Le temps presse et bientôt il ne restera presque plus rien de ce développement, mais je n'avais toujours pas le temps de le décrire.
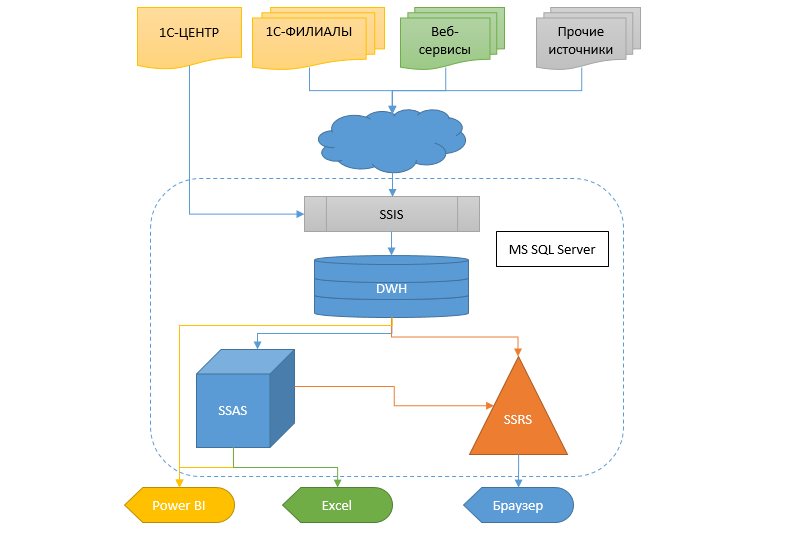
Il s'agira d'une entreprise au niveau fédéral avec un grand nombre de succursales et de sous-succursales. Mais, comme d'habitude, tout a commencé il y a longtemps avec un petit magasin. Au fil des ans, un développement assez rapide et spontané a eu lieu, des succursales, des divisions et d'autres bureaux sont apparus, et l'infrastructure informatique n'a pas reçu l'attention requise à cette époque, ce qui est également fréquent. Bien sûr, 1C77 a été utilisé partout, sans aucune marge de réplication et de mise à l'échelle.Par conséquent, vous savez, à la fin, nous sommes arrivés à la conclusion qu'une pieuvre Frankenstein a été générée avec des tentacules attachées avec du ruban électrique - dans chaque branche, il y avait un mutant autonome qui échangeait avec une base centrale dans le mode «à hauteur du genou», seulement quelques ouvrages de référence, sans lesquels, eh bien, c'était impossible du tout, et le reste est autonome. Pendant un certain temps, ils se sont contentés de copies (des dizaines d'entre eux!) Des bases de succursales du bureau central, mais les données en elles ont traîné pendant plusieurs jours.
La réalité, cependant, nécessite d'obtenir des informations plus rapidement et de manière flexible, et il faut faire autre chose avec cela. Le transfert d'un système comptable à un autre à une telle échelle reste un marécage. Par conséquent, il a été décidé de créer un entrepôt de données (DX), dans lequel les informations proviendraient de différentes bases de données, afin que d'autres services et le système analytique sous forme de cubes, de rapports SSRS et de fuites puissent recevoir des données de ce CD.
Pour l'avenir, je dirai que la transition vers un nouveau système comptable est presque terminée et que la plupart des projets décrits ici seront supprimés dans un proche avenir car inutiles. Désolé, bien sûr, mais rien ne peut être fait.
Ce qui suit est un long article, mais avant de commencer la lecture, permettez-moi de noter qu'en aucun cas je ne passe cette décision comme une norme, mais peut-être que quelqu'un y trouvera quelque chose d'utile.
Je vais commencer par une approche générale du projet, pour lequel SSDT a été choisi comme environnement de développement, avec la publication ultérieure du projet dans Git. Je pense qu'aujourd'hui, il existe suffisamment d'articles et de tutoriels qui décrivent les points forts de cet outil. Mais il y a quelques points dont le problème se situe en dehors de cet environnement.
Stockage des énumérations et des versions de base de données
En ce qui concerne les versions et les énumérations, les exigences du projet signifiaient:
- Commodité de modification et de suivi des modifications de la version de la base de données dans le projet
- Commodité de visualiser la version de la base de données via SSMS pour les administrateurs
- Sauvegarde de l'historique des changements de version dans la base de données elle-même (qui et quand le déploiement a été effectué)
- Stockage des énumérations dans un projet
- Facilité de modification et de suivi des modifications des transferts
- Verrou de déploiement de base de données au-dessus d'un existant s'il n'y avait pas de version incrémentielle
- L'installation d'une nouvelle version, l'enregistrement de l'historique, les transferts et la restructuration doivent être effectués en une seule transaction et complètement annulés en cas d'échec à n'importe quelle étape
Parce que les transferts contiennent souvent de la logique et sont des valeurs de base, sans lesquelles l'ajout d'enregistrements à d'autres tables devient impossible (en raison des clés étrangères FK), ils font essentiellement partie de la structure de la base de données, avec les métadonnées. Par conséquent, une modification d'un élément d'énumération entraîne un incrément de la version de la base de données et, avec cette version, les enregistrements doivent être garantis pour être mis à jour pendant le déploiement.
Je pense que tous les avantages de bloquer le déploiement sans incrémenter la version sont évidents, dont l'incapacité à réexécuter le script de publication s'il a déjà été exécuté avec succès plus tôt.
Bien que le réseau de base de données soit souvent proposé pour n'utiliser que la version principale (sans fractions), nous avons décidé d'utiliser des versions au format XY, où Y est le correctif lorsqu'une faute de frappe a été corrigée dans la description du tableau, de la colonne, du nom de l'élément de liste ou de quelque chose d'autre petit, comme l'ajout d'un commentaire à une procédure stockée, etc. Dans tous les autres cas, la version principale s'accumule.
Peut-être que pour quelqu'un il n'y a rien de
tel et tout est évident. Mais en temps voulu, j'ai pris beaucoup de nerfs et d'énergie sur les conflits internes sur la façon de stocker les transferts dans le projet de base de données, de sorte que ce soit du feng shui (
conformément à mon idée ) et qu'il était pratique de travailler avec eux, tout en minimisant la probabilité d'erreurs.
Avec les transferts, en général, tout est simple - nous créons un fichier PostDeploy dans le projet et y écrivons du code pour remplir les tables. Avec des fusions ou des trankates - c'est comme ça que vous l'aimez. Nous avons préféré clignoter, en vérifiant si le nombre d'enregistrements dans la table cible dépasse le nombre d'enregistrements qui se trouvent dans la source (projet). S'il dépasse, alors une exception est levée pour attirer l'attention dessus, car c'est étrange. Pourquoi y a-t-il moins d'enregistrements dans la source? Parce que l'on est superflu? Pourquoi tout d'un coup? Et si la base de données a déjà des liens vers elle? Bien que nous utilisions des clés étrangères (FK), qui ne vous permettront pas de supprimer l'enregistrement, s'il existe des liens vers celui-ci, nous préférons toujours laisser cette option. En conséquence, PostDeploy s'est transformé en une feuille illisible, car pour chaque table à remplir, en plus des valeurs elles-mêmes, il existe également un code de vérification, une fusion, etc.
Cependant, si vous utilisez PostDeploy en mode SQLCMD, il devient possible d'extraire des blocs de code dans des fichiers séparés.Par conséquent, il ne reste qu'une liste structurée de noms de fichiers pour remplir les énumérations dans PostDeploy.
Il existe certaines nuances avec les versions de base de données. Internet a longtemps débattu de l'endroit où stocker la version de la base de données, à quoi elle devrait ressembler et, en général, si elle doit être stockée quelque part? Supposons que nous décidions d'en avoir besoin, à quel endroit du projet le stocker? Quelque part dans le joker d'un script PostDeploy, ou le mettre dans une variable qui est déclarée dans la première ligne du script?
À mon avis, ni l'un ni l'autre. C'est plus pratique quand il est stocké dans un fichier séparé et qu'il n'y a plus rien.
Quelqu'un dira - il y a dacpac dans les propriétés du projet et vous pouvez y définir la version. Bien sûr, vous pouvez même extraire cette version dans votre script, comme décrit
ici , mais cela n'est pas pratique - pour changer la version de la base de données, vous devez aller quelque part loin, cliquer sur un tas de boutons. Je ne comprends pas la logique de Microsoft - ils l'ont caché dans un coin éloigné, avec des paramètres de base de données tels que le tri, le niveau de compatibilité, etc., parce que la version de la base de données change aussi "souvent" que les paramètres de tri, non? Lorsqu'il y a un développement constant, la version s'accumule à chaque nouveau déploiement, eh bien, la commodité du suivi des modifications joue également un rôle important, car lorsqu'un fichier modifié avec un nom convivial est allumé, c'est une chose, et lorsque le fichier de projet .sqlproj est allumé, dans lequel il y a de nombreuses lignes au format XML , et parmi eux quelque part au centre de la ligne, un chiffre modifié est mis en surbrillance, en quelque sorte pas très.
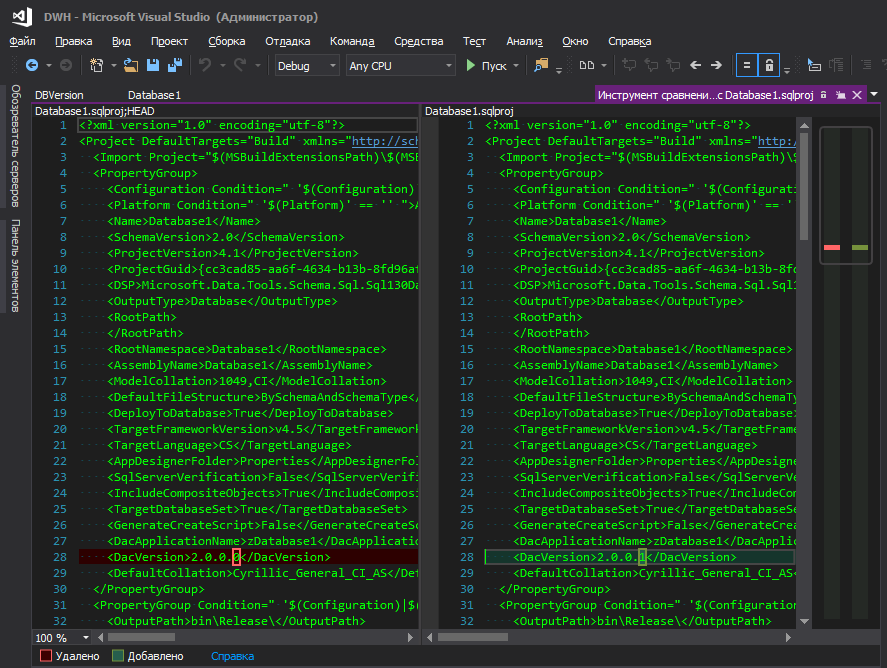
C'est mieux
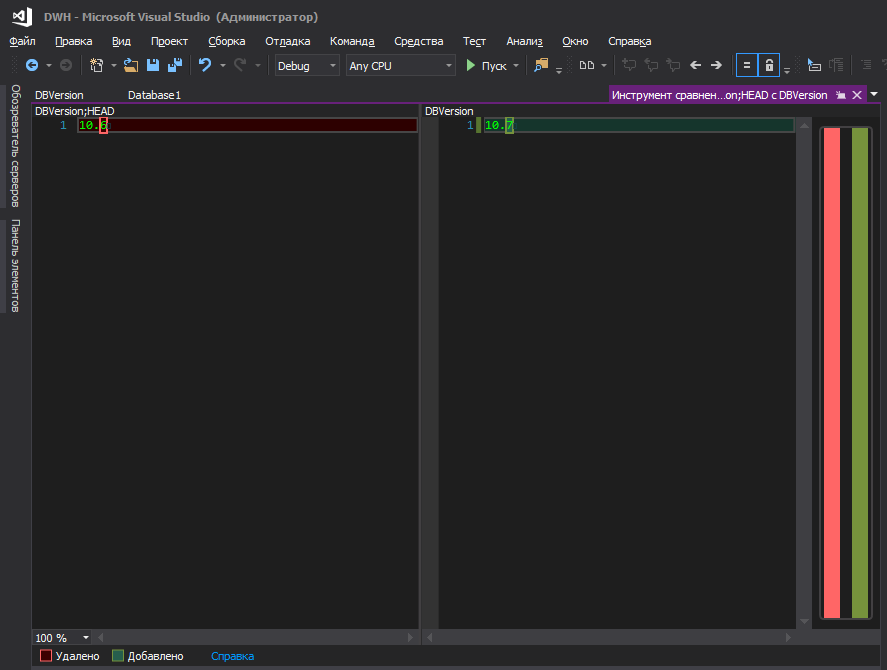
Cependant, ce ne sont peut-être que mes cafards et vous ne devriez pas y faire attention.
Maintenant, la question est: où stocker cette version déjà dans la base de données déployée. Encore une fois, il semble que dacpac le fasse magnifiquement - il écrit tout sur les plaques système, mais pour voir la version, vous devez exécuter la demande (ou peut-il en être autrement, mais je ne sais pas comment les cuisiner? Il semble que dans les anciennes versions de SSMS il y avait une interface pour cela, et maintenant non)
select * from msdb.dbo.sysdac_instances_internal
pour l'administrateur (et pas seulement) ce n'est pas très pratique. Il est beaucoup plus logique que la version soit affichée directement dans les propriétés de la base de données elle-même.

Ou pas?
Pour ce faire, vous devez ajouter un fichier au projet, inclus dans la build, décrivant les propriétés avancées
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
Oui, ils sont vides et ça a l'air moche dans un script de publication, mais vous ne pouvez pas vous en passer. S'ils ne sont pas décrits dans le projet et qu'ils seront dans la base de données, le studio essaiera de les supprimer à chaque déploiement. (Il y a eu de nombreuses tentatives pour contourner cela succinctement et sans options de déploiement inutiles, mais en vain)
Nous allons définir leurs valeurs dans le script PostDeploy.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty sans aucune vérification, car au moment où le bloc a été démarré à partir de PostDeploy, toutes les propriétés étaient déjà créées si elles n'étaient pas là.
Eh bien, ce serait bien de garder l'historique, au sujet de qui et quand déployait la base de données.
Le déploiement des modifications de métadonnées peut être effectué dans la transaction à l'aide d'outils standard en cochant la
case Activer les scripts de transaction dans la fenêtre
Options de publication avancées . Mais cet indicateur n'affecte pas les déploiements (pré / post) et ils continuent de s'exécuter sans transaction. Bien sûr, rien n'empêche la transaction de démarrer au début du script PostDeploy, mais ce sera une transaction distincte des métadonnées, et nous avons la tâche d'annuler les modifications de métadonnées si une exception s'est produite dans PostDeploy.
La solution est simple: démarrez la transaction dans PreDeploy, validez-la dans PostDeploy et n'utilisez aucune coche dans les paramètres de publication à ces fins.
Afin de stocker facilement la version de la base de données dans le projet et de l'enregistrer aux endroits souhaités pendant le déploiement, vous pouvez recourir aux variables SQLCMD. Cependant, je ne veux pas stocker la version quelque part dans le joker du code, je veux qu'elle soit à la surface.
Afin de placer la version de la base de données dans un fichier séparé et d'en gérer la version au niveau du projet, nous ajoutons le bloc suivant à .sqlproj:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
Il s'agit d'une instruction pour MSBuild de lire une ligne à partir d'un fichier avant de créer et de créer un fichier temporaire basé sur les données lues. MSBuild créera un fichier temporaire
SetPreDepVarsTmp.sql , qui
:setvar DBVersion $(ExtDBVersion) ligne
:setvar DBVersion $(ExtDBVersion) , où
$(ExtDBVersion) est la valeur lue dans notre fichier qui stocke la version de la base de données.
Après de telles manipulations, vous pouvez vous référer à ce fichier temporaire à partir du script PreDeploy et y démarrer la transaction globale:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
Version intermédiaireInitialement, le fichier ExtendedProperties.sql a reçu des valeurs non vides, mais des valeurs de variables
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
Les variables, à leur tour, ont été enregistrées dans le fichier SetPreDepVarsTmp.sql automatiquement par MSBuild comme ceci:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
Avec cette approche, vous n'avez pas besoin de réinstaller ces propriétés dans PostDeploy, mais le problème est que SetPreDepVarsTmp.sql contenait des valeurs statiques et si le script de publication a été généré maintenant, mais déployé après une heure, ou pire encore, le lendemain (le développeur l'a vérifié pendant longtemps) visuellement, par exemple), la date de publication spécifiée dans les propriétés sera différente de la date de publication réelle et ne coïncidera pas avec la date de l'historique.
Contenu du fichier BeginTransaction.sqlEn substance, il s'agit simplement d'un copier-coller à partir du bloc de démarrage de transaction standard que le studio génère lorsque la
case à cocher
Activer les scripts de transaction est
cochée , mais nous l'utilisons à notre manière. Dans le script, seul le nom de la table temporaire est passé de
#tmpErrors à
#tmpErrorsManual afin qu'il n'y ait pas de conflit de nom si quelqu'un active la case à cocher.
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
Script PostDeploy declare @TableName VarChar(255) = null
La variable SkipEnumDeploy, comme elle est déjà devenue claire, vous permet d'ignorer l'étape de mise à jour des listes; cela peut être utile pour des changements cosmétiques mineurs. Bien que, du point de vue de la religion, cela puisse ne pas être vrai, cela est certainement utile au stade du développement.
Les fichiers
CaptureTransactionError.sql et
CommitTransaction.sql CaptureTransactionError.sql également
CaptureTransactionError.sql -
CaptureTransactionError.sql (avec des modifications mineures) à partir de l'algorithme de transaction standard que le studio génère lorsque l'indicateur ci-dessus est défini, et que nous jouons maintenant par nous-mêmes.
Content CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
Contenu CommitTransaction.sql Contenu EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
Lors du déploiement de
Publish script aura la structure suivante
Idéalement, bien sûr, j'aimerais que la version soit affichée au moment de la publication

Mais vous ne pouvez pas extraire la valeur du fichier dans cette fenêtre, bien que MSBuild la lise et la place dans la propriété ExtDBVersion à l'aide d'instructions supplémentaires dans le fichier .sqlproj, comme dans l'exemple ci-dessus, mais la construction
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
ne roule pas.
Les développeurs de la suite dans leur
journal Web écrivent comment cela est fait. Selon leur version, la magie réside dans l'instruction
SqlCommandVariableOverride , qui est simple - ajoutez quelques lignes au fichier de projet .sqlproj
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
et c'est fait. Bien essayé, mais non. Peut-être que lorsque ce billet de blog a été publié, tout a fonctionné, mais depuis lors, dans ces États-Unis, vous avez eu trois élections présidentielles et personne ne sait quelles instructions pourraient cesser de fonctionner demain.

Et
ici, un camarade a essayé toutes les options, mais aucune n'a décollé.
Par conséquent, prenez la version de dacpac, ou stockez-la dans PostDeploy, ou dans un fichier séparé, ou _________ (entrez votre version).
Intégration avec 1C
Le premier problème était que 1C77 n'a pas de serveur d'application ou autre démon qui lui permet d'interagir avec lui sans lancer la plateforme. Ceux qui ont travaillé avec 1C77 savent qu'elle n'a pas de mode console complet. Vous pouvez exécuter la plate-forme avec des paramètres et même faire quelque chose en fonction d'eux, mais il y a très peu de paramètres de console et leur objectif était différent. Mais même avec leur aide, vous pouvez nakolkhozit une moissonneuse-batteuse entière. Cependant, il peut s'envoler de façon imprévisible, il peut faire apparaître une fenêtre modale et attendre que quelqu'un clique sur OK et d'autres charmes. Et, peut-être, le plus gros problème - la vitesse de la plate-forme laisse beaucoup à désirer ... Par conséquent, il n'y a qu'une seule solution - les requêtes directes vers la base de données 1C. Compte tenu de la structure, vous ne pouvez pas simplement prendre et écrire ces requêtes, mais l'avantage est qu'il y a toute une communauté qui a développé à un moment un merveilleux outil - 1C ++ (1cpp.dll), ce qui est incroyable pour eux MERCI! La bibliothèque vous permet d'écrire des requêtes en termes de 1C, qui se transforment alors en vrais noms de tables et de champs. Si quelqu'un ne le sait pas, alors la demande peut être écrite en utilisant un pseudo-nom et cela ressemblera à ceci
select from $.
Une telle demande est compréhensible pour les humains, mais il n'y a pas de telle table et champ sur le serveur, il existe d'autres noms, donc 1C ++ le transformera en
select SP5278 from SC2235
et une telle demande est déjà comprise par le serveur. Tout le monde est heureux, personne ne jure - ni une personne, ni un serveur. Ici, il semble que le problème soit résolu.
Le deuxième problème résidait dans le plan des configurations: une configuration était utilisée dans les succursales, une autre dans le bureau central et la troisième dans les succursales! Classe? !! 1 Je le pense aussi. De plus, ils ne sont pas un héritage typique ni même typique, mais entièrement écrits à partir de zéro pendant les Vikings et, malheureusement, ce ne sont pas les meilleurs architectes qui ont jeté les bases de ces configurations ... Le document d'implémentation, par exemple, a un ensemble de détails différent dans chaque configuration. Mais non seulement les noms de certains champs diffèrent, ce qui est beaucoup plus amusant lorsque les noms des détails sont les mêmes, mais la signification des données qui y sont stockées est DIFFÉRENTE.

Dans les configurations, presque aucun registre n'est utilisé, tout est construit sur les subtilités des documents. Par conséquent, parfois, je devais écrire une feuille entière sur une transaction propre, avec un tas de cas et de jointures, pour répéter la logique d'une procédure de la configuration, qui affiche des informations dans le champ de texte du formulaire.
Nous devons rendre hommage à l'équipe de développement, qui pendant toutes ces années a soutenu ce qu'elle a hérité des "implémenteurs", c'est un travail énorme - pour soutenir cela et même optimiser quelque chose. Jusqu'à ce que vous voyiez - vous ne comprenez pas, je ne croyais pas moi-même au début que tout pouvait être si compliqué. Demandez - pourquoi ne pas réécrire à partir de zéro? Manque banal de ressources. L'entreprise se développait si rapidement que, malgré une grande équipe de programmeurs, ils ne pouvaient tout simplement pas répondre aux besoins de l'entreprise, sans parler de la réécriture de l'ensemble du concept.
Nous continuons l'histoire des demandes. De toute évidence, tous les blocs d'extraction de données se sont transformés en stockages afin qu'ils puissent plus tard être lancés côté serveur en contournant la plate-forme 1C. La règle était la suivante: un stockage est responsable de la récupération d'une entité. Parce que La liste de souhaits au début a déjà beaucoup accumulé, car elle est devenue douloureuse au fil des ans, puis des dizaines de fichiers de stockage se sont révélés.
Le troisième problème est de savoir comment augmenter la vitesse et la qualité du développement, et comment alors supporter tout ce monstre? Ecrire une demande pour 1C ++ et copier-coller le résultat de sa conversion en stockage? C'est très gênant et fastidieux, en outre, il y a une forte probabilité d'erreurs - copiez la mauvaise ou la mauvaise ou ne sélectionnez pas la dernière ligne de la requête et copiez sans elle. Cela est particulièrement vrai lorsqu'il s'agit de diriger des requêtes 1C, car il n'y a pas de pseudo-nom comme
Directory. Nomenclature. Article, seuls les vrais noms
SC2235.SP5278 et donc de copier une demande depuis le répertoire des marchandises vers un magasin qui récupère les clients est très simple. Bien sûr, la demande tombera très probablement en raison de l'inadéquation des types et du nombre de champs dans la table de destination, mais il existe des plaques identiques, telles que les énumérations, où seules deux colonnes sont ID et Nom. En général, il ne reste plus qu'à appliquer une sorte d'automatisation. Eh bien, assez de paroles, passons aux choses sérieuses!
Je voulais que le processus de développement du stockage se résume à quelque chose comme ceci:
- Nous corrigeons la requête SQL avec des pseudo-noms et l'enregistrons
- Nous appuyons sur un bouton magique et à la sortie nous recevons la procédure stockée corrigée sur le SQL converti, claire pour le serveur
Quelques détails
Pour résoudre le troisième problème, un traitement externe (.ert) a été écrit. Il existe un certain nombre de procédures de traitement, chacune contenant le texte de la requête pour extraire une entité à l'aide d'un pseudo-nom, comme
select * from $.
Sur le formulaire de traitement, il y a un champ pour afficher le résultat d'une procédure particulière, c'est-à-dire demande convertie en un formulaire compréhensible par le serveur afin que vous puissiez l'essayer rapidement. De plus, un
bloc de débogage est toujours ajouté à cette demande, avec la déclaration des variables, les noms des bases de données de test, des serveurs, etc. Il ne reste plus qu'à copier-coller dans SSMS et appuyer sur F5. Vous pouvez, bien sûr, exécuter cette demande à partir du traitement lui-même, mais le plan de demande et tout cela, eh bien, vous comprenez ... En général, c'est ainsi que le débogage se fait. Parce que Il existe plusieurs configurations; lors du traitement, il est possible de convertir les mêmes textes de requête avec des pseudo-noms d'objets en requêtes finales pour différentes configurations. En effet, dans une confe, la référence de la nomenclature est SC123, et dans une autre - SC321. Mais 1C ++ vous permet de charger différentes configurations lors de l'exécution et de générer une sortie individuelle pour chacune d'entre elles conformément au dictionnaire.
Ensuite, le mode d'exécution par lots a été ajouté au traitement, lorsqu'il démarre automatiquement chacune des procédures pour chaque configuration, et la sortie de chacune d'entre elles est écrite dans des fichiers .sql (ci-après les fichiers de base). Ainsi, nous obtenons un tas de combinaisons de fichiers de base, qui devraient ensuite se transformer automatiquement en procédures stockées à l'aide de VS. Il est à noter que les fichiers de base incluent
un bloc de débogage .
Il semblerait, pourquoi ne pas conclure immédiatement les fichiers finaux des procédures stockées et tout garder dans ce traitement? Le fait est que pour certains tests, il est nécessaire d'exécuter des versions de débogage de requêtes par lots dans lesquelles toutes les variables sont déclarées, en plus je voulais que les noms de procédures stockées soient gérés à partir de VS, en contournant 1C, car c'est logique, n'est-ce pas?
Soit dit en passant, les fichiers de base sont également stockés dans le projet, eh bien, les fichiers des procédures stockées prêtes à l'emploi, bien sûr. À tout moment, sans démarrer 1C, vous pouvez ouvrir le fichier de base dans SSMS et l'exécuter sans vous soucier des déclarations de variables.
Lors du traitement, toutes les procédures avec demandes sont également des modèles, ayant le même ensemble de paramètres, mais dans telle ou telle procédure, seuls les paramètres nécessaires sont utilisés. Dans certains, tout est en jeu, et dans certains, deux suffisent. Par conséquent, l'ajout d'une nouvelle procédure revient à copier le modèle et à remplir les paramètres avec les requêtes elles-mêmes.
Le code de l'une des procédures de traitement, qui se transformera ensuite en procédure stockée
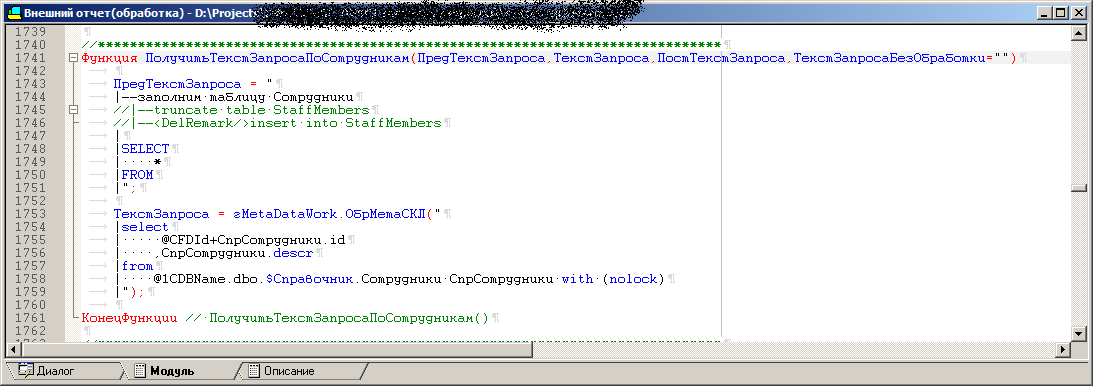
La requête finale va quelque chose comme ceci:
++"("+OPENQUERY()+")"+
Apparence du traitement

Lors du changement de configuration, la liste des éléments disponibles (nécessaires) pour décharger les éléments dans la liste des données change. Si possible, le code de procédure dans 1C était autant que possible unifié. Si des contreparties sont extraites et que ces répertoires sont incohérents dans différentes configurations, alors il y a différents cas à l'intérieur de la procédure de génération, tels que: ce bloc est fixé pour tout le monde, celui-ci n'est ajouté à la demande finale que pour un tel confon, et il y en a un pour l'autre. Il s'avère que dans les procédures stockées pour une entité mais dans des configurations différentes, elles peuvent différer non seulement par les noms de table, mais par des blocs entiers de jointures présents dans l'un et absents dans l'autre. L'ensemble des champs de sortie, bien sûr, est le même et correspond à la table réceptrice ou au conteneur du package SSIS, certains champs sont encombrés de stubs pour les configurations dans lesquelles ces détails ne sont pas en principe.
Bouton magiqueVisual Studio dispose d'outils tels que MSbuild et les impressionnants modèles T4. Par conséquent, en tant que bouton magique, un script a été écrit en C # pour T4, qui:
- Enregistre une configuration vide dans le registre (sinon 1C affichera une fenêtre modale avec une suggestion pour enregistrer une conf et attendre les actions de l'utilisateur)
- Crée une base de données vide pour ce konf sur le serveur SQL, car sans lui 1C donnera une erreur
- Lance 1C et via OLE lui dit d'exécuter le traitement (le même .ert), en transférant également un GUID unique à 1C
- La sortie est une série de fichiers avec des demandes prêtes à l'emploi (converties) et un fichier marqueur, dans lequel le GUID reçu au démarrage est écrit
- L'enregistrement de la conf est supprimé du registre et une base de données vide temporaire est supprimée du serveur
- Vérifie le contenu du fichier de jeton. Si le fichier marqueur contient le GUID que nous avons passé à 1C lors de son démarrage, cela signifie qu'il a fonctionné jusqu'à la fin, n'a pas planté, etc., puis passez à l'étape suivante, ou nous affichons une erreur
- Nous créons des stockages.
- Nous décompilons le fichier .ert avec gcomp pour obtenir les textes du module et les formulaires de traitement, enfin, nous les convertissons en Unicode, pour les envoyer ensuite à Git et les afficher correctement là-bas. Pour ceux qui n'ont pas travaillé avec 1C: le fichier .ert est un binaire et le studio, avec le git, souffle que le fichier .ert a été modifié, mais on ne sait pas exactement ce qui a changé, peut-être que quelqu'un a déplacé le bouton d'un pixel vers la gauche (ce qui inacceptable sans justification)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
. C'est fait.
?Parce que , , .sqlproj,
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
Sur
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
,
OPENQUERY , 1 , , , ,
EXEC .
OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
— . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
ETL
, ( ). (Stage). , ETL SSIS , , , , . . ( ), .
, ( ) , , (.. ), , .
, , . , . zabbix.
.
Parce que 1 , , . , ,
truncate .
, ( ) -, « 1-» .
SSIS
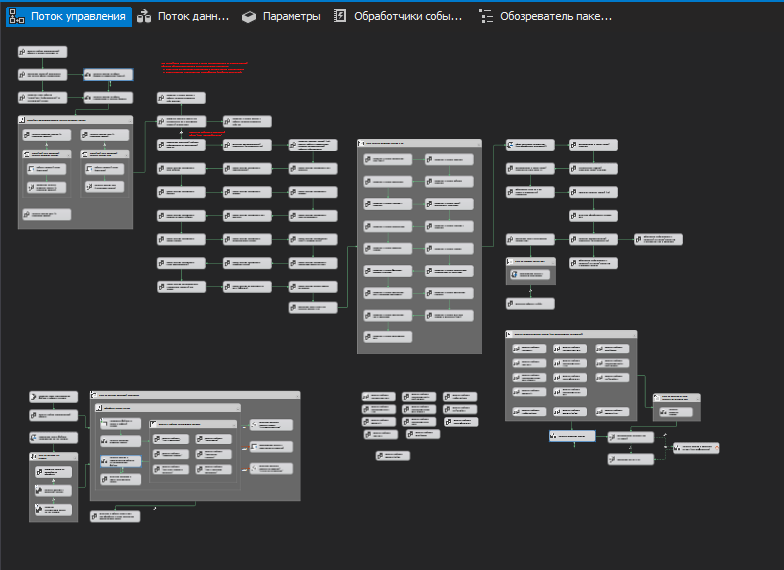
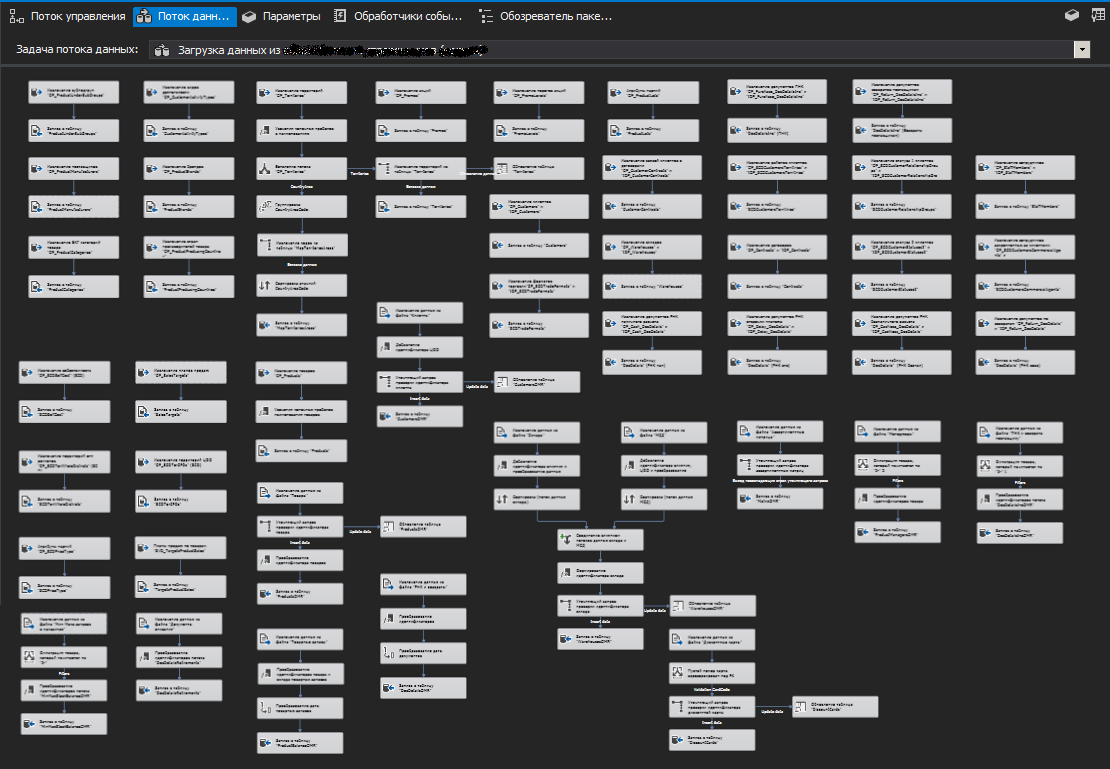
,
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). C'est-à-dire , . , , . - — . .
, (.. ) .
, , .
PS
, , , , . — , . - , , .