Dans cet article, nous expliquerons comment et pourquoi nous avons développé
le système d'interaction - un mécanisme qui transfère les informations entre les applications clientes et les serveurs 1C: Enterprise - de la définition de la tâche à la réflexion sur l'architecture et les détails d'implémentation.
Le système d'interaction (ci-après dénommé CB) est un système de messagerie distribué à tolérance de panne avec une livraison garantie. SV est conçu comme un service très chargé avec une grande évolutivité, et est disponible à la fois en tant que service en ligne (fourni par 1C) et en tant que produit de circulation qui peut être déployé sur ses capacités de serveur.
CB utilise le stockage distribué
Hazelcast et le moteur de recherche
Elasticsearch . Nous parlerons également de Java et de la façon dont nous dimensionnons PostgreSQL horizontalement.

Énoncé du problème
Pour expliquer pourquoi nous avons créé le système d'interaction, je vais vous expliquer un peu comment fonctionne le développement d'applications métier dans 1C.
Pour commencer, un peu de nous pour ceux qui ne savent pas encore ce que nous faisons :) Nous créons la plateforme technologique 1C: Enterprise. La plate-forme comprend un outil de développement d'applications métier, ainsi que d'exécution, qui permet aux applications métier de fonctionner dans un environnement multiplateforme.
Paradigme de développement client-serveur
Les applications métier créées sur «1C: Enterprise» fonctionnent dans l'architecture
client-serveur à trois niveaux «SGBD - serveur d'applications - client». Le code d'application écrit dans le
langage embarqué 1C peut être exécuté sur le serveur d'application ou sur le client. Tous les travaux avec les objets d'application (répertoires, documents, etc.), ainsi que la lecture et l'écriture dans la base de données, sont effectués uniquement sur le serveur. La fonctionnalité de l'interface formulaires et commandes est également implémentée sur le serveur. Le client reçoit, ouvre et affiche des formulaires, «communique» avec l'utilisateur (avertissements, questions ...), de petits calculs dans des formulaires qui nécessitent une réaction rapide (par exemple, multiplier le prix par le montant), travailler avec des fichiers locaux, travailler avec du matériel.
Dans le code d'application, les en-têtes des procédures et des fonctions doivent indiquer explicitement où le code sera exécuté - en utilisant les directives & Sur le client / & Sur le serveur (& AtClient / & AtServer dans la version en langue anglaise). Les développeurs sur 1C vont me corriger maintenant, en disant qu'il y a en fait
plus de directives, mais pour nous ce n'est pas essentiel maintenant.
Le code serveur peut être appelé à partir du code client, mais le code client ne peut pas être appelé à partir du code serveur. Il s'agit d'une limitation fondamentale que nous avons faite pour un certain nombre de raisons. En particulier, parce que le code du serveur doit être écrit de manière à être exécuté de manière égale, peu importe où il est appelé - à partir du client ou du serveur. Et en cas d'appel du code serveur depuis un autre code serveur, le client est absent en tant que tel. Et parce que pendant l'exécution du code du serveur, le client qui l'a provoqué pouvait se fermer, quitter l'application et le serveur n'aurait personne à appeler.
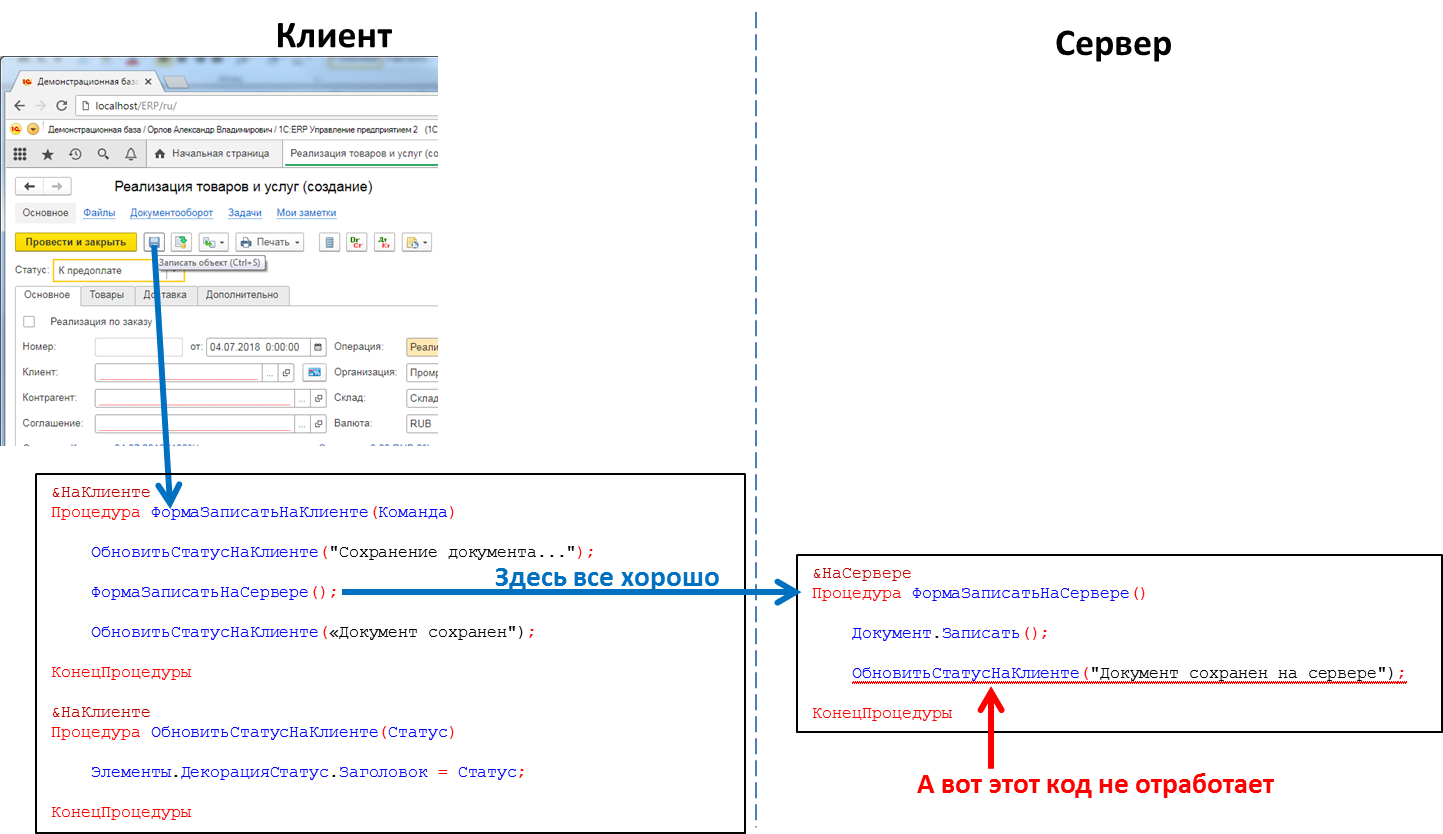 Le code qui traite le clic du bouton: l'appel de procédure serveur du client fonctionnera, l'appel de procédure client du serveur ne fonctionnera pas
Le code qui traite le clic du bouton: l'appel de procédure serveur du client fonctionnera, l'appel de procédure client du serveur ne fonctionnera pasCela signifie que si nous voulons transférer un message vers l'application client depuis le serveur, par exemple, que la formation d'un rapport "longue durée" est terminée et que le rapport peut être consulté, nous n'avons pas une telle méthode. Nous devons passer à des astuces, par exemple, à partir du code client pour interroger périodiquement le serveur. Mais cette approche charge le système d'appels inutiles et n'a en effet pas l'air très élégante.
Et il existe également un besoin, par exemple, lorsqu'un appel téléphonique
SIP arrive, en informer l'application cliente afin que, par le numéro de l'appelant, il le trouve dans la base de données de la contrepartie et affiche les informations utilisateur sur la contrepartie appelante. Ou, par exemple, à la réception de la commande dans l'entrepôt, en informer l'application client du client. En général, il existe de nombreux cas où un tel mécanisme serait utile.
Mise en scène
Créez un moteur de messagerie. Rapide, fiable, avec livraison garantie, avec la possibilité de rechercher de manière flexible des messages. En fonction du mécanisme, implémentez un messager (messages, appels vidéo) qui fonctionne à l'intérieur des applications 1C.
Concevez un système évolutif horizontalement. L'augmentation de la charge doit être fermée en augmentant le nombre de nœuds.
Implémentation
Nous avons décidé de ne pas intégrer la partie serveur de SV directement dans la plateforme 1C: Enterprise, mais de l'implémenter en tant que produit distinct, dont l'API peut être appelée à partir du code d'application 1C. Cela a été fait pour un certain nombre de raisons, dont la principale - je voulais permettre d'échanger des messages entre différentes applications 1C (par exemple, entre le Bureau du commerce et de la comptabilité). Différentes applications 1C peuvent s'exécuter sur différentes versions de la plateforme 1C: Enterprise, être sur des serveurs différents, etc. Dans de telles conditions, la mise en œuvre de CB en tant que produit distinct situé «sur le côté» des installations 1C est la solution optimale.
Nous avons donc décidé de faire du CB un produit distinct. Pour les petites entreprises, nous vous recommandons d'utiliser le serveur CB que nous avons installé dans notre cloud (wss: //1cdialog.com) pour éviter les frais généraux associés à l'installation et à la configuration locale du serveur. Cependant, les gros clients peuvent juger approprié d'installer leur propre serveur CB dans leurs installations. Nous avons utilisé une approche similaire dans notre produit SaaS basé sur le cloud
1cFresh - il est publié en tant que produit de diffusion pour l'installation par les clients, et est également déployé dans notre cloud
https://1cfresh.com/ .
App
Pour l'équilibrage de charge et la tolérance aux pannes, nous ne déploierons pas une application Java, mais plusieurs, nous mettrons un équilibreur de charge devant eux. Si vous devez transférer un message d'un nœud à un autre, utilisez la publication / abonnement dans Hazelcast.
Communication du client avec le serveur - par websocket. Il est bien adapté aux systèmes en temps réel.
Cache distribué
Choisissez entre Redis, Hazelcast et Ehcache. Dans la cour 2015. Redis vient de lancer un nouveau cluster (trop nouveau, effrayant), il y a une Sentinel avec un tas de restrictions. Ehcache ne sait pas comment s'assembler en cluster (cette fonctionnalité est apparue plus tard). Nous avons décidé d'essayer avec Hazelcast 3.4.
Hazelcast va au cluster hors de la boîte. En mode à nœud unique, il n'est pas très utile et ne peut servir que de cache - il ne sait pas comment vider les données sur le disque, il a perdu un nœud unique - il a perdu des données. Nous déployons plusieurs Hazelcasts entre lesquels nous sauvegardons des données critiques. Le cache n'est pas une sauvegarde - ce n'est pas dommage.
Pour nous, Hazelcast c'est:
- Référentiel de sessions utilisateur. Chaque fois, aller dans la base de données pour une session est long, donc nous mettons toutes les sessions dans Hazelcast.
- Cache. Recherche d'un profil utilisateur - archivez le cache. A écrit un nouveau message - mettez-le dans le cache.
- Rubriques pour la communication des instances d'application. Noda génère un événement et le place dans le sujet Hazelcast. Les autres nœuds d'application abonnés à cette rubrique reçoivent et traitent l'événement.
- Serrures de cluster. Par exemple, nous créons une discussion sur une clé unique (discussion-singleton dans le cadre de la base de données 1C):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
Vérifie qu'il n'y a pas de canal. Ils ont pris la serrure, vérifié à nouveau, créé. Si vous ne vérifiez pas le verrou après l'avoir pris, il est possible qu'un autre thread à ce moment soit également vérifié et essaie maintenant de créer la même discussion - mais il existe déjà. Il est impossible de verrouiller via un verrou Java synchronisé ou habituel. À travers la base - lentement, et la base est dommage, à travers Hazelcast - ce dont vous avez besoin.
Choisir un SGBD
Nous avons une expérience approfondie et réussie de travail avec PostgreSQL et de collaboration avec les développeurs de ce SGBD.
PostgreSQL n'est pas facile avec un cluster - il a
XL ,
XC ,
Citus , mais, en général, ce ne sont pas des noSQL, qui évoluent hors de la boîte. NoSQL n'était pas considéré comme le référentiel principal, il suffisait que nous prenions Hazelcast, avec lequel nous n'avions pas travaillé auparavant.
Puisque vous devez faire
évoluer une base de données relationnelle, cela signifie un
partage . Comme vous le savez, lors du partitionnement, nous divisons la base de données en parties distinctes afin que chacune d'entre elles puisse être déplacée vers un serveur distinct.
La première version de notre partitionnement impliquait la possibilité de distribuer chacune des tables de notre application sur différents serveurs dans des proportions différentes. Il y a beaucoup de messages sur le serveur A - s'il vous plaît, transférons une partie de ce tableau au serveur B. Une telle solution vient de crier sur l'optimisation prématurée, nous avons donc décidé de nous limiter à une approche multi-locataire.
Vous pouvez
lire sur le multi-locataire, par exemple, sur le site Web de
Citus Data .
Dans SV, il existe des concepts d'application et d'abonné. Une application est une installation spécifique d'une application métier, telle que l'ERP ou la comptabilité, avec ses utilisateurs et ses données métiers. Un abonné est une organisation ou une personne au nom de laquelle l'application est enregistrée sur le serveur CB. Un abonné peut enregistrer plusieurs applications et ces applications peuvent échanger des messages entre elles. L'abonné est également devenu le locataire de notre système. Les messages de plusieurs abonnés peuvent être dans une seule base physique; si nous constatons que certains abonnés ont commencé à générer beaucoup de trafic - nous le transférons vers une base physique distincte (ou même un serveur de base de données distinct).
Nous avons une base de données principale où une table de routage avec des informations sur l'emplacement de toutes les bases de données d'abonnés est stockée.
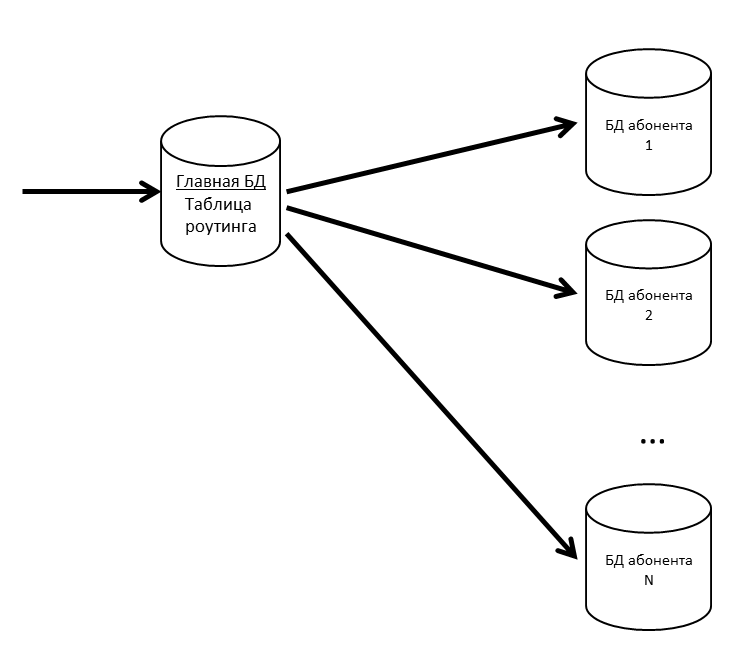
Afin que la base de données principale ne soit pas un goulot d'étranglement, nous conservons la table de routage (et d'autres données fréquemment demandées) dans le cache.
Si la base de données des abonnés commence à ralentir, nous la couperons en partitions à l'intérieur. Sur d'autres projets, nous utilisons pg_pathman pour partitionner de grandes tables.
Étant donné que la perte de messages utilisateur est mauvaise, nous prenons en charge nos bases de données avec des répliques. La combinaison de répliques synchrones et asynchrones vous permet d'être en sécurité en cas de perte de la base de données principale. La perte de message ne se produira qu'en cas de défaillance simultanée de la base de données principale et de sa réplique synchrone.
Si la réplique synchrone est perdue, la réplique asynchrone devient synchrone.
Si la base de données principale est perdue, la réplique synchrone devient la base de données principale, la réplique asynchrone devient la réplique synchrone.
Elasticsearch pour la recherche
Puisque, entre autres, CB est également un messager, ici vous avez besoin d'une recherche rapide, pratique et flexible, tenant compte de la morphologie, par des correspondances inexactes. Nous avons décidé de ne pas réinventer la roue et d'utiliser le moteur de recherche gratuit Elasticsearch, basé sur la bibliothèque
Lucene . Nous déployons également Elasticsearch dans un cluster (master - data - data) pour éliminer les problèmes en cas de panne des nœuds d'application.
Sur github, nous avons trouvé un
plugin de morphologie russe pour Elasticsearch et nous l'avons utilisé. Dans l'index Elasticsearch, nous stockons les racines des mots (définis par le plugin) et des N-grammes. Lorsque l'utilisateur saisit le texte à rechercher, nous recherchons le texte saisi parmi les N-grammes. Lorsqu'il est stocké dans l'index, le mot "textes" sera divisé en N-grammes suivants:
[ceux, tech, tex, texte, textes, ek, eks, ekst, eksts, ks, kst, kst, kst, st, st, st],
Et la racine du mot «texte» sera également enregistrée. Cette approche vous permet de rechercher à la fois au début, au milieu et à la fin du mot.
Image globale
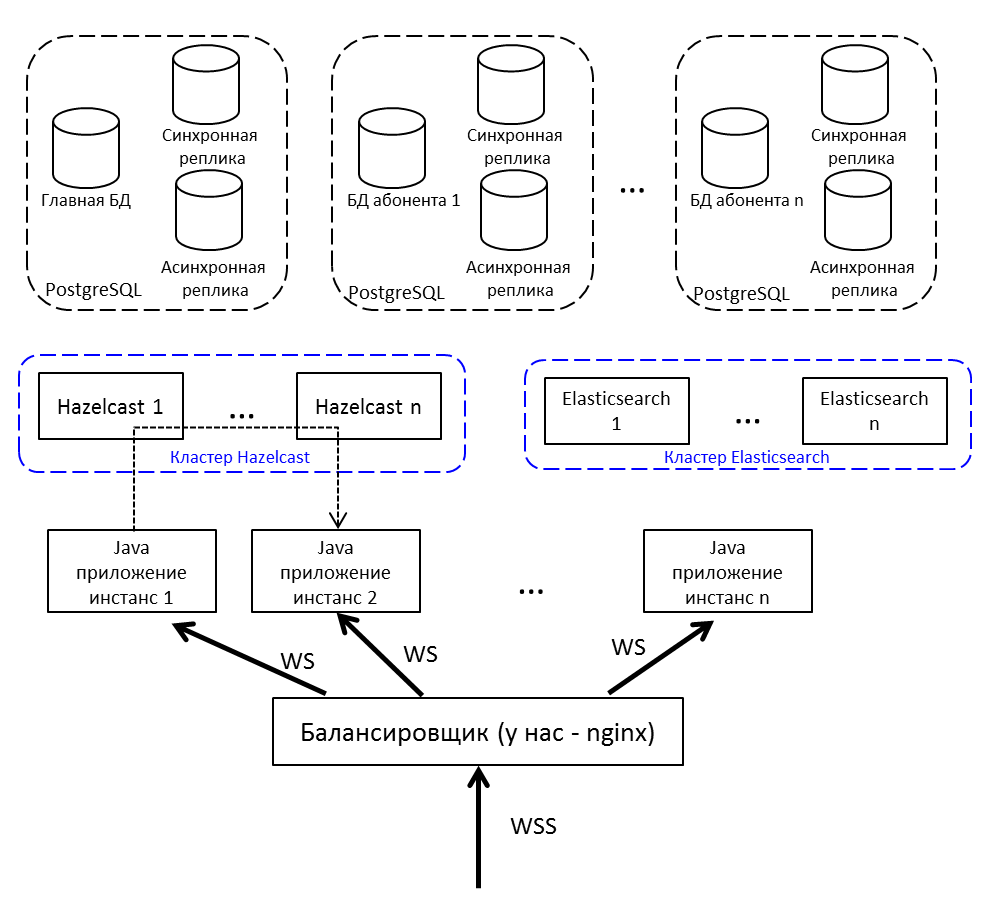
Répétition de l'image du début de l'article, mais avec des explications:
- Equilibreur Internet; nous avons nginx, ça peut être n'importe lequel.
- Les instances d'applications Java communiquent entre elles via Hazelcast.
- Pour travailler avec une prise Web, nous utilisons Netty .
- Application Java écrite en Java 8, constituée de bundles OSGi . Les plans - migration vers Java 10 et transition vers les modules.
Développement et test
Dans le processus de développement et de test de CB, nous avons rencontré un certain nombre de caractéristiques intéressantes des produits que nous utilisons.
Test de charge et fuites de mémoire
La version de chaque version de CB est un test de résistance. Il a réussi quand:
- Le test a fonctionné pendant plusieurs jours et il n'y a eu aucun déni de service
- Le temps de réponse pour les opérations clés n'a pas dépassé un seuil confortable
- La dégradation des performances par rapport à la version précédente ne dépasse pas 10%
Nous remplissons la base de test avec des données - pour cela, nous obtenons des informations sur l'abonné le plus actif du serveur de production, multiplions ses nombres par 5 (le nombre de messages, de discussions, d'utilisateurs) et ainsi nous testons.
Nous réalisons des tests de charge du système d'interaction en trois configurations:
- Test d'effort
- Connexions uniquement
- Inscription abonné
Lors du stress test, nous démarrons plusieurs centaines de threads, et ils chargent sans arrêt le système: écrire des messages, créer des discussions, obtenir une liste de messages. Nous simulons les actions des utilisateurs ordinaires (obtenir une liste de mes messages non lus, écrire à quelqu'un) et des solutions logicielles (transférer un package d'une configuration différente, traiter la notification).
Par exemple, cela fait partie du test de résistance:
- L'utilisateur se connecte.
- Demande des discussions non lues
- 50% de chance de lire les messages
- Avec une probabilité de 50% écrit des messages
- Utilisateur suivant:
- Avec une probabilité de 20% crée une nouvelle discussion.
- Sélectionne au hasard l'une de ses discussions
- Va à l'intérieur
- Demande des messages, des profils d'utilisateurs
- Crée cinq messages adressés à des utilisateurs aléatoires à partir de cette discussion.
- Hors discussion
- Se répète 20 fois
- Se déconnecte, remonte au début du script
- Le chat bot entre dans le système (émule l'échange de messages à partir du code des solutions appliquées)
- Avec une probabilité de 50%, crée un nouveau canal d'échange de données (discussion spéciale)
- Avec une probabilité de 50% écrit un message sur l'un des canaux existants
Le scénario «Only Connections» est apparu pour une raison. Il y a une situation: les utilisateurs ont connecté le système, mais ne sont pas encore impliqués. Le matin à 09h00, chaque utilisateur allume l'ordinateur, établit une connexion avec le serveur et se tait. Ces gars-là sont dangereux, il y en a beaucoup - des paquets ils n'ont que PING / PONG, mais ils gardent la connexion au serveur (ils ne peuvent pas le garder - mais soudain un nouveau message). Le test reproduit la situation où, en une demi-heure, un grand nombre de ces utilisateurs tentent de se connecter au système. Cela ressemble à un test de résistance, mais il se concentre précisément sur cette première entrée - afin qu'il n'y ait pas de défaillances (une personne n'utilise pas le système, mais il est déjà en train de tomber - il est difficile de trouver quelque chose de pire).
Le scénario d'enregistrement d'abonné provient du premier lancement. Nous avons effectué un test de résistance et étions sûrs que le système ne ralentit pas en correspondance. Mais les utilisateurs y sont allés et l'enregistrement a commencé à tomber dans un délai d'attente. Lors de l'inscription, nous avons utilisé
/ dev / random , qui est lié à l'entropie du système. Le serveur n'a pas réussi à accumuler suffisamment d'entropie et a gelé pendant des dizaines de secondes lors de la demande d'un nouveau SecureRandom. Il existe de nombreuses façons de sortir de cette situation, par exemple: passer au moins sécurisé / dev / urandom, mettre une carte spéciale qui génère l'entropie, générer des nombres aléatoires à l'avance et stocker dans le pool. Nous avons temporairement résolu le problème avec un pool, mais depuis lors, nous avons effectué un test distinct pour enregistrer de nouveaux abonnés.
En tant que générateur de charge, nous utilisons
JMeter . Il ne sait pas comment travailler avec une prise web, un plug-in est nécessaire. Les premiers dans les résultats de recherche pour "jmeter websocket" sont des
articles avec BlazeMeter , qui recommandent un
plugin de Maciej Zaleski .
Avec lui, nous avons décidé de commencer.
Presque immédiatement après le début de tests sérieux, nous avons constaté que des fuites de mémoire avaient commencé dans JMeter.
Le plugin est une grande histoire distincte, avec 176 étoiles, il a 132 fourches sur github. L'auteur lui-même ne s'y est pas engagé depuis 2015 (nous l'avons pris en 2015, puis cela n'a pas soulevé de soupçons), plusieurs problèmes de github sur les fuites de mémoire, 7 demandes de tirage non fermées.
Si vous décidez d'effectuer des tests de charge avec ce plugin, faites attention aux discussions suivantes:
- Dans un environnement multithread, la LinkedList habituelle a été utilisée, par conséquent, ils ont reçu NPE lors de l'exécution. Il est résolu soit en passant à ConcurrentLinkedDeque, soit par des blocs synchronisés. Ils ont choisi la première option pour eux-mêmes ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- Fuite de mémoire, la déconnexion ne supprime pas les informations de connexion ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- En mode streaming (lorsque le socket Web ne se ferme pas à la fin de l'exemple, mais est utilisé plus loin dans le plan), les modèles de réponse ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ) ne fonctionnent pas.
C'est l'un de ceux sur github. Qu'avons-nous fait:
- Ils ont pris la fourchette Elyran Kogan (@elyrank) - les problèmes 1 et 3 ont été corrigés
- Problème résolu 2
- Jetée mise à jour du 9.2.14 au 9.3.12
- Wrapped SimpleDateFormat dans ThreadLocal; SimpleDateFormat n'est pas thread-safe, ce qui a conduit à l'exécution de NPE
- Élimination d'une fuite de mémoire supplémentaire (la connexion a été fermée de manière incorrecte lors de la déconnexion)
Et pourtant ça coule!
Le souvenir a commencé à se terminer non pas en un jour, mais en deux. Il n'y avait absolument plus de temps, ils ont décidé d'exécuter moins de threads, mais sur quatre agents. Cela aurait dû suffire pendant au moins une semaine.
Deux jours se sont écoulés ...
Maintenant, la mémoire a commencé à s'épuiser à Hazelcast. Il était évident dans les journaux qu'après quelques jours de test, Hazelcast commence à se plaindre d'un manque de mémoire, et après un certain temps, le cluster se désagrège et les nœuds continuent de mourir individuellement. Nous avons connecté JVisualVM à Hazelcast et vu une «scie montante» - il appelait régulièrement GC, mais ne pouvait pas vider sa mémoire.
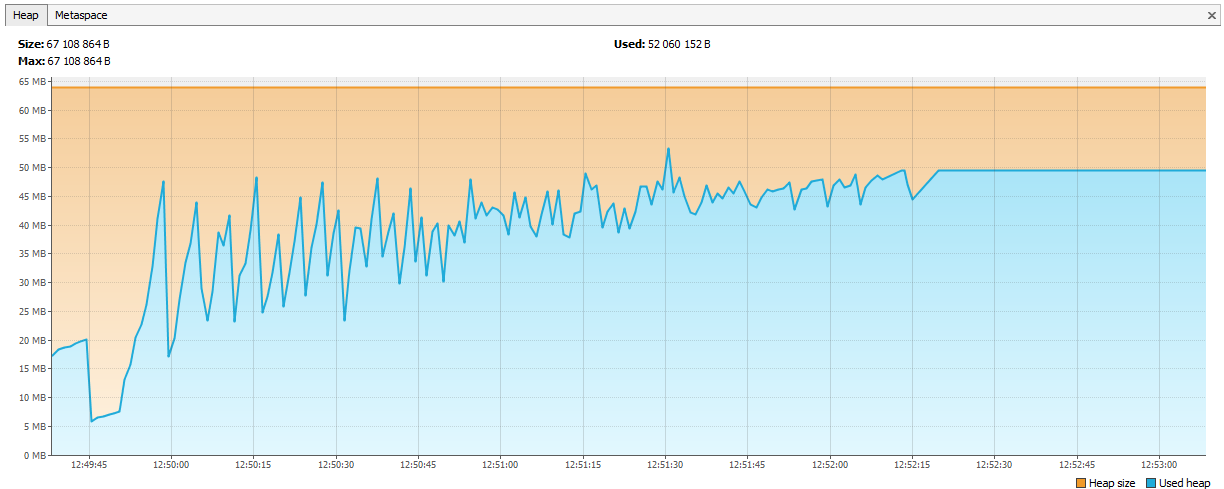
Il s'est avéré que dans Hazelcast 3.4, lors de la suppression de map / multiMap (map.destroy ()), la mémoire n'était pas complètement libérée:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888Maintenant, le bug est corrigé en 3.5, mais c'était un problème. Nous avons créé un nouveau multiMap avec des noms dynamiques et supprimé selon notre logique. Le code ressemblait à ceci:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
Appeler:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
multiMap a été créé pour chaque abonnement et a été supprimé lorsqu'il n'était pas nécessaire. Nous avons décidé de démarrer Map <String, Set>, la clé sera le nom de l'abonnement et les valeurs seront les identifiants de session (à partir desquels vous pourrez ensuite obtenir les ID utilisateur, si nécessaire).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
Les graphiques se redressèrent.
Qu'avons-nous appris d'autre sur les tests de résistance
- JSR223 doit être écrit dans un cache de compilation groovy et activé - c'est beaucoup plus rapide. Lien
- Les graphiques Jmeter-Plugins sont plus faciles à comprendre que les graphiques standard. Lien
À propos de notre expérience avec Hazelcast
Hazelcast était un nouveau produit pour nous, nous avons commencé à travailler avec lui à partir de la version 3.4.1, maintenant notre serveur de production a la version 3.9.2 (au moment de la rédaction, la dernière version de Hazelcast est 3.10).
Génération d'ID
Nous avons commencé avec des identifiants entiers. Imaginons que nous ayons besoin d'un autre Long pour une nouvelle entité. La séquence ne rentre pas dans la base de données, les tables participent au partitionnement - il s'avère qu'il y a un ID de message = 1 dans DB1 et un ID de message = 1 dans DB2, vous ne pouvez pas mettre un tel ID dans Elasticsearch, soit dans Hazelcast, mais le pire est de vouloir réduire les données de deux bases de données en une seule (par exemple, décider qu'une seule base de données est suffisante pour ces abonnés). Vous pouvez créer plusieurs AtomicLongs dans Hazelcast et y conserver le compteur, puis les performances d'obtention d'un nouvel ID sont incrementAndGet plus le temps d'une demande dans Hazelcast. Mais il y a quelque chose de plus optimal dans Hazelcast - FlakeIdGenerator. Chaque client se voit attribuer une plage d'ID au contact, par exemple, le premier de 1 à 10 000, le second de 10 001 à 20 000, etc. Désormais, le client peut émettre de nouveaux identifiants indépendamment jusqu'à la fin de la plage qui lui est attribuée. Cela fonctionne rapidement, mais lorsque vous redémarrez l'application (et le client Hazelcast), une nouvelle séquence commence - d'où les lacunes, etc. De plus, les développeurs ne savent pas très bien pourquoi les ID sont entiers, mais ils vont si différemment. Nous avons tous pesé et opté pour les UUID.
Soit dit en passant, pour ceux qui veulent ressembler à Twitter, il existe une telle bibliothèque Snowcast - il s'agit d'une implémentation Snowflake en plus de Hazelcast. Vous pouvez le voir ici:
github.com/noctarius/snowcastgithub.com/twitter/snowflakeMais nous n'avons pas atteint ses mains.
TransactionalMap.replace
Autre surprise: TransactionalMap.replace ne fonctionne pas. Voici un test:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
J'ai dû écrire mon remplacement en utilisant getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
Testez non seulement les structures de données régulières, mais aussi leurs versions transactionnelles. Il arrive que IMap fonctionne, mais TransactionalMap a disparu.
Attachez un nouveau JAR sans interruption
Tout d'abord, nous avons décidé d'enregistrer des objets de nos classes dans Hazelcast. Par exemple, nous avons une classe Application, nous voulons l'enregistrer et la lire. Enregistrer:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
Nous lisons:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
Tout fonctionne. Ensuite, nous avons décidé de construire un index dans Hazelcast pour le rechercher:
map.addIndex("subscriberId", false);
Et lors de l'écriture d'une nouvelle entité, ils ont commencé à recevoir une exception ClassNotFoundException. Hazelcast a essayé de compléter l'index, mais ne savait rien de notre classe et voulait qu'il ait un JAR avec cette classe. Nous l'avons fait, tout a fonctionné, mais un nouveau problème est apparu: comment mettre à jour le JAR sans arrêter complètement le cluster? Hazelcast ne récupère pas le nouveau JAR lors d'une mise à niveau par pod. A ce moment, nous avons décidé que nous pourrions très bien vivre sans chercher par index. Après tout, si vous utilisez Hazelcast comme stockage de valeur-clé, tout fonctionnera-t-il? Pas vraiment. Là encore, les différents comportements d'IMap et TransactionalMap. Lorsque IMap n'a pas d'importance, TransactionalMap génère une erreur.
IMap Nous écrivons 5000 objets, lisons-le. Tout est attendu.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
Et cela ne fonctionne pas dans la transaction, nous obtenons une exception ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
En 3.8, le mécanisme de déploiement de classe d'utilisateurs est apparu. Vous pouvez affecter un nœud principal et mettre à jour le fichier JAR dessus.
Maintenant, nous avons complètement changé l'approche: nous le sérialisons en JSON et l'enregistrons dans Hazelcast. Hazelcast n'a pas besoin de connaître la structure de nos classes, mais nous pouvons mettre à jour sans temps d'arrêt. Le contrôle de version des objets de domaine est contrôlé par l'application. Différentes versions de l'application peuvent être lancées en même temps, et il est possible qu'une nouvelle application écrive des objets avec de nouveaux champs, mais l'ancienne ne connaît pas ces champs. Et en même temps, la nouvelle application lit les objets enregistrés par l'ancienne application, dans lesquels il n'y a pas de nouveaux champs. Nous gérons de telles situations à l'intérieur de l'application, mais pour plus de simplicité, nous ne modifions ni ne supprimons les champs, nous étendons les classes uniquement en ajoutant de nouveaux champs.
Comment nous fournissons des performances élevées
Quatre voyages à Hazelcast - bon, deux à la base de données - mauvais
Il est toujours préférable d'accéder au cache pour les données que dans la base de données, mais vous ne souhaitez pas stocker les enregistrements non réclamés. La décision sur quoi mettre en cache, nous reportons à la dernière étape de développement. Lorsque la nouvelle fonctionnalité est encodée, nous activons PostgreSQL pour enregistrer toutes les requêtes (log_min_duration_statement à 0) et exécutons le test de charge pendant 20 minutes. À l'aide des journaux collectés, des utilitaires comme pgFouine et pgBadger peuvent créer des rapports analytiques. Dans les rapports, nous recherchons principalement des requêtes lentes et fréquentes. Pour les requêtes lentes, nous construisons un plan d'exécution (EXPLAIN) et évaluons si une telle requête peut être accélérée. Les demandes fréquentes pour les mêmes données d'entrée sont bien mises en cache. Nous essayons de garder les demandes «à plat», une table par demande.
Fonctionnement
SV en tant que service en ligne a été lancé au printemps 2017, puisqu'un produit SV distinct a été lancé en novembre 2017 (à l'époque en version bêta).
Pendant plus d'un an de fonctionnement, de graves problèmes de fonctionnement du service en ligne de CB ne se sont pas produits. Nous surveillons le service en ligne via
Zabbix , collectons et déployons depuis
Bamboo .
Le kit de distribution du serveur CB est livré sous forme de packages natifs: RPM, DEB, MSI. De plus pour Windows, nous fournissons un seul programme d'installation sous la forme d'un EXE, qui installe le serveur, Hazelcast et Elasticsearch sur une seule machine. Au début, nous appelions cette version de l'installation "démo", mais maintenant il est devenu clair que c'est l'option de déploiement la plus populaire.