Dans cet article, je voudrais parler de certaines techniques pour travailler avec des données lors de la formation d'un modèle. En particulier, comment extraire la segmentation des objets sur les boîtes, ainsi que comment entraîner le modèle et obtenir le balisage de l'ensemble de données, en ne marquant que quelques échantillons.
Défi
Il existe un certain processus de fabrication de pizza et de photos à partir de ses différentes étapes (y compris non seulement la pizza). Il est connu que si la recette de la pâte est gâtée, il y aura des boutons blancs sur la croûte. Il existe également un marquage binaire de la qualité du test pour chaque exemple de pizza, réalisé par des experts. Il est nécessaire de développer un algorithme qui déterminera la qualité du test à partir d'une photographie.
L'ensemble de données se compose de photographies prises à partir de différents téléphones, dans différentes conditions, sous différents angles. Instances de pizza - 17k. Nombre total de photos - 60k.
À mon avis, la tâche est assez typique et bien adaptée pour montrer différentes approches de traitement des données. Pour le résoudre, vous devez:
1. Choisissez des photos où il y a une croûte de pizza;
2. Sur les photos sélectionnées, mettez en surbrillance le gâteau;
3. Entraînez le réseau neuronal dans les zones sélectionnées.
Filtrer les photos
À première vue, il semble que le moyen le plus simple serait de confier cette tâche aux scribers, puis de former l'ensemble de données sur des données propres. Cependant, j'ai décidé qu'il était plus facile pour moi de marquer moi-même une petite partie que d'expliquer avec un scribe quel angle était correct. De plus, je n'avais pas de critère dur pour l'angle droit.
Voici donc ce que j'ai fait:
1. 100 photos de bord marquées;

2. Comptage des entités après extraction globale de la grille resnet-152 avec les poids de imagenet11k_places365;
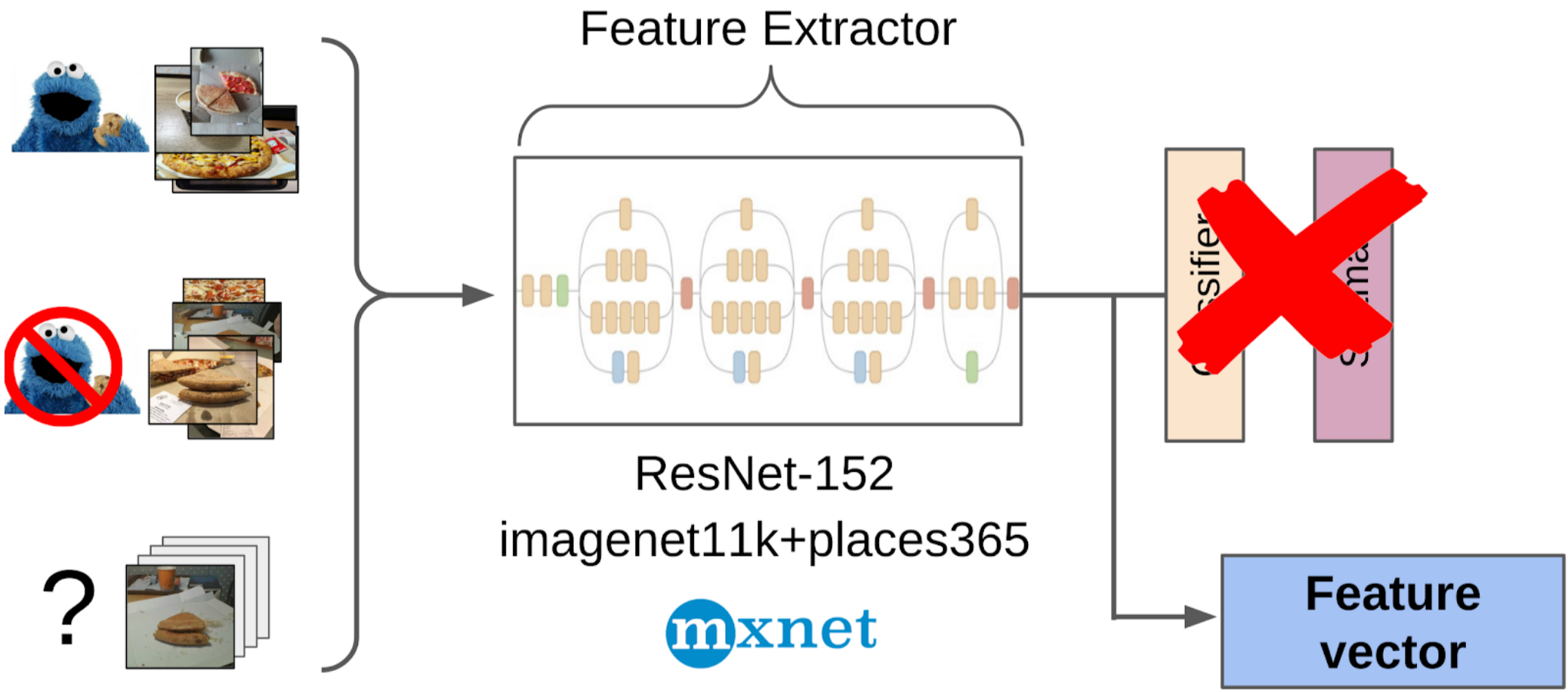
3. A pris la moyenne des caractéristiques de chaque classe, recevant deux ancres;
4. J'ai calculé la distance entre chaque ancre et toutes les caractéristiques des 50 000 photos restantes;
5. Le top 300 à proximité d'une ancre est pertinent pour la classe positive, le top 500 de la plus proche d'une autre ancre est négatif;
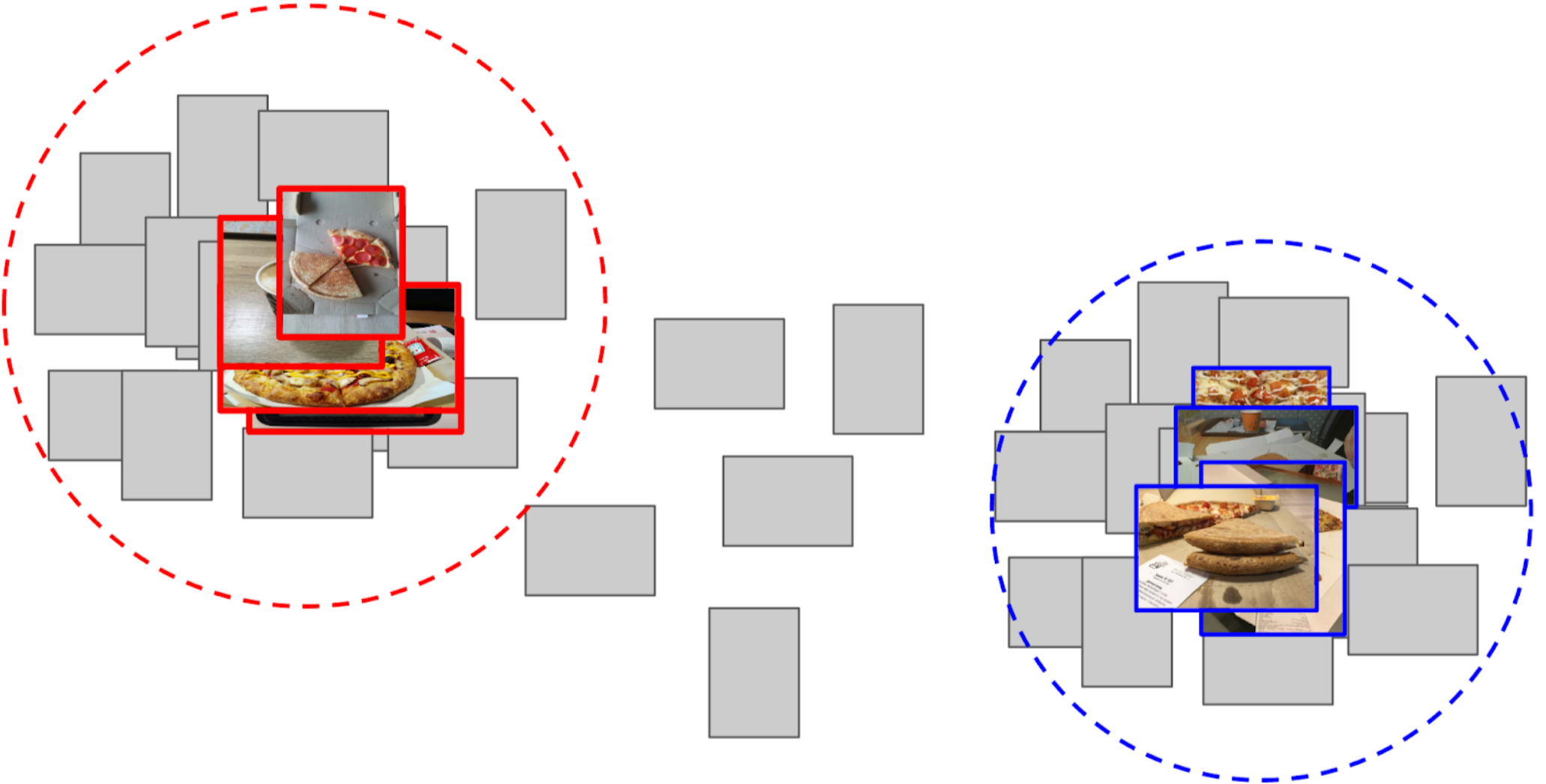
6. J'ai formé LightGBM sur ces échantillons avec les mêmes fonctionnalités (XGboost est indiqué dans l'image, car il a un logo et est plus reconnaissable, mais LightGBM n'a pas de logo);
7. En utilisant ce modèle, j'ai obtenu le balisage de l'ensemble de données complet.

J'ai utilisé approximativement la même approche dans les compétitions de kaggle comme
ligne de base .
Une explication sur les doigts pourquoi cette approche fonctionne mêmeUn réseau de neurones peut être perçu comme une transformation fortement non linéaire d'une image. Dans le cas de la classification, l'image est convertie en probabilités des classes qui étaient dans l'ensemble d'apprentissage. Et ces probabilités peuvent essentiellement être utilisées comme fonctionnalités pour Light GBM. Cependant, c'est une description plutôt médiocre, et dans le cas de la pizza, nous dirons donc que la classe de gâteau est conditionnellement 0,3 chat et 0,7 chien, et la poubelle est le reste. Au lieu de cela, vous pouvez utiliser des fonctionnalités moins clairsemées après le regroupement moyen global. Ils ont une telle propriété que les caractéristiques sont générées à partir des échantillons de l'ensemble d'apprentissage, qui doivent être séparés par une transformation linéaire (une couche entièrement connectée avec Softmax). Cependant, étant donné qu'il n'y avait pas de pizza explicite dans le train imagenet, il est préférable de prendre une transformation non linéaire sous forme d'arbres pour séparer les classes du nouvel ensemble d'entraînement. En principe, vous pouvez aller encore plus loin et prendre des fonctionnalités de certaines couches intermédiaires du réseau neuronal. Ils seront meilleurs dans la mesure où ils n'ont pas encore perdu la localisation des objets. Mais ils sont bien pires en raison de la taille du vecteur d'entités. Et en plus, ils sont moins linéaires qu'en face d'une couche entièrement connectée.
Une légère digression
ODS s'est récemment plaint que personne n'écrive sur leurs échecs. Corriger la situation. Il y a environ un an, j'ai participé au concours
Kaggle Sea Lions avec
Eugene Nizhibitsky . La tâche consistait à compter les otaries à fourrure dans les images du drone. Le balisage a été donné simplement sous la forme de coordonnées de carcasse, mais à un moment donné,
Vladimir Iglovikov les a marquées avec des boîtes et a généreusement partagé cela avec la communauté. À cette époque, je me considérais comme un père de segmentation sémantique (après
Kaggle Dstl ) et
j'ai décidé qu'Unet faciliterait grandement la tâche de comptage si j'apprenais à distinguer classiquement les chats.
Explication de la segmentation sémantiqueLa segmentation sémantique est essentiellement une classification pixel par pixel d'une image. Autrement dit, chaque pixel source de l'image doit être associé à une classe. Dans le cas d'une segmentation binaire (cas de l'article), ce sera soit une classe positive soit une classe négative. Dans le cas de la segmentation multiclasse, chaque pixel se verra attribuer une classe de l'ensemble d'apprentissage (fond, herbe, chat, homme, etc.). Dans le cas de la segmentation binaire, l'architecture du réseau neuronal
U-net fonctionnait bien à l'époque. Ce réseau de neurones a une structure similaire à un codeur-décodeur conventionnel, mais avec une transmission de caractéristiques de la partie codeur au décodeur aux étages de taille appropriée.

Sous forme vanille, cependant, personne ne l'utilise plus, mais au moins ils ajoutent la norme de lot. Eh bien, en règle générale, ils prennent un
gros encodeur et gonflent le décodeur. Les architectures de type U-net ont été remplacées par de nouvelles grilles de segmentation
FPN , qui affichent de bonnes performances sur certaines tâches. Cependant, les architectures de type Unet n'ont pas perdu de leur pertinence à ce jour. Ils fonctionnent bien comme ligne de base, ils sont faciles à former et il est très simple de faire varier la profondeur / la taille des neurosciences en changeant différents eccodeurs.
En conséquence, j'ai commencé à enseigner la segmentation, n'ayant pour cible au premier stade que des chats de boxe. Après la première étape de la formation, j'ai prédit le train et regardé à quoi ressemblaient les prédictions. À l'aide de l'heuristique, on pourrait sélectionner la confiance abstraite dans le masque et diviser conditionnellement les prédictions en deux groupes: où tout est bon et où tout est mauvais.

Des prédictions où tout va bien pourraient être utilisées pour former la prochaine itération du modèle. Les prédictions, où tout va mal, pourraient être choisies avec de grandes zones sans scellés, les mains masquées et également jetées dans le train. Et donc de manière itérative, Eugene et moi avons formé un modèle qui a même appris à segmenter les nageoires d'otaries à fourrure pour les gros individus.
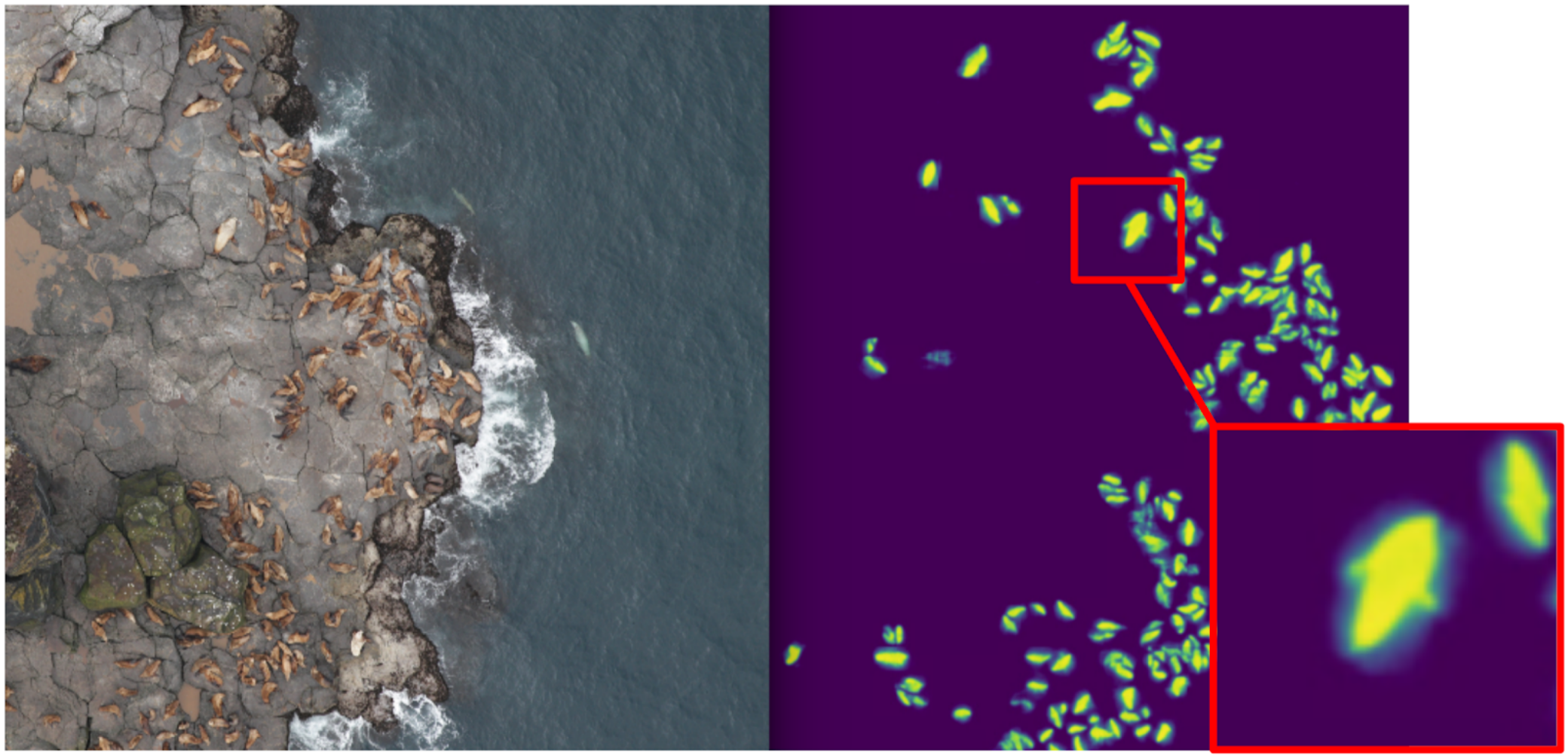
Mais ce fut un échec féroce: nous avons passé beaucoup de temps à apprendre à segmenter les chats cool et ... Cela n'a presque pas aidé dans leur calcul. L'hypothèse que la densité des phoques (le nombre d'individus par unité de surface du masque) est constante n'a pas fonctionné, car le drone a volé à différentes hauteurs et les images avaient des échelles différentes. Et en même temps, la segmentation n'indiquait toujours pas les individus individuels s'ils étaient serrés - ce qui arrivait assez souvent. Et avant l'
approche innovante de la séparation des objets de l'équipe Tocoder au DSB2018, il y avait encore une année. En conséquence, nous sommes restés avec rien mais avons terminé à la 40e place sur 600 équipes.
Cependant, j'ai fait deux conclusions: la segmentation sémantique est une approche pratique pour visualiser et analyser le fonctionnement de l'algorithme, et les masques peuvent être soudés à partir des boîtes avec un certain effort.
Mais revenons à la pizza. Afin de mettre en évidence le gâteau sur les photos sélectionnées et filtrées, l'option la plus correcte serait de confier la tâche aux scribers. À cette époque, nous avions déjà implémenté les boîtes et l'algorithme de consensus pour elles. Je viens donc de jeter quelques exemples et de les donner au balisage. En conséquence, j'ai obtenu 500 échantillons avec une zone de croûte sélectionnée avec précision.
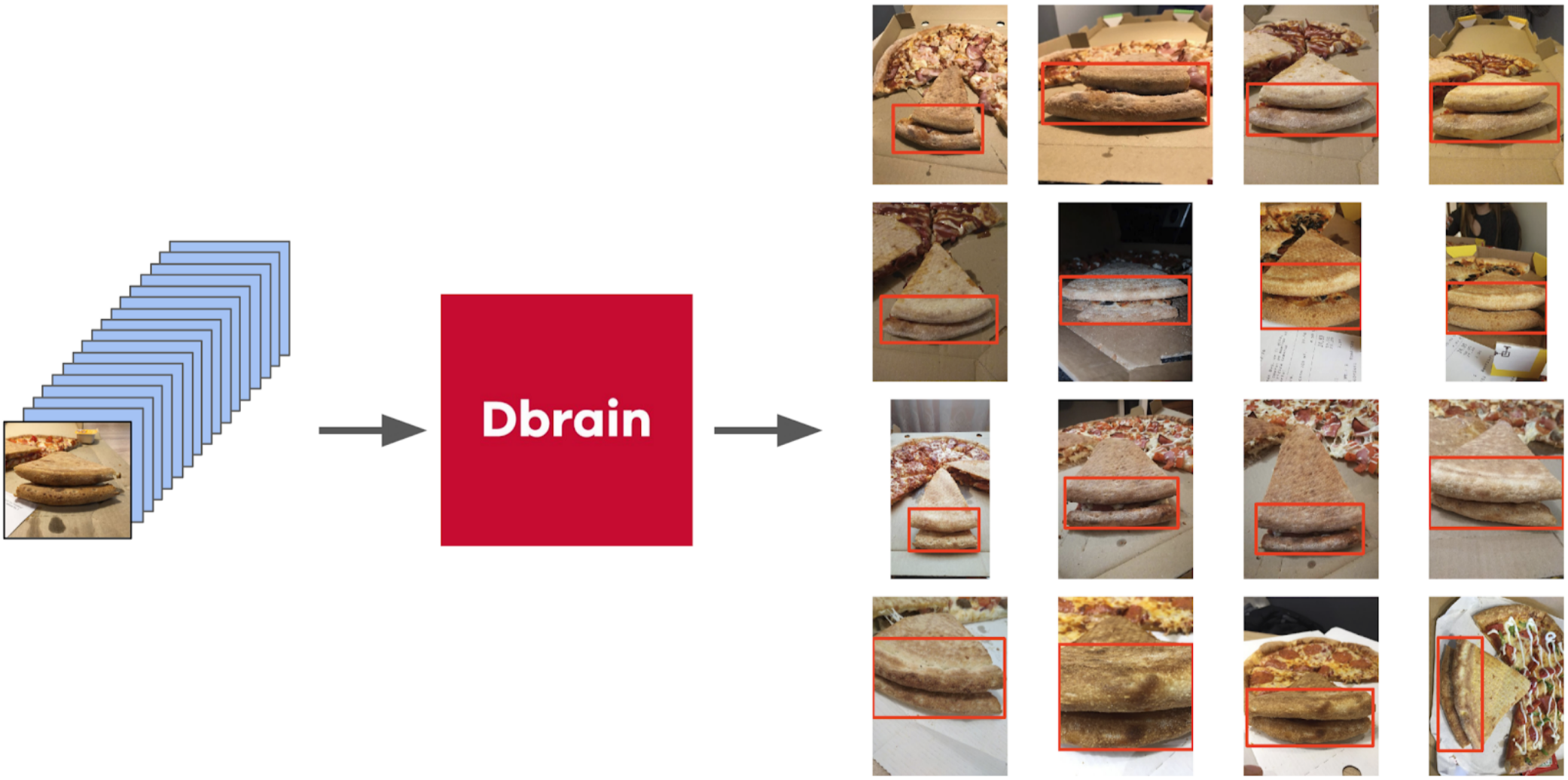
Ensuite, j'ai déterré mon code des scellés et j'ai approché plus formellement la procédure actuelle. Après la première itération de la formation, il était également clairement visible où le modèle s'était trompé. Et la confiance des prédictions peut être définie comme suit:
1 - (zone grise) / (zone de masque) # il y aura une formule, je le promets
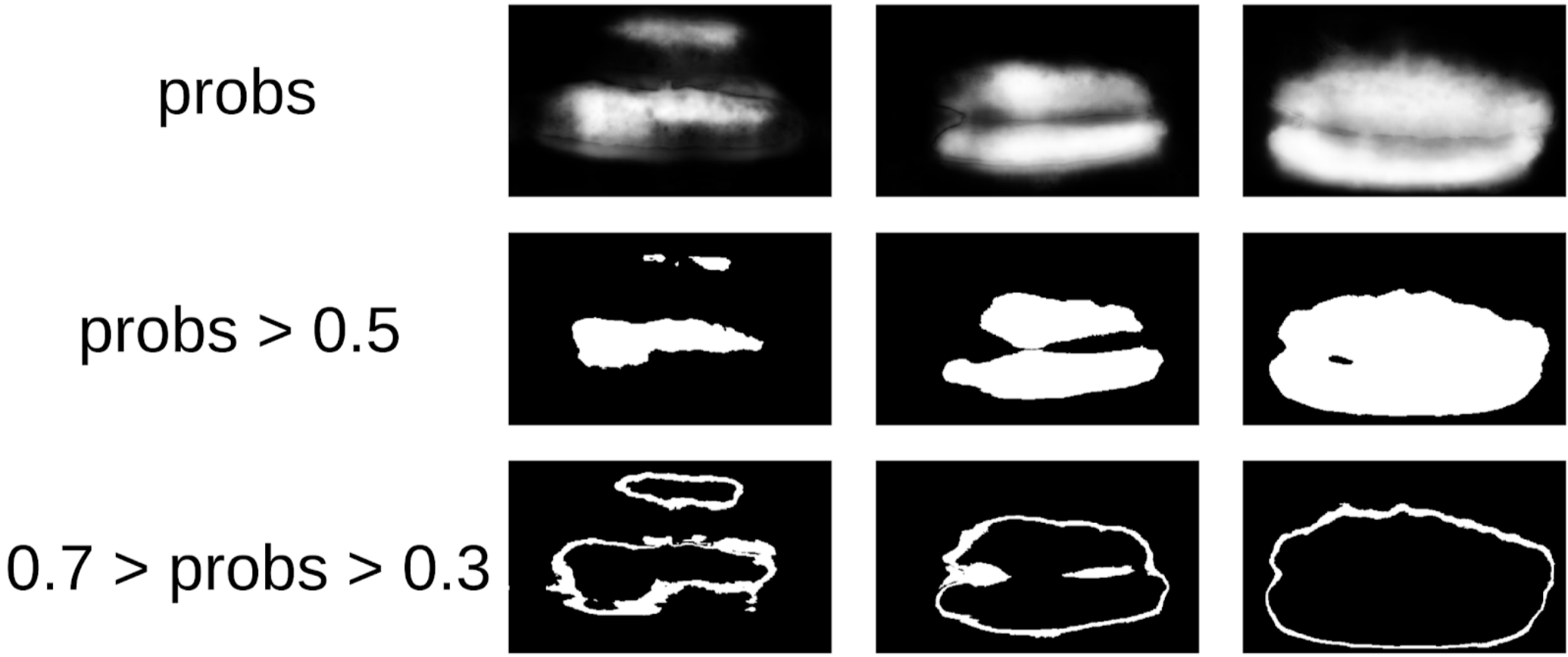
Maintenant, pour faire la prochaine itération de tirer les boîtes sur les masques, un petit ensemble prédira le train TTA. Cela peut être considéré dans une certaine mesure comme une distillation des connaissances WAAAAGH, mais il est plus correct d'appeler le pseudo étiquetage.
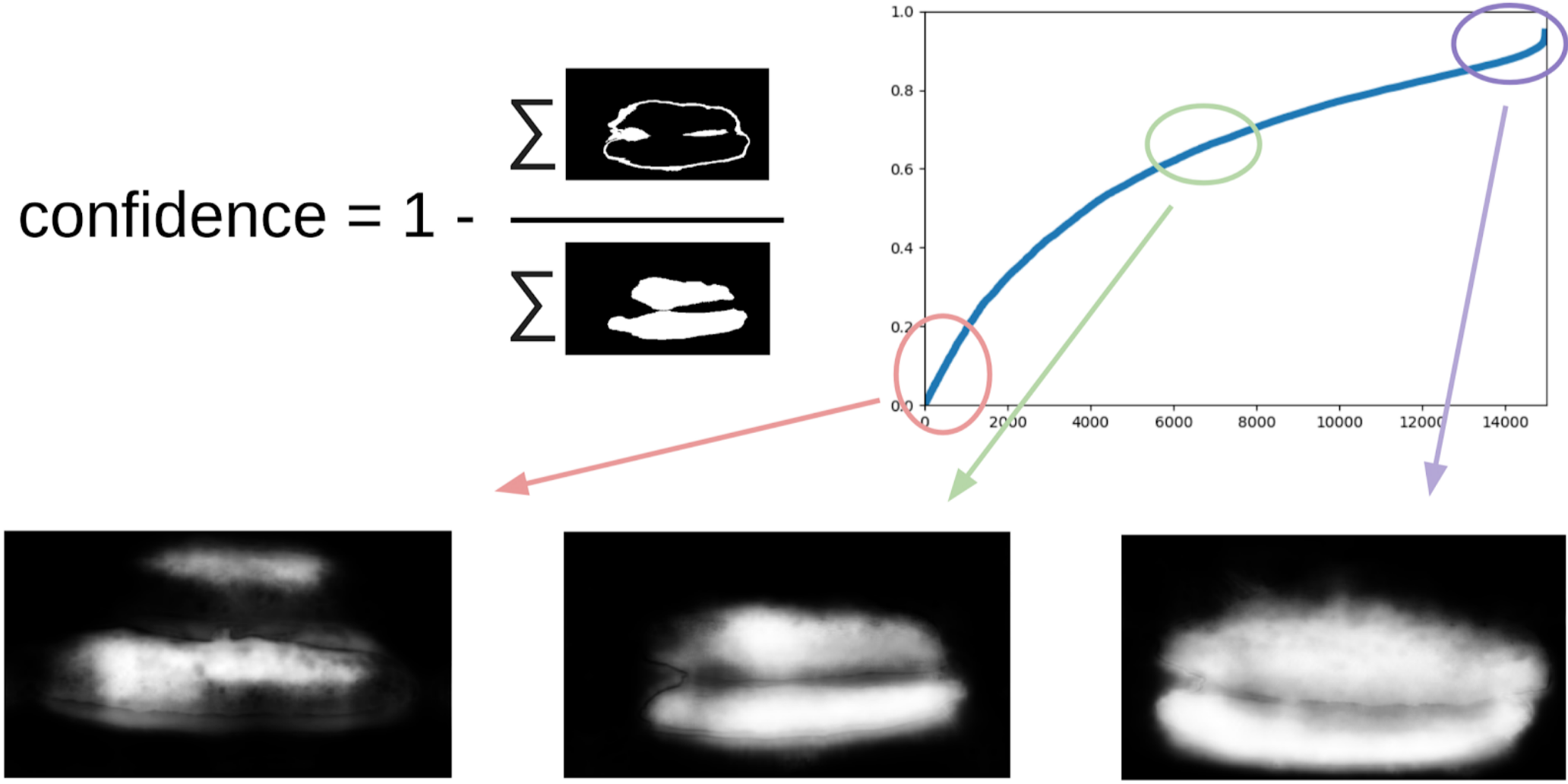
Ensuite, vous devez choisir avec vos yeux un certain seuil de confiance, à partir duquel nous formons un nouveau train. Et vous pouvez éventuellement marquer les échantillons les plus complexes que l'ensemble n'a pas pu gérer. J'ai décidé que ce serait utile et j'ai peint une vingtaine de photos quelque part en digérant le déjeuner.
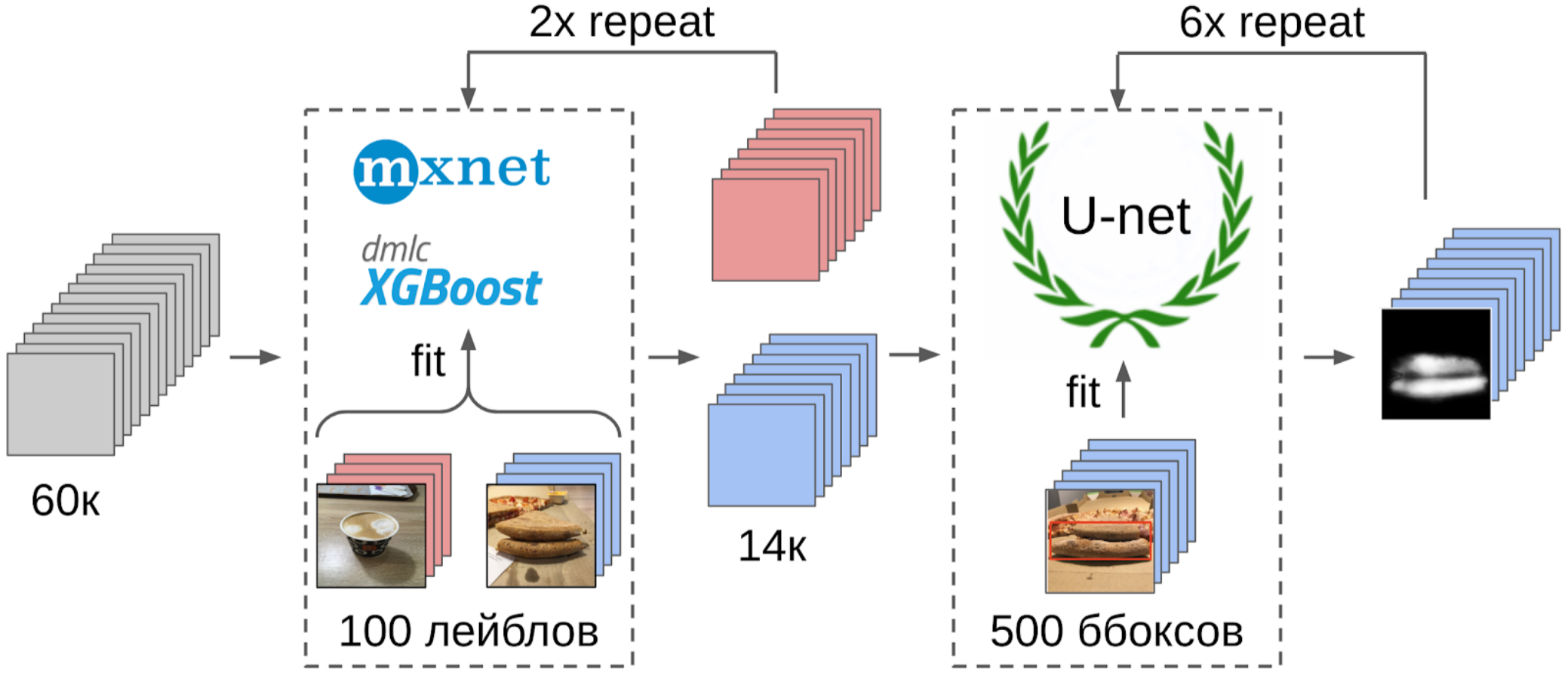
Et maintenant, la dernière partie du pipeline: la formation de modèles. Pour préparer les échantillons, j'ai extrait la zone du masque du gâteau. J'ai également gonflé un peu le masque avec dilatation et l'ai appliqué à l'image pour supprimer l'arrière-plan, car il ne devrait pas y avoir d'informations sur la qualité du test. Et puis je viens de déposer plusieurs modèles du zoo d'Imagenet. Au total, j'ai pu collecter environ 12 000 échantillons confiants. Par conséquent, je n'ai pas enseigné l'ensemble du réseau neuronal, mais seulement le dernier groupe de convolutions, afin que le modèle ne soit pas recyclé.
Pourquoi vous devez geler les couchesIl y a deux bénéfices à cela: 1. Le réseau apprend plus vite, car vous n'avez pas besoin de lire les dégradés pour les couches figées. 2. Le réseau n'est pas recyclé, car il a désormais moins de paramètres libres. On soutient que les premiers groupes de circonvolutions au cours de la formation sur Imagenet génèrent des signes assez communs tels que des transitions de couleurs nettes et des textures qui conviennent à une très large classe d'objets en photographie. Cela signifie que vous ne pouvez pas les former pendant l'apprentissage Transer.
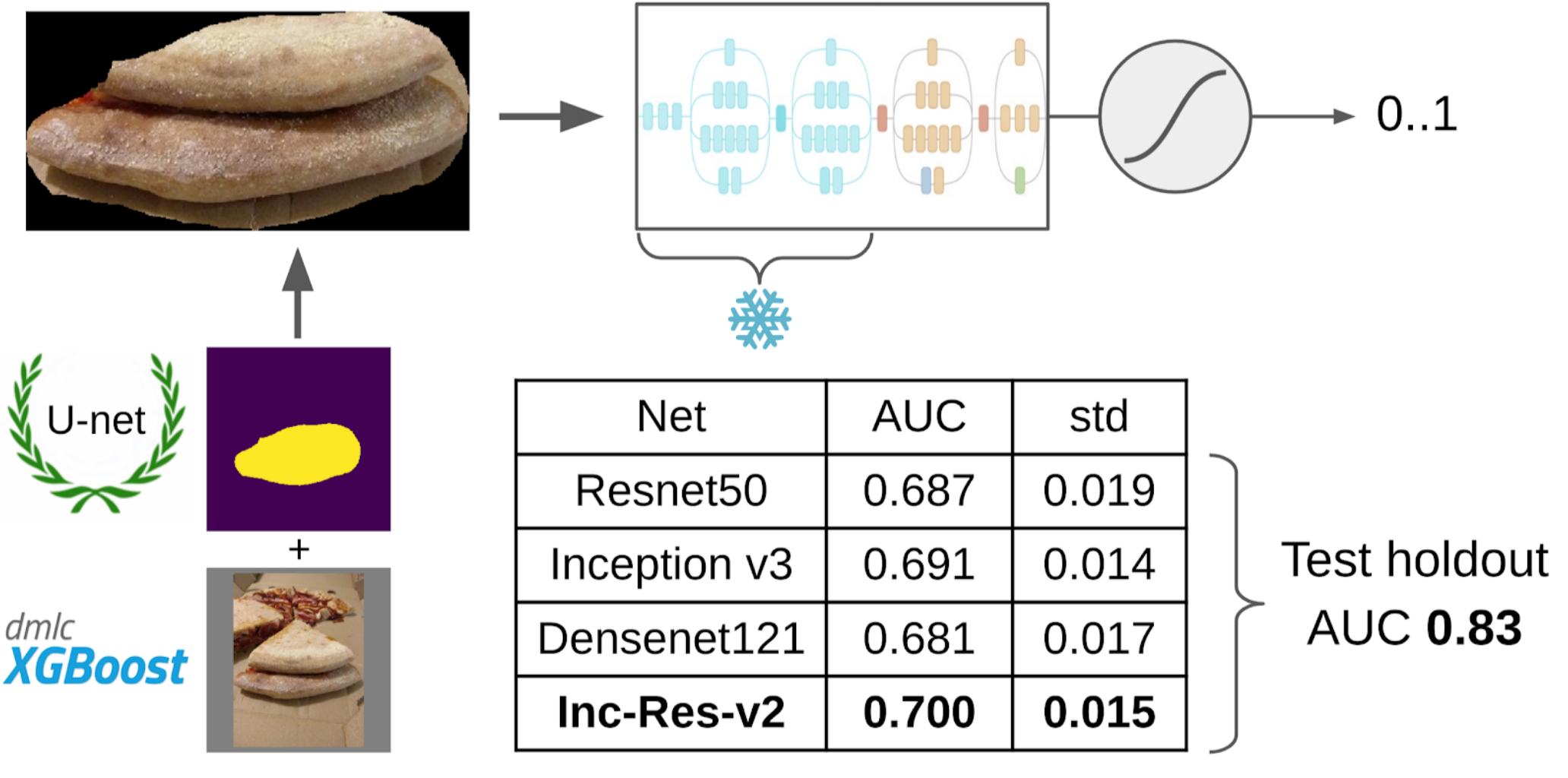
Le meilleur modèle unique était Inception-Resnet-v2, et pour elle, le ROC-AUC sur un pli était de 0,700. Si vous ne sélectionnez rien et soumettez des images brutes telles quelles, alors ROC-AUC est 0,58. Pendant que je développais la solution, le prochain lot de données a été cuit chez DODO pizza, et il a été possible de tester l'ensemble du pipeline sur une tenue honnête. Nous avons vérifié tout le pipeline et obtenu ROC-AUC 0,83.
Regardons maintenant les erreurs:
Top False Negative

On peut voir ici qu'ils sont associés à une erreur de marquage du gâteau, car il y a clairement des signes d'un test gâté.
Top des faux positifs

Ici, les erreurs sont liées au fait que le premier modèle a été choisi pas un très bon angle, selon lequel il est difficile de trouver des signes clés de la qualité du test.
Conclusion
Des collègues me taquinent parfois que je résous de nombreux problèmes par segmentation en utilisant Unet. Cependant, à mon avis, c'est une approche assez puissante et pratique. Il vous permet de visualiser les erreurs du modèle et la confiance de ses prédictions. De plus, l'ensemble de la ligne de paiement semble très simple et il existe maintenant un tas de référentiels pour n'importe quel cadre.