
J'adore Ceph. Je travaille avec lui depuis 4 ans (0.80.x - 12.2.6 , 12.2.5). Parfois, je suis tellement passionné par lui que je passe des soirées et des nuits en sa compagnie, et pas avec ma copine. J'ai rencontré divers problèmes avec ce produit et je continue d'en vivre avec certains à ce jour. Parfois, je me réjouissais de décisions faciles et parfois je rêvais de rencontrer des développeurs pour exprimer mon indignation. Mais Ceph est toujours utilisé dans notre projet et il est possible qu'il soit utilisé dans de nouvelles tâches, au moins par moi. Dans cette histoire, je partagerai notre expérience de fonctionnement de Ceph, d'une certaine manière je m'exprimerai sur le sujet de ce que je n'aime pas dans cette solution et peut-être aider ceux qui ne font que la regarder. Les événements qui ont commencé il y a environ un an lorsque j'ai apporté le Dell EMC ScaleIO, maintenant connu sous le nom de Dell EMC VxFlex OS, m'ont poussé à écrire cet article.
Ce n'est en aucun cas une publicité pour Dell EMC ou leur produit! Personnellement, je ne suis pas très bon avec les grandes entreprises et les boîtes noires comme VxFlex OS. Mais comme vous le savez, tout dans le monde est relatif et en utilisant l'exemple de VxFlex OS, il est très pratique de montrer ce qu'est Ceph en termes de fonctionnement, et je vais essayer de le faire.
Paramètres Il s'agit de nombres à 4 chiffres!
Services Ceph tels que MON, OSD, etc. ont différents paramètres pour configurer toutes sortes de sous-systèmes. Les paramètres sont définis dans le fichier de configuration, les démons les lisent au moment du lancement. Certaines valeurs peuvent être facilement modifiées à la volée en utilisant le mécanisme "d'injection", qui est décrit ci-dessous. Tout est presque super, si vous omettez le moment où il y a des centaines de paramètres:
Marteau:
> ceph daemon mon.a config show | wc -l 863
Lumineux:
> ceph daemon mon.a config show | wc -l 1401
Il s'avère que ~ 500 nouveaux paramètres en deux ans. En général, le paramétrage est cool, ce n'est pas cool qu'il y ait des difficultés à comprendre 80% de cette liste. La documentation décrit par mes estimations ~ 20% et à certains endroits est ambiguë. Une compréhension de la signification de la plupart des paramètres doit être trouvée dans le github du projet ou dans les listes de diffusion, mais cela n'aide pas toujours.
Voici un exemple de plusieurs paramètres qui m'intéressaient tout récemment, je les ai trouvés sur le blog d'un Ceph-gadfly:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
Codez les commentaires dans l'esprit des meilleures pratiques. Comme si, je comprends les mots et même à peu près de quoi ils parlent, mais ce que cela me donnera ne l'est pas.
Ou ici: osd_op_threads dans Luminous avait disparu et seul le code source a aidé à trouver un nouveau nom: threads osd_peering_wq
J'aime aussi le fait qu'il existe des options particulièrement holistiques. Ici, mec montre que l'augmentation de rgw_num _rados_handles est bonne :
et l'autre mec pense que> 1 est impossible et même dangereux .
Et ma chose préférée est lorsque les débutants donnent des exemples de configuration dans leurs articles de blog, où tous les paramètres sont copiés sans réfléchir (il me semble) à partir d'un autre blog du même genre, et donc un tas de paramètres que personne ne connaît, sauf l'auteur du code. config to config.
Je brûle aussi sauvagement avec ce qu'ils ont fait dans Luminous. Il y a une fonctionnalité super cool - changer les paramètres à la volée, sans redémarrer les processus. Vous pouvez, par exemple, modifier le paramètre d'un OSD spécifique:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
ou mettez '*' au lieu de 12 et la valeur sera modifiée sur tous les OSD. C'est vraiment cool, vraiment. Mais, comme beaucoup à Ceph, cela se fait avec le pied gauche. La conception de Bai ne permet pas de modifier toutes les valeurs des paramètres à la volée. Plus précisément, ils peuvent être définis et ils apparaîtront modifiés dans la sortie, mais en fait, seuls quelques-uns sont relus et réappliqués. Par exemple, vous ne pouvez pas modifier la taille du pool de threads sans redémarrer le processus. Pour que l'exécuteur de l'équipe comprenne qu'il est inutile de modifier le paramètre de cette manière - ils ont décidé d'imprimer un message. Bonjour
Par exemple:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Ambigu. En effet, le retrait des bassins devient possible après l'injection. Autrement dit, cet avertissement n'est pas pertinent pour ce paramètre. D'accord, mais il existe encore des centaines de paramètres, y compris des paramètres très utiles, qui comportent également un avertissement et il n'y a aucun moyen de vérifier leur applicabilité réelle. Pour le moment, je ne peux même pas comprendre par le code quels paramètres sont appliqués après l'injection et lesquels ne le sont pas. Pour la fiabilité, vous devez redémarrer les services et cela, vous le savez, exaspère. Enragés parce que je sais qu'il y a un mécanisme d'injection.
Et VxFlex OS? Des processus similaires comme MON (dans VxFlex c'est MDM), OSD (SDS dans VxFlex) ont également des fichiers de configuration, dans lesquels il y a des dizaines de paramètres pour tous. Certes, leurs noms ne disent rien non plus, mais la bonne nouvelle est que nous n'avons jamais eu recours à eux pour brûler autant qu'avec Ceph.
Dette technique
Lorsque vous commencez à vous familiariser avec Ceph avec la version la plus pertinente pour aujourd'hui, alors tout semble aller bien et vous voulez écrire un article positif. Mais quand vous vivez avec lui dans la prod de la version 0.80, alors tout ne semble pas si rose.
Avant Jewel, les processus Ceph s'exécutaient en tant que root. Jewel a décidé de travailler à partir de l'utilisateur «ceph», ce qui a nécessité un changement de propriétaire pour tous les répertoires utilisés par les services Ceph. Il semblerait que cela? Imaginez un OSD qui dessert un disque magnétique SATA pleine capacité de 2 To. Ainsi, le démontage d'un tel disque, en parallèle (vers différents sous-répertoires) avec une utilisation complète du disque prend 3-4 heures. Imaginez, par exemple, que vous ayez 3 centaines de tels disques. Même si vous mettez à jour les nœuds (visualisez immédiatement 8 à 12 disques), vous obtenez une mise à jour assez longue, dans laquelle le cluster aura un OSD de différentes versions et une réplique de données est inférieure au moment de la mise à jour du serveur. En général, nous pensions que c'était absurde, reconstruit les packages Ceph et laissé OSD en cours d'exécution en tant que root. Nous avons décidé qu'en entrant ou en remplaçant l'OSD, nous les transférerions à un nouvel utilisateur. Maintenant, nous changeons 2-3 disques par mois et en ajoutons 1 à 2, je pense que nous pouvons le gérer d'ici 2022).
CRUSH Tunables
CRUSH est le cœur de Ceph, tout tourne autour de lui. Il s'agit de l'algorithme par lequel, de manière pseudo-aléatoire, l'emplacement des données est sélectionné et grâce auquel les clients travaillant avec le cluster RADOS sauront sur quel OSD les données (objets) dont ils ont besoin sont stockées. La principale caractéristique de CRUSH est qu'il n'y a pas besoin de serveurs de métadonnées, tels que Luster ou IBM GPFS (maintenant Spectrum Scale). CRUSH permet aux clients et à l'OSD d'interagir directement entre eux. Bien que, bien sûr, il soit difficile de comparer le stockage d'objets RADOS primitif et les systèmes de fichiers, que j'ai donnés en exemple, mais je pense que l'idée est claire.
Les ajustables CRUSH, à leur tour, sont un ensemble de paramètres / drapeaux qui affectent le fonctionnement de CRUSH, le rendant plus efficace, au moins en théorie.
Ainsi, lors de la mise à niveau de Hammer vers Jewel (testez naturellement), un avertissement est apparu, disant que le profil ajustable a des paramètres qui ne sont pas optimaux pour la version actuelle (Jewel) et il est recommandé de basculer le profil sur l'optimal. En général, tout est clair. Le dock dit que c'est très important et c'est la bonne façon, mais il est également dit qu'après le changement de données, il y aura une rébellion de 10% des données. 10% - cela ne semble pas effrayant, mais nous avons décidé de le tester. Pour un cluster, c'est environ 10 fois moins que sur un prod, avec le même nombre de PG par OSD, rempli de données de test, on a une rébellion de 60%! Imaginez, par exemple, avec 100 To de données, 60 To commencent à se déplacer entre les OSD et cela avec une charge client en constante évolution exigeant une latence! Si je n'ai pas encore dit, nous fournissons s3 et nous n'avons pas beaucoup moins de charge sur rgw même la nuit, dont il y en a 8 et 4 de plus sous les sites Web statiques. En général, nous avons décidé que ce n'était pas notre chemin, d'autant plus que faire une telle reconstruction sur la nouvelle version, avec laquelle nous n'avions pas travaillé dans la prod, était au moins trop optimiste. De plus, nous avions de grands index de bucket qui sont très mal reconstruits et c'était aussi la raison du retard dans le changement de profil. À propos des indices seront séparément un peu plus bas. Au final, nous avons simplement supprimé l'avertissement et décidé d'y revenir plus tard.
Et lors du changement de profil lors des tests, les clients cephfs qui se trouvent dans les noyaux CentOS 7.2 sont tombés car ils ne pouvaient pas fonctionner avec le nouvel algorithme de hachage du nouveau profil fourni. Nous n'utilisons pas cephfs dans la prod, mais si nous en avions l'habitude, ce serait une autre raison de ne pas changer de profil.
Soit dit en passant, le dock dit que si ce qui se passe pendant la rébellion ne vous convient pas, vous pouvez annuler le profil. En fait, après une nouvelle installation de la version Hammer et une mise à niveau vers Jewel, le profil ressemble à ceci:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
Il est important qu'il soit "inconnu" et si vous essayez d'arrêter la reconstruction en le basculant sur "hérité" (comme indiqué dans le dock) ou même sur "marteau", alors la rébellion ne s'arrêtera pas, elle continuera simplement conformément aux autres paramètres ajustables, et non " optimal. " En général, tout doit être soigneusement vérifié et revérifié, ceph n'est pas fiable.
CRUSH trade-of
Comme vous le savez, tout dans ce monde est équilibré et des inconvénients sont appliqués à tous les avantages. L'inconvénient de CRUSH est que les PG sont inégalement répartis sur différents OSD même avec le même poids de ces derniers. De plus, rien n'empêche différents PG de croître à des vitesses différentes, tandis que la fonction de hachage tombera. Plus précisément, nous avons une plage d'utilisation de l'OSD de 48 à 84%, malgré le fait qu'ils ont la même taille et, par conséquent, le poids. Nous essayons même de rendre les serveurs égaux en poids, mais c'est ainsi, juste notre perfectionnisme, pas plus. Et avec le fait que les E / S sont réparties de manière inégale sur les disques, le pire est que lorsque vous atteignez le statut complet (95%) d'au moins un OSD dans le cluster, l'enregistrement entier s'arrête et le cluster passe en lecture seule. L'ensemble du cluster! Et peu importe que le cluster soit toujours plein d'espace. Tout, la finale, sortez! Il s'agit d'une caractéristique architecturale de CRUSH. Imaginez que vous êtes en vacances, certains OSD ont franchi la barre des 85% (le premier avertissement par défaut), et vous avez 10% en stock pour empêcher l'enregistrement de s'arrêter. Et 10% avec un enregistrement actif n'est pas tellement / long. Idéalement, avec une telle conception, Ceph a besoin d'une personne de service qui puisse suivre les instructions préparées dans de tels cas.
Nous avons donc décidé que cela signifie déséquilibrer les données du cluster, car plusieurs OSD étaient proches du seuil proche (85%).
Il existe plusieurs façons:
Le moyen le plus simple est légèrement inutile et peu efficace, car les données elles-mêmes peuvent ne pas bouger de l'OSD bondé ou le mouvement sera négligeable.
- Modifier le poids permanent de l'OSD (POIDS)
Cela entraîne une modification du poids de toute la hiérarchie des compartiments supérieurs (terminologie CRUSH), du serveur OSD, du centre de données, etc. et, par conséquent, au mouvement des données, y compris à partir des OSD dont elles ne sont pas nécessaires.
Nous avons essayé, réduit le poids d'un OSD, après que les données en reconstruisant un autre ont été remplies, nous l'avons réduit, puis le troisième et nous avons réalisé que nous jouerions cela pendant longtemps.
- Modifier le poids OSD non permanent (REWEIGHT)
C'est ce que l'on fait en appelant «ceph osd reweight-by-use». Cela entraîne une modification du poids d'ajustement dit OSD, et le poids du godet supérieur ne change pas. En conséquence, les données sont équilibrées entre différents OSD d'un serveur, pour ainsi dire, sans dépasser les limites du compartiment CRUSH. Nous avons vraiment aimé cette approche, nous avons examiné la marche à sec quels changements seraient et effectués sur la prod. Tout allait bien jusqu'à ce que le processus de rééquilibrage prenne une place intermédiaire. Encore une fois sur Google, en lisant les newsletters, en expérimentant différentes options, et finalement, il s'avère que l'arrêt a été causé par le manque de certains paramètres ajustables dans le profil mentionné ci-dessus. Encore une fois, nous étions pris de dettes techniques. En conséquence, nous avons suivi la voie de l'ajout de disques et de la reconstruction la plus inefficace. Heureusement, nous devions encore le faire car Il était prévu de changer de profil CRUSH avec une marge de capacité suffisante.
Oui, nous connaissons l'équilibreur (lumineux et supérieur), qui fait partie de mgr, qui est conçu pour résoudre le problème de la distribution inégale des données en déplaçant PG entre les OSD, par exemple, la nuit. Mais je n'ai pas encore entendu de critiques positives sur son travail, même dans le Mimic actuel.
Vous direz probablement que la dette technique est purement notre problème et je serais probablement d'accord. Mais pendant quatre ans avec Ceph dans la prod, nous n'avons enregistré qu'un seul temps d'arrêt s3, qui a duré une heure entière. Et puis, le problème n'était pas dans RADOS, mais dans RGW, qui, après avoir tapé leurs 100 threads par défaut, s'est accroché et la plupart des utilisateurs n'ont pas répondu aux demandes. C'était toujours sur Hammer. À mon avis, c'est un bon indicateur et il est atteint car nous ne faisons pas de mouvements brusques et sommes plutôt sceptiques à propos de tout chez Ceph.
GC sauvage
Comme vous le savez, la suppression de données directement du disque est une tâche assez exigeante et dans les systèmes avancés, la suppression est retardée ou ne se fait pas du tout. Ceph est également un système avancé, et dans le cas de RGW, lors de la suppression d'un objet s3, les objets RADOS correspondants ne sont pas immédiatement supprimés du disque. RGW marque les objets s3 comme supprimés, et un flux gc séparé supprime les objets directement des pools RADOS et, en conséquence, est reporté des disques. Après la mise à jour vers Luminous, le comportement de gc a considérablement changé, il a commencé à fonctionner de manière plus agressive, bien que les paramètres de gc soient restés les mêmes. Par le mot sensiblement, je veux dire que nous avons commencé à voir gc travailler sur la surveillance externe du service pour sauter la latence. Cela a été accompagné d'un haut E / S dans le pool rgw.gc. Mais le problème auquel nous sommes confrontés est bien plus épique que le simple E / S. Lorsque gc est en cours d'exécution, de nombreux journaux du formulaire sont générés:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
Où 0 au début est le niveau de journalisation auquel ce message est imprimé. Pour ainsi dire, il n'y a nulle part où abaisser la journalisation en dessous de zéro. En conséquence, ~ 1 Go de journaux ont été générés en nous par un OSD en quelques heures, et tout aurait été bien si les nœuds ceph n'étaient pas sans disque ... Nous chargeons l'OS via PXE directement dans la mémoire et n'utilisons pas de disque local ou NFS, NBD pour la partition système (/). Il s'avère que les serveurs sont sans état. Après un redémarrage, l'état entier est roulé par automatisation. Comment cela fonctionne, je vais en quelque sorte décrire dans un article séparé, maintenant il est important que 6 Go de mémoire soient alloués pour "/", dont ~ 4 est généralement libre. Nous envoyons tous les journaux à Graylog et utilisons une politique de rotation des journaux plutôt agressive et ne rencontrons généralement aucun problème de débordement de disque / RAM. Mais nous n'étions pas prêts pour cela, avec 12 OSD, le serveur "/" s'est rempli très rapidement, les préposés à l'heure n'ont pas répondu au déclencheur dans Zabbix et OSD a juste commencé à s'arrêter en raison de l'impossibilité d'écrire un journal. En conséquence, nous avons réduit l'intensité de gc, le ticket n'a pas commencé car Il était déjà là, et nous avons ajouté un script à cron, dans lequel nous forçons les journaux OSD à tronquer lorsqu'un certain montant est dépassé sans attendre la rotation du journal. Soit dit en passant, le niveau de journalisation a été augmenté .
Groupes de placement et évolutivité louée
À mon avis, PG est l'abstraction la plus difficile à comprendre. PG est nécessaire pour rendre CRUSH plus efficace. L'objectif principal de PG est de regrouper des objets pour réduire la consommation de ressources, augmenter la productivité et l'évolutivité. Adresser des objets directement, individuellement, sans les combiner en PG serait très coûteux.
Le principal problème de PG est de déterminer leur nombre pour un nouveau pool. Depuis le blog Ceph:
"Choisir le bon nombre de PG pour votre cluster est un peu un art noir et un cauchemar pour la convivialité."
Ceci est toujours très spécifique à une installation particulière et nécessite beaucoup de réflexion et de calcul.
Recommandations clés:
- Trop de PG sur l'OSD sont mauvais; il y aura un dépassement des ressources pour leur maintenance et leurs freins pendant le rééquilibrage / récupération.
- Peu de PG sur OSD sont mauvais, les performances en souffriront et les OSD seront remplis de manière inégale.
- Le nombre PG doit être un multiple de degré 2. Cela aidera à obtenir "la puissance de CRUSH".
Et ici ça brûle avec moi. Les PG ne sont pas limités en volume ou en nombre d'objets. Combien de ressources (en nombres réels) sont nécessaires pour desservir un PG? Cela dépend-il de sa taille? Cela dépend-il du nombre de répliques de cette PG? Dois-je prendre un bain de vapeur si j'ai suffisamment de mémoire, des processeurs rapides et un bon réseau?
Et vous devez également penser à la croissance future du cluster. Le nombre PG ne peut pas être réduit - seulement augmenté. En même temps, il n'est pas recommandé de le faire, car cela impliquera, en substance, de diviser une partie de PG en une reconstruction nouvelle et sauvage.
"L'augmentation du nombre de PG d'un pool est l'un des événements les plus percutants d'un cluster Ceph et doit être évité si possible pour les clusters de production."
Par conséquent, vous devez penser à l'avenir immédiatement, si possible.
Un vrai exemple.
Un cluster de 3 serveurs avec 14x2 To OSD chacun, un total de 42 OSD. Réplique 3, endroit utile ~ 28 To. Pour être utilisé sous S3, vous devez calculer le nombre de PG pour le pool de données et le pool d'index. RGW utilise plus de pools, mais les deux sont principaux.
Nous allons dans la calculatrice PG (il y a une telle calculatrice), nous considérons qu'avec les 100 PG recommandés sur l'OSD, nous n'obtenons que 1312 PG. Mais tout n'est pas si simple: nous en avons un en introduction - le cluster va certainement croître trois fois en un an, mais le fer sera acheté un peu plus tard. Nous augmentons trois fois les "PG cibles par OSD", à 300 et nous obtenons 4480 PG.
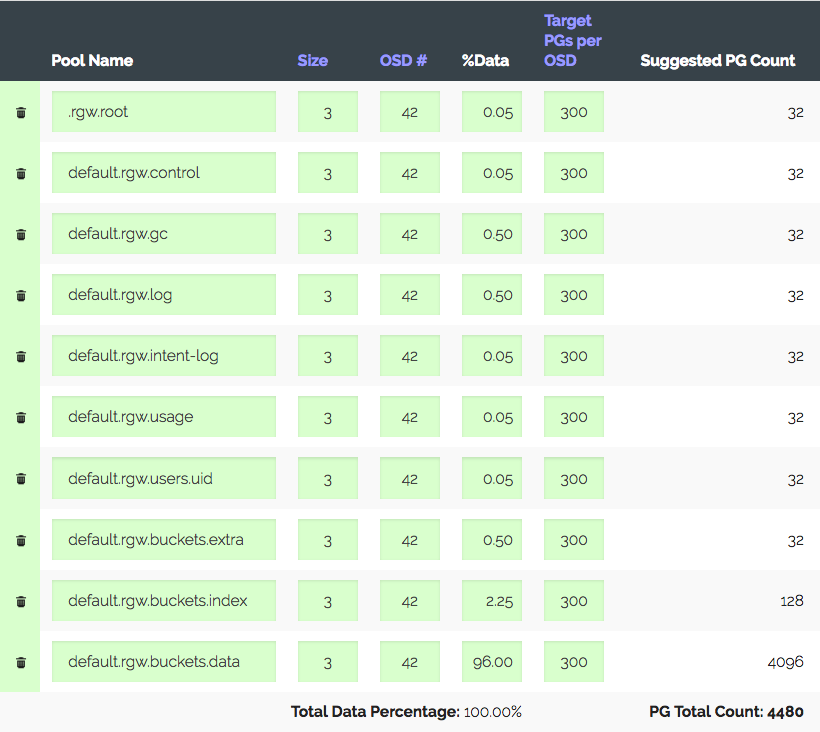
Définissez le nombre de PG pour les pools correspondants - nous recevons un avertissement: trop de PG par OSD ... sont arrivés. Reçu ~ 300 PG sur OSD avec une limite de 200 (Lumineux). Auparavant, c'était 300. Et la chose la plus intéressante est que tous les PG inutiles ne sont pas autorisés à regarder, c'est-à-dire qu'il ne s'agit pas simplement d'un avertissement. En conséquence, nous pensons que nous faisons tout correctement, en élevant les limites, en désactivant l'avertissement et en poursuivant.
Un autre exemple réel est plus intéressant.
S3, volume utile de 152 To, 252 OSD à 1,81 To, ~ 105 PG sur OSD. Le cluster a grandi progressivement, tout allait bien jusqu'à ce que les nouvelles lois de notre pays imposent une croissance à 1 PB, soit + ~ 850 To, et en même temps, vous devez maintenir des performances, ce qui est maintenant assez bon pour S3. Supposons que nous prenions des disques de 6 (5,7 réels) To et en tenant compte de la réplique 3, nous obtenons + 447 OSD. En tenant compte des actuels, nous obtenons 699 OSD avec 37 PG chacun, et si nous prenons en compte des poids différents, il s'avère que les anciens OSD n'ont qu'une douzaine de PG. Vous me dites donc dans quelle mesure cela fonctionnera? Les performances d'un cluster avec un nombre différent de PG sont assez difficiles à mesurer synthétiquement, mais les tests que j'ai menés montrent que pour des performances optimales, il est nécessaire de 50 PG à 2 To OSD. Et qu'en est-il de la poursuite de la croissance? Sans augmenter le nombre de PG, vous pouvez accéder au mappage de PG à OSD 1: 1. Peut-être que je ne comprends pas quelque chose?
Oui, vous pouvez créer un nouveau pool pour RGW avec le nombre de PG souhaité et lui associer une région S3 distincte. Ou même créez un nouveau cluster à proximité. Mais vous devez admettre que ce sont toutes des béquilles. Et il s'avère qu'il semble être un Ceph bien évolutif en raison de son concept, PG évolue avec des réserves. Vous devrez soit vivre avec des vorings désactivés en préparation de la croissance, soit à un moment donné reconstruire toutes les données du cluster, ou marquer des performances et vivre avec ce qui se passe. Ou passez par tout cela.
Je suis heureux que les développeurs de Ceph comprennent que PG est une abstraction complexe et superflue pour l'utilisateur et qu'il vaut mieux ne pas le savoir.
"Dans Luminous, nous avons pris des mesures majeures pour éliminer définitivement l'un des moyens les plus courants de conduire votre cluster dans un fossé, et nous nous efforçons de masquer complètement les PG afin qu'ils ne soient pas quelque chose que la plupart des utilisateurs devront jamais savoir ou pensez à ".
Dans vxFlex, il n'y a pas de concept de PG ou d'analogues. Vous ajoutez simplement des disques au pool et c'est tout. Et ainsi de suite jusqu'à 16 PB. Imaginez, rien n'a besoin d'être calculé, il n'y a pas de tas de statuts de ces PG, les disques sont éliminés uniformément tout au long de la croissance. Parce que les disques sont donnés à vxFlex dans son ensemble (il n'y a pas de système de fichiers au-dessus d'eux), il n'y a aucun moyen d'évaluer la plénitude et il n'y a pas de problème du tout. Je ne sais même pas comment vous dire à quel point c'est agréable.
"Besoin d'attendre SP1"
Une autre histoire de «succès». Comme vous le savez, RADOS est le stockage de valeur-clé le plus primitif. S3, implémenté au-dessus de RADOS, est également primitif, mais toujours un peu plus fonctionnel. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
Performances
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
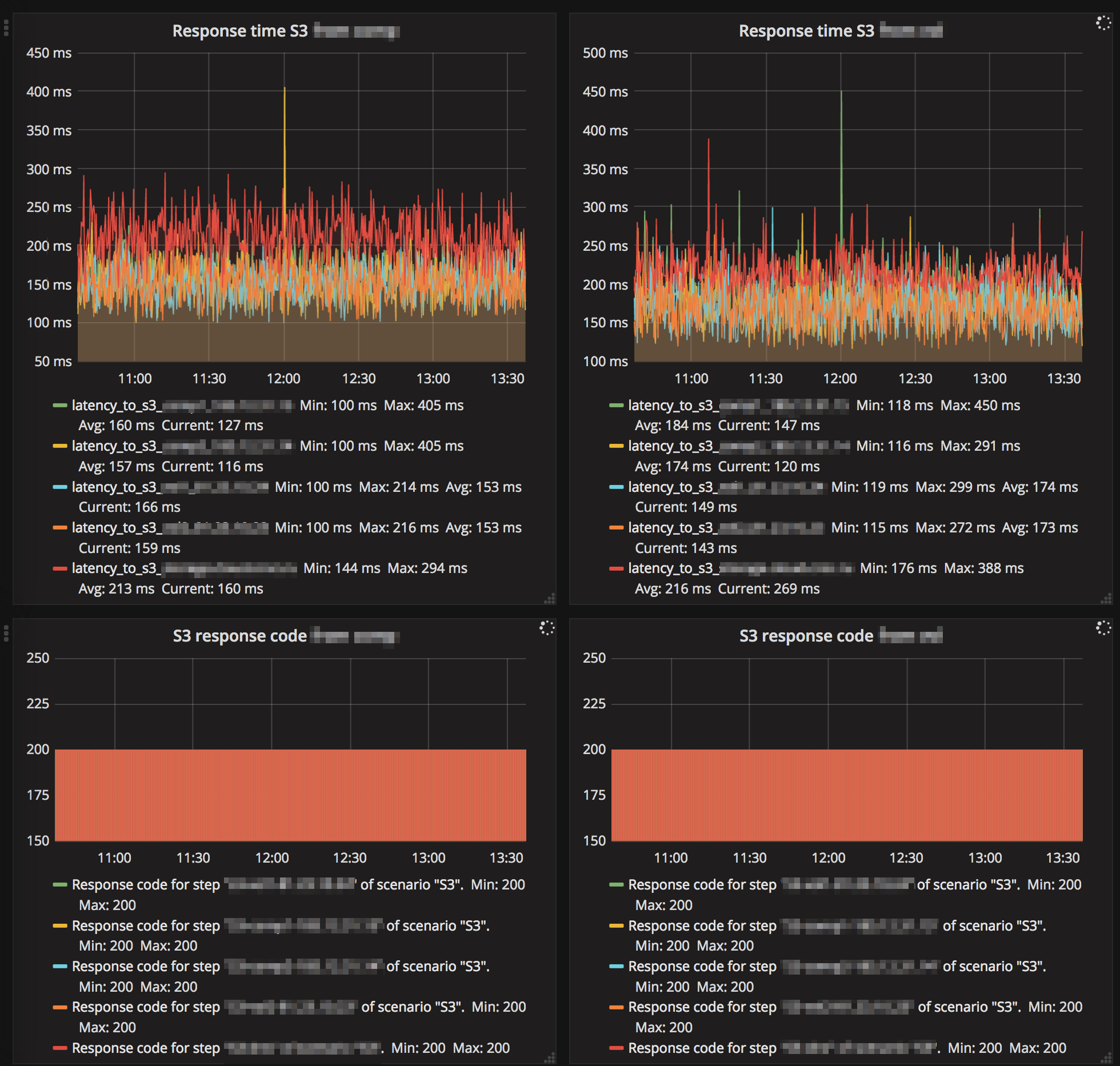
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
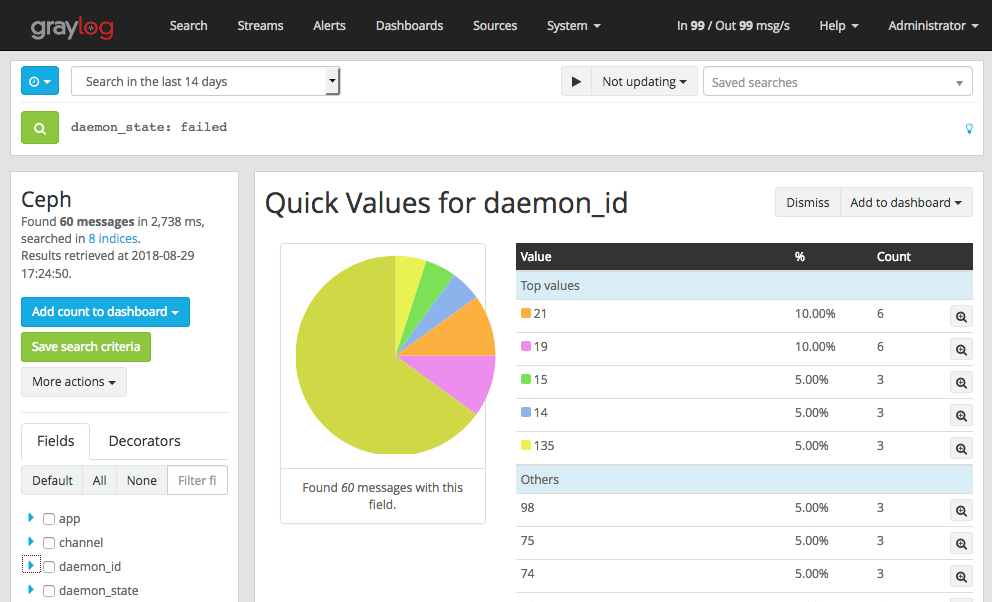
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
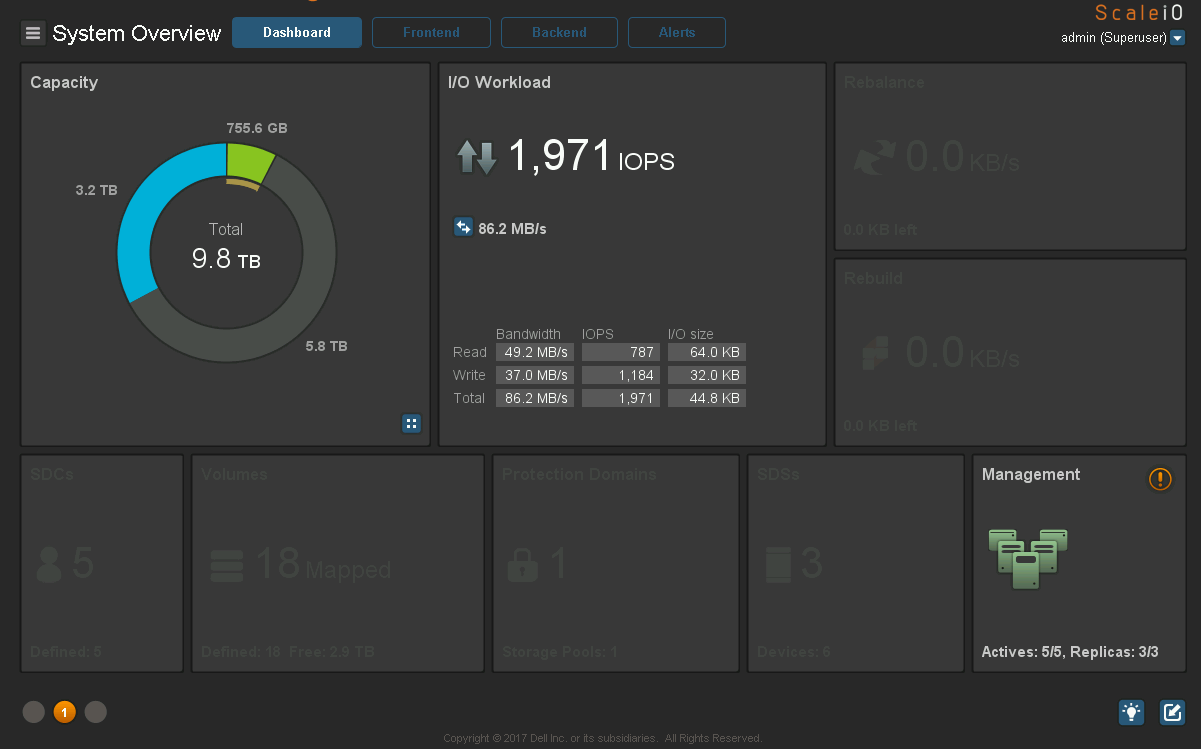
:

IO :
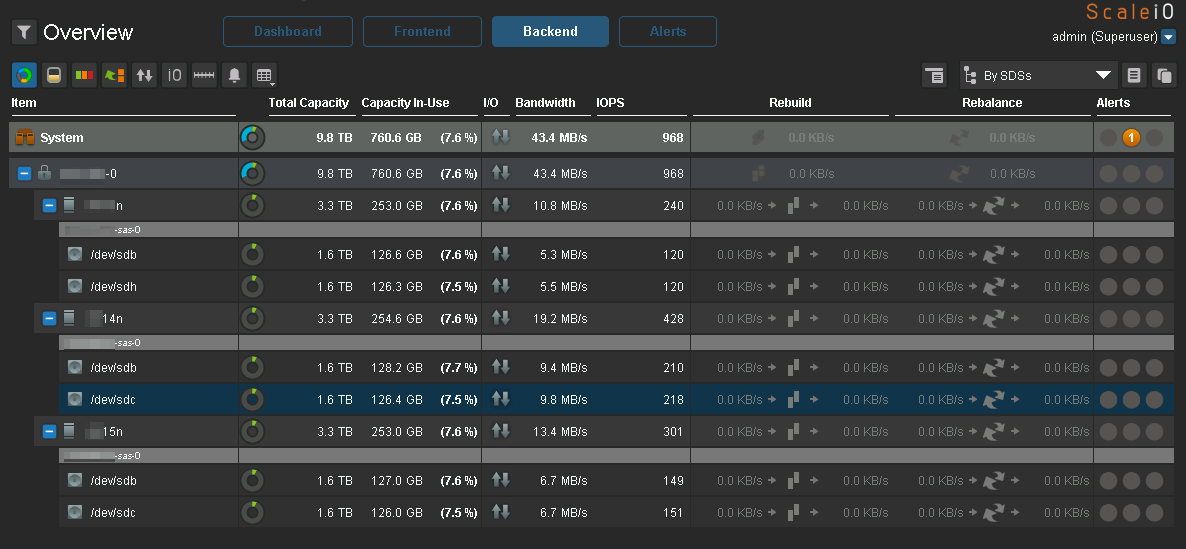
IO, Ceph.
:
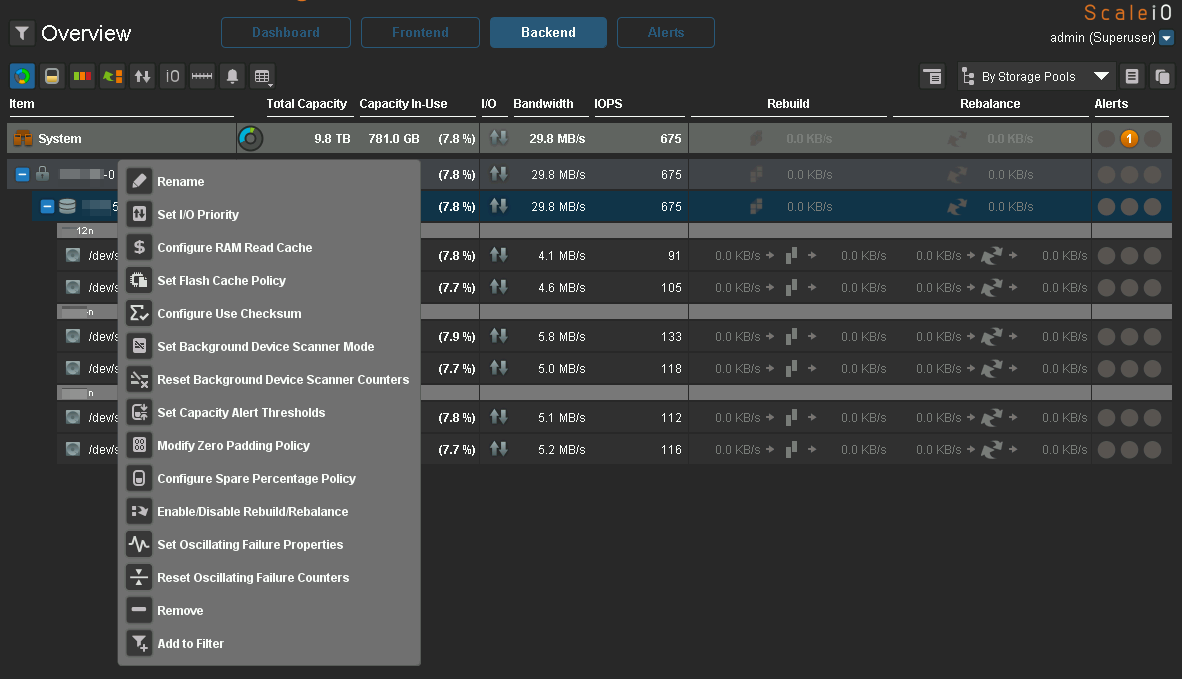
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
Conclusion
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!