Cet article se concentrera sur l'équilibrage de charge dans les projets Web. Beaucoup croient que la solution à ce problème dans la répartition de la charge entre les serveurs - le plus précis, le mieux. Mais nous savons que ce n'est pas entièrement vrai.
La stabilité du système est beaucoup plus importante d'un point de vue commercial .
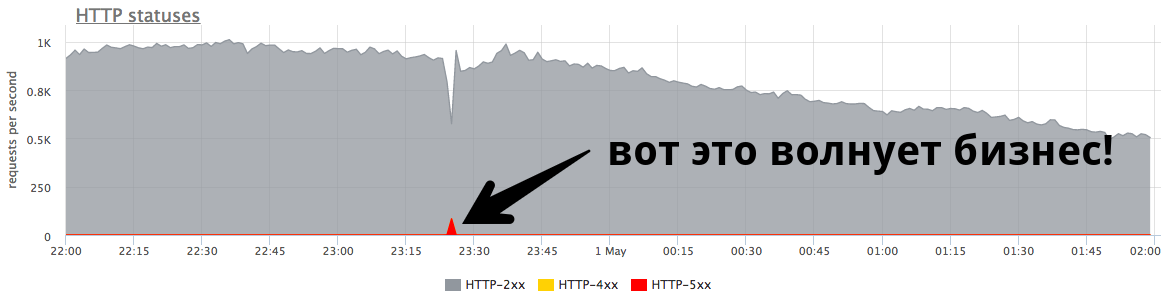
Le petit pic minute à 84 RPS de «cinq cents» est cinq mille erreurs que les vrais utilisateurs ont reçues. C'est beaucoup et c'est très important. Il faut rechercher les raisons, travailler sur les erreurs et essayer de continuer à éviter de telles situations.
Nikolay Sivko (
NikolaySivko ) dans son rapport sur RootConf 2018 a parlé des aspects subtils et pas encore très populaires de l'équilibrage de charge:
- quand répéter la demande (nouvelles tentatives);
- comment sélectionner des valeurs pour les délais d'expiration;
- comment ne pas tuer les serveurs sous-jacents au moment de l'accident / de la congestion;
- si des contrôles de santé sont nécessaires;
- comment gérer les problèmes de scintillement.
Sous décodage chat de ce rapport.
À propos de l'orateur: Nikolay Sivko co-fondateur de okmeter.io. Il a travaillé en tant qu'administrateur système et chef d'un groupe d'administrateurs. Opération supervisée à hh.ru. Il a fondé le service de surveillance okmeter.io. Dans le cadre de ce rapport, le suivi de l'expérience en développement est la principale source de cas.
De quoi allons-nous parler?
Cet article parlera de projets Web. Voici un exemple de production en direct: le graphique montre les demandes par seconde pour un certain service Web.
Quand je parle d'équilibrage, beaucoup le perçoivent comme "nous devons répartir la charge entre les serveurs - le plus précis, le mieux."
En fait, ce n'est pas entièrement vrai. Ce problème concerne un très petit nombre d'entreprises. Le plus souvent, les entreprises s'inquiètent des erreurs et de la stabilité du système.
Le petit pic sur le graphique est «cinq cents», que le serveur a renvoyé en une minute, puis arrêté. Du point de vue d'une entreprise, comme une boutique en ligne, ce petit pic à 84 RPS de «cinq cents» représente 5040 erreurs pour les utilisateurs réels. Certains n'ont pas trouvé quelque chose dans votre catalogue, d'autres n'ont pas pu mettre la marchandise dans le panier. Et c'est très important. Bien que ce pic ne semble pas très grand sur le graphique,
il l'est beaucoup chez les vrais utilisateurs .
En règle générale, tout le monde a de tels pics, et les administrateurs n'y répondent pas toujours. Très souvent, lorsqu'une entreprise demande ce que c'était, ils lui répondent:
- "Ceci est une courte rafale!"
- "C'est juste une version qui sort."
- "Le serveur est mort, mais tout est déjà en ordre."
- "Vasya a changé le réseau de l'un des backends."
Souvent, les gens
n'essaient même pas de comprendre les raisons pour lesquelles cela s'est produit et ne font aucun post-travail pour que cela ne se reproduise plus.
Affiner
J'ai appelé le rapport "Fine tuning" (Eng. Fine tuning), parce que je pensais que tout le monde ne se mettait pas à cette tâche, mais cela en valait la peine. Pourquoi n'y arrivent-ils pas?
- Tout le monde ne parvient pas à cette tâche, car lorsque tout fonctionne, ce n'est pas visible. Ceci est très important pour les problèmes. Le Fakapa n'arrive pas tous les jours, et un si petit problème nécessite des efforts très sérieux pour le résoudre.
- Vous devez réfléchir beaucoup. Très souvent, l'administrateur - la personne qui ajuste la balance - n'est pas en mesure de résoudre ce problème de manière indépendante. Ensuite, nous verrons pourquoi.
- Il capture les niveaux sous-jacents. Cette tâche est très étroitement liée au développement, à l'adoption de décisions qui affectent votre produit et vos utilisateurs.
J'affirme qu'il est temps de faire cette tâche pour plusieurs raisons:- Le monde change, devient plus dynamique, il existe de nombreuses versions. Ils disent que maintenant il est correct de sortir 100 fois par jour, et la sortie est le futur fakap avec une probabilité de 50 à 50 (tout comme la probabilité de rencontrer un dinosaure)
- Du point de vue de la technologie, tout est également très dynamique. Kubernetes et d'autres orchestrateurs sont apparus. Il n'y a pas de bon vieux déploiement, lorsqu'un backend sur une IP est désactivé, une mise à jour est lancée et le service augmente. Maintenant, dans le processus de déploiement dans k8s, la liste des IP en amont change complètement.
- Microservices: maintenant tout le monde communique via le réseau, ce qui signifie que vous devez le faire de manière fiable. L'équilibrage joue un rôle important.
Banc d'essai
Commençons par des cas simples et évidents. Pour plus de clarté, je vais utiliser un banc d'essai. Il s'agit d'une application Golang qui donne http-200, ou vous pouvez la passer en mode "donner http-503".
Nous commençons 3 instances:
- 127.0.0.1:20001
- 127.0.0.1:20002
- 127.0.0.1:20003
Nous servons 100rps via yandex.tank via nginx.
Nginx hors de la boîte:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
Scénario primitif
À un moment donné, activez l'un des backends dans le mode Give 503, et nous obtenons exactement un tiers des erreurs.
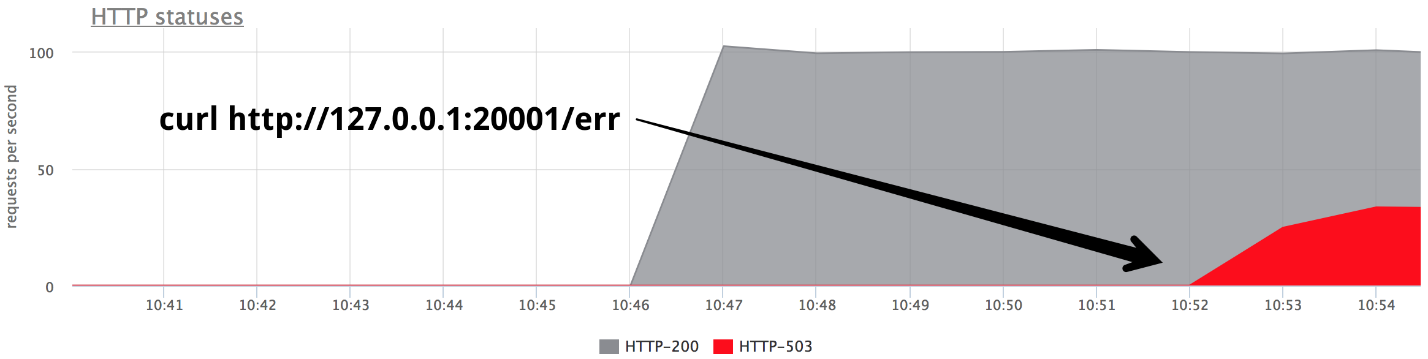
Il est clair que rien ne sort de la boîte: nginx ne réessaye pas de la boîte s'il a reçu
une réponse du serveur.
Nginx default: proxy_next_upstream error timeout;
En fait, c'est assez logique du côté des développeurs de nginx: nginx n'a pas le droit de décider pour vous ce que vous voulez retravailler et ce qui ne l'est pas.
Par conséquent, nous avons besoin de nouvelles tentatives - de nouvelles tentatives, et nous commençons à en parler.
Réessais
Il faut trouver un compromis entre:
- La demande de l'utilisateur est sainte, se blesse, mais répondez. Nous voulons répondre à tout prix à l'utilisateur, l'utilisateur est le plus important.
- Mieux vaut répondre avec une erreur que de surcharger les serveurs.
- Intégrité des données (pour les demandes non idempotentes), c'est-à-dire qu'il est impossible de répéter certains types de demandes.
La vérité, comme d'habitude, se situe quelque part entre - nous sommes obligés d'équilibrer entre ces trois points. Essayons de comprendre quoi et comment.
J'ai divisé les tentatives infructueuses en 3 catégories:
1.
Erreur de transportPour le transport HTTP, il s'agit de TCP et, en règle générale, nous parlons ici d'erreurs de configuration de connexion et de délais d'expiration de configuration de connexion. Dans mon rapport, je mentionnerai 3 équilibreurs courants (nous parlerons un peu d'Envoy):
- nginx : erreurs + timeout (proxy_connect_timeout);
- HAProxy : connexion timeout;
- Envoyé : échec de connexion + flux refusé.
Nginx a la possibilité de dire qu'une tentative ayant échoué est une erreur de connexion et un délai d'expiration de connexion; HAProxy a un délai de connexion, Envoy a également tout ce qui est standard et normal.
2.
Délai de demande:Supposons que nous ayons envoyé une requête au serveur, connecté avec succès, mais que la réponse ne nous vienne pas, nous l'avons attendue et nous comprenons qu'il ne sert à rien d'attendre plus longtemps. C'est ce qu'on appelle le délai d'expiration de la demande:
- Nginx a: timeout (prox_send_timeout * + proxy_read_timeout *);
- HAProxy a OOPS :( - il n'existe pas en principe. Beaucoup de gens ne savent pas que HAProxy, s'il a réussi à établir une connexion, n'essaiera jamais de renvoyer la demande.
- L'envoyé peut tout faire: délai d'expiration || per_try_timeout.
3.
Statut HTTPTous les équilibreurs, à l'exception de HAProxy, sont capables de traiter, si néanmoins le backend vous a répondu, mais avec une sorte de code erroné.
- nginx : http_ *
- HAProxy : OOPS :(
- Envoy : 5xx, erreur de passerelle (502, 503, 504), récupérable-4xx (409)
Délais
Parlons maintenant en détail des délais d'attente, il me semble qu'il vaut la peine d'y prêter attention. Il n'y aura plus de fusée scientifique - il s'agit simplement d'informations structurées sur ce qui se passe généralement et sur la manière dont elles s'y rapportent.
Délai d'expiration de connexion
Le délai de connexion est le temps pour établir une connexion. Ceci est une caractéristique de votre réseau et de votre serveur spécifique et ne dépend pas de la demande. Habituellement, la valeur par défaut pour le délai de connexion est définie sur petite. Dans tous les proxys, la valeur par défaut est suffisamment grande, et c'est faux - ce devrait être des
unités, parfois des dizaines de millisecondes (si nous parlons d'un réseau à l'intérieur d'un DC).
Si vous souhaitez identifier les serveurs problématiques un peu plus rapidement que ces unités-dizaines de millisecondes, vous pouvez ajuster la charge sur le backend en définissant un petit backlog pour recevoir les connexions TCP. Dans ce cas, vous pouvez, lorsque le backlog de l'application est plein, demander à Linux de le réinitialiser pour déborder le backlog. Ensuite, vous pourrez filmer le "mauvais" backend surchargé un peu plus tôt que le délai de connexion:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
Délai d'expiration de la demande
Le délai d'expiration des demandes n'est pas une caractéristique du réseau, mais une
caractéristique d'un groupe de demandes (gestionnaire). Il existe différentes demandes - leur gravité est différente, leur logique interne est complètement différente, elles doivent accéder à des référentiels complètement différents.
Nginx lui
- même
n'a pas de délai d'expiration pour la demande entière. Il a:
- proxy_send_timeout: temps entre deux opérations d'écriture réussies write ();
- proxy_read_timeout: temps entre deux lectures réussies ().
Autrement dit, si vous avez un backend lentement, un octet de fois, donne quelque chose dans un délai d'attente, alors tout va bien. En tant que tel, nginx n'a pas request_timeout. Mais nous parlons en amont. Dans notre centre de données, ils sont contrôlés par nous, par conséquent, en supposant que le réseau n'a pas de loris lent, alors, en principe, read_timeout peut être utilisé comme request_timeout.
Envoy a tout pour lui: timeout || per_try_timeout.
Sélectionnez le délai d'expiration de la demande
Maintenant, la chose la plus importante, à mon avis, est de savoir quel request_timeout mettre. Nous partons de combien il est permis à l'utilisateur d'attendre - c'est un certain maximum. Il est clair que l'utilisateur n'attendra pas plus de 10 s, vous devez donc lui répondre plus rapidement.
- Si nous voulons gérer la défaillance d'un seul serveur, le délai d'expiration doit être inférieur au délai maximal autorisé: request_timeout <max.
- Si vous voulez avoir 2 tentatives garanties d' envoyer une demande à deux backends différents, le délai d'expiration pour une tentative est égal à la moitié de cet intervalle autorisé: per_try_timeout = 0,5 * max.
- Il existe également une option intermédiaire - 2 tentatives optimistes dans le cas où le premier backend s'est "émoussé", mais le second répondra rapidement: per_try_timeout = k * max (où k> 0,5).
Il existe différentes approches, mais en général, le
choix d'un délai d'attente est difficile . Il y aura toujours des cas limites, par exemple, le même gestionnaire dans 99% des cas est traité en 10 ms, mais il y a 1% des cas quand on attend 500 ms, et c'est normal. Cela devra être résolu.
Avec ce 1%, quelque chose doit être fait, car l'ensemble du groupe de demandes doit, par exemple, se conformer au SLA et tenir en 100 ms. Très souvent, à ces moments, la demande est traitée:
- La pagination apparaît aux endroits où il est impossible de renvoyer toutes les données dans un délai d'attente.
- Les administrateurs / rapports sont séparés dans un groupe distinct d'URL afin d'augmenter le délai d'attente pour eux, et oui pour réduire les demandes des utilisateurs.
- Nous réparons / optimisons les demandes qui ne correspondent pas à notre délai d'expiration.
Ici, nous devons prendre une décision, ce qui n'est pas très simple d'un point de vue psychologique, que si nous n'avons pas le temps de répondre à l'utilisateur dans le temps imparti, nous donnerons une erreur (c'est comme dans un ancien dicton chinois: "Si la jument est morte, descendez!")
.Après cela, le processus de surveillance de votre service du point de vue de l'utilisateur est simplifié:
- S'il y a des erreurs, tout est mauvais, il faut le réparer.
- S'il n'y a pas d'erreurs, nous nous adaptons au bon temps de réponse, alors tout va bien.
Tentatives spéculatives # nifig
Nous nous sommes assurés que le choix d'une valeur de timeout est assez difficile. Comme vous le savez, pour simplifier quelque chose, vous devez compliquer quelque chose :)
Nouvelle spéculation - une demande répétée à un autre serveur, qui est lancée par une condition, mais la première demande n'est pas interrompue. Nous prenons la réponse du serveur qui a répondu plus rapidement.
Je n'ai pas vu cette fonctionnalité dans les équilibreurs que je connais, mais il y a un excellent exemple avec Cassandra (protection en lecture rapide):
spéculative_retry = N ms |
M e centileDe cette façon, vous
n'avez pas à expirer . Vous pouvez le laisser à un niveau acceptable et en tout cas avoir une deuxième tentative pour obtenir une réponse à la demande.
Cassandra a une opportunité intéressante de définir une dynamique spéculative_retry ou dynamique, puis la deuxième tentative sera effectuée à travers le centile du temps de réponse. Cassandra accumule des statistiques sur les temps de réponse des demandes précédentes et adapte une valeur de timeout spécifique. Cela fonctionne plutôt bien.
Dans cette approche, tout repose sur l'équilibre entre la fiabilité et la charge parasite. Pas les serveurs. Vous fournissez la fiabilité, mais parfois vous obtenez des demandes supplémentaires au serveur. Si vous étiez pressé quelque part et avez envoyé une deuxième demande, mais que la première a quand même répondu, le serveur a reçu un peu plus de charge. Dans un seul cas, c'est un petit problème.

La cohérence du timeout est un autre aspect important. Nous parlerons davantage de l'annulation de la demande, mais en général, si le délai d'expiration de la demande utilisateur entière est de 100 ms, il est inutile de définir le délai d'expiration de la demande dans la base de données pendant 1 s. Il existe des systèmes qui vous permettent de le faire de manière dynamique: service à service transfère le reste du temps que vous attendez une réponse à cette demande. C'est compliqué, mais si vous en avez soudainement besoin, vous pouvez facilement découvrir comment le faire dans le même Envoy.
Que devez-vous savoir d'autre sur la nouvelle tentative?
Point de non retour (V1)
Ici, V1 n'est pas la version 1. Dans l'aviation, il existe un tel concept - la vitesse V1. Il s'agit de la vitesse après laquelle il est impossible de ralentir lors de l'accélération sur la piste. Il est nécessaire de décoller, puis de décider quoi faire ensuite.
Le même point de non-retour se trouve dans les équilibreurs de charge:
lorsque vous avez transmis 1 octet de la réponse à votre client, aucune erreur ne peut être corrigée . Si le backend meurt à ce stade, aucune nouvelle tentative ne sera utile. Vous ne pouvez que réduire la probabilité qu'un tel scénario se déclenche, effectuer un arrêt progressif, c'est-à-dire dire à votre application: «Vous n'acceptez pas de nouvelles demandes maintenant, mais modifiez les anciennes!» Et alors seulement, éteignez-la.
Si vous contrôlez le client, il s'agit d'une application Ajax ou mobile délicate, il peut essayer de répéter la demande, puis vous pouvez sortir de cette situation.
Point de non-retour [Envoyé]
L'envoyé a eu un truc si étrange. Il y a per_try_timeout - il limite le temps que chaque tentative pour obtenir une réponse à une demande peut prendre. Si ce délai a fonctionné, mais que le backend a déjà commencé à répondre au client, alors tout a été interrompu, le client a reçu une erreur.
Mon collègue Pavel Trukhanov (
tru_pablo ) a fait un
patch , qui est déjà dans master Envoy et sera en 1.7. Maintenant, cela fonctionne comme il se doit: si la réponse a commencé à être transmise, seul le délai global fonctionnera.
Nouvelles tentatives: nécessité de limiter
Les nouvelles tentatives sont bonnes, mais il existe des demandes dites tueuses: les requêtes lourdes qui exécutent une logique très complexe accèdent beaucoup à la base de données et ne correspondent souvent pas à per_try_timeout. Si nous envoyons encore et encore des tentatives, nous tuons notre base. Parce que
dans la plupart des services de base de données (99,9%), il n'y a pas d'annulation de demande .
La demande d'annulation signifie que le client a décroché, vous devez arrêter tout travail maintenant. Golang promeut activement cette approche, mais malheureusement, elle se termine par un backend, et de nombreux référentiels de base de données ne le prennent pas en charge.
En conséquence, les tentatives doivent être limitées, ce qui permet à presque tous les équilibreurs (nous cessons désormais de considérer HAProxy).
Nginx:- proxy_next_upstream_timeout (global)
- proxt_read_timeout ** comme per_try_timeout
- proxy_next_upstream_tries
Envoyé:- délai d'attente (global)
- per_try_timeout
- num_retries
Dans Nginx, nous pouvons dire que nous essayons de faire des tentatives à travers la fenêtre X, c'est-à-dire qu'à un intervalle de temps donné, par exemple 500 ms, nous faisons autant de tentatives que bon. Ou il existe un paramètre qui limite le nombre d'échantillons répétés. Dans
Envoy , la même chose est la quantité ou le délai d'expiration (global).
Nouvelle tentative: appliquer [nginx]
Prenons un exemple: nous définissons des tentatives de relance dans nginx 2 - en conséquence, après avoir reçu HTTP 503, nous essayons d'envoyer à nouveau une demande au serveur. Désactivez ensuite les
deux backends.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
Voici les graphiques de notre banc d'essai. Il n'y a aucune erreur sur le graphique supérieur, car il y en a très peu. Si vous ne laissez que des erreurs, il est clair qu'elles le sont.
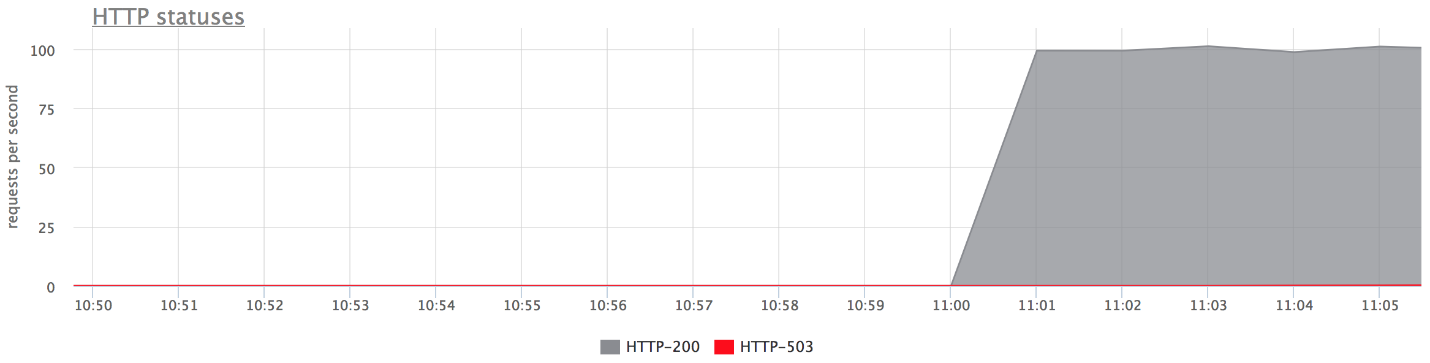
 Qu'est-il arrivé?
Qu'est-il arrivé?- proxy_next_upstream_tries = 2.
- Dans le cas où vous effectuez la première tentative sur le serveur "mort" et la seconde - sur l'autre "mort", vous obtenez HTTP-503 en cas de deux tentatives sur les "mauvais" serveurs.
- Il y a peu d'erreurs, car nginx "interdit" un mauvais serveur. Autrement dit, si dans nginx certaines erreurs sont retournées par le backend, il cesse de faire les tentatives suivantes pour lui envoyer une demande. Ceci est régi par la variable fail_timeout.
Mais il y a des erreurs, et cela ne nous convient pas.
Que faire à ce sujet?Nous pouvons soit augmenter le nombre de nouvelles tentatives (mais revenir ensuite au problème des «demandes de tueur»), soit réduire la probabilité qu'une demande atteigne des backends «morts». Cela peut être fait avec
des bilans de santé.Contrôles de santé
Je suggère de considérer les bilans de santé comme une optimisation du processus de choix d'un serveur «live».
Cela ne donne aucune garantie. Par conséquent, lors de l'exécution d'une demande d'utilisateur, nous sommes plus susceptibles d'accéder uniquement aux serveurs «en direct». L'équilibreur accède régulièrement à une URL spécifique, le serveur lui répond: "Je suis vivant et prêt".
Contrôles d'intégrité: en termes de backend
Du point de vue du backend, vous pouvez faire des choses intéressantes:
- Vérifiez l'état de préparation pour le fonctionnement de tous les sous-systèmes sous-jacents dont dépend le backend: le nombre nécessaire de connexions à la base de données est établi, le pool a des connexions libres, etc., etc.
- Vous pouvez accrocher votre propre logique sur l'URL des contrôles d'intégrité si l'équilibreur utilisé n'est pas très intelligent (par exemple, vous prenez l'équilibreur de charge de l'hôte). Le serveur peut se rappeler que "dans la dernière minute, j'ai donné tant d'erreurs - je suis probablement une sorte de" mauvais "serveur, et pendant les 2 prochaines minutes, je répondrai avec" cinq cents "aux contrôles de santé. Je vais donc m'interdire! " Cela aide parfois beaucoup lorsque vous avez un équilibreur de charge non contrôlé.
- En règle générale, l'intervalle de vérification est d'environ une seconde et vous avez besoin du gestionnaire de vérification d'intégrité pour ne pas tuer votre serveur. Ça devrait être léger.
Contrôles d'intégrité: implémentations
En règle générale, tout ici est le même pour tout le monde:
- Demande;
- Timeout dessus;
- Intervalle pendant lequel nous effectuons les vérifications. Les proxys trompés ont une gigue , c'est-à-dire une certaine randomisation afin que tous les contrôles de santé ne parviennent pas au backend en même temps et ne le tuent pas.
- Seuil malsain - seuil du nombre de contrôles d'intégrité ayant échoué pour que le service le marque comme malsain.
- Seuil sain - au contraire, combien de tentatives réussies doivent passer pour que le serveur puisse retourner en fonctionnement.
- Logique supplémentaire. Vous pouvez analyser l'état de vérification + le corps, etc.
Nginx implémente les fonctions de vérification d'intégrité uniquement dans la version payante de nginx +.
Je note une fonctionnalité d'
Envoy , il a un
mode panique de contrôle de santé
. Lorsque nous avons interdit, comme "malsain", plus de N% des hôtes (disons 70%), il pense que tous nos bilans de santé mentent, et tous les hôtes sont en fait vivants. Dans un très mauvais cas, cela vous aidera à ne pas vous retrouver dans une situation où vous vous êtes tiré une balle dans la jambe et avez banni tous les serveurs. C'est une façon d'être à nouveau en sécurité.
Tout mettre ensemble
Généralement pour les contrôles de santé définis:
- Ou nginx +;
- Ou nginx + autre chose :)
Dans notre pays, il y a une tendance à définir nginx + HAProxy, car la version gratuite de nginx n'a pas de contrôle de santé et jusqu'au 1.11.5 il n'y avait pas de limite sur le nombre de connexions au backend. Mais cette option est mauvaise car HAProxy ne sait pas comment se retirer après avoir établi une connexion. Beaucoup de gens pensent que si HAProxy renvoie une erreur sur les tentatives de nginx et nginx, alors tout ira bien. Pas vraiment. Vous pouvez accéder à un autre HAProxy et au même backend, car les pools de backend sont les mêmes. Vous introduisez donc un niveau d'abstraction supplémentaire pour vous-même, ce qui réduit la précision de votre équilibrage et, par conséquent, la disponibilité du service.
Nous avons nginx + Envoy, mais si vous êtes confus, vous pouvez vous limiter à Envoy uniquement.
Quel genre d'envoyé?
Envoy est un équilibreur de charge pour les jeunes à la mode, développé à l'origine en Lyft, écrit en C ++.
Hors de la boîte, il peut faire un tas de petits pains sur notre sujet aujourd'hui. Vous l'avez probablement vu comme un maillage de service pour Kubernetes. En règle générale, Envoy agit comme un plan de données, c'est-à-dire qu'il équilibre directement le trafic, et il existe également un plan de contrôle qui fournit des informations sur ce dont vous avez besoin pour répartir la charge entre (découverte de service, etc.).
Je vais vous dire quelques mots sur ses petits pains.
Pour augmenter les chances de réussite d'une nouvelle tentative de réponse la prochaine fois que vous essayez, vous pouvez dormir un peu et attendre que les backends reprennent leurs esprits. De cette façon, nous traiterons les problèmes de base de données courts. Envoy a un
délai d'attente pour les relances - fait une pause entre les relances. De plus, l'intervalle de retard entre les tentatives augmente de façon exponentielle. La première nouvelle tentative se produit après 0-24 ms, la seconde après 0-74 ms, puis pour chaque tentative suivante, l'intervalle augmente et le retard spécifique est sélectionné de manière aléatoire dans cet intervalle.
La seconde approche n'est pas spécifique à l'Envoy, mais un modèle appelé
Circuit breaking (disjoncteur ou fusible). Lorsque notre backend s'émousse, en fait, nous essayons de le terminer à chaque fois. En effet, les utilisateurs dans une situation incompréhensible cliquent sur la page d'actualisation, vous envoyant de plus en plus de nouvelles demandes. Vos équilibreurs deviennent nerveux, envoient de nouvelles tentatives, le nombre de demandes augmente - la charge augmente, et dans cette situation, ce serait bien de ne pas envoyer de demandes.
Le disjoncteur vous permet simplement de déterminer que nous sommes dans cet état, de tirer rapidement l'erreur et de donner aux backends «le souffle coupé».
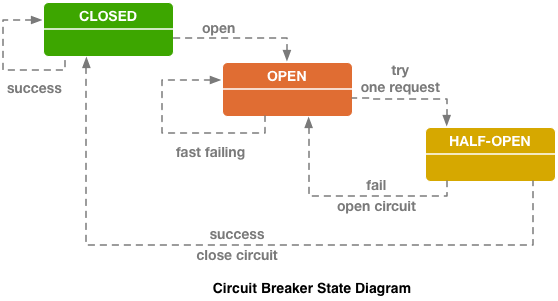 Disjoncteur (hystrix like libs), original sur le blog d'ebay.
Disjoncteur (hystrix like libs), original sur le blog d'ebay.Ci-dessus, le circuit du disjoncteur Hystrix. Hystrix est la bibliothèque Java de Netflix conçue pour implémenter des modèles de tolérance aux pannes.
- Le «fusible» peut être à l'état «fermé» lorsque toutes les demandes sont envoyées au backend et qu'il n'y a aucune erreur.
- Lorsqu'un certain seuil de défaillance est déclenché, c'est-à-dire que certaines erreurs se sont produites, le disjoncteur passe à l'état «Ouvert». Il renvoie rapidement une erreur au client et les demandes ne parviennent pas au backend.
- Une fois dans un certain laps de temps, une petite partie des demandes est toujours envoyée au backend. Si une erreur est déclenchée, l'état reste "Ouvert". Si tout commence à bien fonctionner et à répondre, le «fusible» se ferme et le travail continue.
Dans Envoy, en tant que tel, ce n'est pas tout. Il existe des limites de niveau supérieur sur le fait qu'il ne peut y avoir plus de N demandes pour un groupe en amont spécifique. Si plus, quelque chose ne va pas ici - nous retournons une erreur. Il ne peut plus y avoir N de nouvelles tentatives actives (c'est-à-dire des tentatives qui se produisent actuellement).
Vous n'avez pas eu de nouvelles tentatives, quelque chose a explosé - envoyez des nouvelles tentatives. Envoy comprend que plus de N est anormal et toutes les demandes doivent être traitées avec une erreur.
Disjoncteur [Envoyé]- Nombre maximal de connexions de cluster (groupe en amont)
- Nombre maximal de demandes en attente du cluster
- Nombre maximal de demandes de cluster
- Nouvelles tentatives actives du cluster
Cette chose simple fonctionne bien, elle est configurable, vous n'avez pas à proposer de paramètres spéciaux et les paramètres par défaut sont assez bons.
Disjoncteur: notre expérience
Auparavant, nous avions un collecteur de métriques HTTP, c'est-à-dire que les agents installés sur les serveurs de nos clients envoyaient des métriques à notre cloud via HTTP. Si nous rencontrons des problèmes dans l'infrastructure, l'agent écrit les métriques sur son disque puis essaie de nous les envoyer.
Et les agents tentent constamment de nous envoyer des données, ils ne sont pas fâchés que nous répondions de manière incorrecte et ne partons pas.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
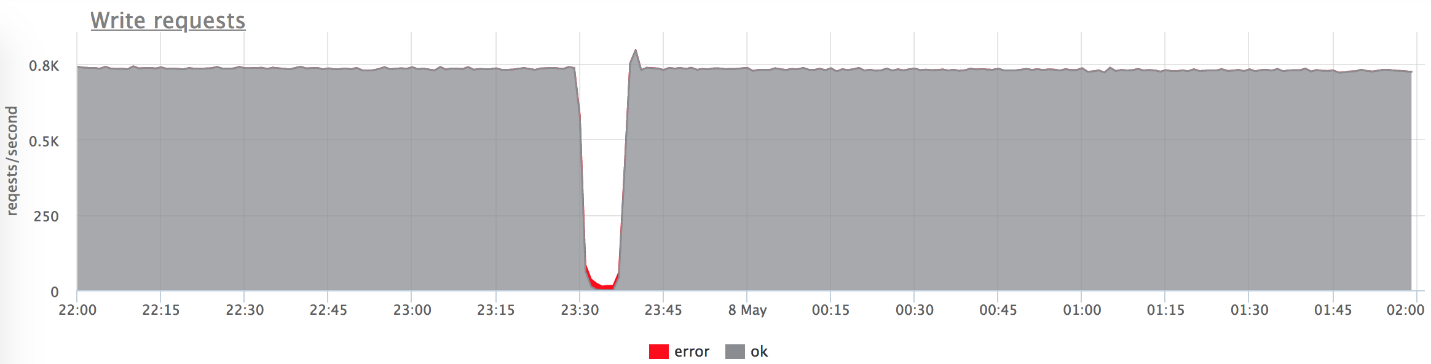
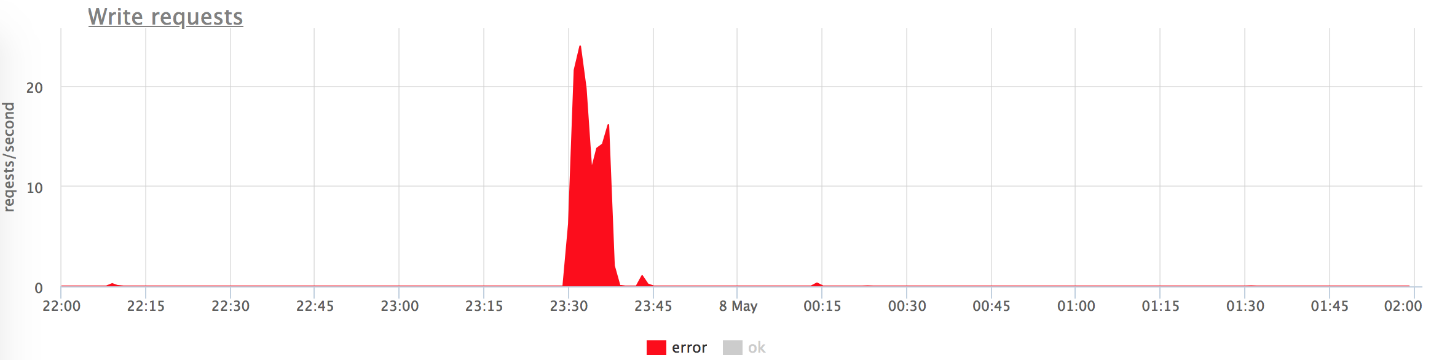
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
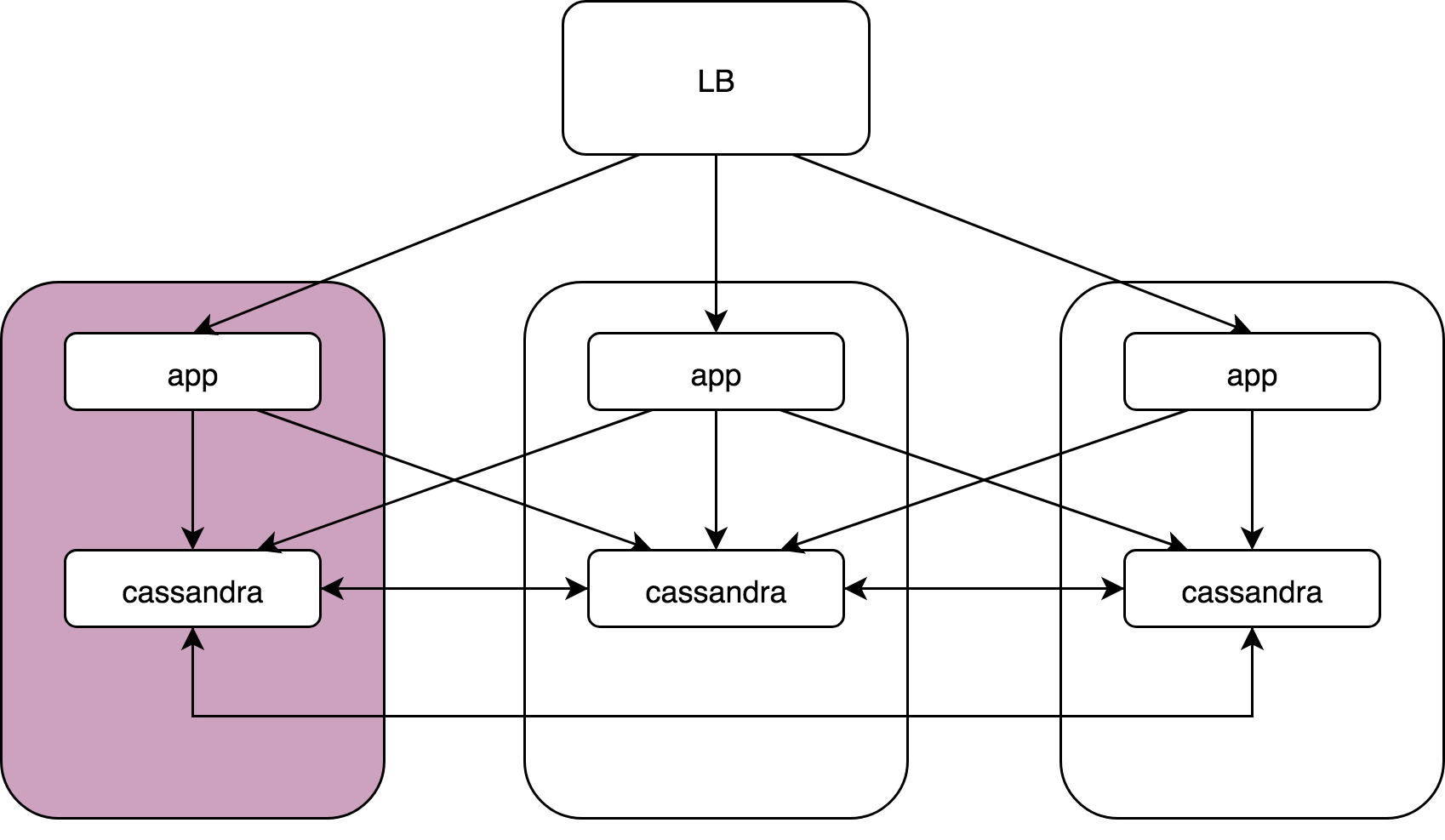
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .