un certain nombre de nœuds pour lesquels les performances maximales.
Ajoutez plus de processeurs et les performances sont réduites . J'ai vu cela dans de vrais tests de résistance.
Les gens veulent souvent augmenter le nombre de processeurs et augmenter la productivité. Il existe deux façons de procéder:
- Réduisez la partie séquentielle
- Réduisez les coûts d'approbation
USL dans les groupes humains?
Essayons l'analogie. Si la «tâche» de calcul est un projet, alors nous pouvons représenter le nombre de personnes dans le projet comme le nombre de «processeurs» qui effectuent le travail.
Dans ce cas, la partie séquentielle est un travail qui ne peut être effectué que séquentiellement, étape par étape. Cela peut être un sujet pour un futur article, mais maintenant nous ne sommes pas intéressés par l'essence de la partie séquentielle.
Nous semblons voir une analogie directe avec les coûts de la réconciliation. Quel que soit le temps que les membres de l'équipe passent à restaurer une vision commune du monde, les coûts d'alignement sont présents.
Pour cinq personnes dans une pièce, ces coûts sont minimes. Dessin de cinq minutes avec un marqueur sur le tableau noir une fois par semaine environ.
Pour une grande équipe dans plusieurs fuseaux horaires, l'amende peut croître et se formaliser. Documents et procédures pas à pas. Présentations pour l'équipe et ainsi de suite.
Dans certaines architectures, la réconciliation n'est pas si importante. Imaginez une équipe avec des employés sur trois continents, mais chacun travaille sur un service qui utilise des données dans un format strictement défini et crée des données dans un format strictement défini. Ils n'ont pas besoin de cohérence en ce qui concerne les changements de processus, mais ils ont besoin de cohérence en ce qui concerne les changements de formats.
Parfois, les outils et les langues peuvent modifier les coûts de la réconciliation. L'un des arguments en faveur du typage statique est qu'il permet d'interagir en équipe. Essentiellement, les types de code sont un mécanisme pour traduire les changements dans un modèle du monde. Dans un langage typé dynamiquement, nous avons besoin soit d'artefacts secondaires (tests unitaires ou messages de discussion), soit nous devons créer des limites où certains départements rétablissent très rarement la cohérence avec d'autres.
Toutes ces méthodes visent à réduire les coûts de coordination. Rappelons qu'une mise à l'échelle excessive entraîne une diminution du débit. Donc, si vous avez des coûts de coordination élevés et trop de personnes, l'équipe dans son ensemble travaille plus lentement. J'ai vu des équipes où il semblait que nous pouvions couper la moitié des gens et travailler deux fois plus vite. Les coûts USL et de rapprochement aident maintenant à comprendre pourquoi cela se produit - c'est plus que le simple enlèvement des ordures. Il s'agit de réduire les frais généraux d'échange de modèles mentaux.
Dans
The Loop of Fear, j'ai fait référence à des bases de code où les développeurs connaissaient la nécessité de changements à grande échelle, mais craignaient de nuire accidentellement. Cela signifie que l'équipe sur-gonflée
n'est pas encore parvenue à un consensus. Il semble très difficile de se réconcilier après la perte. Cela signifie qu'il est impossible d'ignorer les coûts de coordination.
USL et microservices
À mon avis, USL explique l'intérêt pour les microservices. En divisant un grand système en parties de plus en plus petites qui sont déployées indépendamment les unes des autres, vous réduisez la partie séquentielle du travail. Dans un grand système avec un grand nombre de participants, la partie séquentielle dépend de la quantité d'efforts à intégrer, tester et déployer. L'avantage des microservices est qu'ils n'ont pas besoin de travail d'intégration, de test d'intégration ou de retard dans le déploiement synchronisé.
Mais le coût de l'appariement signifie que vous n'obtiendrez peut-être pas l'accélération souhaitée. L'analogie est peut-être un peu tendue ici, mais je pense qu'il est possible de considérer les changements d'interface entre les microservices comme nécessitant une réconciliation entre les équipes. Si c'est trop, vous n'obtiendrez pas les avantages souhaités des microservices.
Que faire à ce sujet?
Ma suggestion: regardez l'architecture, le langage, les outils et l'équipe utilisés. Pensez à l'endroit où le temps est perdu pour la réconciliation lorsque les gens modifient le modèle systémique du monde.
Recherchez les
lacunes . Écarts entre les limites internes du système et divisions au sein de l'équipe.
Utilisez l'environnement pour communiquer les changements afin que le processus de réconciliation ait lieu pour tout le monde, pas individuellement.
Regardez les communications de votre équipe. Combien de temps et d'efforts faut-il pour assurer la cohérence? Peut-être faire de petits changements et en réduire le besoin?