
Dès le début, nous avons planifié des solutions d'ingénierie et de produits afin que Discord soit bien adapté au chat vocal tout en jouant avec des amis. Ces solutions ont permis de faire évoluer considérablement le système, d'avoir une petite équipe et des ressources limitées.
Cet article décrit les différentes technologies utilisées par Discord pour les conversations audio / vidéo.
Pour plus de clarté, nous appellerons l'ensemble du groupe d'utilisateurs et les canaux le «groupe» (guilde) - dans le client, ils sont appelés «serveurs». Au lieu de cela, le terme «serveur» fait référence à notre infrastructure de serveurs.Principes fondamentaux
Chaque discussion audio / vidéo dans Discord prend en charge de nombreux participants. Nous avons vu un millier de personnes discuter à tour de rôle dans des discussions en grand groupe. Une telle prise en charge nécessite une architecture client-serveur, car un réseau peer-to-peer peer-to-peer devient prohibitif avec une augmentation du nombre de participants.
Le routage du trafic réseau via les serveurs Discord garantit également que votre adresse IP n'est jamais visible - et personne ne lancera une attaque DDoS. Le routage via des serveurs présente d'autres avantages: par exemple, la modération. Les administrateurs peuvent rapidement désactiver le son et la vidéo pour les intrus.
Architecture client
Discord fonctionne sur de nombreuses plateformes.
- Web (Chrome / Firefox / Edge, etc.)
- Application autonome (Windows, MacOS, Linux)
- Téléphone (iOS / Android)
Nous pouvons prendre en charge toutes ces plates-formes d'une seule manière: grâce à la réutilisation du code
WebRTC . Cette spécification pour les communications en temps réel comprend des composants réseau, audio et vidéo. La norme est adoptée
par le World Wide Web Consortium et l'
Internet Engineering Group . WebRTC est disponible dans tous les navigateurs modernes et en tant que bibliothèque native pour une implémentation dans les applications.
L'audio et la vidéo dans Discord s'exécutent sur WebRTC. Ainsi, l'application de navigateur repose sur l'implémentation de WebRTC dans le navigateur. Cependant, les applications pour ordinateurs de bureau, iOS et Android utilisent un seul moteur multimédia C ++ construit au-dessus de leur propre bibliothèque WebRTC, qui est spécialement adapté aux besoins de nos utilisateurs. Cela signifie que certaines fonctions de l'application fonctionnent mieux que dans le navigateur. Par exemple, dans nos applications natives, nous pouvons:
- Contourner le volume de Windows par défaut, lorsque toutes les applications sont automatiquement désactivées lors de l'utilisation d'un casque . Cela n'est pas souhaitable lorsque vous et vos amis partez en raid et coordonnez les activités de discussion Discord.
- Utilisez votre propre contrôle de volume au lieu du mélangeur de système d'exploitation global.
- Traitez les données audio d'origine pour détecter l'activité vocale et diffuser l'audio et la vidéo dans les jeux.
- Réduisez la bande passante et la consommation du processeur pendant les périodes de silence - même dans les conversations vocales les plus nombreuses à un moment donné, seules quelques personnes parlent en même temps.
- Fournit des fonctionnalités à l'échelle du système pour le mode push to talk.
- Envoyez avec des paquets audio-vidéo des informations supplémentaires (par exemple, un indicateur de priorité dans le chat).
Avoir votre propre version de WebRTC signifie des mises à jour fréquentes pour tous les utilisateurs: c'est un processus long que nous essayons d'automatiser. Mais cet effort est payant grâce aux spécificités de nos joueurs.
Dans Discord, la communication vocale et vidéo est lancée en entrant un canal vocal ou un appel. Autrement dit, la connexion est toujours initiée par le client - cela réduit la complexité des parties client et serveur et augmente également la tolérance aux erreurs. En cas de défaillance de l'infrastructure, les participants peuvent simplement se reconnecter au nouveau serveur interne.
Sous notre contrôle
Le contrôle de la bibliothèque native vous permet d'implémenter certaines fonctions différemment de l'implémentation du navigateur de WebRTC.
Tout d'abord, WebRTC s'appuie sur le protocole de description de session (
SDP ) pour négocier l'audio / vidéo entre les participants (jusqu'à 10 Ko par échange de paquets). Dans sa propre bibliothèque, l'API de niveau inférieur de WebRTC (
webrtc::Call ) est utilisée pour créer les deux flux - entrant et sortant. Lorsqu'il est connecté à un canal vocal, l'échange d'informations est minime. Il s'agit de l'adresse et du port du serveur principal, de la méthode de chiffrement, des clés, du codec et de l'identification du flux (environ 1000 octets).
webrtc::AudioSendStream* createAudioSendStream( uint32_t ssrc, uint8_t payloadType, webrtc::Transport* transport, rtc::scoped_refptr<webrtc::AudioEncoderFactory> audioEncoderFactory, webrtc::Call* call) { webrtc::AudioSendStream::Config config{transport}; config.rtp.ssrc = ssrc; config.rtp.extensions = {{"urn:ietf:params:rtp-hdrext:ssrc-audio-level", 1}}; config.encoder_factory = audioEncoderFactory; const webrtc::SdpAudioFormat kOpusFormat = {"opus", 48000, 2}; config.send_codec_spec = webrtc::AudioSendStream::Config::SendCodecSpec(payloadType, kOpusFormat); webrtc::AudioSendStream* audioStream = call->CreateAudioSendStream(config); audioStream->Start(); return audioStream; }
En outre, WebRTC utilise Interactive Connectivity Establishment (
ICE ) pour déterminer le meilleur itinéraire entre les participants. Étant donné que chaque client se connecte au serveur, nous n'avons pas besoin d'ICE. Cela vous permet de fournir une connexion beaucoup plus fiable si vous êtes derrière NAT et de garder votre adresse IP secrète des autres participants. Les clients effectuent régulièrement des requêtes ping afin que le pare-feu maintienne une connexion ouverte.
Enfin, WebRTC utilise le protocole
SRTP (Secure Real-time Transport Protocol) pour crypter les médias. Les clés de chiffrement sont définies à l'aide du protocole Datagram Transport Layer Security (
DTLS ) basé sur TLS standard. La bibliothèque WebRTC intégrée vous permet d'implémenter votre propre couche de transport à l'aide de l'API
webrtc::Transport .
Au lieu de DTLS / SRTP, nous avons décidé d'utiliser un
cryptage Salsa20 plus rapide. De plus, nous n'envoyons pas de données audio pendant les périodes de silence - un phénomène courant, en particulier dans les grandes salles de chat. Cela conduit à des économies importantes de bande passante et de ressources CPU, cependant, le client et le serveur doivent être prêts à tout moment à cesser de recevoir des données et à réécrire les numéros de série des paquets audio / vidéo.
Étant donné que l'application Web utilise l'implémentation basée sur navigateur de l'
API WebRTC , SDP, ICE, DTLS et SRTP ne peuvent pas être abandonnés. Le client et le serveur échangent toutes les informations nécessaires (moins de 1200 octets lors de l'échange de paquets) - et la session SDP est établie sur la base de ces informations pour les clients. Le backend est chargé de résoudre les différences entre les applications de bureau et de navigateur.
Architecture de backend
Il existe plusieurs services de chat vocal sur le backend, mais nous nous concentrerons sur trois: Discord Gateway, Discord Guilds et Discord Voice. Tous nos serveurs de signaux sont écrits en
Elixir , ce qui nous permet de réutiliser le code à plusieurs reprises.
Lorsque vous êtes en ligne, votre client prend en charge une connexion WebSocket à une passerelle Discord (nous l'appelons une connexion de
passerelle WebSocket). Grâce à cette connexion, votre client reçoit des événements liés aux groupes et canaux, messages texte, packages de présence, etc.
Lorsqu'il est connecté à un canal vocal, l'état de la connexion est affiché par l'
objet d' état vocal. Le client met à jour cet objet via la connexion de passerelle.
defmodule VoiceStates.VoiceState do @type t :: %{ session_id: String.t(), user_id: Number.t(), channel_id: Number.t() | nil, token: String.t() | nil, mute: boolean, deaf: boolean, self_mute: boolean, self_deaf: boolean, self_video: boolean, suppress: boolean } defstruct session_id: nil, user_id: nil, token: nil, channel_id: nil, mute: false, deaf: false, self_mute: false, self_deaf: false, self_video: false, suppress: false end
Lorsque vous êtes connecté à un canal vocal, vous êtes affecté à l'un des serveurs Discord Voice. Il est responsable de la transmission du son à chaque participant de la chaîne. Tous les canaux vocaux d'un groupe sont affectés à un serveur. Si vous êtes le premier à discuter, le serveur Discord Guilds est responsable de l'attribution du serveur Discord Voice à l'ensemble du groupe en utilisant le processus décrit ci-dessous.
Destination du serveur vocal Discord
Chaque serveur Discord Voice fait périodiquement rapport sur son état et sa charge. Ces informations sont placées dans un système de découverte de services (nous utilisons
etcd ), comme indiqué dans un
article précédent .
Le serveur Discord Guilds surveille le système de découverte de services et attribue au groupe le serveur Discord Voice le moins utilisé de la région. Lorsque cette option est sélectionnée, tous les objets d'état de la voix (également pris en charge par le serveur Discord Guilds) sont transférés vers le serveur Discord Voice afin qu'il puisse configurer le transfert audio / vidéo. Les clients sont informés du serveur Discord Voice sélectionné. Ensuite, le client ouvre la
deuxième connexion WebSocket avec le serveur vocal (nous l'appelons la connexion
vocale WebSocket), qui est utilisée pour configurer le transfert multimédia et l'indication vocale.
Lorsque le client affiche l'état
En attente du point de terminaison , cela signifie que le serveur Discord Guilds recherche le serveur Discord Voice optimal. Un message
Voice Connected indique que le client a réussi à échanger des paquets UDP avec le serveur Discord Voice sélectionné.
Le serveur Discord Voice contient deux composants: un module de signaux et une unité de relais multimédia, appelée unité de transfert sélectif (
SFU ). Le module de signal contrôle entièrement la SFU et est responsable de la génération des identificateurs de flux et des clés de chiffrement, de la redirection des indicateurs vocaux, etc.
Notre SFU (en C ++) est chargée de diriger le trafic audio et vidéo entre les canaux. Il est développé seul: pour notre cas particulier, SFU offre des performances maximales et, par conséquent, les plus grandes économies. Lorsque les modérateurs violent (coupent le son du serveur), leurs paquets audio ne sont pas traités. SFU fonctionne également comme un pont entre les applications natives et basées sur un navigateur: il implémente le transport et le chiffrement pour les applications natives et du navigateur, convertissant les paquets pendant la transmission. Enfin, la SFU est responsable du traitement du protocole
RTCP , qui est utilisé pour optimiser la qualité vidéo. SFU collecte et traite les rapports RTCP des destinataires - et informe les expéditeurs de la bande disponible pour la transmission vidéo.
Tolérance aux pannes
Étant donné que seuls les serveurs Discord Voice sont disponibles directement depuis Internet, nous en parlerons.
Le module de signal surveille en permanence le SFU. S'il se bloque, il redémarre instantanément avec une pause minimale en service (plusieurs paquets perdus). Le statut SFU est restauré par le module de signal sans aucune interaction avec le client. Bien que les plantages de SFU soient rares, nous utilisons le même mécanisme pour mettre à jour les SFU sans interruption de service.
Lorsque le serveur Discord Voice tombe en panne, il ne répond pas au ping - et est supprimé du système de découverte de services. Le client remarque également un plantage du serveur en raison d'une connexion vocale WebSocket interrompue, puis il demande le
ping du serveur vocal via la connexion de la passerelle WebSocket. Le serveur Discord Guilds confirme l'échec, consulte le système de découverte de services et attribue un nouveau serveur Discord Voice au groupe. Les Discord Guilds envoient ensuite tous les objets d'état de la voix au nouveau serveur vocal. Tous les clients reçoivent une notification concernant le nouveau serveur et s'y connectent pour démarrer la configuration multimédia.
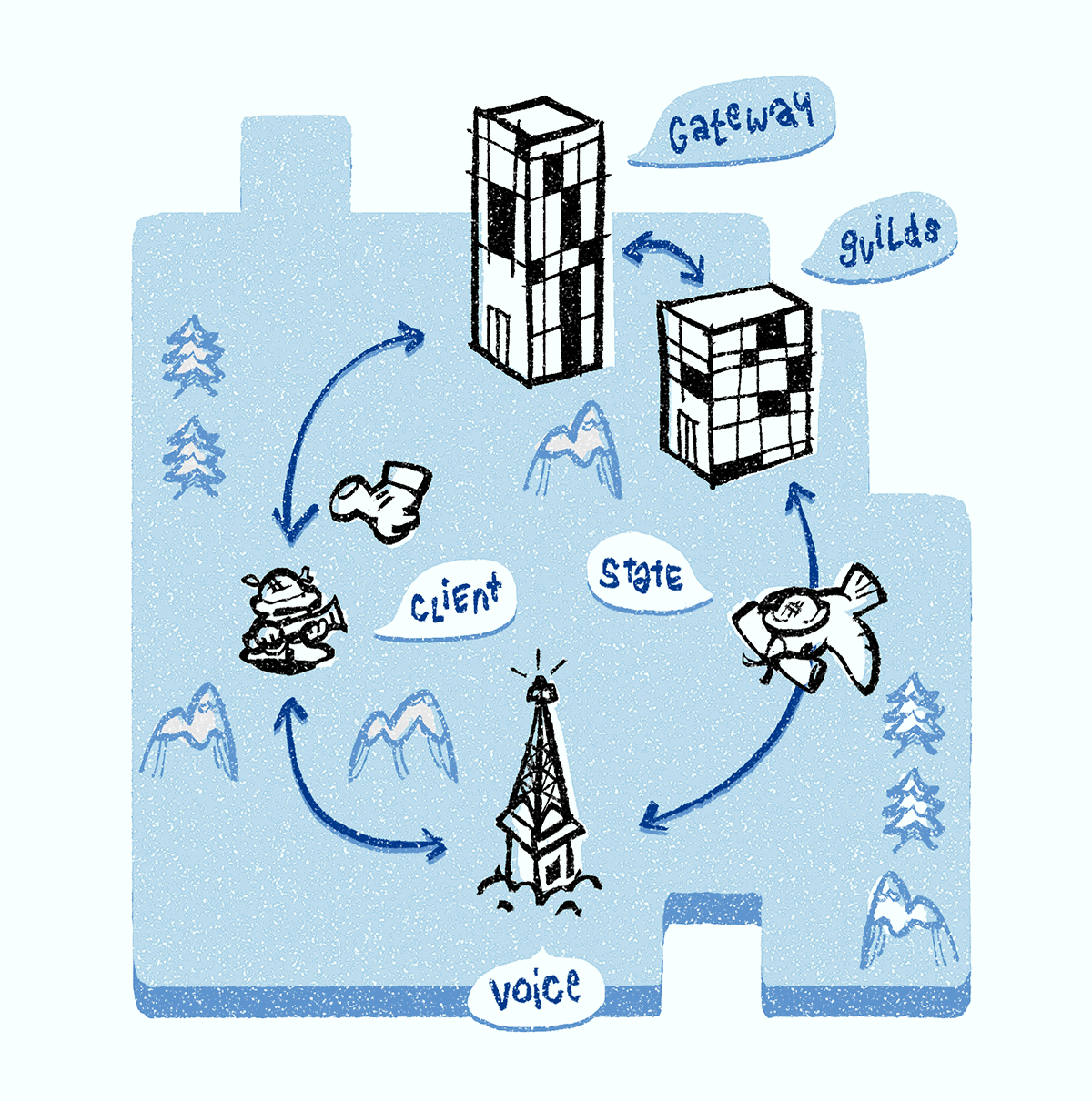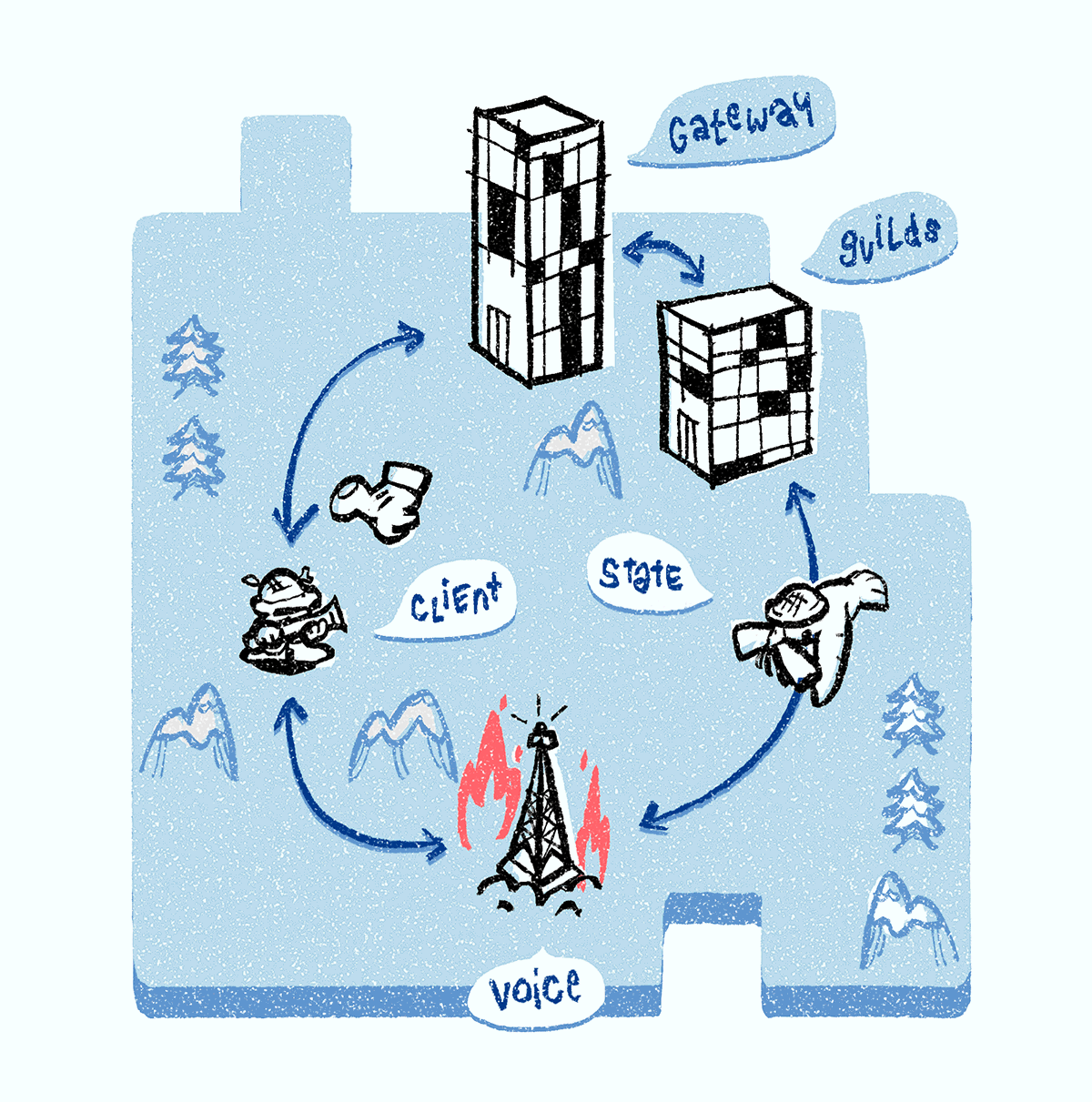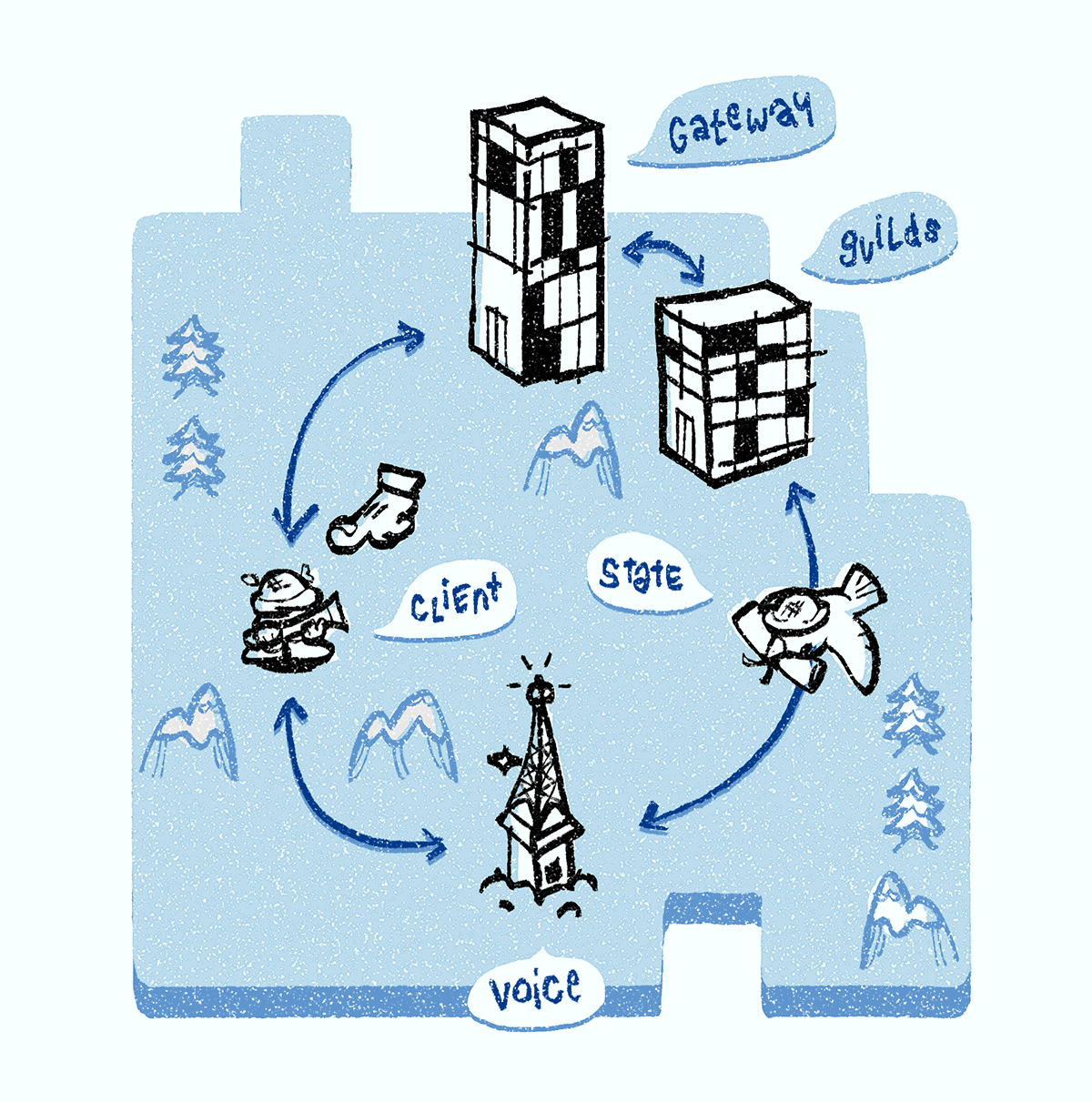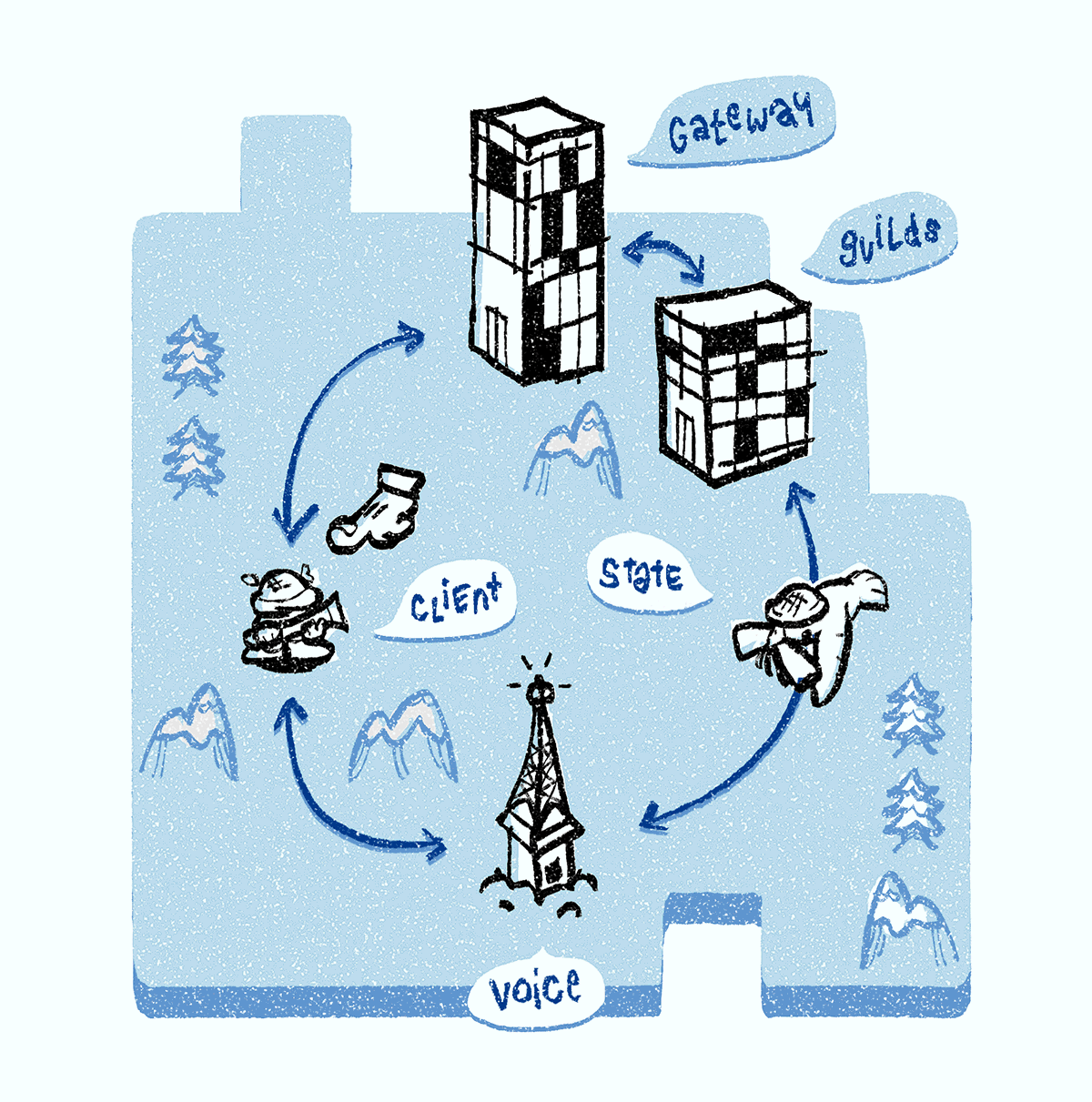
Très souvent, les serveurs Discord Voice tombent sous DDoS (nous voyons cela par l'augmentation rapide des paquets IP entrants). Dans ce cas, nous effectuons la même procédure que lorsque le serveur tombe en panne: nous le supprimons du système de découverte de services, sélectionnons un nouveau serveur, lui transférons tous les objets d'état de communication vocale et informons les clients du nouveau serveur. Lorsque l'attaque DDoS s'apaise, le serveur retourne au système de découverte de services.
Si le propriétaire du groupe décide de choisir une nouvelle région pour le vote, nous suivons une procédure très similaire. Discord Guilds Server sélectionne le meilleur serveur vocal disponible dans une nouvelle région en consultation avec un système de découverte de services. Il y traduit ensuite tous les objets de l'état de la communication vocale et informe les clients du nouveau serveur. Les clients interrompent la connexion WebSocket actuelle avec l'ancien serveur Discord Voice et créent une nouvelle connexion avec le nouveau serveur Discord Voice.
Mise à l'échelle
L'ensemble de l'infrastructure de Discord Gateway, Discord Guilds et Discord Voice prend en charge la mise à l'échelle horizontale. Discord Gateway et Discord Guilds fonctionnent dans Google Cloud.
Nous avons plus de 850 serveurs vocaux dans 13 régions (situées dans plus de 30 centres de données) à travers le monde. Cette infrastructure offre une plus grande redondance en cas de pannes dans les centres de données et les DDoS. Nous travaillons avec plusieurs partenaires et utilisons nos serveurs physiques dans leurs centres de données. Plus récemment, la région sud-africaine a été ajoutée. Grâce aux efforts d'ingénierie dans les architectures client et serveur, Discord est désormais capable de servir simultanément plus de 2,6 millions d'utilisateurs de chat vocal avec un trafic sortant de plus de 220 Gbit / s et 120 millions de paquets par seconde.
Et ensuite?
Nous surveillons en permanence la qualité des communications vocales (les métriques sont envoyées du côté client aux serveurs backend). À l'avenir, ces informations contribueront à la détection et à l'élimination automatiques de la dégradation.
Bien que nous ayons lancé le chat vidéo et les screencasts il y a un an, ils ne peuvent désormais être utilisés que dans des messages privés. Par rapport à l'audio, la vidéo nécessite beaucoup plus de puissance CPU et de bande passante. Le défi consiste à équilibrer la quantité de bande passante et les ressources CPU / GPU utilisées pour garantir la meilleure qualité vidéo, en particulier lorsqu'un groupe de joueurs d'une chaîne se trouve sur différents appareils.
La technologie SVC (
Scalable Video Coding ), une extension de la norme H.264 / MPEG-4 AVC, peut devenir une solution au problème.
Les screencasts nécessitent encore plus de bande passante que la vidéo, en raison du FPS et de la résolution plus élevés que les webcams conventionnelles. Nous travaillons actuellement sur la prise en charge du codage vidéo matériel dans une application de bureau.