Une caractéristique importante des tâches d'apprentissage automatique est que des résultats tout aussi bons peuvent être obtenus en utilisant différentes méthodes. Cela donne de l'enthousiasme aux compétitions ML: même en ayant d'autres compétences qu'un adversaire manifestement fort, vous pouvez toujours gagner. Les équipes Tensorborne et Neurobotics avaient des chances presque égales de gagner le hackathon DeepHack et ont finalement pris les deux premières places. Lors de la
formation Yandex, les représentants des deux équipes ont fait un volumineux rapport. Dans le décodage, vous trouverez une analyse détaillée des solutions et des conseils pour les concurrents débutants.
Et bien sûr, prenez des vacances de hackathon. Lorsque vous participez à un hackathon hebdomadaire et travaillez en même temps, c'est mauvais. Vous arrivez à 19 heures, après avoir travaillé un peu, asseyez-vous et compilez Docker avec TensorFlow, Keras, pour que tout cela commence sur certains serveurs distants auxquels vous n'avez même pas accès. Quelque part en deux nuits, vous attrapez la catharsis, et cela fonctionne pour vous - sans Docker, sans tout, parce que vous avez compris que c'est possible et ainsi.
Vitaly Davydov:
- Bonjour à tous! Nous aurions dû avoir deux rapports, mais nous avons décidé de les combiner en un seul, car nous parlons de la première et de la deuxième place dans la compétition DeepHack. Nous représentons deux équipes. Notre équipe Tensorborne a pris la 2e place, et l'équipe de Gregory Neurobotics - la première.

Le rapport comprendra trois parties principales. Dans l'intro, je vais parler de l'histoire de DeepHack, de ce que c'est, des mesures, etc. Ensuite, les gars parleront de solutions, de quels problèmes, d'exemples, etc.
Avant de parler de DeepHack, il convient de noter qu'il s'agit d'un petit sous-ensemble d'une autre très grande compétition mondiale ConvAI2, qui a lancé Facebook l'année dernière. Cette année est la deuxième itération. À un moment donné, Facebook a parrainé l'Institut de physique et de technologie de Moscou, et le concours DeepHack a été créé sur la base du laboratoire PhysTech.

En savoir plus sur ConvAI lui-même. Quel problème essaie-t-il de résoudre? Il est spécialisé dans les systèmes interactifs. Le problème avec les systèmes de dialogue est qu'il n'y a pas d'outil d'évaluation unique, un outil d'évaluation, pour comprendre la qualité des dialogues. Cette chose est très subjective d'une personne à l'autre: quelqu'un peut aimer la conversation, pas quelqu'un. La tâche globale générale de ConvAI est de proposer une métrique unifiée commune pour l'évaluation des dialogues, qui n'est pas encore disponible. Prix - 20 000 $ pour AWS Mechanical Turk. Ce ne sont pas des prêts à Amazon, ce ne sont que des prêts à Mechanical Turk, qui est en fait un analogue de Yandex.Tolki. Il s'agit d'un service de crowdsourcing qui vous permet de faire du balisage sur les données.
La tâche, qui est construite sur ConvAI, est de construire un chit-chat-bot avec lequel vous pouvez faire une sorte de dialogue. Ils ont choisi trois mesures: Perplexité, Hits @ 1 et F1. Je vais maintenant montrer le tableau qui était au moment de notre présentation.
L'évaluation par laquelle ils ont essayé de le faire est passée par trois étapes. La première étape est la mesure automatique, puis l'évaluation AWS Mechanical Turk, puis le chat en direct avec des bénévoles.
Puisque ConvAI est parrainé par Facebook, il promeut activement sa bibliothèque pour créer des systèmes conversationnels ParlAI. C'est assez compliqué, mais je pense que tous les participants ont utilisé cette bibliothèque. Nous l'avons traité pendant un certain temps, il n'est pas compatible avec Python 3.6, par exemple, et il y a un certain nombre de problèmes.
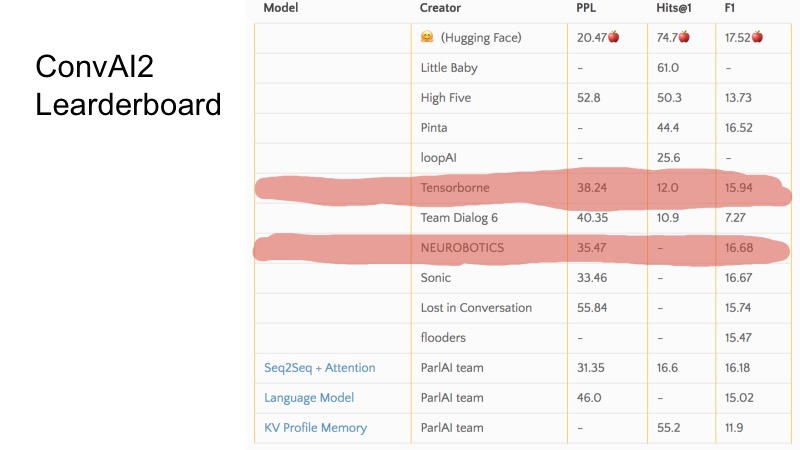
Dans ces quelques lignes, vous pouvez voir quels postes nous occupions au moment de la soumission. En général, ConvAI est étrangement organisé dans le sens où il y a trois métriques et on ne sait pas très bien comment va le classement sur ce tableau. On peut voir que pour certaines mesures, certaines équipes sont plus élevées, pour certaines plus faibles. L'organisation de l'ensemble du ConvAI était un peu étrange.
Mais il y a trois bases de base. Pour se qualifier pour DeepHack, il a fallu briser cette ligne de base et les 10 meilleures équipes se sont qualifiées pour la finale. En secret, je dirai que seules 8 équipes ont envoyé des décisions et que tout le monde a atteint la finale. Ce n'était pas très difficile.

La tâche de DeepHack était un peu plus compréhensible et simple. Nous devions à nouveau construire un robot de conversation, mais qui imiterait une personnalité donnée. Autrement dit, le robot a reçu une description d'une personne à l'entrée, et lors d'une conversation avec lui, il a dû la révéler. Le prix était assez intéressant - un voyage au NIPS cet automne, qui est entièrement parrainé.
La métrique, contrairement à ConvAI, était déjà différente. Il y avait deux mesures, et la mesure totale est pondérée entre les deux. La première mesure est la qualité globale, une évaluation de la façon dont le bot a répondu de manière adéquate, à quel point il était intéressant de communiquer avec lui, s'il écrivait des ordures, etc. La deuxième mesure est un jeu de rôle, 0 ou 1. Cela signifie Le bot est-il entré dans la description qui lui a été donnée? La personne qui communique avec le bot ne voit pas la description. L'évaluation a eu lieu dans Telegram, c'est-à-dire qu'il n'y avait qu'un seul bot Telegram, et quand l'utilisateur a commencé à communiquer avec lui, il est arrivé à un bot aléatoire de toutes les soumissions, pour être honnête. Yandex et MIPT, apparemment, y ont versé un peu de trafic, et il y a eu environ 10 000 dialogues, si je me souviens bien.
J'ai déjà parlé du tour de qualification. La finale était à plein temps. Cela s'est déroulé pendant sept jours de travail à l'Institut de physique et de technologie de Moscou, un cluster a été fourni, une place, nous nous sommes assis et avons travaillé là-bas. L'évaluation était en fait tous les jours, et le score final, la note du bot à la fin, était calculé de cette façon. Le concours a commencé lundi, la première soumission a eu lieu mardi et l'évaluation a eu lieu le lendemain. La solution que vous avez publiée mardi a été évaluée mercredi avec un poids de 1,5. Ce que vous avez envoyé mercredi - avec un poids de 1,4, etc.

À propos de l'ensemble de données que Facebook a donné pour la formation. Il s'appelle Persona-Chat et est une description de deux personnalités et d'un ensemble de dialogues. Il y a une description de la première personne et de la seconde. Dans le processus de description du dialogue, ils essaient de se révéler. C'est tout ce qui a été donné. Cependant, comme toujours, dans la compétition, il n'était pas interdit d'utiliser d'autres ensembles de données tiers.
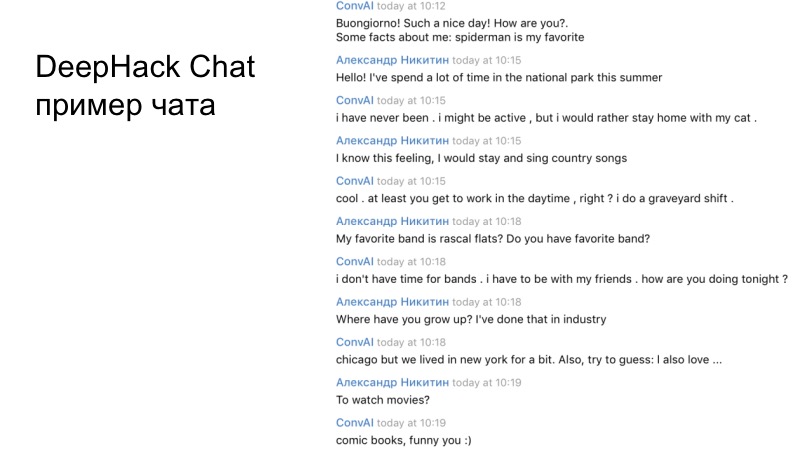
Un exemple du dialogue de notre équipe. Si vous lisez attentivement, il est clair que le bot résultant fonctionne de manière tout à fait adéquate et répond tout à fait correctement.
Gregory parlera de la première place.
Grigory Rashkov:
- Je voudrais parler de notre expérience de participation au concours, de notre stratégie et de notre décision.

Premièrement, la particularité de la compétition est qu'elle est longue, nous n'avons pas eu deux jours, comme sur un hackathon ordinaire, mais cinq jours, pour lesquels nous avons pu prendre de nombreuses décisions.

Évaluations très subjectives, car des personnes complètement différentes ont évalué leurs critères, en particulier, l'organisateur du hackathon Mikhail Bubtsev a dit que s'il devinait même de quel profil il parlait, mais que le bot à un moment donné contredisait son profil, il n'a pas répondu à la question , comme il est écrit, il a choisi un profil différent, même s'il savait de quoi il s'agissait.
Et le troisième est le manque de validation. Les participants n'ont pas pu faire un petit changement et recevoir immédiatement des commentaires.
Comme dans tous les films d'horreur, notre équipe a tout de suite décidé de se séparer. Le premier groupe était engagé dans notre solution principale basée sur le Wasserstein GAN, le deuxième groupe était engagé dans le bot, le panneau d'administration du bot basé sur la ligne de base. Parce que nous devions envoyer quelque chose le premier et le deuxième jour.

En bref sur la ligne de base: Seq2Seq plus l'attention, qui est légèrement adaptée à cette tâche spécifique. Comment exactement? Une phrase est envoyée à l'entrée, l'incorporation est tirée de GloVe, mais la présentation de chaque phrase en tant qu'incorporation pondérée est examinée plus avant. Les poids sont sélectionnés en fonction de la fréquence inverse du mot. Plus un mot apparaît rarement, plus il a de poids.

Cela est nécessaire pour refléter le caractère unique de ces caractéristiques. Tout allait à un ensemble, une matrice, un masque a été construit sur la base de cet ensemble et d'un état caché, puis ce masque a été superposé à l'ensemble, un contexte a été obtenu, puis il a été connecté, par le biais de la non-linéarité, il a été envoyé à l'entrée des décodeurs.

Pour le premier jour, nous n'avons pas encore écrit notre décision, nous avons dû envoyer quelque chose, alors nous avons écrit un agent basé sur la ligne de base, mais nous nous sommes fixé pour tâche de nous démarquer d'une manière ou d'une autre de la masse grise des agents. Pour ce faire, nous avons utilisé des heuristiques simples, notre bot a été le premier à entamer un dialogue, et il a utilisé un sourire dans cette phrase. Et ça a marché.
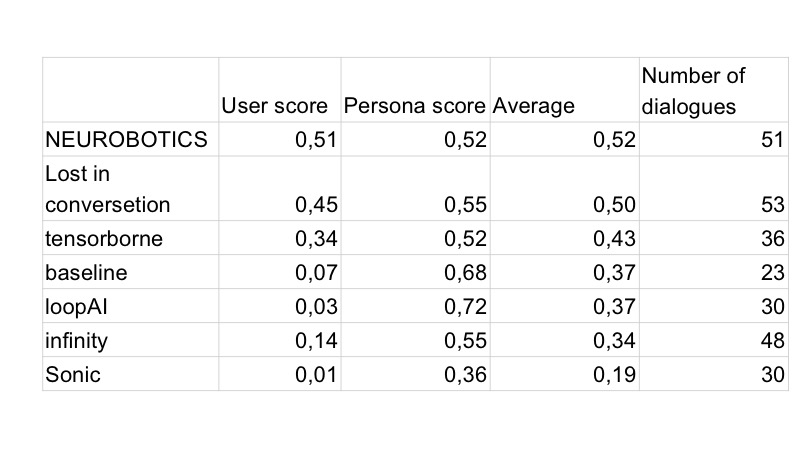
Naturellement, le lendemain, tous les bots ont commencé à être créés en premier, et tous avaient des émoticônes. Le deuxième jour, les habitants de Vilabaggio ont continué à travailler avec le GAN, les habitants de Vilaribo ont essayé d'autres heuristiques.
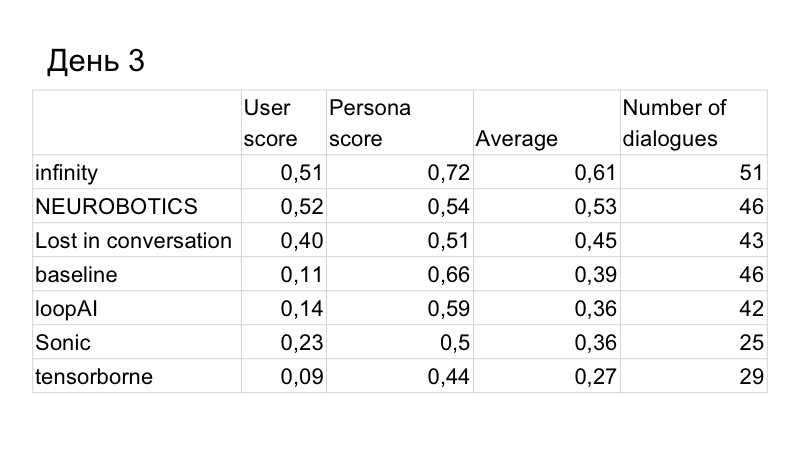
En conséquence, le score sur la qualité du dialogue s'est légèrement amélioré, mais nous avons été dépassés par la personne. Ce sont les résultats du troisième jour, il ne restait que deux jours. Nous avons compris que ce ne serait pas assez de temps pour nous d'écrire un GAN et de le tester normalement, car il étudie depuis longtemps, dur, nous devons sélectionner beaucoup d'hyperparamètres. Nous avons donc décidé de passer à la ligne de base, car cela fonctionne si bien.

Notre tâche était d'améliorer la reconnaissance du profil utilisateur. Nous avons proposé une telle heuristique. Quel était le problème? L'utilisateur a heureusement parlé avec le bot, lui demandant quel genre de travail il avait, ses loisirs, quel type de voiture il conduisait, le bot a bien répondu à tout cela, car le bot a généralement bien répondu. En conséquence, à la fin du dialogue, l'utilisateur a vu deux profils qui n'avaient rien à voir avec ce qui était dans le dialogue, simplement parce que d'autres choses y étaient indiquées que celles demandées par l'utilisateur. Par conséquent, nous avons décidé qu'il était nécessaire de donner en quelque sorte des informations à partir du profil.
Comment faire cela de la manière la plus logique? Si une personne a des intérêts, elle en parlera probablement, cherchez des intérêts communs. Par conséquent, nous avons décidé que le bot poserait à certains moments des questions sur la base de son profil. Il y avait un effet intéressant que le générateur, qui a été écrit simplement selon les règles linguistiques de G, utilise un fait A du profil, par conséquent, G (A) est entré dans la boîte de dialogue, tout cela est envoyé à la mémoire du bot, et la prochaine fois que le modèle génère des informations, procédant à la fois du profil et de ce dialogue, c'est-à-dire, avec une plus grande probabilité, il dira quelque chose lié au profil.
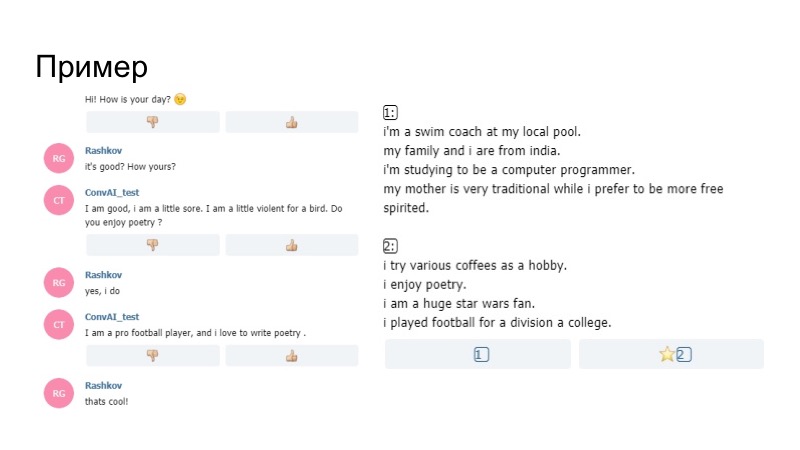
À quoi cela ressemblait-il en réalité? Le robot dans le profil dit qu'il est ravi de la poésie, puis pendant la conversation, il me demande si j'aime la poésie. Je dis oui, et plus loin sur son modèle, pas le générateur que nous avons construit selon les règles, dit qu'il aime écrire de la poésie. Ainsi, le bot s'est concentré sur son profil, et cela a fonctionné.

Nous sommes revenus à la première place. Le dernier jour est resté. Nous avons remarqué que nous perdons néanmoins en tant que dialogue.

Nous avons profité de plusieurs autres solutions. Tout d'abord, ils ont utilisé la paraphrase, analysé ce que les autres ont dit, car les organisateurs ont présenté cette base de données et ont remarqué que beaucoup de gens communiquent avec le bot n'est pas tout à fait correct.
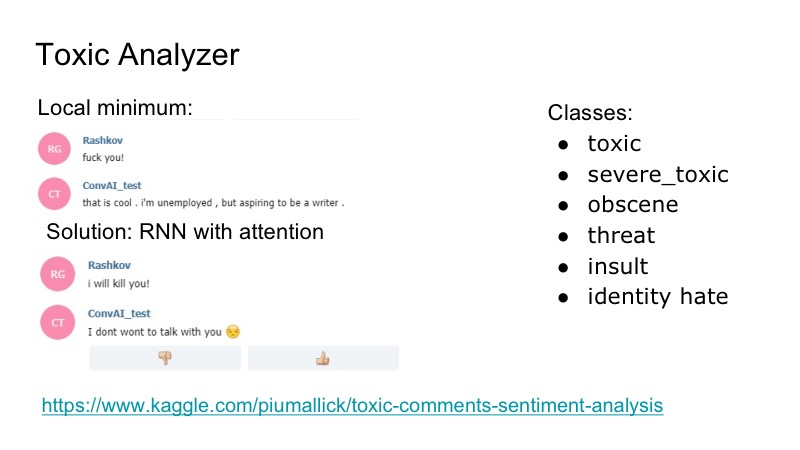
Il y a un minimum local intéressant au bot: il répond très bien à toutes les insultes, il est d'accord avec elles, et pour corriger cela, nous avons décidé d'utiliser la compétition Kaggle pour l'analyseur de commentaires toxiques, nous avons écrit un classificateur très simple, également avec l'attention de RNN. Dans cet ensemble de données, il y avait les classes suivantes, qui se chevauchaient: insultes, menaces ... Nous avons décidé de ne pas étudier le modèle séparément, qui parlera, car un tel problème a été rencontré, mais il n'était pas très fréquent. Par conséquent, nous venons d'écrire une sorte de gag auquel le bot a répondu, et tout le monde était content.

De plus, nous avons utilisé la paraphrase pour enrichir le discours de notre bot. Ce n'était pas non plus très difficile, nous avons remplacé les mots de la phrase par des synonymes, regardé les n-grammes résultants dans la phrase, afin qu'ils ne diffèrent pas beaucoup de ceux qui étaient à l'origine, puis nous avons choisi la combinaison la plus appropriée pour la phrase avec la plus grande probabilité.
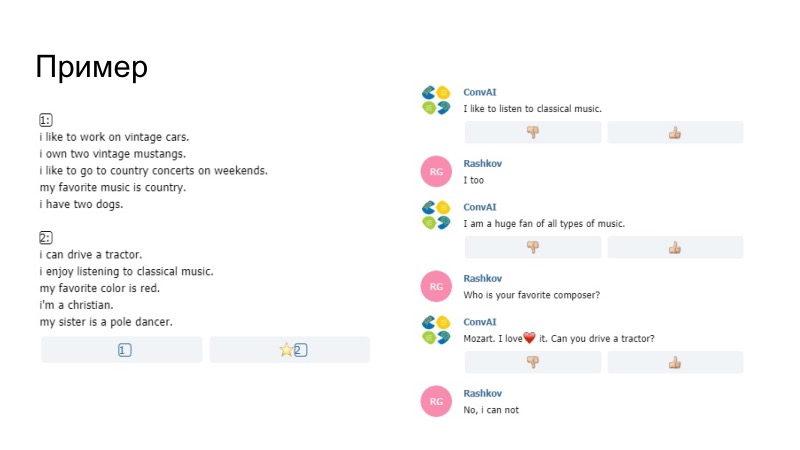
Comme exemple de ce qui s'est passé, le bot ici dit qu'il aime écouter de la musique, il dit apprécier dans le profil, il a été remplacé par comme avec nous. Nous ne savons pas si le modèle lui-même ou notre Paraphraser l'a généré, mais cette chose est passée. Une autre remarque qu'il était impossible d'envoyer uniquement des données du profil. Des pentagrammes y ont été comparés. Si les pentagrammes coïncidaient avec votre remarque et votre profil, alors simplement cette phrase ne passait pas, les organisateurs l'ont arrangée. De plus, entre autres, nous avons ajouté un dictionnaire de smiley.

Le deuxième exemple, nous avons beaucoup de sourires. Puis il y a eu l'heuristique, lorsque le bot a réagi à votre comportement que vous ne lui avez pas écrit pendant longtemps. Paraphraser a également fonctionné ici et a donné un bon résultat.

La qualité du dialogue était la meilleure, la qualité de jouer le rôle aussi.
Nous avons essayé de faire en sorte que le modèle génère un ensemble d'options et nous les avons comparées au profil. Mais il me semblait que dans ce cas le bot fonctionnait moins bien, on ne pouvait pas faire de validation, seulement des évaluations subjectives en deux ou trois conversations. Par conséquent, ils ont décidé de ne pas mettre une telle chose, car le profil était déjà bien reconnu.
Ensuite, nous avons écrit une solution au problème inverse, le deuxième modèle, qui a sélectionné le profil souhaité dans le dialogue. Nous avions prévu de l'utiliser initialement pour la formation afin d'en lire la fonction de perte et de la distribuer ensuite dans le réseau. Mais cela pourrait aggraver le locuteur lui-même, alors ils ont décidé de ne pas le dire comme ça. Nous avons également pensé à utiliser cette chose pour le comportement du bot, mais nous n'avons pas eu le temps de tout tester et avons décidé de refuser cette chose. De plus, nous avons décidé de mettre des émoticônes basées sur la coloration émotionnelle de la phrase, avons écrit un modèle, mais n'avons pas trouvé un ensemble de données approprié, et celles qui ont été utilisées ne sont pas un peu à ce sujet.

Notre équipe.
Même si votre modèle principal, que vous espérez, ne peut pas l'écrire ou donne un mauvais résultat, n'abandonnez pas immédiatement, vous devez essayer des choses plus simples, ce qui est tout à fait naturel. Et la deuxième chose, parfois cela vaut la peine de regarder ce que votre modèle manque et de penser à des tâches spécifiques, de les décomposer et de résoudre des problèmes spécifiques, ce que nous avons fait. Merci de votre attention.
Sergey Kolesnikov:
- Je m'appelle Sergey Kolesnikov, je représenterai la décision de Tensorborne.

Nous avons trouvé un beau nom, sommes allés au concours, avons trouvé beaucoup de morceaux différents pour sortir deux articles après cela, mais n'avons pas gagné le hackathon. Par conséquent, il sera appelé: "Comment ne pas gagner le hackathon, mais toujours publier les putains de deux articles." Universitaires, monsieur.
Les caractéristiques du concours auquel nous avons participé ont dépassé notre motivation. En raison du fait que l'évaluation a été effectuée quotidiennement, les forfaits devaient également être faits quotidiennement et la récompense finale a été déterminée, comme nous le voulons dans RL, par sommation à prix réduit. Tout cela est devenu le fait que nous devions envoyer au moins quelque chose chaque jour pour que cela fonctionne, et nous avons obtenu au moins une sorte de score. En conséquence, cela est devenu ce que vous voulez - vous ne voulez pas, mais vous avez dû ramer.
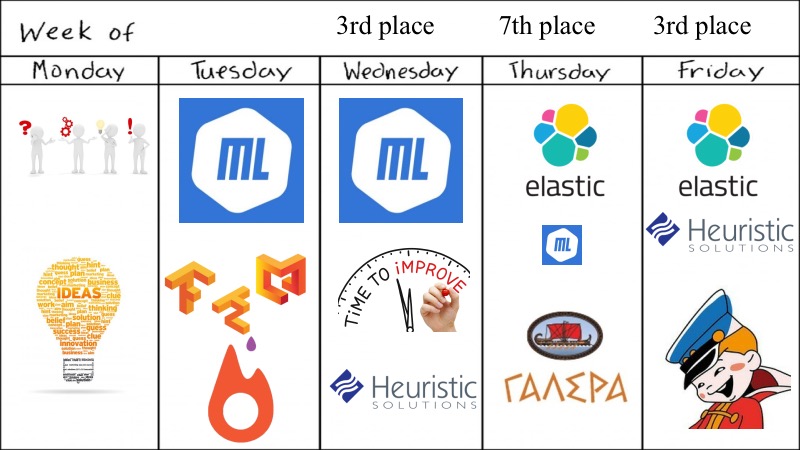
Qu'avions-nous? Aperçu pour toute la semaine.
Malgré le fait que le hackathon disait qu'il était hebdomadaire, tout a été décidé en quatre jours, ce qui ne semble pas suffisant pour cette tâche ConvAI.
Au départ, nous étions cinq, tous de bons diplômés universitaires, ou alors Fiztekh, alors lundi nous sommes venus et avons lancé beaucoup de suggestions, d'idées que vous pouvez essayer, quels modèles d'apprentissage en profondeur essayer. Certes, nous n'avons pas expérimenté avec GAN, car nous les avons déjà expérimentés pour les textes et cela ne fonctionne pas, nous avons donc pris quelque chose de plus simple, en plus, il y avait des compétitions très similaires et nous avions des modèles de pré-entraînement. Mardi, nous avons même pu lancer quelque chose sur le deep learning, ML était dans la mesure du possible, nous avons lancé de merveilleux dockers avec prise en charge GPU et d'autres choses pour Tensorflow et Keras, nous devons donner une médaille distincte pour cela, car ce n'est pas si trivial comme je voudrais.
Selon les résultats de mardi, ils étaient prometteurs, et nous avons décidé d'améliorer légèrement notre ML avec de petites heuristiques et autres, et avons échoué à la septième place. Mais grâce à nos coéquipiers, quelqu'un a trouvé ElasticSearch et l'a essayé. Il y a eu un moment très gênant où ElasticSearch a bien fonctionné, et les modèles DL et ML, et ainsi de suite, étaient un peu moins robustes. La fin du concours était proche. Et comme l'a noté l'orateur précédent, nous avons décidé de pagayer dans la direction qui fonctionne. Nous avons pris ElasticSearch, de petites heuristiques et avons pensé que c'était assez bon, et vraiment assez bon, parce que nous avons pris la deuxième place.
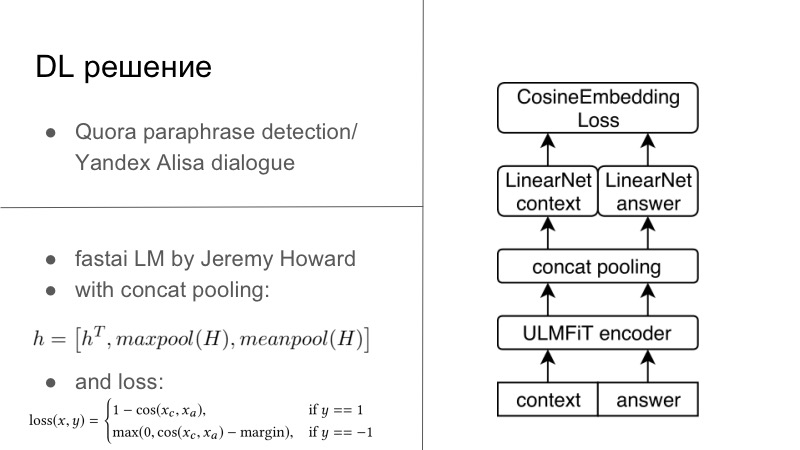
Plus de détails. En fait, il y avait plusieurs solutions DL. La première solution DL était assez simple. Qui se souvient, l'année précédente ou l'année dernière, il y avait un concours de détection de paraphrase Quora, et cette année il y avait un concours de Yandex pour Alice pour construire des dialogues et plus encore. Vous remarquerez peut-être que les tâches y sont très proches. Dans le premier, il fallait dire si ces deux phrases étaient des paraphrases, et dans le second, il fallait poursuivre le dialogue. Nous pensions que puisque nous développons des systèmes de dialogue, continuons aussi bien le dialogue. Et cela a parfaitement fonctionné, le dialogue avec Quora était très personnel.
Fondamentalement, tout semblait avoir un encodeur, généralement nous nous entraînons tous sur nos RNN habituels, et de préférence LSTM avec attention et d'autres choses. Et ensuite, nous avons généralement utilisé soit la perte d'inclusion Cosaine, présentée sur la diapositive ci-dessous, soit une autre perte d'intégration du type Tripler Loss ou quelque chose d'autre qui incorpore des paraphrases ou des réponses à un dialogue spécifique, et non des retards de paraphrases, etc. C'était la première solution, c'était sur Tensorflow, Keras, c'était prêt, nous l'avons essayé, et c'était plutôt bien.
Une autre solution est née en un jour deux hackathons en soirée. Il y a un gars formidable Jeremy Howard, il fait la promotion du DL et du ML pour tout le monde, il a deux merveilleux cours qui vous présentent le cours de cette entreprise et d'autres choses, et pour ce cours, il a écrit son FastAI. Tout cela fonctionne sur PyTorch, et à bien des égards même réécrit PyTorch, c'est l'un des inconvénients de cette bibliothèque. Mais des pros, Jeremy n'a pas grand-chose à voir avec la PNL, cette année en mars avec un autre étudiant, ils ont publié un article où ils ont enseigné le LSTM sur toutes les meilleures pratiques dans le merveilleux FastAI, avec de nombreuses astuces qu'il promeut dans son cours, et a obtenu SOTA pratiquement pour tout.
Étant donné que je suis un petit évangéliste de PyTorch, j'ai toujours été en mesure de déraciner ce modèle de FastAI, de le pousser, vous pouvez déjà le dire, dans mon cadre PyTorch, et même d'entraîner le tout pour cette tâche. Fondamentalement, nous avions un certain contexte de dialogue, en fait, même si nous avions plusieurs phrases, vous les concaténiez simplement en une phrase lourde. answer, . FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

Exemples. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! Sérieusement.
Vous n'avez même pas besoin d'utiliser vos modèles pré-formés. Commencer par les lignes de base est probablement mieux.Et bien sûr, prenez des vacances de hackathon. Lorsque vous participez à un hackathon hebdomadaire et travaillez en même temps, c'est mauvais. Vous arrivez à 19 heures, après avoir travaillé un peu, asseyez-vous et compilez Docker avec TensorFlow, Keras, pour que tout cela commence sur certains serveurs distants auxquels vous n'avez même pas accès. Quelque part en deux nuits, vous attrapez la catharsis, et cela fonctionne pour vous - sans Docker, sans tout, parce que vous avez compris que c'est possible et ainsi.Il semble que si vous participez à une grande compétition, allouez-y un peu plus de temps que ce que vous ne pouvez pas dormir en une semaine et participez. Allez gagner. Je vous remercie!