Cette note est une version écrite de mon rapport «Comment ruiner les performances en utilisant un code inefficace» de la conférence JPoint 2018. Vous pouvez regarder des vidéos et des diapositives sur la page de la conférence . Dans le calendrier, le rapport est marqué d'un verre offensif de smoothies, il n'y aura donc rien de super compliqué, c'est plus probable pour les débutants.
Objet du rapport:
- comment regarder le code pour y trouver des goulots d'étranglement
- antipatterns communs
- râteau non évident
- contournement du râteau
En marge, ils ont souligné quelques inexactitudes / omissions dans le rapport, elles sont notées ici. Les commentaires sont également les bienvenus.
Impact des performances sur les performances
Il existe une classe d'utilisateurs:
class User { String name; int age; }
Nous devons comparer les objets entre eux, nous déclarons donc les méthodes equals et hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
Le code est réalisable, la question est différente: les performances de ce code seront-elles les meilleures? Pour y répondre, rappelons les caractéristiques de la méthode Object::equals : elle ne renvoie un résultat positif que lorsque tous les champs comparés sont égaux, sinon le résultat sera négatif. En d'autres termes, une différence suffit déjà pour un résultat négatif.
Après avoir regardé le code généré pour @EqualsAndHashCode nous verrons quelque chose comme ceci:
public boolean equals(Object that) {
L'ordre de vérification des champs correspond à l'ordre de leur déclaration, ce qui dans notre cas n'est pas la meilleure solution, car comparer des objets en utilisant des equals «plus difficile» que de comparer des types simples.
Ok, essayons de créer des méthodes equals/hashCode utilisant l'Idea:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
Une idée crée un code plus intelligent qui connaît la complexité de comparer différents types de données. Eh bien, nous allons @EqualsAndHashCode et nous écrirons explicitement equals/hashCode . Voyons maintenant ce qui se passe lorsque la classe s'étend:
class User { List<T> props; String name; int age; }
Recréer equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
Les listes sont comparées avant de comparer les chaînes, ce qui n'a aucun sens lorsque les chaînes sont différentes. À première vue, il n'y a pas beaucoup de différence, car les chaînes de longueur égale sont comparées par des signes (c'est-à-dire que le temps de comparaison augmente avec la longueur de la chaîne):
Il y avait une inexactitudeLa méthode java.lang.String::equals est intrusive , il n'y a donc pas de comparaison de connexion à l'exécution.
Envisagez maintenant de comparer deux ArrayList (comme l'implémentation de liste la plus utilisée). En examinant ArrayList , nous sommes surpris de constater qu'il n'a pas sa propre implémentation d' equals , mais utilise une implémentation héritée:
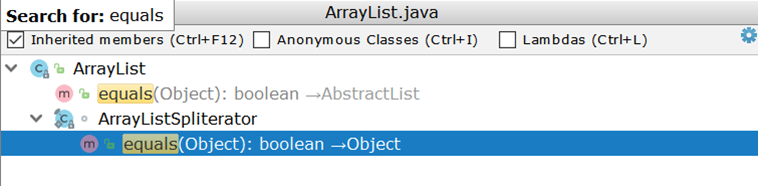
L'important ici est la création de deux itérateurs et le passage par paire à travers eux. Supposons qu'il existe deux ArrayList :
- en un numéro de 1 à 99
- dans le deuxième nombre de 1 à 100
Idéalement, il suffirait de comparer les tailles des deux listes et si elles ne coïncident pas, retournent immédiatement un résultat négatif (comme le fait AbstractSet ), en réalité, 99 comparaisons seront effectuées et seulement au centième il deviendra clair que les listes sont différentes.
Qu'y a-t-il avec les Kotlinites?
data class User(val name: String, val age: Int);
Ici, tout est comme un Lombok - l'ordre de comparaison correspond à l'ordre de l'annonce:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
Comme solution de contournement, vous pouvez organiser manuellement les déclarations de champ.
Compliquons la tâche
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
Le code implique l'accès à la base de données même lorsque le résultat de la vérification des conditions indiquées par la flèche est prévisible à l'avance. Si la valeur de la variable valid est fausse, le code dans le bloc if ne s'exécutera jamais, ce qui signifie que vous pouvez vous passer d'une demande:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
Note de la toucheLe naufrage peut être insignifiant lorsque l'entité renvoyée par JpaRepository::findOne déjà dans le cache du premier niveau - alors il n'y aura pas de demande.
Un exemple similaire sans branchement explicite:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
Un retour rapide vous permet de retarder la demande:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
Un ajout assez évident qui ne figurait pas dans le rapportImaginez qu'un certain chèque utilise une entité similaire:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
Si la vérification utilise la même entité, vous devez vous assurer que l'appel aux entités / collections enfants "paresseux" est effectué après l'appel aux champs déjà chargés. À première vue, une demande supplémentaire n'aura pas d'impact significatif sur l'image globale, mais tout peut changer lorsqu'une action est effectuée en boucle.
Conclusion: les chaînes d'actions / contrôles doivent être ordonnées par ordre croissant de complexité des opérations individuelles, peut-être que certaines d'entre elles n'auront pas à être réalisées.
Cycles et traitement en masse
L'exemple suivant n'a pas besoin d'explications spéciales:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
En raison de plusieurs requêtes de base de données, le code est lent.
RemarqueLes performances peuvent enrollStudents encore plus si la méthode enrollStudents exécutée en dehors d'une transaction: alors chaque appel à osdjrJpaRepository::findOne sera exécuté dans une nouvelle transaction (voir SimpleJpaRepository ), ce qui signifie recevoir et renvoyer une connexion à la base de données, ainsi que créer et vider le cache de premier niveau.
Correction:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
Nous mesurons le temps d'exécution (en microsecondes) pour une collection de clés (10 et 100 pièces) Benchmark
RemarqueSi vous utilisez Oracle et transmettez plus de 1 000 clés à findAll , vous obtiendrez l'exception ORA-01795: maximum number of expressions in a list is 1000 .
De plus, effectuer des requêtes lourdes (avec plusieurs clés) peut être pire que n requêtes. Tout dépend de l'application spécifique, de sorte que le remplacement mécanique du cycle par un traitement de masse peut dégrader les performances.
Un exemple plus complexe sur le même sujet
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
Dans ce cas, nous ne pouvons pas remplacer la boucle par JpaRepository::findAll , JpaRepository::findAll cela briserait la logique: toutes les valeurs obtenues à partir de JpaRepository::findAll ne seront pas null et le bloc if ne fonctionnera pas.
Le fait que pour chaque clé de base de données nous aidera à résoudre cette difficulté
renvoie la valeur réelle ou son absence. Autrement dit, dans un sens, une base de données est un dictionnaire. Java de la boîte nous donne une implémentation prête à l'emploi du dictionnaire - HashMap - sur lequel nous allons construire la logique de remplacement de la base de données:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
Exemple inverse
Ce code crée toujours une nouvelle transaction pour enregistrer une liste d'entités. Le fléchissement commence par plusieurs appels à une méthode qui ouvre une nouvelle transaction:
Solution: appliquez immédiatement la méthode Saver::save à l'ensemble des données:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
Beaucoup de transactions fusionnent en une seule, ce qui donne une augmentation tangible (temps en microsecondes): Benchmark
Un exemple avec plusieurs transactions est difficile à formaliser, ce qui ne peut pas être dit à propos de l'appel de JpaRepository::findOne dans une boucle.
L'approche est applicable non seulement à la base de données, alors Tagir lany Valeev est allé plus loin. Et si plus tôt nous écrivions comme ceci:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
et tout allait bien, maintenant "l'idée" suggère de se corriger:
List<Long> list = new ArrayList<>(); list.addAll(items);
Mais même cette option ne la satisfait pas toujours, car vous pouvez la rendre encore plus courte et plus rapide:
List<Long> list = new ArrayList<>(items);
Comparer (temps en ns)Pour ArrayList, cette amélioration donne une augmentation notable:
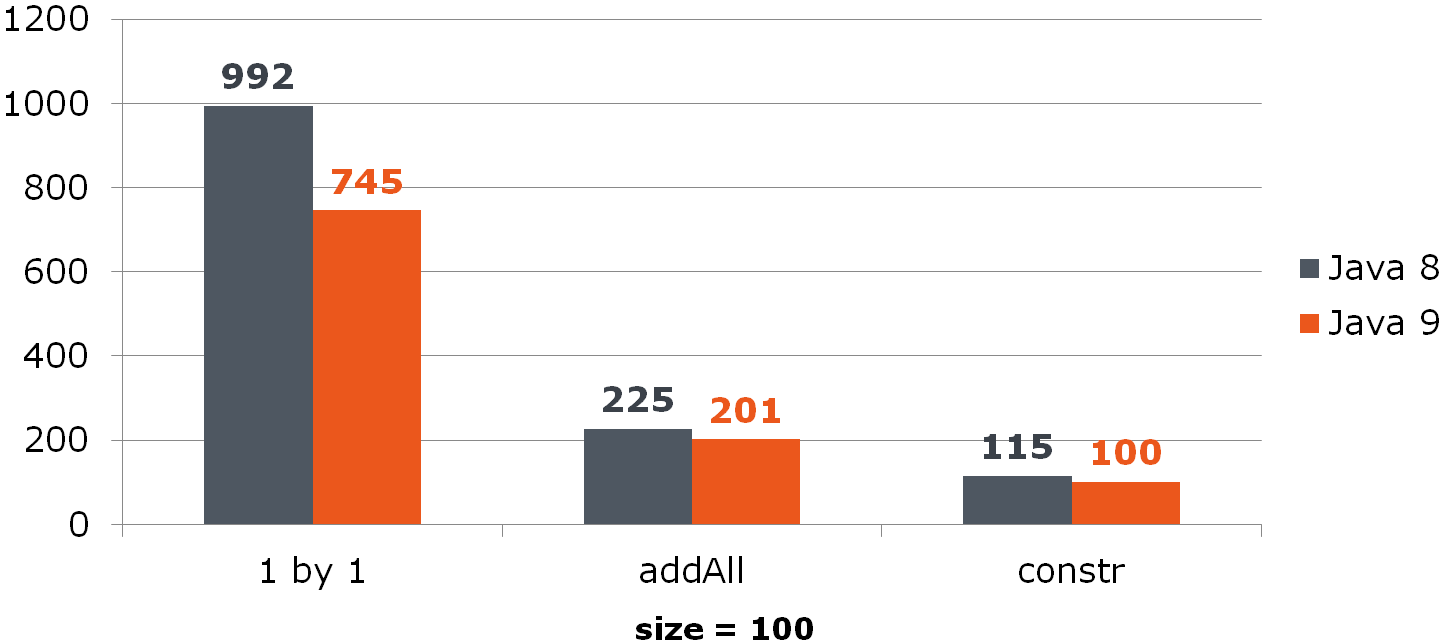
Pour HashSet, ce n'est pas si rose:

Benchmark
Suppression de ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
Le problème réside dans l'implémentation de la méthode List::remove :
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
Solution:
list.subList(from, to).clear();
Mais que faire si la valeur distante est utilisée dans le code source?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
Maintenant, vous devez d'abord parcourir la liste nettoyée:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
Si vous voulez vraiment supprimer dans le cycle, alors un changement dans la direction de passage dans la liste aidera à soulager la douleur. Son sens est de déplacer un plus petit nombre d'éléments après le nettoyage de la cellule:
Comparez les trois méthodes (sous les colonnes se trouvent% d'éléments supprimés d'une liste de taille 100):
Au fait, quelqu'un a-t-il remarqué l'anomalie?
A voir
Si nous supprimons la moitié de toutes les données se déplaçant depuis la fin, le dernier élément est toujours supprimé et il n'y a pas de décalage:
Benchmark
Conclusion: les opérations de masse sont souvent plus rapides que les opérations simples.
Portée et performances
Ce code n'a pas besoin d'explications particulières:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
Nous réduisons la portée, ce qui donne moins 1 requête:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
Et ici, le lecteur attentif devrait se demander: qu'en est-il de l'analyse statique? Pourquoi l’idée ne nous a-t-elle pas parlé de l’amélioration à la surface?
Le fait est que les possibilités d'analyse statique sont limitées: si la méthode est complexe (surtout en interaction avec la base de données) et affecte l'état général, alors le transfert de son exécution peut casser l'application. L'analyseur statique est capable de signaler des exécutions très simples, dont le transfert, disons, à l'intérieur du bloc ne cassera rien.
Vous pouvez utiliser la surbrillance variable comme ersatz, mais encore une fois, utilisez-la soigneusement, car les effets secondaires sont toujours possibles. Vous pouvez utiliser l'annotation @org.jetbrains.annotations.Contract(pure = true) , disponible dans la bibliothèque jetbrains-annotations pour indiquer les méthodes sans état :
Conclusion: le plus souvent, l'excès de travail ne fait qu'aggraver les performances.
Exemple le plus inhabituel
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
Cette implémentation ouvre une transaction même lorsque la transaction n'est pas nécessaire (retour rapide -1 de la méthode).
Il vous suffit de supprimer la transactionnalité à l'intérieur de la ContractCounter::countContracts , là où elle est nécessaire, et de la supprimer de la méthode "externe".
Comparez le temps d'exécution pour le cas où -1 (ns) est retourné: Comparez la consommation de mémoire (octets): Benchmark
Conclusion: les contrôleurs et les services "tournés vers l'extérieur" doivent être libérés de la transactionnalité (ce n'est pas leur responsabilité) et toute la logique de la vérification des données d'entrée, qui ne nécessite pas l'accès à la base de données et aux composants transactionnels, devrait y être supprimée.
Convertir la date / l'heure en chaîne
L'une des tâches éternelles consiste à transformer la date / l'heure en chaîne. Avant le G8, nous faisions ceci:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
Avec la sortie de JDK 8, nous avons obtenu LocalDate/LocalDateTime et, en conséquence, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
Mesurons ses performances:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
Question: disons que notre service reçoit des données de l'extérieur et que nous ne pouvons pas refuser java.util.Date . Serait-il avantageux pour nous de convertir Date en LocalDate si ce dernier est plus rapidement converti en chaîne? Calculez:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
Ainsi, la conversion Date -> LocalDate bénéfique lors de l'utilisation du "neuf". Au G8, les coûts de conversion engloutiront tous les avantages de DateTimeFormatter -a.
Benchmark
Conclusion: profitez de nouvelles solutions.
Un autre "huit"
Dans ce code, nous voyons une redondance évidente:
Iterator<Long> iterator = items
Nous le supprimons:
Iterator<Long> iterator = items
Voyons combien les performances se sont améliorées: Incroyable non? J'ai expliqué ci-dessus qu'un travail excessif dégrade les performances. Mais ici, nous supprimons l'excédent - et (soudainement) il empire. Pour comprendre ce qui se passe, prenez deux itérateurs et regardez-les sous une loupe:
Divulguer Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

Le premier itérateur est le ArrayList$Itr régulier.
Le passage à travers est simple: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
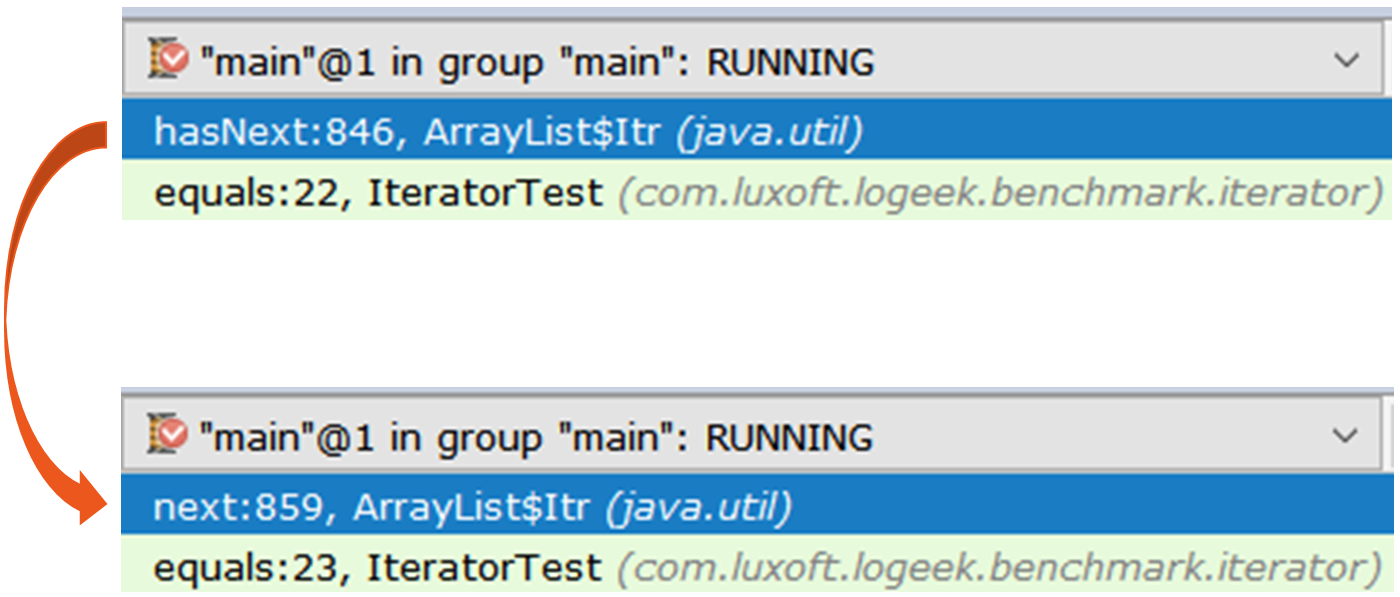
Le second est plus intéressant, il s'agit de Spliterators$Adapter , qui est basé sur ArrayList$ArrayListSpliterator .
Le traverser est plus difficile Regardons l'itération de l'itérateur via async-profiler :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
On peut voir que la plupart du temps est passé à travers l'itérateur, bien que dans l'ensemble, nous n'en ayons pas besoin, car la recherche peut se faire comme ceci:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Stream::forEach clairement un gagnant, mais c'est étrange: il est toujours basé sur ArrayListSpliterator , mais son utilisation s'est considérablement améliorée.
Voyons le profil: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
Dans ce profil, la plupart du temps est consacré à «avaler» les valeurs à l'intérieur du Blackhole . Par rapport à un itérateur, une partie beaucoup plus importante du temps est consacrée directement à l'exécution du code Java. On peut supposer que la raison est le poids spécifique inférieur de la collecte des ordures, par rapport à la force brute de l'itérateur. Vérifier:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
En effet, Stream::forEach fournit la moitié de la consommation de mémoire.
Pourquoi est-ce plus rapide?La chaîne d'appels du début au trou noir ressemble à ceci:
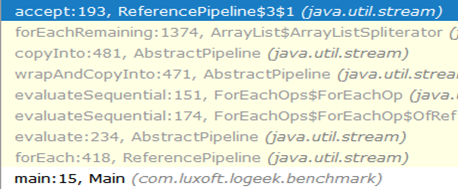
Comme vous pouvez le voir, l'appel à ArrayListSpliterator::tryAdvance disparu de la chaîne et ArrayListSpliterator::forEachRemaining est apparu à la ArrayListSpliterator::forEachRemaining :
ArrayListSpliterator::forEachRemaining grande vitesse ArrayListSpliterator::forEachRemaining obtenu en utilisant un passage à travers le tableau entier en 1 appel de méthode. Lorsque vous utilisez un itérateur, le passage est limité à un élément, nous nous ArrayListSpliterator::tryAdvance donc toujours sur ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining a accès à l'ensemble du tableau et ArrayListSpliterator::forEachRemaining dessus avec un cycle de comptage sans appels supplémentaires.
Avis importantVeuillez noter que le remplacement mécanique
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
sur
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Ce n'est pas toujours équivalent, car dans le premier cas, nous utilisons une copie des données pour le passage sans affecter le flux lui-même, et dans le second cas, les données sont directement extraites du flux.
Benchmark
Conclusion: lorsque vous traitez des représentations complexes de données, préparez-vous au fait que même les règles de «fer» (travail supplémentaire néfaste) cessent de fonctionner. L'exemple ci-dessus montre que la liste intermédiaire apparemment superflue donne l'avantage d'une implémentation plus rapide de l'énumération.
Deux astuces
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
La première chose qui attire votre attention est une "amélioration" pourrie, à savoir le passage d'un tableau de longueur non nulle à la méthode Collection::toArray . Il explique en détail pourquoi cela est nocif.
Le deuxième problème n'est pas aussi évident et, pour sa compréhension, nous pouvons établir un parallèle entre le travail du critique et de l'historien.
Voici ce que Robin Collingwood écrit à ce sujet: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→