Il y a quelques années, les systèmes de recommandation commençaient à peine à séduire leurs consommateurs. Les magasins en ligne utilisent activement des algorithmes de recommandation, offrant à leurs clients de plus en plus de nouveaux produits en fonction de leur historique d'achat.
Dans le service à la clientèle, les systèmes de recommandation sont devenus pertinents il n'y a pas si longtemps. En raison de l'augmentation du contenu offert, les clients ont commencé à se perdre dans les flux d'informations de quoi, où et quand ils ont besoin de voir. Les opérateurs de télévision à péage et les cinémas en ligne ont pris la tête des amateurs de contenu vidéo.

Comme un moyen efficace de résoudre le problème éternel de «que voir?» des systèmes de recommandation sont apparus qui fonctionnent sur la base d'un modèle mathématique particulier.
Il y a deux ans, nous avons introduit un système de recommandations, l'avons complété par la suite par des sélections éditoriales et nous avons ressenti un effet notable à la fois sur les ventes et sur la durée d'utilisation de notre service.
Quels sont les systèmes de recommandation
Un système de recommandation est lorsque vous voulez voir quelque chose, mais que vous ne savez pas quoi exactement, et le téléviseur réussit à deviner vos préférences. Il s'agit d'un filtrage de contenu qui sélectionne des films et des émissions de télévision en fonction des préférences et de l'analyse du comportement des utilisateurs. Le système utilisé par l'opérateur devrait prédire la réaction du spectateur à un élément particulier et offrir un contenu qu'il pourrait aimer.
Lors de la programmation de systèmes de recommandation, trois méthodes principales sont utilisées: le filtrage collaboratif, le filtrage basé sur le contenu et les systèmes experts (systèmes basés sur les connaissances).
Le filtrage collaboratif repose sur trois étapes: la collecte d'informations sur les utilisateurs, la construction d'une matrice de calcul des associations et l'émission de recommandations fiables.
Cinematch, que Netflix utilise, est un bon exemple de filtrage collaboratif. Les utilisateurs attribuent explicitement ou implicitement des notes aux films regardés et des recommandations sont formulées en tenant compte à la fois de leurs notes d'utilisateurs et de celles des autres téléspectateurs. Pour ce faire, le système sélectionne des utilisateurs ayant des préférences similaires, dont les notes sont proches des leurs. Sur la base de l'avis de ce cercle de personnes, le spectateur reçoit automatiquement la recommandation: regarder un film particulier.
Bien entendu, pour un fonctionnement correct du système de recommandation, les données accumulées et collectées jouent un rôle fondamental. Plus les données s'accumulent sur le profil de consommation d'un abonné particulier, plus les recommandations lui sont précises.
Le système de recommandation de contenu est formulé en fonction des attributs attribués à chaque élément. Si vous regardez des films d'un certain genre, le système vous proposera automatiquement du contenu proche de votre genre dans certaines positions. C'est sur la base d'un tel système de recommandations que fonctionne le site Pandora.
Les systèmes de recommandation d'experts proposent des recommandations non pas sur la base de notes, mais sur la base de similitudes entre les exigences des utilisateurs et les descriptions de produits, ou en fonction des restrictions définies par l'utilisateur lors de la spécification du produit souhaité. Par conséquent, ce type de système est unique, car il permet au client d'indiquer explicitement ce qu'il veut.
Les systèmes experts sont plus efficaces dans les contextes où la quantité de données disponibles est limitée et le filtrage collaboratif fonctionne mieux dans les environnements où il y a de grandes quantités de données. Mais lorsque les données sont diversifiées, il est possible de résoudre le même problème par différentes méthodes. Cela signifie qu'il combinera de manière optimale les recommandations reçues de plusieurs manières, améliorant ainsi la qualité du système dans son ensemble.
C'est un tel système hybride d'E-Contenta qui fonctionne dans notre service
WiFire TV . Il a été mis en service et débogué en décembre 2016 et fonctionne selon le principe suivant: si le système en sait beaucoup sur l'utilisateur ou sur le contenu, alors les algorithmes de filtrage collaboratif prévalent. Si le contenu est nouveau ou si des informations insuffisantes sont collectées sur l'interaction des utilisateurs avec lui, des algorithmes de contenu sont utilisés pour évaluer la similitude du contenu sur la base des métadonnées existantes.
Comment les algorithmes de recommandations ont été construits
Pour créer une sélection personnalisée dans E-Contenta, il était nécessaire de classer tout le contenu disponible en fonction de la probabilité qu'un utilisateur particulier soit intéressé par ce contenu.
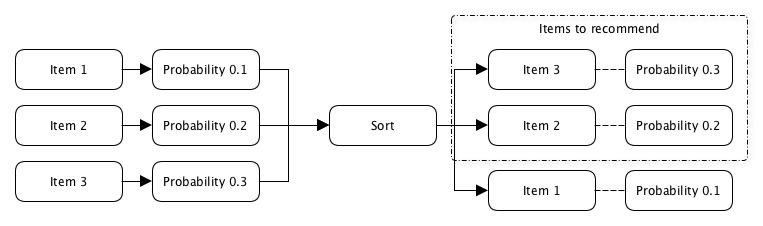
L'intérêt de l'utilisateur est principalement déterminé au moment où il clique sur le contenu qui lui est recommandé, et la probabilité est définie comme le rapport du nombre de clics au nombre de fois où ce contenu a été recommandé à cet utilisateur.
p (clic) = N clics / N affichagesLa difficulté réside dans le fait que vous devez recommander à l'utilisateur quelque chose qu'il n'a jamais vu, ce qui signifie qu'il n'y a tout simplement pas de données sur le nombre de clics ou d'impressions pour calculer cette probabilité.
Par conséquent, au lieu de la probabilité réelle, il a été décidé d'utiliser une estimation de cette probabilité, en d'autres termes, la valeur prédite.
L'idée d'un filtre collaboratif est simple:
- Prendre des données historiques sur les utilisateurs qui consultent le contenu
- Sur la base de ces données, regroupez les utilisateurs en fonction du contenu qu'ils ont consulté
- Pour un utilisateur donné, de prédire la probabilité de son intérêt pour une unité de contenu particulière, sur la base des données historiques d'autres utilisateurs du même groupe.
Ainsi, les utilisateurs participent conjointement au processus de sélection du contenu.
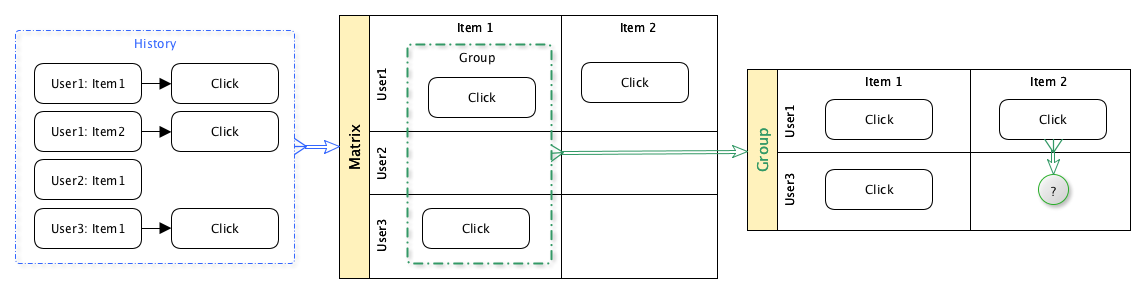
Il existe de nombreuses options différentes pour mettre en œuvre cette approche:
1. Construisez un modèle en utilisant directement les identifiants des unités de contenu:
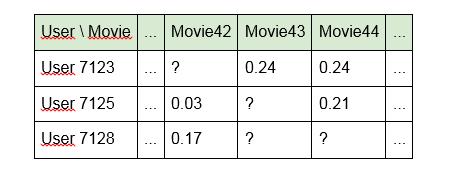
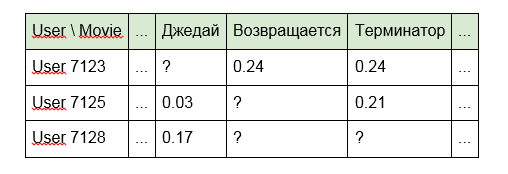
L'inconvénient de cette approche est que le modèle "ne voit" aucun lien entre les unités de contenu. Par exemple, «Terminator» et «Terminator 2» pour elle seront aussi éloignés l'un de l'autre que «Alien» et «Good night, Kids!». De plus, la matrice elle-même s'avère très clairsemée (beaucoup de cellules vides et un peu remplies).
2. Au lieu d'identifiants, utilisez les mots inclus dans le titre des articles, programmes ou films:
3. Pour les films, noms d'acteurs, réalisateurs ou données d'IMDb:
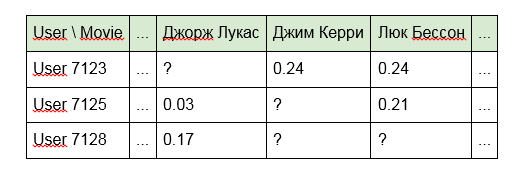
Les deuxième et troisième options éliminent partiellement les inconvénients de la première approche, étant donné la connexion de contenu ayant des caractéristiques communes (du même réalisateur ou des mêmes mots dans le titre). Cependant, la rareté de la matrice est également réduite, mais comme on dit, il n'y a pas de limite à la perfection.
Conserver une gamme complète de notes d'utilisateurs en mémoire coûte assez cher. En prenant des estimations approximatives du nombre d'utilisateurs de Runet à 80 millions de personnes et de la taille de la base de données IMDb à 370 000 films, nous obtenons la taille requise de 27 téraoctets. La décomposition singulière est une méthode pour réduire la dimension de la matrice.
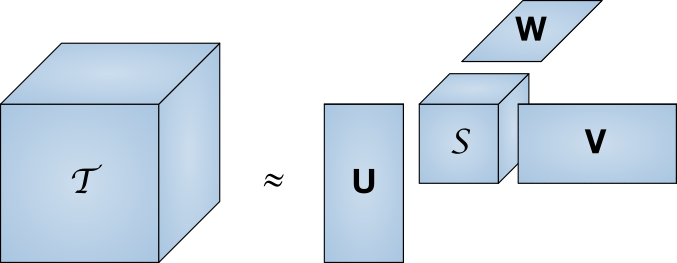 Une grande matrice T est représentée comme le produit d'un ensemble de matrices plus petites
Une grande matrice T est représentée comme le produit d'un ensemble de matrices plus petitesEn d'autres termes, la recherche de la matrice "core", qui a les mêmes propriétés que la matrice complète, mais beaucoup plus petite. Parallèlement à une diminution de dimension, la décharge diminue également. Dans cet article, nous n'entrerons pas dans les subtilités de l'implémentation, d'autant plus que des bibliothèques prêtes à l'emploi existent déjà pour un certain nombre de langages de programmation.
Difficultés techniques
Démarrage à froidLa situation où le manque de données pour le nouveau contenu ou l'utilisateur ne permet pas de donner des recommandations de haute qualité, également connu sous le nom de «Cold Start», est un problème typique pour le filtrage collaboratif.
Une solution consiste à mélanger plusieurs unités de contenu dans les recommandations qui ne collectent pas suffisamment de données. Dans le même temps, le contenu le plus populaire sera recommandé au nouvel utilisateur.
Le plus populaireEn utilisant l'approche ci-dessus, il est important de ne pas oublier que sa conséquence sera une augmentation systématique de la fréquence d'occurrence des «plus populaires» dans la liste recommandée. Apprendre du comportement des utilisateurs qui se voient souvent proposer le «plus populaire», le système de recommandation risque d'apprendre à recommander exclusivement le contenu le plus populaire.
La principale différence entre les recommandations personnelles et les recommandations banales du contenu le plus populaire est qu'elles prennent en compte les goûts individuels, qui peuvent différer considérablement des goûts «moyens».
Ainsi, l'échantillon de réactions des utilisateurs au contenu utilisé pour former le modèle de recommandation doit être normalisé.
Disponibilité, basculement et évolutivitéLe nombre d'utilisateurs de la ressource peut créer une charge de centaines et de milliers de demandes au système de recommandation par seconde. De plus, la panne d'un ou plusieurs serveurs ne doit pas conduire à un déni de service.
Dans ce cas, la solution classique consiste à utiliser un équilibreur de charge qui envoie une demande à l'un des serveurs de cluster. De plus, chacun des serveurs est en mesure de traiter une demande entrante. En cas de défaillance de l'un des serveurs du cluster, l'équilibreur bascule automatiquement la charge vers les serveurs restant dans le système. En choisissant HTTP comme protocole de transport, nous pouvons utiliser Nginx comme équilibreur de charge.
À mesure que l'audience de la ressource augmente, le nombre de serveurs dans le cluster peut augmenter. Dans ce cas, il est important de minimiser le coût de préparation d'un nouveau serveur.
Le système de recommandation nécessite l'installation d'un certain nombre de composants sur lesquels il s'appuie fonctionnellement. Docker est utilisé pour automatiser le déploiement d'un système de recommandation avec toutes ses dépendances.
Docker vous permet de collecter tous les composants nécessaires, de les «empaqueter» dans une image et de placer une telle image dans un référentiel (registre), puis de la télécharger et de la déployer sur un nouveau serveur en quelques minutes. Un avantage important de Docker est que la «surcharge» lors de son utilisation est minimale: le temps d'appel de l'application dans le conteneur Docker est augmenté de quelques nanosecondes par rapport à l'application exécutée dans un système d'exploitation normal.
Un autre avantage important est la possibilité de revenir rapidement à la version stable précédente de l'application en cas de nouvelle panne (il suffit de prendre l'ancienne version du registre).
Le deuxième type de demandes système dont vous devez vous occuper sont les demandes qui suivent l'activité des utilisateurs. Pour que l'utilisateur n'ait pas à attendre que le système traite complètement l'action qu'il a effectuée, le processus de traitement est effectué indépendamment du processus d'enregistrement des actions.
Apache Kafka a été choisi chez E-Contenta comme plate-forme qui fournit le transfert de données des actions utilisateur aux processeurs. Kafka implémente le modèle architectural Message-Oriented Middleware), qui est capable de garantir la livraison de dizaines et de centaines de milliers de messages par seconde et d'agir comme un tampon qui protège les gestionnaires des volumes de données excessifs aux heures de pointe.
Auto-apprentissage completDe nouveaux contenus et de nouveaux utilisateurs apparaissent régulièrement - sans formation régulière, la qualité du modèle se dégrade. La formation doit être effectuée sur des serveurs distincts afin que le processus de formation, qui nécessite des ressources informatiques importantes, n'affecte pas les performances des serveurs de combat.
Jenkins est la solution classique pour orchestrer des tâches distribuées régulières. Le service planifié commence à recevoir et à normaliser de nouveaux échantillons de formation, à former un modèle de recommandation, à fournir de nouveaux modèles et à mettre à jour tous les serveurs de cluster, ce qui permet de maintenir la qualité des recommandations sans efforts supplémentaires. En cas d'échec à l'une des étapes, Jenkins remet indépendamment le système à son état stable précédent et informe l'administrateur de l'échec.
À propos de la façon dont nous l'avons implémenté sur WifireTV
De plus, afin que le système fonctionne correctement, nous avons invité un compteur de télévision indépendant et l'avons invité à mesurer la télévision des abonnés. Les données uniques résultantes sont animées à l'aide d'algorithmes de science des données. La rétroaction continue des abonnés qui interagissent avec les recommandations remplit la base des précédents pour les algorithmes d'apprentissage automatique et permet aux recommandations de changer en fonction des signes implicites de changement des préférences des abonnés, comme la période de l'année, l'approche des vacances ou la composition de la famille.
Dans le processus de test, nous avons dû résoudre le problème associé à la recommandation de contenu télévisuel - comment aider nos abonnés à comprendre les flux de diffusion. La tâche est également compliquée par les services de visualisation différée. Nous avons intégré un système qui, au lieu d'une commutation cyclique sans fin des canaux, permet de trouver un programme intéressant en seulement 2 ou 3 touches. Pour cela, le système de recommandation surveille la sortie de nouvelles séries de programmes et prédit l'intérêt des téléspectateurs pour des programmes et des diffusions de films irréguliers. En fait, les algorithmes machine remplacent le travail de l'éditeur responsable.
Le travail avec la télévision en streaming a ses propres spécificités. Par exemple, souvent les mêmes émissions de télévision populaires sont diffusées sur différentes chaînes. Dans ce cas, le système de recommandation doit comprendre la duplication des informations et choisir une recommandation basée sur les préférences de l'abonné concernant les canaux, l'heure de début de transmission, etc. Cette duplication d'informations se produit également lorsqu'un abonné a un abonnement aux versions SD et HD des chaînes.
Au cours de ces deux années, nous avons expérimenté différentes versions de systèmes de recommandation et trouvé un terrain d'entente, ce qui nous permet d'améliorer l'engagement du public et de monétiser plus efficacement le contenu existant. Nous utilisons la sélection automatique des recommandations décrites ci-dessus ainsi que le réglage manuel - sélections éditoriales.
Cette approche a permis d'augmenter de manière significative (10 fois) la monétisation des services VOD et SVOD.
Les recommandations éditoriales sont des collections de films et de séries thématiques liés à des premières, des vacances et des dates mémorables. Il est très pratique d'informer les abonnés et de leur donner la possibilité de regarder de nouveaux films, d'anciens succès ou impopulaires, mais à notre avis, des films très intéressants en termes de contenu et d'intrigue. Nous communiquons étroitement avec nos fournisseurs (cinémas en ligne et services vidéo supplémentaires, tels que ivi, megogo, amediateka) et sélectionnons personnellement chaque film qui sera intéressant à regarder pour notre abonné.
En vacances, nous faisons des sélections spéciales sur un sujet spécifique. Par exemple, le jour de la victoire, ce sont des films sur le thème militaire. Le 1er septembre - une sélection de contenus pour enfants, qui se compose de programmes éducatifs, de dessins animés et de documentaires.
La sélection manuelle augmente parfaitement la fidélité de nos abonnés. Selon nos estimations les plus prudentes, environ 10% de notre base d'abonnés regardent des films mensuels que nous recommandons et cet indicateur est en constante augmentation.
Quel est le résultat?
Wifire TV gère actuellement un système de recommandation intelligent d'E-Contenta. Il est basé sur la science des données et les métadonnées de 90% des abonnés de l'opérateur. L'algorithme prend en compte des centaines de données: ce que l'abonné regarde, quels films et programmes sont populaires, quand il utilise le service et qui est maintenant devant l'écran. Nous voulons transmettre à nos abonnés la valeur de l'abonnement à des forfaits de chaînes premium, en les mélangeant dans des recommandations pertinentes pour l'utilisateur. Nous voulons également montrer qu'acquérir et regarder du contenu vidéo légal est normal, pratique et simple.
Le système de recommandation dira à l'abonné des films intéressants, même s'ils sont depuis longtemps hors de la catégorie des nouveaux produits: ainsi, le vaste catalogue de vidéos cesse d'être une bibliothèque poussiéreuse, mais devient une vitrine interactive qui s'adapte avec souplesse aux goûts et aux humeurs des abonnés.