
Ce guide guide les directives de conception structurée pour les applications cloud évolutives, résilientes et hautement accessibles. Il est conçu pour vous aider à prendre des décisions concernant votre architecture, quelle que soit la plateforme cloud que vous utilisez.
Le manuel est organisé comme une séquence d'étapes - choisir une architecture → choisir des technologies pour le calcul et le stockage des données → concevoir une application Azure → choisir des modèles → vérifier l'architecture. Pour chacun d'eux, des recommandations vous aideront à développer l'architecture de l'application.
Aujourd'hui, nous publions une partie du premier chapitre de ce livre. Vous pouvez télécharger la version complète gratuitement
ici .
Table des matières
- Le choix de l'architecture - 1;
- Le choix des technologies de calcul et de stockage des données - 35;
- Conception d'une application Azure: principes de conception - 60;
- Conception d'une application Azure: indicateurs de qualité - 95;
- Conception d'une application Azure: modèles de conception - 103;
- Répertoire de modèles - 110;
- Listes de contrôle de validation de l'architecture - 263;
- Conclusion - 291;
- Architectures de référence Azure - 292;
Choix d'architecture
La première décision que vous devez prendre lors de la conception d'une application cloud est de choisir une architecture. Le choix de l'architecture dépend de la complexité de l'application, de sa portée, de son type (IaaS ou PaaS) et des tâches auxquelles elle est destinée. Il est également important de tenir compte des compétences de l'équipe de développement et des chefs de projet, ainsi que de la disponibilité d'une architecture prête à l'emploi pour l'application.
Le choix de l'architecture impose certaines restrictions sur la structure de l'application, limitant le choix des technologies et autres éléments de l'application. Ces limitations sont associées à la fois aux avantages et aux inconvénients de l'architecture sélectionnée.
Les informations de cette section vous aideront à trouver un équilibre entre elles lors de l'implémentation d'une architecture particulière. Cette section répertorie dix principes de conception à garder à l'esprit. Le respect de ces principes vous aidera à créer une application plus évolutive, résiliente et gérable.
Nous avons identifié un ensemble d'options d'architecture couramment utilisées dans les applications cloud. La section dédiée à chacun d'eux contient:
- description et logique de l'architecture;
- des recommandations sur la portée de cette architecture;
- avantages, inconvénients et recommandations d'utilisation;
- Option de déploiement recommandée à l'aide des services Azure appropriés.
Présentation de l'architecture
Cette section fournit un bref aperçu des options d'architecture que nous avons identifiées, ainsi que des recommandations générales pour leur utilisation. Vous pouvez trouver des informations plus détaillées dans les sections pertinentes disponibles via les liens.
Niveau N
L'architecture à N niveaux est le plus couramment utilisée dans les applications d'entreprise. Pour gérer les dépendances, l'application est divisée en couches, chacune étant responsable d'une certaine fonction logique, par exemple, pour la présentation des données, la logique métier ou l'accès aux données. Un calque peut appeler d'autres calques ci-dessous. Cependant, une telle division en couches horizontales peut entraîner des difficultés supplémentaires. Par exemple, il peut être difficile d'apporter des modifications à une partie de l'application sans affecter ses autres éléments. Par conséquent, la mise à jour d'une telle application n'est souvent pas facile et les développeurs devront ajouter de nouvelles fonctionnalités moins souvent.
L'architecture à N niveaux est un choix naturel lors du transfert d'applications déjà utilisées construites sur la base d'une architecture à plusieurs niveaux. Par conséquent, cette architecture est le plus souvent utilisée dans des solutions IaaS (infrastructure as a service) ou dans des applications combinant IaaS avec des services managés.

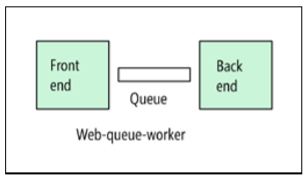
Interface Web - File d'attente - Rôle du travailleur
Pour les solutions PaaS, l'architecture de l'interface Web-file d'attente-travail-rôle convient. Avec cette architecture, l'application possède une interface Web qui traite les requêtes HTTP et un rôle de serveur qui est responsable des opérations qui prennent du temps ou qui demandent des ressources informatiques. Une file d'attente de messages asynchrone est utilisée pour communiquer entre l'interface et le rôle de travail du serveur.
L'architecture «interface web - file d'attente - rôle professionnel» convient aux tâches relativement simples qui nécessitent des ressources informatiques. Comme l'architecture N-tier, ce modèle est facile à comprendre. L'utilisation de services gérés simplifie le déploiement et le fonctionnement. Mais lors de la création d'applications pour des domaines complexes, il peut être difficile de contrôler les dépendances. L'interface Web et le rôle de travail peuvent facilement s'étendre à de gros composants monolithiques difficiles à maintenir et à mettre à jour. Comme avec l'architecture N-tier, ce modèle se caractérise par un taux de mise à jour inférieur et des opportunités d'amélioration limitées.
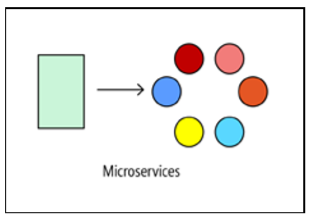
Microservices
Si l'application est conçue pour résoudre des problèmes plus complexes, essayez de l'implémenter sur la base d'une architecture de microservices. Une telle application se compose de nombreux petits services indépendants. Chaque service est responsable d'une fonction commerciale distincte. Les services sont faiblement couplés et utilisent des contrats API pour interagir.
Une petite équipe de développeurs peut travailler sur la création d'un service distinct. Les services peuvent être déployés sans coordination complexe entre les développeurs, ce qui facilite leur mise à jour régulière. L'architecture de microservice est plus difficile à mettre en œuvre et à gérer que les deux approches précédentes. Cela nécessite une culture de gestion du développement mature. Mais si tout est correctement organisé, cette approche permet d'augmenter la fréquence de sortie des nouvelles versions, d'accélérer la mise en œuvre des innovations et de rendre l'architecture plus tolérante aux pannes.
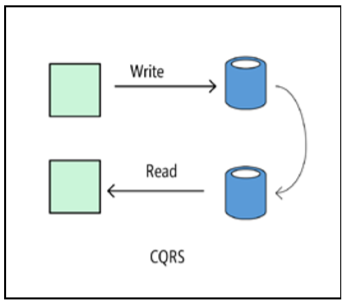
Cqrs
L'architecture de CQRS (Command and Query Responsibility Segregation, la répartition des responsabilités entre les équipes et les requêtes) vous permet de séparer les opérations de lecture et d'écriture entre les modèles individuels. Par conséquent, les parties du système chargées de modifier les données sont isolées des parties du système chargées de lire les données. De plus, les opérations de lecture peuvent être effectuées dans une vue matérialisée qui est physiquement distincte de la base de données dans laquelle écrire. Cela vous permet de mettre à l'échelle indépendamment les processus de lecture et d'écriture et d'optimiser la présentation matérialisée pour l'exécution des requêtes.
Le modèle CQRS est mieux utilisé pour un sous-système d'une plus grande architecture. En général, il ne doit pas être appliqué à l'ensemble de l'application, car cela complique inutilement son architecture. Il fonctionne bien dans les systèmes de collaboration, où un grand nombre d'utilisateurs travaillent simultanément avec les mêmes données.
Architecture basée sur les événements
Une architecture basée sur des événements utilise un modèle de publication-abonnement dans lequel les fournisseurs publient des événements et les consommateurs s'y abonnent. Les fournisseurs sont indépendants des consommateurs et les consommateurs sont indépendants les uns des autres.
Une architecture basée sur les événements est bien adaptée aux applications qui ont besoin de recevoir et de traiter rapidement de grandes quantités de données à faible latence, comme l'Internet des objets. De plus, une telle architecture fonctionne bien dans les cas où différents sous-systèmes doivent traiter différemment les mêmes données d'événement.

Big data, big computing
Les mégadonnées et l'informatique sont des options d'architecture spéciales utilisées pour résoudre des problèmes particuliers. Lorsque vous utilisez l'architecture Big Data, les grands ensembles de données sont divisés en fragments, qui sont ensuite traités en parallèle à des fins d'analyse et de génération de rapports. Le big computing est également appelé calcul haute performance (HPC). Cette technologie vous permet de répartir l'informatique entre plusieurs (milliers) de cœurs de processeur. Ces architectures peuvent être utilisées pour la simulation, le rendu 3D et d'autres tâches similaires.
Options d'architecture comme limitations
L'architecture agit comme une contrainte dans la conception d'une solution, en particulier, elle détermine quels éléments peuvent être utilisés et quelles connexions entre eux sont possibles. Les contraintes définissent la "forme" de l'architecture et vous permettent de faire un choix parmi un ensemble d'options plus restreint. Si les restrictions de l'architecture sélectionnée sont respectées, la solution aura des propriétés caractéristiques de cette architecture.
Par exemple, les microservices sont caractérisés par les restrictions suivantes:
- chaque service est responsable d'une fonction distincte;
- les services sont indépendants les uns des autres;
- Les données ne sont disponibles que pour le service qui en est responsable. Les services n'échangent pas de données.
Le respect de ces restrictions conduit à la création d'un système dans lequel les services peuvent être déployés indépendamment les uns des autres, les défauts sont isolés, des mises à jour fréquentes sont possibles et de nouvelles technologies sont facilement ajoutées à l'application.
Avant de choisir une architecture, assurez-vous de bien comprendre les principes sous-jacents et les limitations associées. Sinon, vous pouvez obtenir une solution qui correspond extérieurement au modèle d'architecture sélectionné, mais elle ne révèle pas pleinement le potentiel de ce modèle. Le bon sens est également important. Parfois, il est plus sage d’abandonner l’une ou l’autre restriction que de rechercher une architecture propre.
Le tableau suivant montre comment la gestion des dépendances est implémentée dans chacune de leurs architectures et pour quelles tâches telle ou telle architecture est la plus appropriée.

Analyse des avantages et des inconvénients
Les limitations créent des difficultés supplémentaires, il est donc important de comprendre ce que vous devez sacrifier lors du choix de l'une ou l'autre option d'architecture et de pouvoir répondre à la question de savoir si les avantages de l'option choisie l'emportent sur ses inconvénients pour une tâche spécifique dans un contexte spécifique.
Voici quelques-uns des inconvénients à considérer lors du choix d'une architecture:
- La complexité L'utilisation d'une architecture complexe est-elle justifiée pour votre tâche? Et vice versa, une architecture trop simple est-elle choisie pour une tâche complexe? Dans ce cas, vous risquez d'obtenir un système sans structure claire, car l'architecture utilisée ne vous permet pas de gérer correctement les dépendances.
- Messagerie asynchrone et finalement cohérence. La messagerie asynchrone permet de séparer les services et améliore la fiabilité (grâce à la possibilité de renvoyer des messages) et l'évolutivité. Cependant, cela crée certaines difficultés, comme la sémantique d'une seule transmission et le problème de cohérence à long terme.
- Interaction entre services. Si vous divisez l'application en services séparés, il y a un risque que l'échange de données entre les services prenne trop de temps ou conduise à une congestion du réseau (par exemple, lors de l'utilisation de microservices).
- Gérabilité. À quel point sera-t-il difficile de gérer l'application, de surveiller son travail, de déployer des mises à jour et d'effectuer d'autres tâches?
Architecture à N niveaux
Dans l'architecture à N niveaux, une application est divisée en couches logiques et couches physiques.
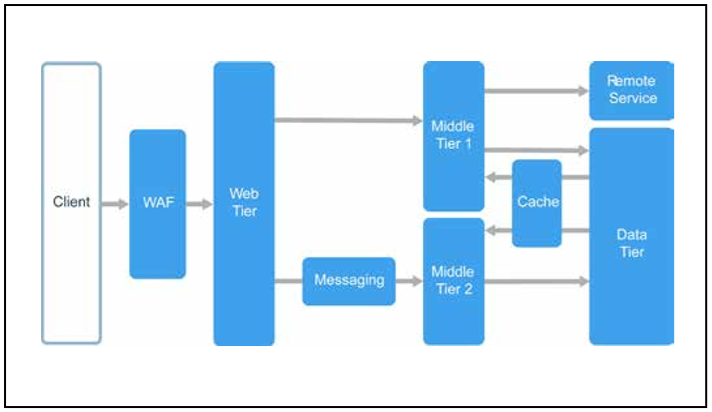
Les couches sont un mécanisme de partage des responsabilités et de gestion des dépendances. Chaque couche a son propre domaine de responsabilité. Les couches de niveau supérieur utilisent les services des couches de niveau inférieur, mais pas l'inverse.
Les niveaux sont physiquement séparés et fonctionnent sur différents ordinateurs. Un niveau peut accéder à l'autre directement ou à l'aide de messages asynchrones (files d'attente de messages). Bien que chaque couche doive être placée à son propre niveau, cela n'est pas nécessaire. Vous pouvez placer plusieurs couches sur un même niveau. La séparation physique des niveaux rend la solution non seulement plus évolutive et tolérante aux pannes, mais aussi plus lente, car le réseau est souvent utilisé pour l'interaction. Une application traditionnelle à trois niveaux se compose d'un niveau de présentation, d'un niveau intermédiaire et d'un niveau de base de données. Un niveau intermédiaire est facultatif. Les applications plus complexes peuvent comprendre plus de trois niveaux. Le diagramme ci-dessus montre une application avec deux niveaux intermédiaires responsables de divers domaines fonctionnels.
Une application à N niveaux peut avoir une architecture à couche fermée ou une architecture à couche ouverte.
- Dans une architecture fermée, une couche arbitraire ne peut accéder qu'à la couche inférieure la plus proche.
- Dans une architecture ouverte, une couche arbitraire peut faire référence à n'importe quelle couche inférieure.
L'architecture à couche fermée limite les dépendances entre les couches. Cependant, son utilisation peut augmenter excessivement le trafic réseau si une couche particulière transmet simplement les demandes à la couche suivante.
Applications d'architecture
L'architecture à N niveaux est généralement utilisée dans les applications IaaS, où chaque niveau s'exécute sur un ensemble distinct de machines virtuelles. Cependant, une application à N niveaux ne doit pas être une application IaaS pure. Il est souvent pratique d'utiliser des services gérés pour certains composants d'une solution, en particulier pour la mise en cache, la messagerie et le stockage de données.
L'architecture à N niveaux est recommandée pour une utilisation dans les cas suivants:
- applications Web simples;
- Portage d'une application locale sur Azure avec un refactoring minimal
- déploiement cohérent d'applications sur site et cloud.
L'architecture à N niveaux est courante parmi les applications locales ordinaires, elle est donc bien adaptée au portage des applications existantes vers Azure.
Les avantages
- La possibilité de transférer des applications entre le déploiement local et le cloud, ainsi qu'entre les plateformes cloud.
- Moins de formation pour la plupart des développeurs.
- Une extension naturelle du modèle d'application traditionnel.
- Prise en charge des environnements hétérogènes (Windows / Linux).
Inconvénients
- Il est facile d'obtenir une application dans laquelle le niveau intermédiaire effectue uniquement des opérations CRUD dans la base de données, augmentant le temps de traitement des demandes et n'apportant aucun avantage.
- L'architecture monolithique ne permettra pas le développement de composants individuels par des équipes de développement indépendantes.
- La gestion d'une application IaaS prend plus de temps qu'une application de service géré uniquement.
- Il peut être difficile de gérer la sécurité du réseau dans les grands systèmes.
Recommandations
- Utilisez la mise à l'échelle automatique à charge variable. Voir Meilleures pratiques pour la mise à l'échelle automatique.
- Utilisez la messagerie asynchrone pour séparer les niveaux les uns des autres.
- Cachez les données semi-statiques. Voir Considérations relatives à la mise en cache.
- Garantissez une haute disponibilité au niveau de la base de données avec une solution telle que Always On Availability Groups dans SQL Server.
- Installez un pare-feu d'application Web (WAF) entre l'interface et Internet.
- Placez chaque niveau dans votre propre sous-réseau; utiliser des sous-réseaux comme limites de sécurité.
- Limitez l'accès au niveau de données en autorisant uniquement les requêtes provenant des niveaux intermédiaires.
Architecture de machine virtuelle à N niveaux
Cette section fournit des instructions pour la construction d'une architecture à N niveaux à l'aide de machines virtuelles.

Cette section fournit des instructions pour la construction d'une architecture à N niveaux à l'aide de machines virtuelles. Chaque niveau se compose de deux ou plusieurs machines virtuelles hébergées dans un ensemble de disponibilité ou dans un ensemble évolutif de machines virtuelles. L'utilisation de plusieurs machines virtuelles offre une tolérance aux pannes en cas de panne de l'une d'entre elles. Pour répartir les demandes entre des machines virtuelles du même niveau, des sous-systèmes d'équilibrage de charge sont utilisés. Le niveau peut être mis à l'échelle horizontalement, en ajoutant de nouvelles machines virtuelles au pool.
Chaque niveau est également placé dans son propre sous-réseau. Cela signifie que leurs adresses IP internes sont dans la même plage. Cela facilite l'application des règles NSG (Network Security Group) et des tables de routage à des couches individuelles.
L'état du niveau Web et du niveau métier n'est pas surveillé. Toute machine virtuelle peut gérer toutes les demandes pour ces niveaux. La couche de données doit être constituée d'une base de données répliquée. Pour Windows, nous vous recommandons d'utiliser SQL Server avec des groupes de disponibilité Always On pour une haute disponibilité. Pour Linux, vous devez choisir une base de données qui prend en charge la réplication, comme Apache Cassandra.
L'accès à chaque niveau est limité par les groupes de sécurité réseau (NSG). Par exemple, l'accès au niveau base de données n'est autorisé que pour le niveau entreprise
Fonctionnalités supplémentaires
- L'architecture à N niveaux ne doit pas nécessairement comporter trois niveaux. Les applications plus complexes ont tendance à utiliser plus de niveaux. Dans ce cas, utilisez le routage via la couche 7 pour rediriger les demandes vers un niveau spécifique.
- Les niveaux limitent la décision concernant l'évolutivité, la fiabilité et la sécurité. Il est recommandé d'utiliser différents niveaux pour les services ayant des exigences différentes pour ces caractéristiques.
- Utilisez la mise à l'échelle automatique à l'aide d'ensembles évolutifs de machines virtuelles.
- Trouvez des éléments dans votre architecture que vous pouvez implémenter avec des services gérés sans refactorisation majeure. Faites particulièrement attention à la mise en cache, à la messagerie, au stockage et aux bases de données.
- Pour augmenter la sécurité, placez l'application derrière le réseau de périmètre. Le réseau de périmètre comprend des composants de réseau virtuel qui assurent la sécurité, tels que des pare-feu et des inspecteurs de paquets. Pour plus d'informations, voir Architecture de réseau de référence de périmètre.
- Pour une haute disponibilité, placez deux ou plusieurs composants de réseau virtuel dans l'ensemble de disponibilité et ajoutez un équilibreur de charge pour répartir les demandes Internet entre eux. Pour plus d'informations, voir Déploiement de composants de réseau virtuel pour une haute disponibilité.
- N'autorisez pas l'accès direct aux machines virtuelles exécutant le code d'application via les protocoles RDP et SSH. À la place, les opérateurs doivent entrer dans le nœud du bastion. Il s'agit d'une machine virtuelle située sur le réseau utilisée par les administrateurs pour se connecter à d'autres machines virtuelles. Sur l'hôte bastion, les règles NSG sont configurées pour autoriser l'accès via RDP et SSH uniquement à partir d'adresses IP publiques approuvées.
- Vous pouvez étendre le réseau virtuel Azure à un réseau local à l'aide d'un réseau à réseau de type réseau virtuel (VPN) ou Azure ExpressRoute. Pour plus d'informations, voir Architecture de référence de réseau hybride.
- Si votre organisation utilise Active Directory pour la gestion des identités, vous pouvez étendre votre environnement Active Directory au réseau virtuel Azure. Pour plus d'informations, voir Architecture de référence de gestion des identités.
- Si vous avez besoin d'un niveau de disponibilité supérieur à celui requis par l'accord de niveau de service de machine virtuelle Azure, répliquez l'application entre les deux régions et configurez Azure Traffic Manager pour le basculement. Pour plus d'informations, voir Démarrage de machines virtuelles Windows dans plusieurs régions et Démarrage de machines virtuelles Linux dans plusieurs régions.
Vous pouvez télécharger la version complète du livre gratuitement et l'étudier sur le lien ci-dessous.
→
Télécharger