L'utilisation du type Struct et du modificateur en lecture seule peut parfois entraîner une dégradation des performances. Aujourd'hui, nous allons discuter de la façon d'éviter cela en utilisant un analyseur de code Open Source - ErrorProne.NET.

Comme vous le savez probablement dans mes publications précédentes "
Le modificateur 'in' et les structures en lecture seule en C # " ("Le modificateur dans et les structures en lecture seule en C #") et "
Les pièges de performance des sections locales ref et les retours ref en C # " (" Pièges de performance lors de l'utilisation de variables locales et de valeurs de retour avec le modificateur ref)), travailler avec des structures est plus difficile qu'il n'y paraît. Laissant de côté la question de la mutabilité, je note que le comportement des structures avec modificateur en lecture seule (lecture seule) et sans lui dans des contextes en lecture seule varie considérablement.
Il est supposé que les structures sont utilisées dans des scripts de programmation qui nécessitent de hautes performances, et pour travailler efficacement avec elles, vous devez savoir quelque chose sur les diverses opérations cachées générées par le compilateur pour vous assurer que la structure reste inchangée.
Voici une brève liste des mises en garde dont vous devez vous souvenir:
- L'utilisation de grandes structures transmises ou renvoyées par valeur peut entraîner des problèmes de performances sur les chemins d'exécution de programme critiques.
xY entraîne la xY une copie de protection de x si:
x est un champ en lecture seule;- le type
x est une structure sans modificateur en lecture seule; Y n'est pas un champ.
Les mêmes règles fonctionnent si x est un paramètre avec le modificateur in, une variable locale avec le modificateur ref en lecture seule, ou le résultat de l'appel d'une méthode qui renvoie une valeur via une référence en lecture seule.
Voici quelques règles à garder à l'esprit. Et, plus important encore, le code qui s'appuie sur ces règles est très fragile (c'est-à-dire que les modifications apportées au code provoquent immédiatement des changements importants dans d'autres parties du code ou de la documentation - environ la traduction). Combien de personnes remarqueront que remplacer
public readonly int X ; sur
public int X { get; } public int X { get; } dans une structure fréquemment utilisée sans modificateur en lecture seule affecte-t-elle considérablement les performances? Ou est-il facile de voir que le passage d'un paramètre à l'aide du modificateur in au lieu de passer par la valeur peut réduire les performances? C'est vraiment possible lorsque vous utilisez la propriété in d'un paramètre dans une boucle, lorsqu'une copie de protection est créée à chaque itération.
De telles propriétés des structures font littéralement appel au développement d'analyseurs. Et l'appel a été entendu.
Découvrez ErrorProne.NET - un ensemble d'analyseurs qui vous informe sur la possibilité de modifier le code du programme pour améliorer sa conception et ses performances lorsque vous travaillez avec des structures.
Analyse de code avec sortie de message "Rendre la structure X en lecture seule"
La meilleure façon d'éviter les erreurs subtiles et les impacts négatifs sur les performances lors de l'utilisation de structures est de les rendre en lecture seule chaque fois que possible. Le modificateur en lecture seule dans la déclaration de structure exprime clairement l'intention du développeur (soulignant que la structure est immuable) et aide le compilateur à éviter de générer des copies de sécurité dans de nombreux contextes mentionnés ci-dessus.
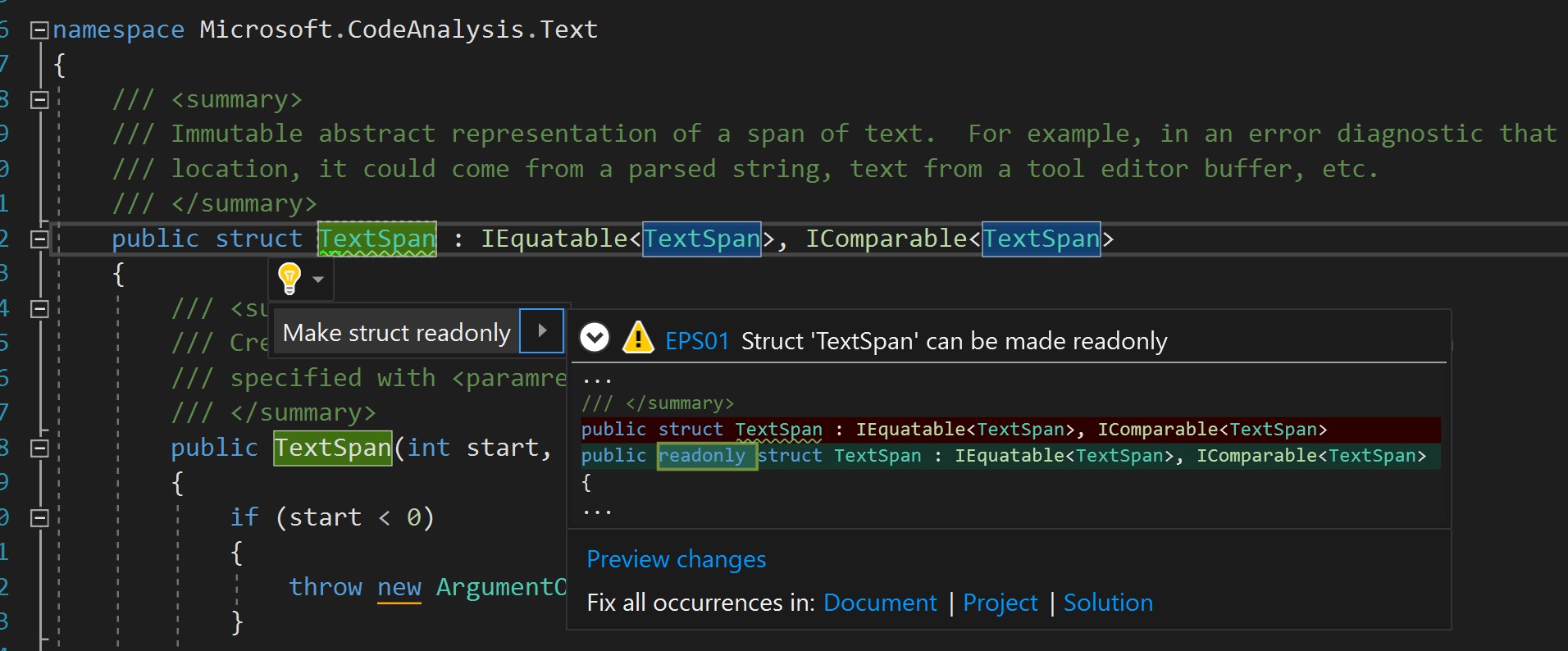
La déclaration d'une structure en lecture seule ne viole pas l'intégrité du code. Vous pouvez exécuter le fixateur (processus de correction du code) en mode batch en toute sécurité et déclarer toutes les structures de la solution logicielle entière en lecture seule.
Convivialité pour le modificateur de lecture seule de la référence
L'étape suivante consiste à évaluer la sécurité de l'utilisation de nouvelles fonctionnalités (dans le modificateur, les variables de lecture locales, les variables de référence, etc.). Cela signifie que le compilateur ne créera pas de copies de protection cachées susceptibles de réduire les performances.
Trois types de types peuvent être envisagés:
- les structures amies en lecture seule dont l'utilisation n'entraîne jamais la création de copies de protection;
- les structures qui ne sont pas conviviales à référencer en lecture seule, dont l'utilisation dans le contexte de la lecture seule conduit toujours à la création de copies de protection;
- structures neutres - structures dont l'utilisation peut donner lieu à des copies de protection selon l'élément utilisé dans le contexte de lecture seule.
La première catégorie comprend les structures en lecture seule et les structures POCO. Le compilateur ne générera jamais de copie de protection si la structure est en lecture seule. Il est également sûr d'utiliser les structures POCO dans le contexte de la lecture seule: l'accès aux champs est considéré comme sûr et aucune copie de protection n'est créée.
La deuxième catégorie est constituée des structures sans modificateur en lecture seule qui ne contiennent pas de champs ouverts. Dans ce cas, tout accès au membre public dans le contexte de lecture seule entraînera la création d'une copie de protection.
La dernière catégorie est constituée des structures avec des champs publics ou internes et des propriétés ou méthodes publiques ou internes. Dans ce cas, le compilateur crée des copies de protection en fonction du membre utilisé.
Cette séparation permet de générer instantanément des avertissements si la structure "hostile" est transmise avec le modificateur in, stockée dans la variable locale ref en lecture seule, etc.

L'analyseur n'affiche pas d'avertissement si la structure "hostile" est utilisée comme champ en lecture seule, car il n'y a pas d'alternative dans ce cas. Les modificateurs in et ref en lecture seule sont conçus pour être optimisés spécifiquement pour éviter de créer des copies redondantes. Si la structure est "hostile" par rapport à ces modificateurs, vous avez d'autres options: passer un argument par valeur ou enregistrer une copie dans une variable locale. À cet égard, les champs en lecture seule se comportent différemment: si vous souhaitez rendre le type immuable, vous devez utiliser ces champs. N'oubliez pas: le code doit être clair et élégant, et seulement secondairement rapide.
Analyse Cci
Le compilateur effectue de nombreuses actions cachées à l'utilisateur. Comme indiqué dans un article précédent, il est assez difficile de voir quand une copie de protection est créée.
L'analyseur détecte les copies cachées suivantes:
- Cci du champ en lecture seule.
- Cci de po.
- Cci de la variable locale en lecture seule ref.
- Bcc return ref en lecture seule.
- Cci lors de l'appel d'une méthode d'extension qui prend un paramètre avec ce modificateur par valeur pour une instance de la structure.
public struct NonReadOnlyStruct { public readonly long PublicField; public long PublicProperty { get; } public void PublicMethod() { } private static readonly NonReadOnlyStruct _ros; public static void Samples(in NonReadOnlyStruct nrs) {
Veuillez noter que les analyseurs affichent des messages de diagnostic uniquement si la taille de la structure est ≥ 16 octets.
Utiliser des analyseurs dans des projets réels
Le transfert de grandes structures en valeur et, par conséquent, la création de copies de protection par le compilateur affectent considérablement les performances. Au moins, cela est démontré par les résultats des tests de performance. Mais comment ces phénomènes affecteront-ils les applications réelles en termes de temps de bout en bout?
Pour tester les analyseurs à l'aide de code réel, je les ai utilisés pour deux projets: le projet Roslyn et le projet interne sur lequel je travaille actuellement chez Microsoft (le projet est une application informatique indépendante avec des exigences de performances strictes); appelons-le «Projet D» pour plus de clarté.
Voici les résultats:
- Les projets avec des exigences de performances élevées contiennent généralement de nombreuses structures, et la plupart d'entre elles peuvent être en lecture seule. Par exemple, dans le projet Roslyn, l'analyseur a trouvé environ 400 structures qui peuvent être en lecture seule, et dans le projet D, environ 300.
- Dans les projets nécessitant des performances élevées, les copies aveugles ne doivent être créées que dans des situations exceptionnelles. Je n'ai trouvé que quelques cas de ce type dans le projet Roslyn, car la plupart des structures ont des champs publics au lieu de propriétés publiques. Cela évite de créer des copies de protection dans des situations où les structures sont stockées dans des champs en lecture seule. Il y avait plus de copies aveugles dans le projet D, car au moins la moitié d'entre elles avaient des propriétés en lecture seule (accès en lecture seule).
- Le transfert de structures même assez grandes à l'aide du modificateur in est susceptible d'avoir très peu d'effets (presque imperceptibles) sur la durée du programme.
J'ai changé les 300 structures du projet D, les rendant en lecture seule, puis j'ai corrigé des centaines de cas de leur utilisation, indiquant qu'elles sont passées avec le modificateur in. J'ai ensuite mesuré le temps de transit de bout en bout pour différents scénarios de performances. Les différences étaient statistiquement insignifiantes.
Est-ce à dire que les fonctionnalités décrites ci-dessus sont inutiles? Pas du tout.
Travailler sur un projet avec des exigences de performance élevées (par exemple, sur Roslyn ou «Project D») implique qu'un grand nombre de personnes passent beaucoup de temps sur différents types d'optimisation. En fait, dans certains cas, les structures de notre code ont été transmises avec le modificateur ref et certains champs ont été déclarés sans le modificateur readonly pour exclure la génération de copies de protection. L'absence de croissance de la productivité lors du transfert de structures avec le modificateur in peut signifier que le code a été bien optimisé et qu'il n'y a pas de copie excessive des structures sur les chemins critiques de son passage.
Que dois-je faire avec ces fonctionnalités?
Je crois que la question de l'utilisation du modificateur en lecture seule pour les structures ne nécessite pas beaucoup de réflexion. Si la structure est immuable, le modificateur en lecture seule force simplement explicitement le compilateur à une telle décision de conception. Et le manque de copies de protection pour de telles structures n'est qu'un bonus.
Aujourd'hui, mes recommandations sont les suivantes: si la structure peut être lue seule, alors certainement procédez de cette façon.
L'utilisation des autres options envisagées présente des nuances.
Pré-optimisation contre pré-pessimisation?
Herb Sutter introduit le concept de «pessimisation préliminaire» dans son livre étonnant,
C ++ Coding Standards: 101 Rule, Recommendations, and Best Practices .
«Ceteris paribus, la complexité et la lisibilité du code, certains modèles de conception efficaces et les idiomes de codage devraient naturellement s'écouler du bout des doigts. Un tel code n'est pas plus difficile à écrire que ses alternatives pessimisées. Vous ne faites pas d'optimisation préliminaire, mais évitez la pessimisation volontaire. »
De mon point de vue, un paramètre avec le modificateur in est juste le cas. Si vous savez que la structure est relativement grande (40 octets ou plus), vous pouvez toujours la passer avec le modificateur in. Le coût d'utilisation du modificateur in est relativement faible, car vous n'avez pas besoin d'ajuster les appels et les avantages peuvent être réels.
En revanche, pour les variables locales et les valeurs de retour avec le modificateur ref en lecture seule, ce n'est pas le cas. Je dirais que ces fonctionnalités devraient être utilisées lors du codage des bibliothèques, et il vaut mieux les refuser dans le code de l'application (uniquement si le profilage du code ne révèle pas que l'opération de copie est vraiment un problème). L'utilisation de ces fonctionnalités nécessite des efforts supplémentaires et il devient plus difficile pour le lecteur de code de les comprendre.
Conclusion
- Utilisez le modificateur en lecture seule pour les structures lorsque cela est possible.
- Pensez à utiliser le modificateur in pour les grandes structures.
- Pensez à utiliser des variables locales et à renvoyer des valeurs avec le modificateur ref readonly pour coder les bibliothèques ou dans les cas où les résultats du profilage de code indiquent que cela peut être utile.
- Utilisez ErrorProne.NET pour détecter les problèmes de code et partager les résultats.