Lors de la présentation de NVIDIA SIGGRAPH 2018, le PDG de la société, Jensen Juan, a officiellement dévoilé l'architecture GPU Turing tant attendue (et rumeur et spéculation). La prochaine génération de GPU NVIDIA, Turing, inclura un certain nombre de nouvelles fonctionnalités et verra le monde plus tard cette année. Bien que la visualisation professionnelle (ProViz) ait été au centre des annonces d'aujourd'hui, nous nous attendons à ce que la nouvelle architecture soit utilisée dans d'autres produits NVIDIA à venir. La revue d'aujourd'hui n'est pas seulement une liste de toutes les fonctionnalités de Turing.

Rendu hybride et réseaux de neurones: noyaux RT et tenseur
Alors, quelle est la particularité et la nouveauté de l'architecture Turing? Marquee, au moins pour la communauté NVIDIA ProViz, est conçu pour le rendu hybride, qui combine le lancer de rayons avec la pixellisation traditionnelle.

Changement majeur: NVIDIA a inclus encore plus d'équipements de traçage de rayons dans Turing pour offrir le traçage de rayons accéléré matériel le plus rapide. Une nouveauté pour l'architecture de Turing est l'unité informatique spécialisée RT Core, comme l'appelle NVIDIA, actuellement il n'y a pas assez d'informations à ce sujet, on sait seulement que sa fonction est la prise en charge du lancer de rayons. Ces unités de traitement accélèrent à la fois la vérification de l'intersection des rayons et des triangles, ainsi que la manipulation des BVH (hiérarchies des volumes englobants).
NVIDIA affirme que les composants de Turing les plus rapides peuvent compter 10 milliards (Giga) de rayons par seconde, ce qui, comparé au Pascal non accéléré, représente une amélioration de 25 fois des performances de traçage des rayons.
L'architecture de Turing comprend des noyaux de tenseurs Volta qui ont été renforcés. Les noyaux tenseur sont un aspect important de plusieurs initiatives NVIDIA. Parallèlement à l'accélération du traçage des rayons, un outil important dans le «sac magique» NVIDIA est de réduire le nombre de rayons requis dans la scène en utilisant la réduction du bruit AI pour effacer l'image, ici les noyaux tensoriels font mieux. Bien sûr, ce n'est pas le seul domaine où ils sont bons - tous les réseaux de neurones et les empires d'IA de NVIDIA sont construits sur eux.
Turing se caractérise par la prise en charge d'une plus grande plage de précision, ce qui signifie la possibilité d'une accélération significative des charges de travail qui n'ont pas d'exigences de précision élevées. En plus du mode de précision Volta FP16, les noyaux tenseurs de Turing prennent en charge INT8 et même INT4. Ceci est 2 et 4 fois plus rapide que FP16, respectivement. Bien que NVIDIA ne veuille pas entrer dans les détails lors de la présentation, je suggère qu'ils implémentent quelque chose de similaire à l'empaquetage de données, qui est utilisé pour les opérations de faible précision sur les cœurs CUDA. Malgré la précision réduite du réseau neuronal (le retour est réduit - selon INT4, nous n'obtenons que 16 (!) Valeurs) - certains modèles ont vraiment besoin de ce faible niveau de précision. En conséquence, les modes de précision réduits afficheront un bon débit, en particulier dans les tâches de sortie, ce qui plaira sans aucun doute à certains utilisateurs.
En revenant au rendu hybride en général, il est intéressant de noter que malgré ces grandes accélérations individuelles, la promesse globale de NVIDIA de gains de performances semble un peu plus modeste. Bien que l'entreprise promette d'augmenter la productivité de 6 fois par rapport à Pascal, il est temps de demander quelles pièces sont accélérées, et en comparaison avec lesquelles. Le temps nous le dira.
Parallèlement, afin de mieux utiliser les noyaux tensoriels en dehors du ray tracing et des tâches d'apprentissage approfondi étroitement ciblées, NVIDIA déploiera un SDK, NVIDIA NGX, qui permettra l'intégration de réseaux de neurones dans le traitement d'images. NVIDIA prévoit l'utilisation de réseaux de neurones et de cœurs tenseurs pour le traitement d'images et de vidéos supplémentaires, y compris des méthodes telles que le prochain Deep-Anti-Aliasing (DLAA).
Turing SM: cœurs INT dédiés, cache unique, ombrage à débit variable
Avec les noyaux RT et tensoriels, l'architecture Turing Streaming Multiprocessor (SM) elle-même introduit de nouvelles astuces. En particulier, l'un des derniers changements de Volta a été hérité, à la suite duquel les cœurs Integer sont alloués dans leurs propres blocs et ne font pas partie des cœurs à virgule flottante CUDA. L'avantage est une génération d'adresse plus rapide et des performances Fused Multiply Add (FMA).
Quant à ALU (j'attends toujours la confirmation de Turing) - support pour des opérations plus rapides avec une faible précision (par exemple, FP16 rapide). À Volta, cela est mis en œuvre comme des opérations de FP16 à double fréquence par rapport à FP32 et des opérations INT8 à 4x. Les noyaux tenseur prennent déjà en charge ce concept, il serait donc logique de le transférer vers les noyaux CUDA.
Fast FP16, la technologie Rapid Packed Math et d'autres moyens de regrouper plusieurs petites opérations en une seule grande opération sont tous des éléments clés de l'amélioration des performances du GPU à un moment où la loi de Moore ralentit.
En utilisant des types de données volumineux (exacts) uniquement lorsque cela est nécessaire, ils peuvent être regroupés pour effectuer plus de travail dans la même période. Ceci est principalement important pour la sortie des réseaux de neurones, ainsi que pour le développement de jeux. Le fait est que tous les programmes de shader n'ont pas besoin de précision FP32, et la réduction de la précision peut améliorer les performances et réduire la bande passante mémoire utile et l'utilisation du fichier de registre.
Turing SM inclut quelque chose que NVIDIA appelle «l'architecture de cache unifiée». Comme j'attends toujours des diagrammes SMID officiels de NVIDIA, il n'est pas clair s'il s'agit de la même unification que nous avons vue avec Volta - où le cache L1 a été combiné avec la mémoire partagée - ou NVIDIA est allé plus loin. Dans tous les cas, NVIDIA prétend avoir maintenant offert deux fois plus de bande passante par rapport à la «génération précédente», mais on ne sait pas si cela signifie «Pascal» ou «Volta» (ce dernier est plus probable).
Enfin, profondément caché dans le communiqué de presse de Turing, il a été fait mention du support de l'ombrage à taux variable. Il s'agit d'une technologie de rendu graphique relativement jeune et évolutive, sur laquelle il existe peu d'informations (en particulier sur la façon dont elle est implémentée par NVIDIA). Mais à un niveau d'abstraction très élevé, cela ressemble à «la technologie de prochaine génération de NVIDIA qui vous permet d'appliquer un ombrage avec différentes résolutions, ce qui permet aux développeurs d'afficher différentes zones de l'écran à différentes résolutions efficaces pour la qualité de concentration (et le temps de rendu) dans les zones où cela est le plus nécessaire» .
Nourrir la bête: prise en charge de GDDR6
La mémoire utilisée par les GPU étant développée par des sociétés tierces, il n'y a pas de secret. JEDEC et son grand Samsung à 3 membres, SK Hynix et Micron développent la mémoire GDDR6 en tant que successeur de GDDR5 et GDDR5X. NVIDIA a confirmé que Turing le soutiendrait. Selon le fabricant, la première génération de GDDR6 est annoncée comme ayant une bande passante mémoire allant jusqu'à 16 Gb / s par bus, soit deux fois plus que les cartes NVIDIA GDDR5 de dernière génération, et 40% plus rapide que les dernières cartes NVIDIA GDDR5X.
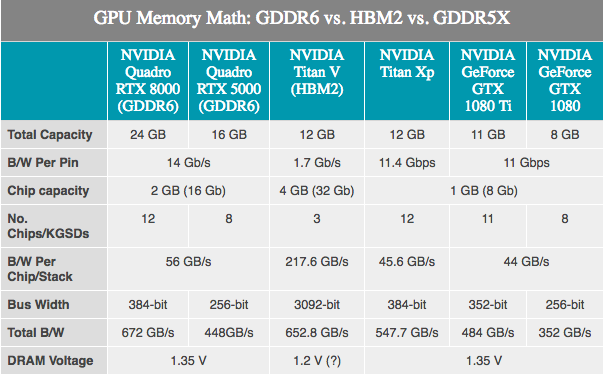
Comparé au GDDR5X, le GDDR6 ne ressemble pas à une percée majeure, car de nombreuses innovations du GDDR6 ont déjà été appliquées au GDDR5X. Les changements fondamentaux incluent ici des tensions de fonctionnement plus faibles (1,35 V), et la mémoire interne est maintenant divisée: deux canaux de mémoire par microcircuit. Pour une puce standard de 32 bits - deux canaux de mémoire de 16 bits, nous avons au total 16 de ces canaux sur une carte de 256 bits. Bien que cela, à son tour, indique qu'il existe un très grand nombre de canaux, les GPU bénéficieront au maximum de l'innovation, car ils sont historiquement les appareils les plus «parallèles».

NVIDIA, pour sa part, a confirmé que les premières cartes Turing Quadro utiliseront la GDDR6 à 14 Gb / s. Dans le même temps, NVIDIA a également confirmé l'utilisation de la mémoire Samsung, en particulier pour ses appareils avancés de 16 gigaoctets. Ceci est important car cela signifie qu'un GPU NVIDIA 256 bits typique peut être équipé de 8 modules standard et obtenir 16 Go de capacité de mémoire totale, voire 32 Go s'ils utilisent le mode à clapet (permet d'adresser 32 Go de mémoire sur 256 bits standard bus).
Toutes sortes de détails: NVLink, VirtualLink et 8K HEVC
Se terminant déjà par un examen de l'architecture Turing, NVIDIA a confirmé nonchalamment la prise en charge de certaines des nouvelles fonctionnalités d'E / S externes. Le support NVLink sera présent dans au moins plusieurs produits Turing. Rappelons que NVIDIA l'utilise dans les trois nouvelles cartes Quadro. NVIDIA propose une configuration GPU bidirectionnelle.
Un point important (avant qu'une partie de notre public orienté jeu ne se lance dans la lecture): la présence de NVLink dans l'équipement Turing ne signifie pas qu'il sera utilisé dans les cartes vidéo grand public. Peut-être que tout sera limité aux cartes Quadro et Tesla.
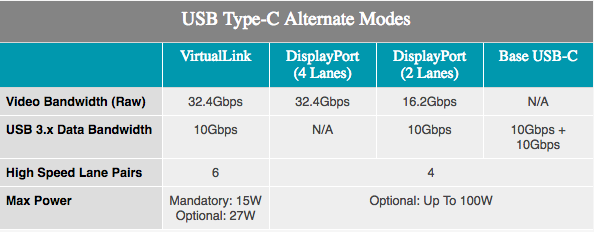
Avec l'ajout de la prise en charge de VirtualLink, les lecteurs et utilisateurs ProViz auront ce à quoi s'attendre de la réalité virtuelle. Un autre mode USB Type-C a été annoncé le mois dernier et prend en charge une puissance de 15 W +, un transfert de données de 10 Gb / s grâce à l'USB 3.1 Gen 2, 4 bandes DisplayPort HBR3 sur un seul câble. En d'autres termes, il s'agit d'une connexion DisplayPort 1.4 avec des données et une alimentation supplémentaires. Cela permet à la carte vidéo de contrôler directement le casque VR. La norme est prise en charge par NVIDIA, AMD, Oculus, Valve et Microsoft, de sorte que les produits Turing seront les premiers d'un certain nombre de produits qui prendront en charge la nouvelle norme.
Bien que NVIDIA n'ait abordé que très peu le sujet, nous savons que le codeur vidéo NVENC a été mis à jour dans Turing. La dernière itération NVENC ajoute un support d'encodage HEKC 8K spécial. Pendant ce temps, NVIDIA a pu améliorer la qualité de son encodeur, lui permettant d'atteindre la même qualité qu'auparavant, avec un débit vidéo inférieur de 25%.
Indicateurs de performance
Parallèlement aux spécifications matérielles annoncées, NVIDIA présente plusieurs chiffres de performances des équipements Turing. Il convient de noter que nous en savons très, très peu ici. Les composants sont apparemment basés sur les SKU Turing entièrement et partiellement inclus avec 4608 noyaux CUDA et 576 noyaux tensoriels. Les fréquences n'ont pas été divulguées, cependant, puisque ces chiffres sont profilés pour le matériel Quadro, nous verrons probablement des vitesses d'horloge inférieures à celles de tout équipement grand public.

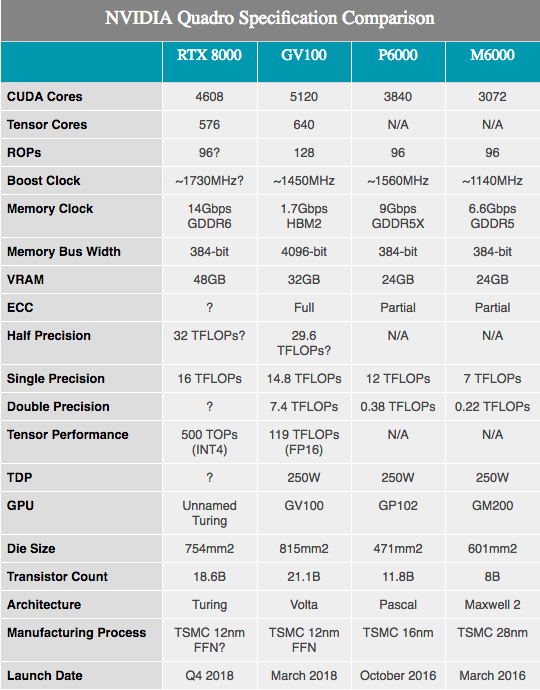
Avec les 10 GigaRays / sec susmentionnés pour les cœurs RT, les performances des cœurs de tenseurs NVIDIA sont de 500 billions d'opérations de tenseur par seconde (500T TOP). Pour référence, NVIDIA mentionne souvent le GPU GV100 comme capable de fournir un maximum de 120T TOP, mais ce n'est pas la même chose. En particulier, alors que le GV100 est mentionné dans le traitement des opérations FP16, les performances de Turing sont citées avec une précision extrêmement faible INT4, qui ne représente qu'un quart de la taille de FP16 et, par conséquent, augmente le débit quatre fois. Si nous normalisons la précision, les noyaux tensoriels de Turing ne semblent pas avoir le meilleur débit par cœur, mais offrent plutôt plus d'options de précision que Volta. Dans tous les cas, 576 cœurs tenseurs dans cette puce la mettent presque à égalité avec le GV100, qui en compte 640.
Concernant les cœurs CUDA, NVIDIA affirme que le GPU Turing peut offrir 16 performances TFLOPS. Ceci est légèrement en avance sur les performances de 15 TFLOPS avec la précision simple du Tesla V100, ou encore plus en avance sur les 13,8 TFLOPS de Titan V.Si vous recherchez des informations plus conviviales, c'est environ 32% de plus que le Titan Xp. Après avoir esquissé quelques calculs approximatifs sur papier, nous pouvons supposer la vitesse d'horloge du GPU d'environ 1730 MHz, étant donné qu'au niveau SM, il n'y a eu aucun changement supplémentaire qui changerait les formules de performance ALU traditionnelles.
Pendant ce temps, NVIDIA a annoncé que les cartes Quadro seront livrées avec une mémoire GDDR6 fonctionnant à 14 Gb / s. Et en regardant les deux meilleures SKU Quadro offrant respectivement 48 Go et 24 Go GDDR6, nous voyons presque le bus mémoire 384 bits sur ce GPU Turing. En ce qui concerne les chiffres, cela équivaut à 672 Go / s de bande passante mémoire pour les deux cartes Quadro haut de gamme.
Sinon, avec un changement d'architecture, il est difficile de faire de nombreuses comparaisons de performances utiles, surtout lors de la comparaison avec Pascal. D'après ce que nous avons vu avec Volta, les performances globales de NVIDIA se sont améliorées, en particulier dans les charges de travail informatiques bien conçues. Ainsi, une amélioration d'environ 33% des performances du papier par rapport au Quadro P6000 pourrait bien être quelque chose de beaucoup plus important.
Je mentionnerai la taille cristalline du nouveau GPU. Situé sur 754 mm2, ce n'est pas seulement grand, c'est énorme. Par rapport aux autres GPU, seul le NVIDIA GV100 est le deuxième en taille, qui reste actuellement le fleuron de NVIDIA. Mais avec 18,6 milliards de transistors, il est facile de voir pourquoi la puce résultante devrait être si grosse. Apparemment, NVIDIA a de grands projets pour ce GPU, qui à terme pourra justifier la présence de deux énormes processeurs graphiques dans sa pile de produits.
NVIDIA, pour sa part, n'a pas indiqué de numéro de modèle spécifique pour ce GPU - qu'il s'agisse d'un GPU traditionnel de classe 102 ou même de classe 100. Je me demande si nous verrons une modification de ce type de GPU pour un produit de consommation sous une forme ou une autre; il est si grand que NVIDIA souhaitera peut-être le conserver pour ses GPU Quadro et Tesla plus rentables.
Publié au quatrième trimestre de 2018, sinon plus tôt
En conclusion, je dirai qu'avec l'annonce de l'architecture Turing, NVIDIA a annoncé que les 4 premières cartes Quadro basées sur les GPU Turing - Quadro RTX 8000, RTX 6000 et RTX 5000 commenceront à être livrées au quatrième trimestre de cette année. Étant donné que la nature même de cette annonce est quelque peu inversée - généralement NVIDIA annonce d'abord les composants grand public - je n'appliquerais pas la même chronologie aux cartes grand public qui n'ont pas des exigences de validation aussi strictes. Nous verrons de l'équipement Turing au quatrième trimestre de cette année, sinon plus tôt. Ceux qui veulent acheter Quadro peuvent commencer à économiser de l'argent dès maintenant: le meilleur des nouvelles cartes Quadro RTX 8000 vous coûtera environ 10000 $.
Enfin, pour les consommateurs avec Tesla de NVIDIA, le lancement du Turing laisse Volta dans les limbes. NVIDIA ne nous a pas dit si Turing allait éventuellement s'étendre dans l'espace haut de gamme de Tesla - en remplacement du GV100 - ou si leur meilleur processeur Volta resterait le maître de son domaine pendant des siècles. Cependant, puisque les autres cartes Tesla ont jusqu'à présent été basées sur Pascal, elles sont les premières candidates à l'éviction de Turing en 2019.
Merci de rester avec nous. Aimez-vous nos articles? Vous voulez voir des matériaux plus intéressants? Soutenez-nous en passant une commande ou en le recommandant à vos amis, une
réduction de 30% pour les utilisateurs Habr sur un analogue unique de serveurs d'entrée de gamme que nous avons inventés pour vous: Toute la vérité sur VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbps à partir de 20 $ ou comment diviser le serveur? (les options sont disponibles avec RAID1 et RAID10, jusqu'à 24 cœurs et jusqu'à 40 Go de DDR4).
VPS (KVM) E5-2650 v4 (6 cœurs) 10 Go DDR4 240 Go SSD 1 Gbit / s jusqu'en décembre gratuitement en payant pour une période de six mois, vous pouvez commander
ici .
Dell R730xd 2 fois moins cher? Nous avons seulement
2 x Intel Dodeca-Core Xeon E5-2650v4 128 Go DDR4 6x480 Go SSD 1 Gbps 100 TV à partir de 249 $ aux Pays-Bas et aux États-Unis! Pour en savoir plus sur la
création d'un bâtiment d'infrastructure. classe utilisant des serveurs Dell R730xd E5-2650 v4 coûtant 9 000 euros pour un sou?