Lorsque l'application était monolithique et soudain, une fois qu'elle a été distribuée, une autre inconnue est ajoutée à la formule de calcul de disponibilité - le réseau. En raison de problèmes d'appels entre les composants, les applications tombent souvent et commencent à se branler. Et découvrir les raisons du travail instable d'une application distribuée est une autre tâche. Un gâchis supplémentaire dans la structure de l'application est fait par les kubernetes conditionnels, qui, à sa discrétion, peuvent distribuer arbitrairement des pods conditionnels en fonction de nœuds conditionnels. J'écris «conditionnel», car à la place de kubernetes il peut y avoir Swarm et Openshift, et d'autres et d'autres.
Je veux dire, sans visualisation normale, déterminer où est la température peut être très difficile. Sous la coupe, mon idée des capacités potentielles des outils qui peuvent dessiner une carte d'application et mettre en évidence les endroits pour appliquer un plantain, ainsi qu'une liste de ces outils avec des captures d'écran.
Commençons par déterminer ce qu'il est souhaitable de voir sur la carte des applications, puis nous examinerons les approches de surveillance, puis nous passerons à des fournisseurs spécifiques.
Ce que je veux voir sur la carte d'application
La première chose qui me vient à l'esprit est la possibilité de regrouper les nœuds d'application selon certains critères. Par exemple, je dis que dans ce groupe, j'ai un frontend, et dans ce backend ou ici, j'ai des instances du service Payments, et ici Shipping. Eh bien, et ainsi de suite. Et les personnes responsables de telle ou telle partie voient immédiatement le tableau complet de ce qui se passe dans leur zone de responsabilité.
La seconde consiste à présenter l'application par niveaux avec la possibilité de voir, par exemple, en termes d'infrastructure, de service, d'instances de service, etc. Comme dans le premier cas, cela aide à identifier la couche problématique.
Troisièmement , les sorties et les entrées de ces nœuds, y compris les connexions entre eux. Sur ces chaînes, j'aimerais voir les signaux d'or que Google décrit dans Site 6 Reliability Engineering du chapitre 6 de Monitoring Distributed Systems. J'ai déjà
publié une traduction de ce chapitre
sur un blog sur le Medium . Et les signaux sont les suivants: latence, trafic (débit), erreurs (taux d'erreur) et saturation (saturation).
Peut-être que je n'ai pas pris en compte quelque chose. Veuillez consulter les commentaires si vous pensez que d'autres éléments importants manquent.
Quelles sont les différentes approches de suivi
Je ne sais pas comment on peut l'appeler, donc j'appellerai les approches agent et surveillance sans agent. Maintenant, je vais expliquer hu de hu.
Surveillance des agents
La surveillance des agents signifie la nécessité d'implémenter des agents de surveillance spéciaux dans une application contrôlée. Les agents incorporent l'ID de trace dans les en-têtes de paquets.
Ce type comprend les solutions de surveillance APM et toutes celles qui sont intégrées en injectant des SDK dans le code d'application.
Avantages: aide à trouver la cause première du problème, les en-têtes peuvent suivre avec précision le chemin des transactions.
Inconvénients: frais généraux possibles dus à une modification de l'algorithme d'application, l'incapacité à intégrer dans les applications héritées, la prise en charge d'un ensemble limité de langages de programmation
Surveillance sans agent
Surveillance sans modification de l'application. Ce type inclut les journaux, le suivi au niveau du système d'exploitation et la surveillance du trafic réseau.
Avantages: la surveillance de la couverture de divers cadres et langages de programmation peut fonctionner là où l'injection d'ID de trace n'est pas possible, il n'y a pas de surcharge sur une application contrôlée.
Inconvénients: sans identifiant de trace, il peut être difficile de restaurer le contexte d'une transaction commerciale, l'impossibilité d'écouter le trafic si l'encapsulation SSL est configurée et qu'il n'y a pas de clés,
Ce que les vendeurs proposent
Vendorov a été démonté sur la base d'agent / sans agent, vous pouvez demander d'autres caractéristiques dans les commentaires ou dans un message personnel. La plus grande expérience que j'ai eue avec Instana, Appdynamics et New Relic, si vous voulez regarder, je peux vous aider avec des licences de démonstration pour une période dépassant 14 jours (comme ils le proposent sur leurs sites par défaut).
Surveillance des agents
Instana est un outil de surveillance des systèmes distribués. Une caractéristique clé est un agent unique pour toutes les technologies prises en charge et la collecte de métriques une fois par seconde.
 Appdynamics
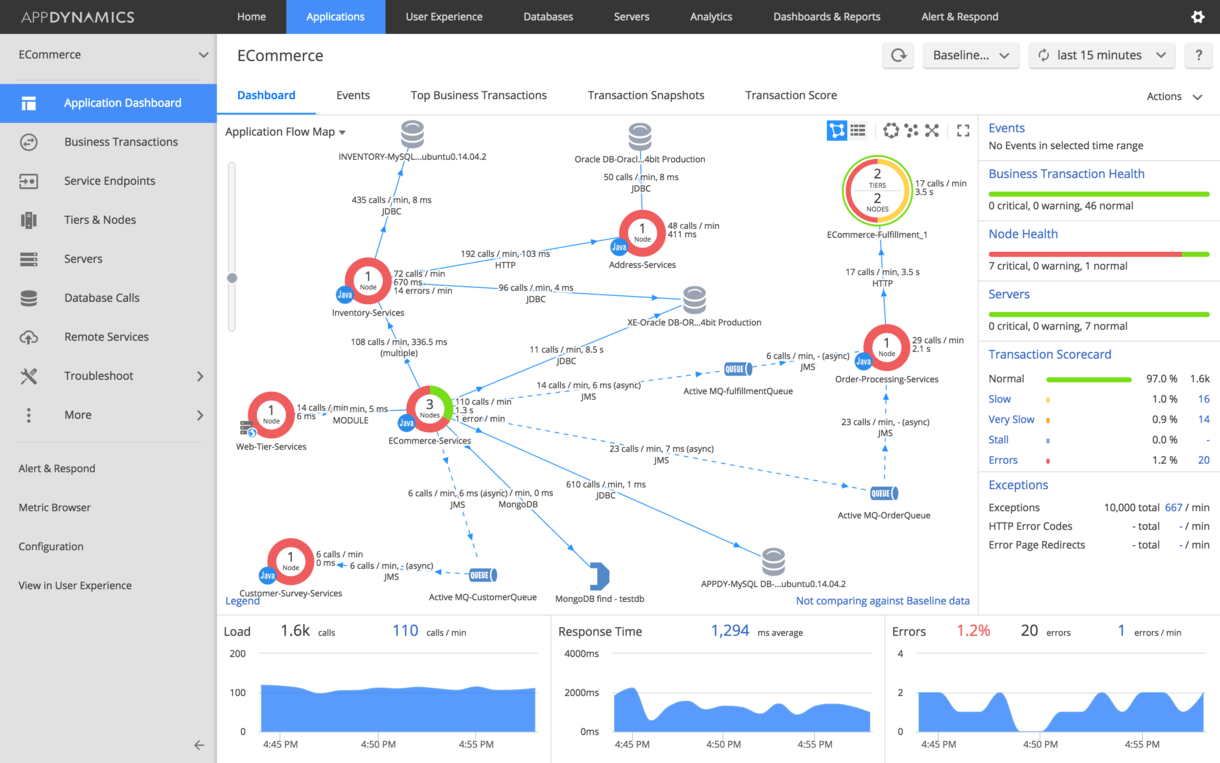
Appdynamics est une solution bien connue pour la surveillance APM. Capable de créer une carte d'application basée sur les appels entre les composants d'application. La surveillance de l'agent est requise pour surveiller les appels.
 New Relic
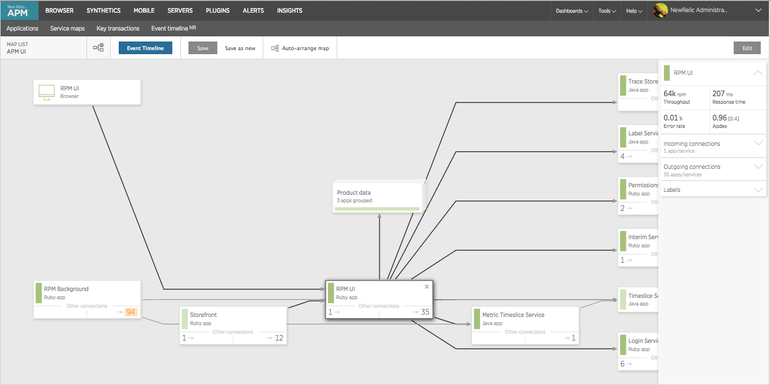
New Relic est un concurrent direct d'Appdynamics. La principale différence est que seule la surveillance à partir du cloud est possible (les agents sont également installés sur les serveurs cibles). Construit une carte des applications basée sur les appels.
 Dynatrace
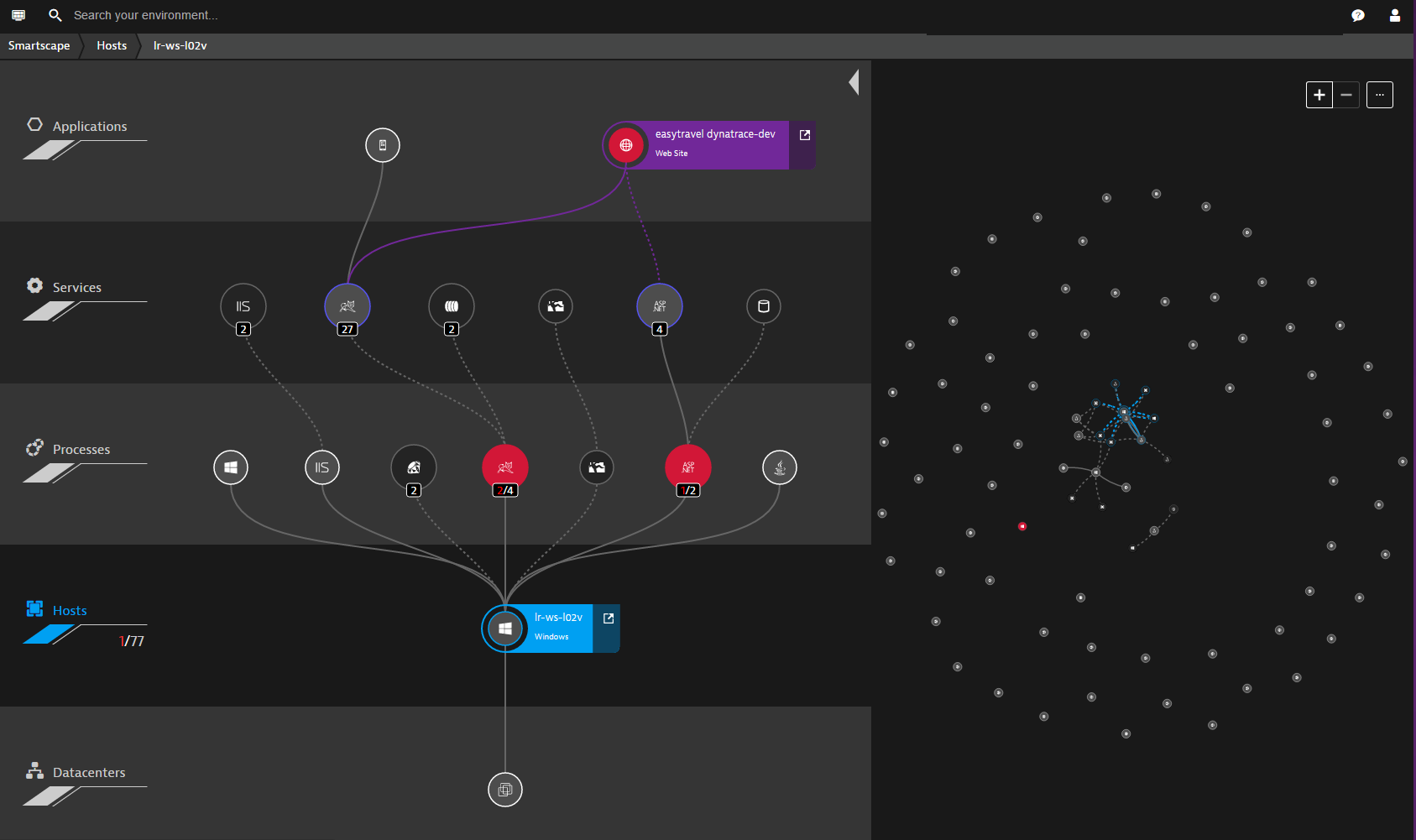
Dynatrace est un outil de surveillance APM. Il prend en charge la surveillance de divers langages de programmation et peut fonctionner à la fois à partir du cloud et sur site.
 AWS X-Ray
AWS X-Ray - Surveillez les applications hébergées sur AWS. Prend en charge la visualisation de la carte d'application, nécessite l'installation de son propre SDK.
 OpenTracing
OpenTracing est une API pour l'instrumentation des applications distribuées. De nombreuses
solutions commerciales et non commerciales sont basées sur cette API.
Jaeger est un outil de trading open source gratuit. Construit sur la base d'OpenTracing.
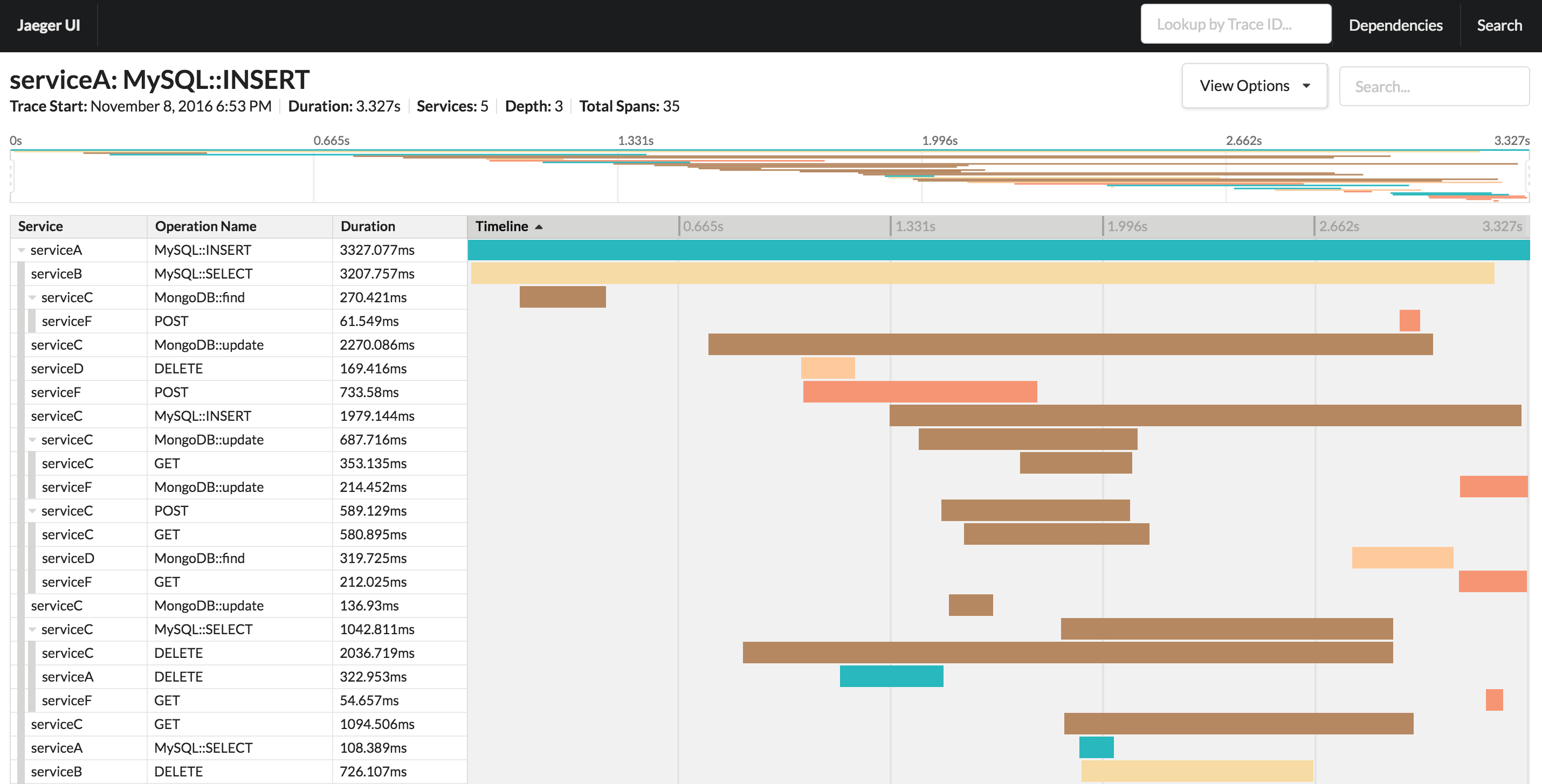 Datadog APM
Datadog APM est un outil commercial de surveillance des applications distribuées. Il fonctionne sur la base de l'OpenTracing mentionné.

Surveillance sans agent
OpenZipkin est un outil gratuit pour
suivre les applications distribuées. Une caractéristique de son travail est la collecte de données sur les appels à l'aide des bibliothèques d'instrumentation et l'envoi ultérieur de ces données au collecteur OpenZipkin.
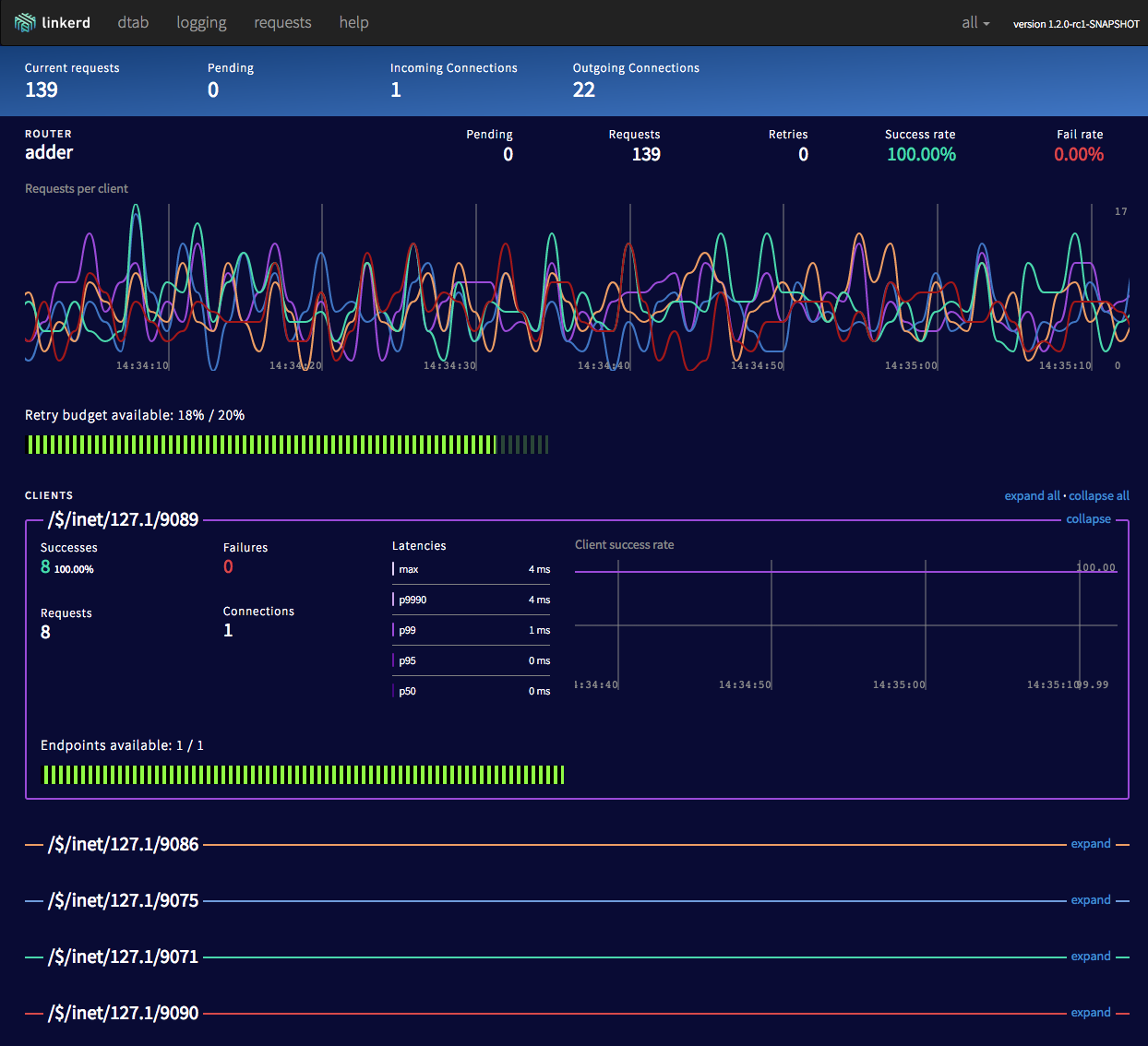
 Linkerd
Linkerd est un outil gratuit pour
suivre les appels dans l'application. C'est un module complémentaire pour OpenZipkin, il est installé sur l'infrastructure kubernetes en tant que conteneur de sidecar.
 Envoy
Envoy est un outil gratuit. Il fonctionne comme un proxy auquel les données d'appel sont envoyées entre les composants de l'application. Il n'y a pas d'interface Web propre, les données peuvent être reçues via des requêtes HTTP GET ou envoyées à statsd.
Netsil est un outil de surveillance des applications distribuées basé sur l'écoute du trafic. Cela fonctionne quelle que soit la langue dans laquelle la demande est écrite.
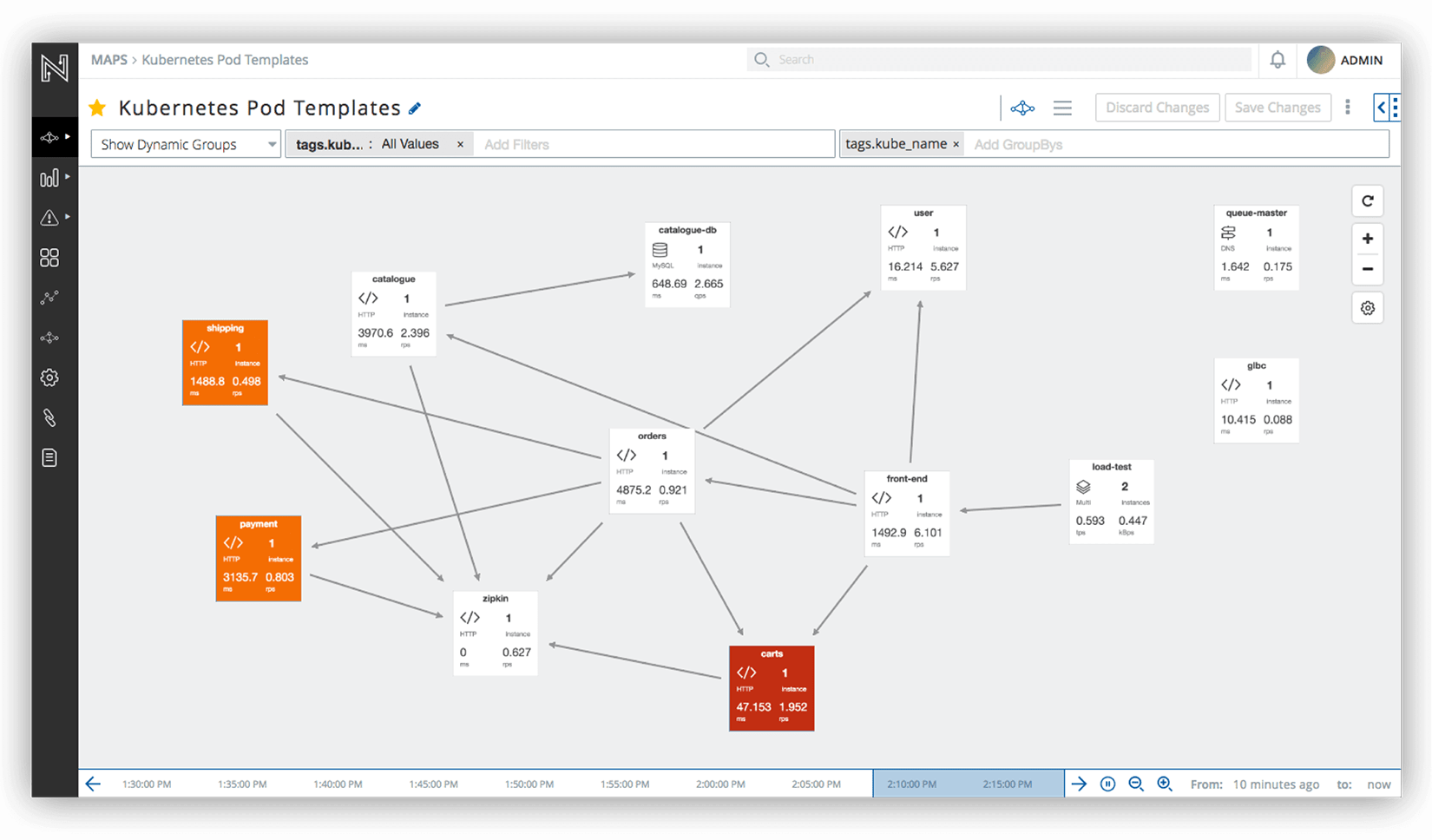
Dites qui a utilisé quoi et quelle impression a été laissée.