L'introduction de l'IA au niveau de la puce vous permet de traiter plus de données localement, car une augmentation du nombre d'appareils ne donne plus le même effet
Les fabricants de puces travaillent sur de nouvelles architectures qui augmentent considérablement la quantité de données traitées par watt et par cycle. Le terrain est préparé pour l'une des plus grandes révolutions de l'architecture de puces de ces dernières décennies.
Tous les principaux fabricants de puces et de systèmes changent de direction de développement. Ils sont entrés dans la course aux architectures, qui prévoit un changement de paradigme en tout: des méthodes de lecture et d'écriture à la mémoire, à leur traitement et, finalement, à la disposition de divers éléments sur une puce. Bien que la miniaturisation se poursuive, personne ne parie sur la mise à l'échelle pour faire face à la croissance explosive des données des capteurs et à l'augmentation du volume de trafic entre les machines.
Parmi les changements dans les nouvelles architectures:
- De nouvelles méthodes pour traiter une plus grande quantité de données en 1 cycle d'horloge, parfois avec moins de précision ou par priorité de certaines opérations, selon l'application.
- De nouvelles architectures de mémoire qui changent la façon dont nous stockons, lisons, écrivons et accédons aux données.
- Modules de traitement plus spécialisés situés dans tout le système près de la mémoire. Au lieu d'un processeur central, les accélérateurs sont sélectionnés en fonction du type de données et de l'application.
- Dans le domaine de l'IA, des travaux sont en cours pour combiner différents types de données sous forme de modèles, ce qui augmente efficacement la densité des données tout en minimisant les écarts entre les différents types.
- Maintenant, la disposition du boîtier est le composant principal de l'architecture, avec une attention de plus en plus grande accordée à la facilité de changer ces conceptions.
«Il existe plusieurs tendances qui affectent les avancées technologiques», a déclaré Stephen Wu, un ingénieur distingué de Rambus. - Dans les centres de données, vous tirez le meilleur parti du matériel et des logiciels. Sous cet angle, les propriétaires de centres de données envisagent l'économie. Introduire quelque chose de nouveau coûte cher. Mais les goulots d'étranglement changent, des puces spécialisées sont donc introduites pour un calcul plus efficace. Et si vous réduisez les flux de données dans les deux sens vers les E / S et la mémoire, cela peut avoir un impact important. »
Les changements sont plus évidents au bord de l'infrastructure informatique, c'est-à-dire parmi les capteurs d'extrémité. Les fabricants ont soudain réalisé que des dizaines de milliards d'appareils généreraient trop de données: un tel volume ne pouvait pas être envoyé vers le cloud pour traitement. Mais le traitement de toutes ces données en périphérie pose d'autres problèmes: il nécessite des améliorations de performances majeures sans augmentation significative de la consommation électrique.
«Il y a une nouvelle tendance vers une précision moindre», a déclaré Robert Ober, architecte principal de la plate-forme Tesla chez Nvidia. - Ce ne sont pas seulement des cycles de calcul. Il s'agit d'un conditionnement de données plus intensif en mémoire, où le format d'instructions 16 bits est utilisé. »
Aubert estime que grâce à une série d'optimisations architecturales dans un avenir prévisible, vous pouvez doubler la vitesse de traitement tous les deux ans. "Nous verrons une augmentation spectaculaire de la productivité", a-t-il déclaré. - Pour cela, vous devez faire trois choses. Le premier est l'informatique. Le second est la mémoire. La troisième zone est la bande passante hôte et la bande passante d'E / S. Beaucoup de travail doit être fait pour optimiser le stockage et la pile réseau. »
Quelque chose est déjà en cours d'implémentation. Dans une présentation à la conférence Hot Chips 2018, Jeff Rupley, architecte en chef du Samsung Research Center de Samsung, a souligné plusieurs changements architecturaux majeurs du processeur M3. Un inclut plus d'instructions par temps - six au lieu de quatre dans la dernière puce M2. De plus, la prédiction de branchement sur les réseaux de neurones a été implémentée et la file d'attente d'instructions a été doublée.
De tels changements déplacent le point d'innovation de la fabrication directe de microcircuits à l'architecture et au design d'une part et à la disposition des éléments de l'autre côté de la chaîne de production. Bien que les innovations continuent de se poursuivre dans les processus technologiques, ce n'est qu'aux dépens de celui-ci qu'il est incroyablement difficile d'obtenir une augmentation de 15 à 20% de la productivité et de la puissance dans chaque nouveau modèle de puce - et cela ne suffit pas pour faire face à la croissance rapide du volume de données.
«Les changements ont lieu à un rythme exponentiel», a déclaré Victor Pan, président et chef de la direction de Xilinx, dans un discours à la conférence Hot Chips, «10 zettaoctets [10
21 octets] de données seront générés chaque année, et la plupart d'entre eux ne sont pas structurés.»
De nouvelles approches de la mémoire
Travailler avec autant de données nécessite de repenser chaque composant du système, des méthodes de traitement des données à leur stockage.
«Il y a eu de nombreuses tentatives pour créer de nouvelles architectures de mémoire», a déclaré Carlos Machin, directeur principal de l'innovation chez eSilicon EMEA. - Le problème est que vous devez lire toutes les lignes et sélectionner un bit dans chacune. Une option consiste à créer une mémoire qui peut être lue de gauche à droite, ainsi que de haut en bas. Vous pouvez aller encore plus loin et ajouter du calcul à la mémoire. »
Ces changements comprennent la modification des méthodes de lecture de la mémoire, l'emplacement et le type des éléments de traitement, ainsi que l'introduction de l'IA pour prioriser le stockage, le traitement et le mouvement des données dans tout le système.
«Et si, dans le cas de données éparses, nous ne pouvons lire qu'un octet de ce tableau à la fois - ou peut-être huit octets consécutifs du même chemin d'octets sans gaspiller d'énergie sur d'autres octets ou chemins d'octets qui ne nous intéressent pas ? "Demande Mark Greenberg, directeur du marketing produit Cadence." - À l'avenir, cela est possible. Si vous regardez l'architecture de HBM2, par exemple, la pile est organisée en 16 canaux virtuels de 64 bits chacun, et vous n'avez besoin que de 4 mots 64 bits consécutifs pour accéder à n'importe quel canal virtuel. Ainsi, il est possible de créer des tableaux de données d'une largeur de 1024 bits, d'écrire horizontalement, mais de lire verticalement quatre mots de 64 bits à la fois. "
La mémoire est l'un des principaux composants de l'architecture de von Neumann, mais maintenant elle est également devenue l'un des principaux domaines d'expérimentation. «L'ennemi principal est les systèmes de mémoire virtuelle, où les données sont déplacées de manière plus artificielle», a déclaré Dan Bouvier, architecte en chef des produits clients chez AMD. - Ceci est une émission diffusée. Nous sommes habitués à cela dans le domaine du graphisme. Mais si nous résolvons les conflits dans la banque de mémoire DRAM, nous obtenons un streaming beaucoup plus efficace. Un GPU séparé peut alors utiliser la DRAM dans une plage d'efficacité de 90%, ce qui est très bon. Mais si vous configurez le streaming sans interruption, le CPU et l'APU tomberont également dans la plage d'efficacité de 80% à 85%. »
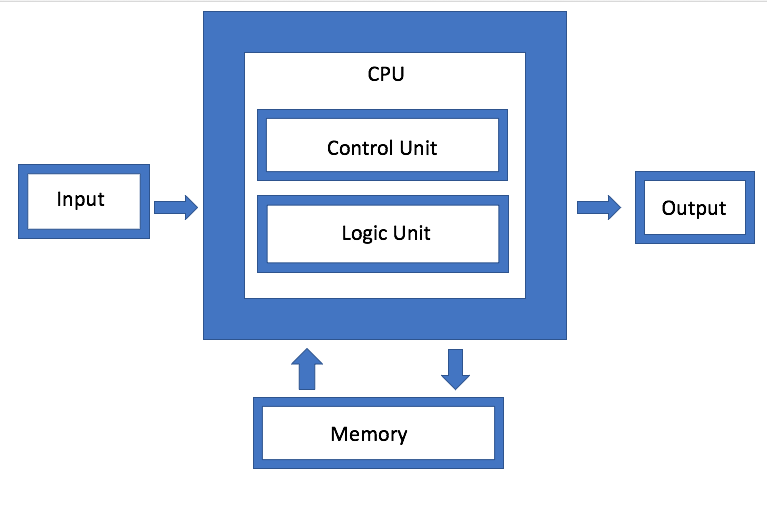 Fig. 1. Architecture von Neumann. Source: Ingénierie des semi-conducteurs
Fig. 1. Architecture von Neumann. Source: Ingénierie des semi-conducteursIBM développe un type différent d'architecture de mémoire, qui est essentiellement une version mise à niveau de l'agrégation de disques. L'objectif est qu'au lieu d'utiliser un seul lecteur, le système puisse utiliser arbitrairement toute la mémoire disponible via un connecteur, que Jeff Stucheli, architecte matériel IBM, appelle le "Swiss Army Knife" pour connecter les éléments. L'avantage de l'approche est qu'elle vous permet de mélanger et de faire correspondre différents types de données.
«Le processeur devient le centre d'une interface de signalisation haute performance», explique Stucelli. «Si vous modifiez la microarchitecture, le cœur effectue plus d'opérations par cycle à la même fréquence.»
La connectivité et le débit doivent garantir le traitement d'un volume radicalement accru de données générées. "Les principaux goulots d'étranglement se trouvent maintenant dans les emplacements de déplacement des données", a déclaré Wu de Rambus. "L'industrie a fait un excellent travail en augmentant la vitesse de l'informatique." Mais si vous attendez des données ou des modèles de données spécialisés, vous devez exécuter la mémoire plus rapidement. Ainsi, si vous regardez la DRAM et la NVM, les performances dépendent du modèle de trafic. Si les données sont en streaming, la mémoire offrira de très bonnes performances. Mais si les données arrivent par gouttes aléatoires, elles sont moins efficaces. Et peu importe ce que vous faites, avec une augmentation de volume, vous devez toujours le faire plus rapidement. »
Plus d'informatique, moins de trafic.
Le problème est aggravé par le fait qu'il existe plusieurs types différents de données générées à différentes fréquences et vitesses par des dispositifs en périphérie. Pour que ces données puissent circuler librement entre différents modules de traitement, la gestion doit devenir beaucoup plus efficace que par le passé.
«Il existe quatre configurations principales: plusieurs-à-plusieurs, des sous-systèmes de mémoire, des E / S basse consommation et des grilles et topologies en anneau», explique Charlie Janak, président-directeur général d'Arteris IP. - Vous pouvez placer les quatre sur une puce, ce qui se produit avec les puces IoT clés. Ou vous pouvez ajouter des sous-systèmes HBM à haut débit. Mais la complexité est énorme, car certaines de ces charges de travail sont très spécifiques et la puce a plusieurs tâches différentes. Si vous regardez certaines de ces micropuces, elles obtiennent d'énormes quantités de données. C'est dans des systèmes tels que les radars et les lidars de voiture. Ils ne peuvent exister sans certaines interconnexions avancées. »
La tâche est de savoir comment minimiser le mouvement des données, mais en même temps maximiser le flux de données lorsque cela est nécessaire - et trouver en quelque sorte un équilibre entre le traitement local et centralisé sans augmenter inutilement la consommation d'énergie.
«D'une part, il s'agit d'un problème de bande passante», a déclaré Rajesh Ramanujam, responsable du marketing produit pour NetSpeed Systems. - Vous voulez réduire le trafic autant que possible, alors transférez les données plus près du processeur. Mais si vous avez encore besoin de déplacer les données, il est conseillé de les compacter autant que possible. Mais rien n'existe par lui-même. Tout doit être planifié au niveau du système. A chaque étape, plusieurs axes interdépendants doivent être considérés. Ils déterminent si vous utilisez la mémoire de la manière traditionnelle de lecture et d'écriture, ou si vous utilisez de nouvelles technologies. Dans certains cas, vous devrez peut-être modifier la façon dont vous stockez les données elles-mêmes. Si vous avez besoin de performances supérieures, cela signifie généralement une augmentation de la surface de la puce, ce qui affecte la dissipation thermique. Et maintenant, compte tenu de la sécurité fonctionnelle, la surcharge de données ne peut pas être autorisée. »
C'est pourquoi tant d'attention est accordée au traitement des données à la périphérie et à la bande passante du canal par divers modules de traitement des données. Mais au fur et à mesure que vous développez différentes architectures, la manière et le lieu de mise en œuvre de ce traitement de données sont très différents.
Par exemple, Marvell a introduit un contrôleur SSD avec IA intégrée pour gérer la lourde charge de calcul en périphérie. Le moteur AI peut être utilisé pour l'analyse directement à l'intérieur du disque SSD.
«Vous pouvez charger des modèles directement dans le matériel et effectuer le traitement matériel sur le contrôleur SSD», a déclaré Ned Varnitsa, ingénieur en chef de Marvell. - Aujourd'hui, il rend le serveur dans le cloud (hôte). Mais si chaque disque envoie des données vers le cloud, cela créera une énorme quantité de trafic réseau. Il est préférable de faire le traitement en périphérie, et l'hôte émet uniquement une commande, qui n'est que des métadonnées. Plus vous avez de disques, plus la puissance de traitement est importante. Il s'agit d'un énorme avantage de la réduction du trafic. "
Cette approche est particulièrement intéressante car elle s'adapte à différentes données selon l'application. Ainsi, l'hôte peut générer une tâche et l'envoyer au périphérique de stockage pour traitement, après quoi seuls les métadonnées ou les résultats des calculs sont renvoyés. Dans un autre scénario, un périphérique de stockage peut stocker des données, les prétraiter et générer des métadonnées, des balises et des index, qui sont ensuite récupérés par l'hôte au besoin pour une analyse plus approfondie.
C'est l'une des options possibles. Il y en a d'autres. Rupli de Samsung a souligné l'importance du traitement et de la fusion des idiomes qui peuvent décoder deux instructions et les combiner en une seule opération.
L'IA s'occupe du contrôle et de l'optimisation
À tous les niveaux d'optimisation, l'intelligence artificielle est utilisée - c'est l'un des éléments vraiment nouveaux de l'architecture de la puce. Au lieu de permettre au système d'exploitation et au middleware de gérer les fonctions, cette fonction de surveillance est répartie sur la puce, entre les puces et au niveau du système. Dans certains cas, des réseaux de neurones matériels sont introduits.
«Il ne s'agit pas tant de rassembler davantage, mais de changer l'architecture traditionnelle», explique Mike Gianfanya, vice-président du marketing, eSilicon. - Avec l'aide de l'IA et de l'apprentissage automatique, vous pouvez distribuer des éléments à travers le système, obtenant un traitement plus efficace avec les prévisions. Ou vous pouvez utiliser des puces distinctes qui fonctionnent indépendamment dans le système ou dans le module. »
ARM a développé sa première puce d'apprentissage automatique, qu'elle prévoit de publier plus tard cette année pour plusieurs marchés. «Il s'agit d'un nouveau type de processeur», a déclaré Ian Bratt, ingénieur émérite d'ARM. - Il comprend un bloc fondamental - c'est un moteur informatique, ainsi qu'un moteur MAC, un moteur DMA avec un module de contrôle et un réseau de diffusion. Au total, 16 cœurs de calcul sont fabriqués à l'aide de la technologie de traitement à 7 nm, qui produisent 4 TeraOps à une fréquence de 1 GHz. »
Comme ARM fonctionne avec un écosystème partenaire, sa puce est plus polyvalente et personnalisable que les autres puces AI / ML en cours de développement. Au lieu d'une structure monolithique, il sépare le traitement par fonction, de sorte que chaque module informatique fonctionne sur une carte d'entités distincte. Bratt a identifié quatre ingrédients clés: la planification statique, le pliage efficace, les mécanismes de rétrécissement et l'adaptation programmée aux futurs changements de conception.
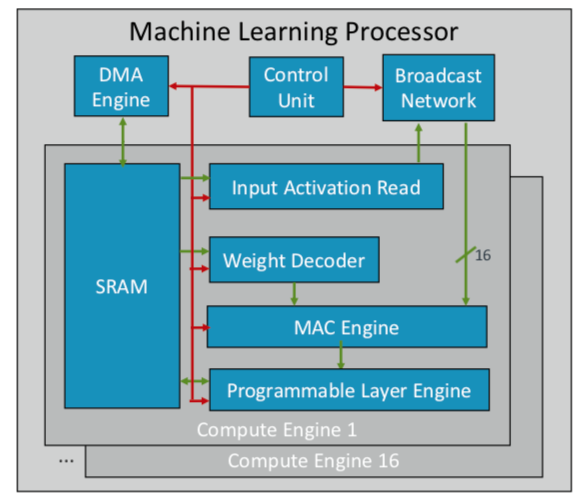 Fig. 2. Architecture ML du processeur ARM. Source: ARM / Hot Chips
Fig. 2. Architecture ML du processeur ARM. Source: ARM / Hot ChipsPendant ce temps, Nvidia a choisi une tactique différente: créer un moteur dédié d'apprentissage en profondeur à côté du GPU pour optimiser le traitement d'image et de vidéo.
Conclusion
En utilisant certaines ou toutes ces approches, les fabricants de puces s'attendent à doubler leurs performances tous les deux ans, en suivant une croissance explosive des données, tout en restant dans le cadre serré des budgets de consommation d'énergie. Mais ce n'est pas seulement plus informatique. Il s'agit d'un changement dans la plate-forme de conception de puces et de systèmes, lorsque le volume croissant de données, plutôt que les limitations matérielles et logicielles, devient le principal facteur.
«Lorsque les ordinateurs sont apparus dans les entreprises, il semblait à beaucoup que le monde autour de nous s'était accéléré», a déclaré Aart de Gues, président et chef de la direction de Synopsys. - Ils ont fait des comptes sur des morceaux de papier avec des piles de livres. Le grand livre s'est transformé en une pile de cartes perforées pour l'impression et l'informatique. Un énorme changement s'est produit et nous le voyons à nouveau. Avec l'avènement mental des simples ordinateurs de calcul, l'algorithme des actions n'a pas changé: vous pouvez tracer chaque étape. Mais maintenant, quelque chose d'autre se produit qui pourrait conduire à une nouvelle accélération. C’est comme sur un champ agricole d’inclure l’arrosage et d’appliquer un certain type d’engrais seulement un certain jour, lorsque la température atteint le niveau souhaité. Cette utilisation du machine learning est une optimisation qui n'était pas évidente dans le passé. »
Il n'est pas seul dans cette appréciation. «Les nouvelles architectures seront adoptées», a déclaré Wally Raines, président et chef de la direction de Mentor, Siemens Business. - Ils seront conçus. L'apprentissage automatique sera utilisé dans de nombreux cas ou dans la plupart des cas, car votre cerveau apprend de sa propre expérience. J'ai visité 20 entreprises ou plus qui développent des processeurs d'IA spécialisés d'un type ou d'un autre, et chacun d'eux a sa propre petite niche. Mais vous verrez de plus en plus leur application dans des applications spécifiques, et ils compléteront l'architecture traditionnelle de von Neumann. L'informatique neuromorphique deviendra courante. Il s'agit d'une grande étape dans l'efficacité informatique et la réduction des coûts. Les appareils mobiles et les capteurs commenceront à faire le travail que les serveurs font aujourd'hui. »