Remarque perev. : Cet article a été écrit par Javier Salmeron, un ingénieur de la célèbre communauté Kubernetes de Bitnami, et publié sur le blog de la CNCF début août. L'auteur parle des principes de base du mécanisme RBAC (contrôle d'accès basé sur les rôles) qui est apparu dans Kubernetes il y a un an et demi. Le matériel sera particulièrement utile pour ceux qui connaissent le dispositif des composants clés des K8 (voir les liens vers d'autres articles similaires à la fin).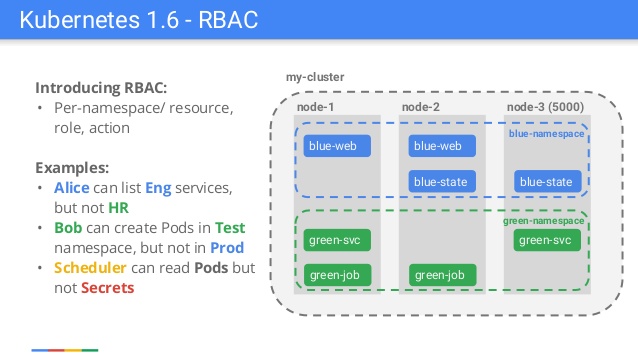 Diapositive d'une présentation faite par un employé de Google à l'occasion de la sortie de Kubernetes 1.6
Diapositive d'une présentation faite par un employé de Google à l'occasion de la sortie de Kubernetes 1.6De nombreux utilisateurs expérimentés de Kubernetes se souviennent de la version de Kubernetes 1.6, lorsque l'autorisation basée sur le contrôle d'accès basé sur les rôles (RBAC) est devenue bêta. Un mécanisme d'authentification alternatif est donc apparu, qui complétait le contrôle d'accès basé sur les attributs (ABAC), déjà difficile à gérer et à comprendre. Tout le monde a accueilli avec enthousiasme la nouvelle fonctionnalité, mais en même temps, d'innombrables utilisateurs ont été déçus. StackOverflow et GitHub regorgeaient de rapports de restrictions RBAC car la plupart de la documentation et des exemples ne tenaient pas compte de RBAC (mais maintenant tout va bien). L'exemple de référence était Helm: l'exécution de
helm init +
helm install ne fonctionnait plus. Du coup, nous devions ajouter des éléments «bizarres» comme
ServiceAccounts ou
RoleBindings avant même de déployer le graphique avec WordPress ou Redis (voir les
instructions pour en savoir plus).
Laissant de côté ces premières tentatives infructueuses, on ne peut pas nier l'énorme contribution de RBAC pour transformer Kubernetes en une plate-forme prête à la production. Beaucoup d'entre nous ont réussi à jouer avec Kubernetes avec des privilèges d'administrateur complets, et nous comprenons parfaitement que dans un environnement réel, il est nécessaire:
- Avoir de nombreux utilisateurs avec des propriétés différentes qui fournissent le mécanisme d'authentification souhaité.
- Ayez un contrôle total sur les opérations que chaque utilisateur ou groupe d'utilisateurs peut effectuer.
- Ayez un contrôle total sur les opérations que chaque processus du cœur peut effectuer.
- Limitez la visibilité de certaines ressources dans les espaces de noms.
Et à cet égard, RBAC est un élément clé qui fournit des capacités indispensables. Dans l'article, nous allons rapidement passer en revue les bases
(voir cette vidéo pour plus de détails; suivez le lien du webinaire Bitnami d'une heure en anglais - environ la traduction ) et approfondissez un peu les moments les plus déroutants.
La clé pour comprendre RBAC dans Kubernetes
Pour réaliser pleinement l'idée de RBAC, vous devez comprendre que trois éléments y sont impliqués:
- Sujets - un ensemble d'utilisateurs et de processus qui souhaitent avoir accès à l'API Kubernetes;
- Ressources - Une collection d'objets API Kubernetes disponibles dans un cluster. Leurs exemples (entre autres) sont Pods , Deployments , Services , Nodes , PersistentVolumes ;
- Verbes (verbes) - un ensemble d'opérations pouvant être effectuées sur les ressources. Il existe différents verbes (obtenir, regarder, créer, supprimer, etc.), mais tous sont finalement des opérations CRUD (créer, lire, mettre à jour, supprimer).

Avec ces trois éléments à l'esprit, l'idée clé du RBAC est:
«Nous voulons connecter les sujets, les ressources API et les opérations.» En d'autres termes, nous voulons indiquer pour un
utilisateur donné quelles
opérations peuvent être effectuées sur une variété de
ressources .
Comprendre les objets RBAC dans l'API
En combinant ces trois types d'entités, les objets RBAC disponibles dans l'API Kubernetes deviennent clairs:
Roles connectent les ressources et les verbes. Ils peuvent être réutilisés pour différents sujets. Lié à un espace de noms (nous ne pouvons pas utiliser de modèles représentant plus d'un [espace de noms], mais nous pouvons déployer le même objet de rôle dans différents espaces de noms). Si vous souhaitez appliquer le rôle à l'ensemble du cluster, il existe un objet ClusterRoles similaire.RoleBindings connectent les entités d'entité restantes. En spécifiant un rôle qui lie déjà les objets API aux verbes, nous sélectionnons maintenant les sujets qui peuvent les utiliser. L'équivalent pour le niveau de cluster (c'est-à-dire sans liaison aux espaces de noms) est ClusterRoleBindings .
Dans l'exemple ci-dessous, nous donnons à l'utilisateur
jsalmeron le droit de lire, d'obtenir une liste et de créer des foyers dans l'espace de noms de
test . Cela signifie que
jsalmeron pourra exécuter ces commandes:
kubectl get pods --namespace test kubectl describe pod --namespace test pod-name kubectl create --namespace test -f pod.yaml
... mais pas comme ça:
kubectl get pods --namespace kube-system
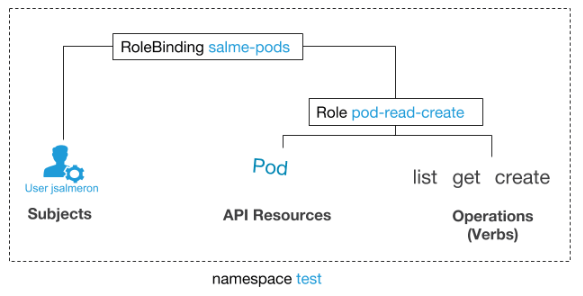
Exemples de fichiers YAML:
kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: pod-read-create namespace: test rules: - apiGroups: [""] resources: ["pods"] verbs: ["get", "list", "create"]
kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: salme-pods namespace: test subjects: - kind: User name: jsalmeron apiGroup: rbac.authorization.k8s.io roleRef: kind: Role name: pod-read-create apiGroup: rbac.authorization.k8s.io
Un autre point intéressant est le suivant: maintenant que l'utilisateur peut créer des pods, pouvons-nous en limiter le nombre? Cela nécessitera d'autres objets qui ne sont pas directement liés à la spécification RBAC et vous permettra de configurer les limites de ressources:
ResourceQuota et
LimitRanges . Ils valent vraiment la peine d'être explorés lors de la configuration d'un composant de cluster aussi important [que la création de foyers].
Sujets: Utilisateurs et ... Comptes de service?
L'une des difficultés rencontrées par de nombreux utilisateurs de Kubernetes dans le contexte des sujets est la distinction entre les utilisateurs réguliers et les
ServiceAccounts . En théorie, tout est simple:
Users - utilisateurs globaux, conçus pour des personnes ou des processus vivant en dehors du cluster;ServiceAccounts - limité par l'espace de noms et destiné aux processus du cluster s'exécutant sur des pods.
La similitude des deux types réside dans la nécessité de s'authentifier auprès de l'API pour effectuer certaines opérations sur de nombreuses ressources, et leurs sujets semblent très spécifiques. Ils peuvent également appartenir à des groupes, donc
RoleBinding permet de lier plusieurs sujets (bien qu'un seul groupe soit autorisé pour
ServiceAccounts -
system:serviceaccounts ). Cependant, la principale différence est la cause du mal de tête: les utilisateurs n'ont pas d'objets qui leur correspondent dans l'API Kubernetes. Il s'avère qu'une telle opération existe:
kubectl create serviceaccount test-service-account
... mais celui-ci est parti:
kubectl create user jsalmeron
Cette situation a une conséquence grave: si le cluster ne stocke pas d'informations sur les utilisateurs, l'administrateur devra gérer les comptes en dehors du cluster. Il existe différentes façons de résoudre le problème: certificats TLS, jetons, OAuth2, etc.
De plus, vous devrez créer des contextes
kubectl que nous puissions accéder au cluster via ces nouveaux comptes. Pour créer des fichiers avec eux, vous pouvez utiliser les commandes de
kubectl config (qui ne nécessitent pas d'accès à l'API Kubernetes, elles peuvent donc être exécutées par n'importe quel utilisateur). La vidéo ci-dessus présente un exemple de création d'un utilisateur avec des certificats TLS.
RBAC dans les déploiements: exemple
Nous avons vu un exemple dans lequel l'utilisateur spécifié se voit accorder des droits sur les opérations du cluster. Mais qu'en est-il des
déploiements nécessitant un accès à l'API Kubernetes? Envisagez un scénario spécifique pour mieux comprendre.
Prenons par exemple l'application d'infrastructure populaire - RabbitMQ. Nous utiliserons le
graphique Helm pour RabbitMQ de Bitnami (du référentiel officiel helm / charts), qui utilise le
conteneur bitnami / rabbitmq . Un plugin pour Kubernetes est intégré au conteneur, qui est responsable de la détection des autres membres du cluster RabbitMQ. Pour cette raison, le processus à l'intérieur du conteneur nécessite un accès à l'API Kubernetes et nous devons configurer le
ServiceAccount avec les privilèges RBAC corrects.
En ce qui concerne les
ServiceAccounts de
ServiceAccounts , suivez cette bonne pratique:
- Configurez
ServiceAccounts pour chaque déploiement avec un
ensemble minimal de privilèges .
Pour les applications qui nécessitent un accès à l'API Kubernetes, vous pourriez être tenté de créer une sorte de «
ServiceAccount privilégié» qui peut faire presque n'importe quoi dans le cluster. Bien que cela semble être une solution plus simple, cela peut finalement conduire à une vulnérabilité de sécurité qui pourrait permettre des opérations indésirables. (La vidéo examine un exemple de Tiller [composant Helm] et les conséquences d'avoir des
ServiceAccounts avec de grands privilèges.)
En outre, différents
déploiements auront des besoins différents en termes d'accès à l'API, il est donc raisonnable que chaque
déploiement ait des
ServiceAccounts différents.
Gardant cela à l'esprit, voyons quelle configuration RBAC est correcte pour
le cas
de déploiement avec RabbitMQ.
Dans la
documentation du plugin et
son code source, vous pouvez voir qu'il demande une liste de
Endpoints à l'API Kubernetes. C'est ainsi que les membres restants du cluster RabbitMQ sont détectés. Par conséquent, le graphique Bitnami RabbitMQ crée:
- ServiceAccount pour les foyers avec RabbitMQ:
{{- if .Values.rbacEnabled }} apiVersion: v1 kind: ServiceAccount metadata: name: {{ template "rabbitmq.fullname" . }} labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" {{- end }}
- Rôle (nous supposons que l'intégralité du cluster RabbitMQ est déployé dans un seul espace de noms), permettant au verbe obtenir pour la ressource Endpoint :
{{- if .Values.rbacEnabled }} kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] {{- end }}
- RoleBinding connectant un
ServiceAccount à un rôle:
{{- if .Values.rbacEnabled }} kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: {{ template "rabbitmq.fullname" . }}-endpoint-reader labels: app: {{ template "rabbitmq.name" . }} chart: {{ template "rabbitmq.chart" . }} release: "{{ .Release.Name }}" heritage: "{{ .Release.Service }}" subjects: - kind: ServiceAccount name: {{ template "rabbitmq.fullname" . }} roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: {{ template "rabbitmq.fullname" . }}-endpoint-reader {{- end }}

Le diagramme montre que nous avons autorisé les processus en cours d'exécution dans les pods RabbitMQ à effectuer des opérations d'
obtention sur les objets
Endpoint . Il s'agit de l'ensemble minimal d'opérations requis pour que tout fonctionne. Dans le même temps, nous savons que le graphique déployé est sûr et n'effectuera pas d'actions indésirables dans le cluster Kubernetes.
Réflexions finales
Pour travailler avec Kubernetes en production, les stratégies RBAC ne sont pas facultatives. Ils ne peuvent pas être considérés comme un ensemble d'objets API que seuls les administrateurs doivent connaître. Les développeurs en ont réellement besoin pour déployer des applications sécurisées et tirer pleinement parti du potentiel offert par l'API Kubernetes pour les applications natives du cloud. Plus d'informations sur RBAC peuvent être trouvées à ces liens:
PS du traducteur
Lisez aussi dans notre blog: