System.IO.Pipelines est une nouvelle bibliothèque qui simplifie l'organisation du code dans .NET. Il est difficile d'assurer des performances et une précision élevées si vous devez gérer un code complexe. La tâche de System.IO.Pipelines est de simplifier le code. Plus de détails sous la coupe!

La bibliothèque est née des efforts de l'équipe de développement .NET Core pour faire de Kestrel l'un des
serveurs Web les plus rapides de l'industrie . Il a été initialement conçu dans le cadre de l'implémentation de Kestrel, mais est devenu une API réutilisable, disponible dans la version 2.1 en tant qu'API BCL de première classe (System.IO.Pipelines).
Quels problèmes résout-elle?
Pour analyser correctement les données d'un flux ou d'une socket, vous devez écrire une grande quantité de code standard. En même temps, de nombreux pièges compliquent le code lui-même et son support.
Quelles difficultés surgissent aujourd'hui?
Commençons par une tâche simple. Nous devons écrire un serveur TCP qui reçoit des messages séparés par des lignes (\ n) du client.
Serveur TCP avec NetworkStream
DÉVIATION: comme dans toute tâche nécessitant des performances élevées, chaque cas spécifique doit être considéré en fonction des caractéristiques de votre application. Il peut ne pas être judicieux de consacrer des ressources à l'utilisation de diverses approches, qui seront discutées plus loin, si l'échelle de l'application réseau n'est pas très grande.
Le code .NET normal avant d'utiliser des pipelines ressemble à ceci:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
voir
sample1.cs sur
githubCe code fonctionnera probablement avec les tests locaux, mais il contient un certain nombre d'erreurs:
- Peut-être qu'après un seul appel à ReadAsync, le message entier ne sera pas reçu (jusqu'à la fin de la ligne).
- Il ignore le résultat de la méthode stream.ReadAsync () - la quantité de données réellement transférées vers le tampon.
- Le code ne gère pas la réception de plusieurs lignes dans un seul appel ReadAsync.
Ce sont les erreurs de lecture des données de streaming les plus courantes. Pour les éviter, vous devez effectuer un certain nombre de modifications:
- Vous devez mettre en mémoire tampon les données entrantes jusqu'à ce qu'une nouvelle ligne soit trouvée.
- Il est nécessaire d'analyser toutes les lignes renvoyées dans le tampon.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
voir
sample2.cs sur
githubJe le répète: cela pourrait fonctionner avec des tests locaux, mais parfois il y a des chaînes de plus de 1 Ko (1024 octets). Il est nécessaire d'augmenter la taille du tampon d'entrée jusqu'à ce qu'une nouvelle ligne soit trouvée.
De plus, nous collectons des tampons dans un tableau lors du traitement de longues chaînes. Nous pouvons améliorer ce processus avec ArrayPool, qui évite la réallocation des tampons lors de l'analyse des longues lignes du client.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
voir sample3.cs sur githubLe code fonctionne, mais maintenant la taille du tampon a changé, en conséquence, de nombreuses copies en apparaissent. Plus de mémoire est également utilisée, car la logique ne réduit pas le tampon après le traitement des lignes. Pour éviter cela, vous pouvez enregistrer la liste des tampons, plutôt que de modifier la taille du tampon chaque fois qu'une chaîne arrive plus longtemps que 1 Ko.
De plus, nous n'augmentons pas la taille de la mémoire tampon de 1 Ko, jusqu'à ce qu'elle soit complètement vide. Cela signifie que nous transférerons des tampons de plus en plus petits vers ReadAsync, par conséquent, le nombre d'appels au système d'exploitation augmentera.
Nous essaierons d'éliminer cela et allouerons un nouveau tampon dès que la taille de l'existant deviendra inférieure à 512 octets:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
voir sample4.cs sur githubEn conséquence, le code est considérablement compliqué. Lors de la recherche du délimiteur, nous suivons les tampons remplis. Pour ce faire, utilisez une liste, qui affiche des données en mémoire tampon lors de la recherche d'un nouveau séparateur de ligne. Par conséquent, ProcessLine et IndexOf accepteront List au lieu de byte [], offset et count. La logique d'analyse commencera à traiter un segment du tampon ou plusieurs.
Et maintenant, le serveur traitera les messages partiels et utilisera la mémoire partagée pour réduire la consommation globale de mémoire. Cependant, un certain nombre de modifications doivent être apportées:
- Depuis ArrayPoolbyte, nous n'utilisons que Byte [] - des tableaux gérés de manière standard. En d'autres termes, lorsque les fonctions ReadAsync ou WriteAsync sont exécutées, la période de validité des tampons est liée à l'heure de l'opération asynchrone (pour interagir avec les propres API d'E / S du système d'exploitation). Étant donné que la mémoire épinglée ne peut pas être déplacée, cela affecte les performances du garbage collector et peut provoquer une fragmentation de la baie. Vous devrez peut-être modifier l'implémentation du pool, en fonction de la durée d'attente des opérations asynchrones.
- Le débit peut être amélioré en rompant le lien entre la lecture et la logique du processus. Nous obtenons l'effet du traitement par lots, et maintenant la logique d'analyse sera capable de lire de grandes quantités de données, en traitant de gros blocs de tampons, plutôt que d'analyser des lignes individuelles. En conséquence, le code devient encore plus compliqué:
- Il est nécessaire de créer deux cycles qui fonctionnent indépendamment l'un de l'autre. Le premier lira les données du socket et le second analysera les tampons.
- Ce qu'il faut, c'est un moyen de dire à la logique d'analyse que les données deviennent disponibles.
- Il est également nécessaire de déterminer ce qui se passe si la boucle lit les données du socket trop rapidement. Nous avons besoin d'un moyen d'ajuster le cycle de lecture si la logique d'analyse ne le suit pas. Ceci est communément appelé «contrôle de flux» ou «résistance à l'écoulement».
- Nous devons nous assurer que les données sont transmises en toute sécurité. Maintenant, l'ensemble de tampons est utilisé à la fois par le cycle de lecture et le cycle d'analyse; ils fonctionnent indépendamment les uns des autres sur différents threads.
- La logique de gestion de la mémoire est également impliquée dans deux éléments de code différents: l'emprunt de données du pool de tampons, qui lit les données du socket, et le retour du pool de tampons, qui est la logique d'analyse.
- Il faut être extrêmement prudent avec le retour de tampons après avoir exécuté la logique d'analyse. Sinon, il est possible que nous retournions le tampon dans lequel la logique de lecture du socket est toujours en cours d'écriture.
La complexité commence à passer par le toit (et c'est loin d'être le cas!). Pour créer un réseau hautes performances, vous devez écrire du code très complexe.
Le but de System.IO.Pipelines est de simplifier cette procédure.
Serveur TCP et System.IO.Pipelines
Voyons comment fonctionne System.IO.Pipelines:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
voir sample5.cs sur githubLa version en pipeline de notre lecteur de ligne a deux boucles:
- FillPipeAsync lit à partir du socket et écrit dans PipeWriter.
- ReadPipeAsync lit à partir de PipeReader et analyse les lignes entrantes.
Contrairement aux premiers exemples, il n'y a pas de tampons spécialement affectés. C'est l'une des principales fonctions de System.IO.Pipelines. Toutes les tâches de gestion des tampons sont transférées vers les implémentations PipeReader / PipeWriter.
La procédure est simplifiée: nous utilisons le code uniquement pour la logique métier, au lieu d'implémenter une gestion complexe des tampons.
Dans la première boucle, PipeWriter.GetMemory (int) est d'abord appelé pour obtenir une certaine quantité de mémoire du rédacteur principal. Puis PipeWriter.Advance (int) est appelé, ce qui indique à PipeWriter combien de données sont réellement écrites dans le tampon. Ceci est suivi d'un appel à PipeWriter.FlushAsync () afin que PipeReader puisse accéder aux données.
La deuxième boucle consomme les tampons qui ont été écrits par PipeWriter mais reçus à l'origine du socket. Lorsque la demande à PipeReader.ReadAsync () est renvoyée, nous obtenons un ReadResult contenant deux messages importants: les données lues sous la forme ReadOnlySequence, ainsi que le type de données logique IsCompleted, qui indique au lecteur si l'écrivain a fini de travailler (EOF). Lorsque le terminateur de ligne (EOL) est trouvé et que la chaîne est analysée, nous diviserons le tampon en parties pour ignorer le fragment qui a déjà été traité. Après cela, PipeReader.AdvanceTo est appelé et indique à PipeReader combien de données ont été consommées.
À la fin de chaque cycle, le lecteur et l'écrivain sont terminés. Par conséquent, le canal principal libère toute la mémoire allouée.
System.io.pipelines
Lecture partielle
En plus de gérer la mémoire, System.IO.Pipelines remplit une autre fonction importante: il analyse les données dans le canal, mais ne les consomme pas.
PipeReader possède deux API principales: ReadAsync et AdvanceTo. ReadAsync reçoit des données du canal, AdvanceTo indique à PipeReader que ces tampons ne sont plus requis par le lecteur, vous pouvez donc vous en débarrasser (par exemple, les renvoyer dans le pool de tampons principal).
Voici un exemple d'un analyseur HTTP qui lit les données des tampons de données de canal partiels jusqu'à ce qu'il reçoive une ligne de départ appropriée.

ReadOnlySequenceT
L'implémentation de canal stocke une liste de tampons associés transmis entre PipeWriter et PipeReader. PipeReader.ReadAsync expose ReadOnlySequence, qui est un nouveau type de BCL et se compose d'un ou plusieurs segments ReadOnlyMemory <T>. Il est similaire à Span ou Memory, ce qui nous donne la possibilité de regarder des tableaux et des chaînes.
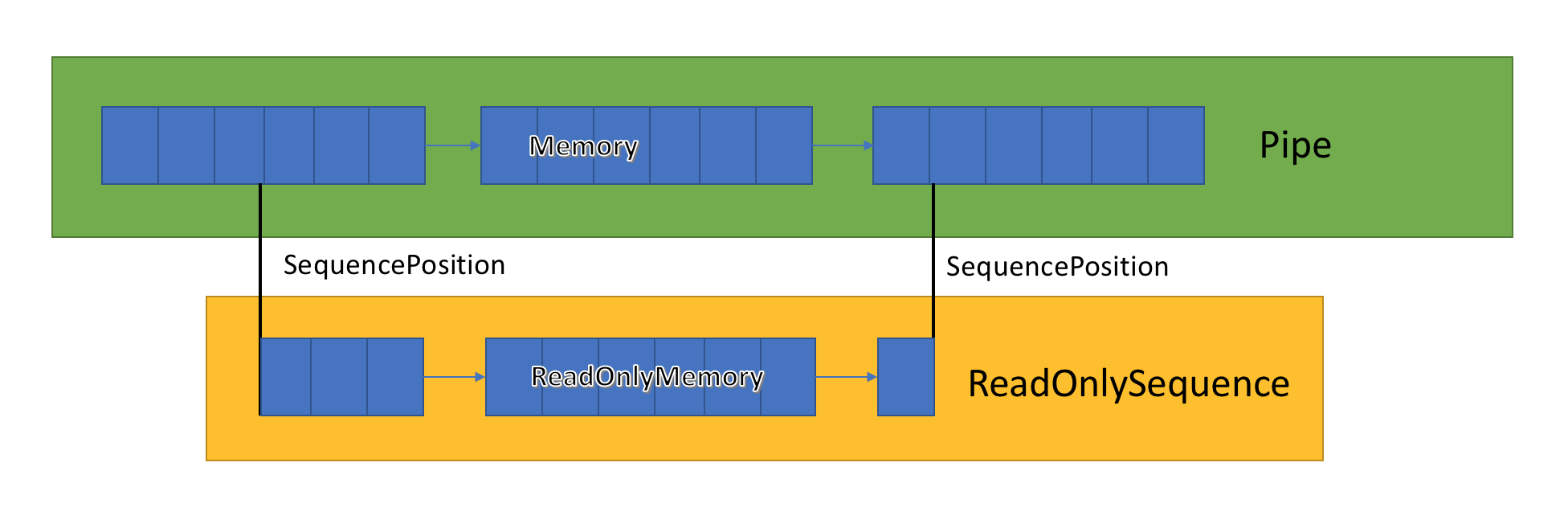
À l'intérieur du canal, il existe des pointeurs qui indiquent où se trouvent le lecteur et l'écrivain dans l'ensemble général de données en surbrillance, et les mettent également à jour au fur et à mesure que les données sont écrites et lues. SequencePosition est un point unique dans une liste liée de tampons et est utilisé pour séparer efficacement ReadOnlySequence <T>.
Étant donné que ReadOnlySequence <T> prend en charge un ou plusieurs segments, le fonctionnement standard de la logique hautes performances consiste à séparer les chemins rapides et lents en fonction du nombre de segments.
À titre d'exemple, voici une fonction qui convertit ASCII ReadOnlySequence en une chaîne:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
voir
sample6.cs sur
githubRésistance à l'écoulement et contrôle du débit
Idéalement, la lecture et l'analyse fonctionnent ensemble: le flux de lecture consomme les données du réseau et les place dans des tampons, tandis que le flux d'analyse crée des structures de données appropriées. L'analyse prend généralement plus de temps que la simple copie de blocs de données à partir du réseau. Par conséquent, le flux de lecture peut facilement surcharger le flux d'analyse. Par conséquent, le flux de lecture sera obligé de ralentir ou de consommer plus de mémoire pour enregistrer les données pour le flux d'analyse. Pour garantir des performances optimales, un équilibre est nécessaire entre la fréquence de pause et l'allocation d'une grande quantité de mémoire.
Pour résoudre ce problème, le pipeline a deux fonctions de contrôle de flux de données: PauseWriterThreshold et ResumeWriterThreshold. PauseWriterThreshold détermine la quantité de données qui doit être mise en mémoire tampon avant que PipeWriter.FlushAsync ne soit suspendu. ResumeWriterThreshold détermine la quantité de mémoire que le lecteur peut consommer avant que l'enregistreur ne reprenne ses opérations.
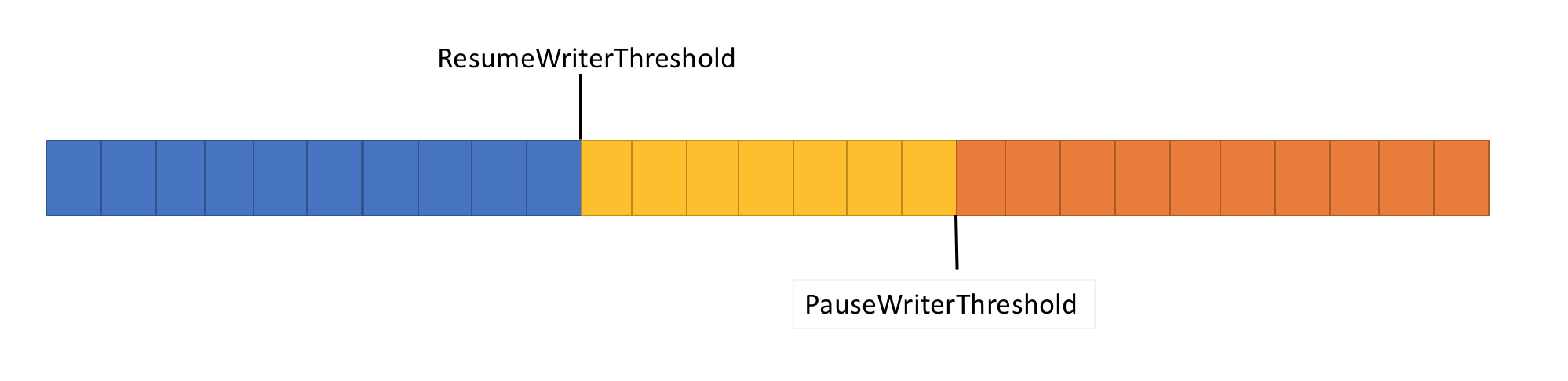
PipeWriter.FlushAsync «se verrouille» lorsque la quantité de données dans le flux en pipeline dépasse la limite définie dans PauseWriterThreshold et «déverrouille» lorsqu'elle tombe en dessous de la limite définie dans ResumeWriterThreshold. Pour éviter de dépasser la limite de consommation, seules deux valeurs sont utilisées.
Planification des E / S
Lorsque vous utilisez async / wait, les opérations suivantes sont généralement appelées dans les threads de pool ou dans le SynchronizationContext en cours.
Lors de l'exécution d'E / S, il est très important de surveiller attentivement où il est exécuté afin de mieux utiliser le cache du processeur. Ceci est essentiel pour les applications hautes performances telles que les serveurs Web. System.IO.Pipelines utilise le PipeScheduler pour déterminer où exécuter les rappels asynchrones. Cela vous permet de contrôler très précisément les flux à utiliser pour les E / S.
Un exemple d'application pratique est le transport Kestrel Libuv, dans lequel les rappels d'E / S sont effectués sur des canaux dédiés de la boucle d'événements.
Le modèle PipeReader présente d'autres avantages.
- Certains systèmes de base prennent en charge «attendre sans mise en mémoire tampon»: vous n'avez pas besoin d'allouer de mémoire tampon jusqu'à ce que les données disponibles apparaissent dans le système de base. Donc, sur Linux avec epoll, vous ne pouvez pas fournir de tampon de lecture tant que les données ne sont pas prêtes. Cela évite la situation lorsque de nombreux threads attendent des données et que vous devez immédiatement réserver une énorme quantité de mémoire.
- Le pipeline par défaut facilite l'écriture de tests unitaires de code réseau: la logique d'analyse est distincte du code réseau, et les tests unitaires exécutent uniquement cette logique dans des tampons en mémoire, plutôt que de la consommer directement à partir du réseau. Il permet également de tester facilement des modèles complexes en envoyant des données partielles. ASP.NET Core l'utilise pour tester divers aspects des outils d'analyse http de Kestrel.
- Les systèmes qui permettent au code utilisateur d'utiliser les principaux tampons du système d'exploitation (par exemple, les API d'E / S Windows enregistrées) conviennent initialement à l'utilisation de pipelines car l'implémentation PipeReader fournit toujours des tampons.
Autres types connexes
Nous avons également ajouté un certain nombre de nouveaux types BCL simples à System.IO.Pipelines:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT a été ajouté dans .NET Core 1.0, et dans .NET Core 2.1, il existe désormais une représentation abstraite plus générale pour un pool qui fonctionne avec n'importe quel MemoryT. Nous obtenons un point d'extensibilité qui nous permet de mettre en œuvre des stratégies de distribution plus avancées, ainsi que de contrôler la gestion des tampons (par exemple, utiliser des tampons prédéfinis au lieu de tableaux exclusivement gérés).
- IBufferWriterT est un récepteur pour l'enregistrement de données tamponnées synchronisées (implémenté par PipeWriter).
- IValueTaskSource - ValueTaskT existe depuis la sortie de .NET Core 1.1, mais dans .NET Core 2.1, il a acquis des outils extrêmement efficaces qui fournissent des opérations asynchrones ininterrompues sans distribution. Voir ici pour plus d'informations.
Comment utiliser les convoyeurs?
Les API se trouvent dans le package nuget
System.IO.Pipelines .
Pour un exemple d'application serveur .NET Server 2.1 qui utilise des pipelines pour traiter les messages en minuscules (de l'exemple ci-dessus), voir
ici . Il peut être démarré en utilisant dotnet run (ou Visual Studio). Dans l'exemple, les données devraient être transmises à partir du socket sur le port 8087, puis les messages reçus sont écrits sur la console. Vous pouvez utiliser un client, tel que netcat ou putty, pour vous connecter au port 8087. Envoyez un message en minuscules et voyez comment cela fonctionne.
Actuellement, le pipeline fonctionne sur Kestrel et SignalR, et nous espérons qu'il trouvera à l'avenir une application plus large dans de nombreuses bibliothèques réseau et composants de la communauté .NET.