À quelle fréquence entendez-vous la déclaration selon laquelle les règles de corrélation fournies par le fabricant
SIEM ne fonctionnent pas et sont supprimées ou désactivées immédiatement après l'installation du produit? Lors des événements de sécurité de l'information, toute section dédiée au SIEM traite ce problème d'une manière ou d'une autre.
Prenons une chance et essayons de trouver une solution au problème.
Le plus souvent, le principal problème est appelé le fait que les règles de corrélation du fabricant SIEM ne sont pas initialement adaptées à l'infrastructure particulière d'un client particulier.
En analysant les problèmes exprimés sur différents sites, on a l'impression que le problème n'a pas de solution. L'implémentation de SIEM devra encore affiner beaucoup ce que le fabricant offre, ou jeter toutes les règles et écrire les vôtres, tandis que ce problème est inhérent à toutes les solutions de n'importe quelle partie du quadrant Gartner.
Involontairement, vous vous demandez si tout est vraiment si mauvais et si ce nœud gordien ne peut pas être coupé? L'expression «règles de corrélation qui fonctionnent tout de suite» n'est-elle qu'un slogan marketing qui ne coûte rien?
Un article peut vous intéresser si:
- Vous travaillez déjà avec une sorte de solution SIEM.
- Je prévois simplement de le mettre en œuvre.
- Nous avons décidé de construire notre SIEM avec le blackjack et les corrélations basées sur la pile ELK, ou autre chose.
Sur quoi porteront les articles
Dans le cadre de cette série d'articles, nous énumérons les principaux problèmes qui entravent la mise en œuvre du concept de «règles de corrélation qui fonctionnent hors de la boîte», et essayons également de décrire une approche systématique pour les résoudre.
Je dois dire tout de suite que c’est cet article que les experts techniques peuvent qualifier de: «eau», «à propos de rien». Tout est ainsi, mais pas tout à fait. Avant d'aborder une tâche difficile, je veux d'abord savoir pourquoi elle est née et ce que nous apporte sa solution.
Pour une meilleure compréhension de l'ensemble des questions qui seront présentées, je donnerai la structure générale de toute la série d'articles:
- Article 1: Cet article. Parlons de l'énoncé du problème et essayons de comprendre pourquoi nous avons généralement besoin des règles "Règles de corrélation qui fonctionnent hors de la boîte." L'article sera de nature idéologique et, s'il devient complètement ennuyeux, vous pouvez le sauter. Mais je ne conseille pas de le faire, car dans les prochains articles, j'y ferai souvent référence. Ici, nous allons discuter des principaux problèmes qui se dressent sur notre chemin et des méthodes pour les résoudre.
- Article 2: Hourra! C'est là que nous arrivons aux premiers détails de l'approche proposée pour résoudre le problème. Décrivons comment notre système d'information sécurisé SIEM devrait «voir». Parlons de ce qui devrait être l'ensemble des champs nécessaires pour normaliser les événements.
- Article 3: Nous décrivons le rôle de la catégorisation des événements et comment la méthodologie de normalisation des événements est construite sur sa base. Nous montrons en quoi les événements informatiques diffèrent des événements SI et pourquoi ils devraient avoir des principes de catégorisation différents. Nous donnons des exemples en direct du travail de cette méthodologie.
- Article 4: Examinez de près les actifs qui composent notre système automatisé et voyez comment ils affectent la performance des règles. Nous veillerons à ce que ce ne soit pas aussi simple avec eux: ils doivent être identifiés et constamment mis à jour.
- Article 5: Ce pour quoi tout a commencé. Nous décrivons l'approche de l'écriture des règles de corrélation, basée sur tout ce qui a été énoncé dans les articles précédents.
Énoncé du problème et pourquoi il est important
Essayons de décrire, en termes simples, notre tâche: «Moi, en tant que client, qui ai acheté une solution SIEM, je m'abonne pour mettre à jour la base de règles et paie pour le support du fabricant (et parfois de l'intégrateur), je veux être rapidement informé des règles de corrélation qui ont été établies serait utile dans mon SIEM. " Quant à moi, donc tout à fait un bon souhait, pas de contraintes techniques architecturales ou structurelles.
Et maintenant, attention, supposons que nous avons déjà résolu tous les problèmes et que notre tâche est déjà terminée. Qu'est-ce que cela nous donne?
- Premièrement , nous économisons les coûts de main-d'œuvre de nos spécialistes. Désormais, ils n'ont plus à passer du temps à étudier la logique de chaque nouvelle règle et à l'adapter aux réalités d'un système automatisé particulier.
- Deuxièmement , nous économisons le budget depuis nous ne demandons pas à l'intégrateur ou à quelqu'un d'autre d'écrire ou d'adapter les règles pour nous moyennant des frais.
- Troisièmement , tous les acteurs importants du marché SIEM disposent d'unités et de départements de recherche qui se concentrent sur l'analyse des menaces à la sécurité de l'information. Il est important d'utiliser leur expérience, surtout si nous payons pour cela.
- Quatrièmement , nous raccourcissons notre réponse aux nouvelles menaces. Je n'écrirai pas sur l'éternité qui passe entre l'apparition d'une menace, le développement de règles de corrélation pour sa détection et sa mise en œuvre dans un produit spécifique pour un client particulier, de nombreux articles ont déjà été écrits sur ce sujet.
- Cinquièmement , cela nous rapproche tous de la possibilité de partager entre nous des règles unifiées qui fonctionneront pour tout client, dans le cadre d'une solution SIEM bien sûr.
De nombreux experts techniques qui ont trouvé une solution au problème et qui ont lu jusqu'à présent objecteront immédiatement: "Oui, bien sûr, il y a des avantages, mais ce n'est pas techniquement faisable." Personnellement, je pense que la tâche est assez «lourde» et maintenant, tant sur les marchés occidentaux que russes, il y a des SIEM qui contiennent tous les éléments nécessaires pour la résoudre. Je veux attirer votre attention sur ce point - les produits ne vous permettent pas de résoudre le problème, mais contiennent uniquement tous les blocs nécessaires à partir desquels, en tant que concepteur, vous pouvez assembler la solution que nous recherchons.
Je pense que c'est très important, car tout ce qui sera décrit plus loin peut être implémenté dans presque tous les SIEM existants et matures.
Assez des paroles, alors nous parlerons plus en détail des problèmes qui se posent pour résoudre notre problème.
Les défis auxquels nous sommes confrontés
À la recherche d'une solution au problème ci-dessus, voyons à quels problèmes nous devons faire face. La mise en évidence des principaux problèmes permettra une meilleure compréhension des problèmes et développera une approche systématique pour les résoudre.
Les problèmes auxquels nous sommes confrontés sont une boule de neige, chacun exacerbant considérablement la situation. Beaucoup de ces problèmes conduisent à la création de «règles de corrélation qui fonctionnent hors de la boîte» est extrêmement difficile.
En général, les problèmes sont répartis dans les quatre grands blocs suivants:
- Perte de données lors de la normalisation associée à la transformation des modèles du "monde".
- Absence de règles claires et universellement acceptées pour normaliser les événements.
- La "mutation" constante de l'objet de protection - notre système automatisé.
- Manque de règles pour écrire des règles de corrélation.
Examinons maintenant ces questions plus en détail.
Transformation du modèle mondial
Ce problème est plus facilement décrit en utilisant l'analogie suivante.
Le monde qui nous entoure est diversifié et multiforme, mais notre ouïe et notre vision ne fixent qu'un spectre limité de rayonnement. Ayant vu ou entendu une sorte de phénomène, nous construisons dans nos têtes l'image de cet événement, en utilisant déjà son modèle tronqué. Par exemple, notre œil ne voit pas dans le spectre infrarouge et l'oreille ne capte pas les vibrations inférieures à 16 Hz. Il s'agit de la première transformation du phénomène d'origine. Il arrive dans ce modèle que notre imagination apporte quelque chose qui n'était pas dans le phénomène d'origine. Nous pouvons parler de ce phénomène à l'interlocuteur en utilisant la parole orale avec toutes ses limites et caractéristiques. Il s'agit de la deuxième transformation du modèle. Enfin, l'interlocuteur, selon nos mots, décide d'écrire sur ce phénomène à son collègue du messager. Il s'agit de la troisième et, très probablement, de la transformation la plus spectaculaire du modèle en termes de perte d'informations.
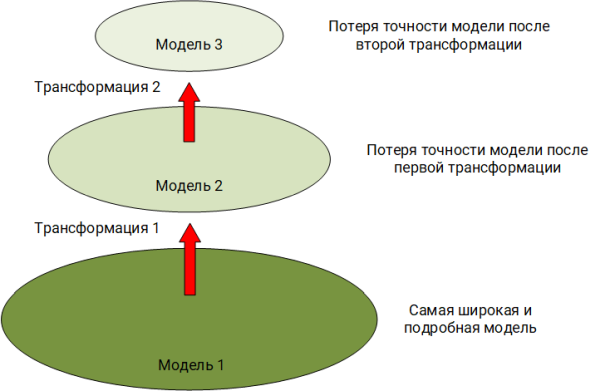
Dans l'exemple décrit ci-dessus, nous observons un problème classique, auquel le «modèle conceptuel» d'origine (
Sovetov B. Ya., Yakovlev S. A., System Modeling ) est transformé par simplification en un autre modèle tout en perdant en détail.
Exactement la même chose se produit dans le monde des événements générés par des logiciels ou du matériel.
Une explication peut servir ici est une telle image simplifiée déjà de notre domaine:
- La première transformation du modèle. Un fichier exécutable a été chargé dans la RAM, le système d'exploitation a commencé à exécuter les instructions qui y sont décrites. Le système d'exploitation transmet certaines informations sur cette opération au service démon / journalisation (auditd, journal des événements, etc.). Si vous n'activez pas un audit étendu des actions, certaines informations ne tombent pas dans ce démon. Mais même dans le cadre d'un audit approfondi, certaines informations seront toujours ignorées, car Les développeurs de systèmes d'exploitation ont décidé qu'un tel volume d'informations était suffisant pour comprendre ce qui se passait.
- La deuxième transformation du modèle. Et maintenant, le démon / service crée un événement, écrit des informations sur le disque, et ici nous comprenons que la longueur de la ligne d'événement peut être limitée par un certain nombre d'octets. Si le démon / service maintient un journal structuré, il contient alors un schéma de l'événement avec certains champs. Que faire s'il y a tellement d'informations qu'elles ne rentrent pas dans un schéma «câblé»? À juste titre, il est très probable que ces informations seront simplement jetées.
Maintenant, à quoi cela ressemble dans le cadre de notre tâche.
Nous avons déjà un modèle simplifié (ayant déjà perdu beaucoup de détails) d'un phénomène représenté par un enregistrement dans un fichier journal - un événement. SIEM lit cet événement, le normalise en répartissant les données entre les champs de son schéma. Le nombre de champs dans le schéma ne peut a priori pas les contenir autant qu'il est nécessaire pour couvrir toutes les sémantiques possibles de tous les événements de toutes les sources, c'est-à-dire qu'à cette étape le modèle est transformé et les données sont perdues.

Il est important de comprendre qu'en raison de ce problème, l'expert, en analysant les journaux dans SIEM ou en décrivant la règle de corrélation, ne voit pas l'événement initial lui-même, mais son modèle au moins deux fois déformé, qui a perdu beaucoup d'informations. Et, si les informations perdues sont extrêmement importantes dans l'enquête sur l'incident et, à la suite de la rédaction de la règle, elles devront être extraites de quelque part. Il est possible pour un expert de trouver les informations manquantes soit en se référant à la source d'origine (événement brut, vidage de mémoire, etc.) soit en modélisant les données manquantes dans sa tête sur la base de sa propre expérience, ce qui est pratiquement impossible à faire directement à partir de règles de corrélation.
Un bon indicateur de ce problème est, sinon étrange, des champs comme la chaîne de périphérique client, Datafield ou autre chose. Ces champs représentent une sorte de «vidage» où ils mettent des données qu'ils ne savent pas où mettre, ou quand tous les autres champs appropriés sont simplement inondés.
L'ensemble des champs de taxonomie, en règle générale, reflète le modèle du «monde» tel que le développeur SIEM voit le sujet. Si le modèle est très «étroit», alors il contient un petit nombre de champs et lors de la normalisation de certains événements, ils seront simplement manqués. SIEM avec un ensemble de champs initialement fixe et dynamiquement non extensible a souvent ce problème.
En revanche, s'il y a trop de champs, des problèmes surviennent en raison d'un manque de compréhension dans quel domaine vous devez mettre certaines données de l'événement d'origine. Cette situation entraîne la possibilité de l'apparition d'une duplication sémantique, lorsque sémantiquement les mêmes données de l'événement initial s'inscrivent immédiatement dans plusieurs champs. Cela est souvent observé dans les solutions où l'ensemble des champs de schéma peut être étendu dynamiquement par n'importe quel module de normalisation avec le support d'une nouvelle source.
Si vous avez un SIEM «combat» à portée de main, regardez vos événements. À quelle fréquence pendant la normalisation utilisez-vous des champs supplémentaires réservés (chaîne d'appareil personnalisée, champ de données, etc.)? De nombreux types d'événements avec des champs supplémentaires remplis indiquent que vous observez le premier problème. Rappelez-vous maintenant, ou demandez à vos collègues, à quelle fréquence avec le soutien d'une nouvelle source ont-ils dû ajouter un nouveau champ, car il n'y en avait pas assez réservé? La réponse à cette question est un indicateur du deuxième problème.
Méthodologie de normalisation des événements
Il est important de se rappeler qui et comment normalise les événements, car il joue un rôle important. Une partie des sources est prise en charge directement par le développeur des solutions SIEM, une partie est l'intégrateur qui a implémenté SIEM pour vous et une partie est la vôtre. C'est là que le prochain problème nous attend: chacun des participants interprète à sa manière le sens des champs du schéma d'événement et effectue donc la normalisation de différentes manières. Ainsi, différents participants peuvent décomposer des données sémantiquement identiques dans différents champs. Bien sûr, il existe un certain nombre de champs dont le nom ne permet pas une double interprétation. Supposons src_ip ou dst_ip, mais même avec eux, il y a des difficultés. Par exemple, dans les événements réseau, est-il nécessaire de changer src_ip en dst_ip lors de la normalisation des connexions entrantes et sortantes au sein de la même session?
Sur la base de ce qui précède, il est nécessaire de créer une méthodologie claire pour soutenir les sources, dans le cadre de laquelle il serait clairement indiqué:
- Quels sont les domaines du circuit pour ce qui est nécessaire.
- Quels types de données correspondent à quels champs.
- Quelles informations sont importantes pour nous dans le cadre de chaque type d'événement.
- Quelles sont les règles pour remplir les champs.
Le modèle de l'objet de protection et sa mutation
Dans le cadre de la solution de la tâche, l'objet de la protection est notre système automatisé (AS). Oui, c'est l'UA dans la définition de
GOST 34.003-90 , avec tous ses processus, personnes et technologies. C'est un point important, nous y reviendrons plus loin dans les articles suivants.
Le mot "mutation" n'est pas choisi ici par hasard. Rappelons qu'en mutation, la mutation s'entend comme des changements persistants dans le génome. Qu'est-ce que le génome AC? Dans le cadre de cette série d'articles, sous le génome AS, je comprendrai son architecture et sa structure. Et les «changements durables» ne sont que le résultat du travail quotidien des administrateurs système, des ingénieurs réseau, des ingénieurs sécurité des informations. Sous l'influence de ces changements, le CA passe d'un état à l'autre toutes les minutes. Certains États se caractérisent par un haut niveau de sécurité, d'autres moins. Mais maintenant, pour nous, cela n'a plus d'importance.
Il est important de comprendre que le modèle AC n'est pas statique, dont tous les paramètres sont décrits dans la documentation technique et de travail, mais un objet vivant, en constante mutation. Le SIEM, construisant en lui-même le modèle de l'objet de protection, doit en tenir compte et pouvoir le mettre à jour en temps opportun et de manière efficace, en suivant le rythme de mutation. Et, si nous voulons que les règles de corrélation «fonctionnent tout de suite», il faut qu'elles prennent en compte ces mutations et fonctionnent toujours avec l'image la plus pertinente du «monde».
Méthodologie d'élaboration des règles de corrélation
D'après la
«pyramide» présentée ci
- dessus
, il est clair que lors de l'élaboration des règles de corrélation, nous sommes obligés de lutter pour tous les problèmes qui se situent aux niveaux inférieurs. Pour résoudre ces problèmes, les règles sont dotées d'une logique supplémentaire: filtrage supplémentaire des événements, vérification des valeurs vides, conversion des types de données et transformation de ces données (par exemple, extraction d'un nom de domaine à partir du nom d'utilisateur de domaine complet), isolation des informations sur qui interagit avec qui et avec qui. cadre d'événement.
Après tout cela, les règles sont envahies par un tel nombre de slogans, de recherche de sous-chaînes et d'expressions régulières que la logique de leur travail ne devient claire que pour leurs auteurs et ensuite, jusqu'à leurs prochaines vacances. De plus, les changements constants du système automatisé - les mutations nécessitent une mise à jour régulière des règles contre la fraude. Une image familière?
En fin de compte
Dans le cadre de cette série d'articles, nous allons essayer de comprendre comment faire fonctionner les règles de corrélation hors de la boîte.
Pour résoudre le problème, nous devons faire face aux problèmes suivants:
- Perte de données lors de la transformation du modèle «monde» au stade de la normalisation.
- L'absence d'une définition claire d'une méthodologie de normalisation.
- Mutation permanente de l'objet de protection sous l'influence des personnes et des processus.
- Manque de méthodologie pour écrire des règles de corrélation.
Beaucoup de ces problèmes se situent dans le plan de la construction du schéma d'événement correct - un ensemble de champs et le processus de normalisation des événements - le fondement des règles de corrélation. Une autre partie des problèmes est résolue par des méthodes organisationnelles et méthodologiques. Si nous parvenons à trouver une solution à ces problèmes, le concept d'élaboration de règles prêtes à l'emploi aura un large effet positif et portera l'expertise des fabricants SIEM à un nouveau niveau.
Et ensuite? Dans le prochain article, nous essaierons de faire face à la perte de données lors de la transformation du modèle «monde» et réfléchirons à la façon dont l'ensemble des champs nécessaires à notre tâche devrait ressembler - un diagramme.
Série d'articles:Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 1: Marketing pur ou problème insoluble? (
Cet article )
Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 2. Le schéma de données comme reflet du modèle «monde»Profondeurs SIEM: corrélations prêtes à l'emploi. Partie 3.1. Catégorisation des événementsProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 3.2. Méthodologie de normalisation des événementsProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 4. Modèle de système comme contexte de règles de corrélationProfondeurs SIEM: corrélations prêtes à l'emploi. Partie 5. Méthodologie pour développer des règles de corrélation