 Nous avons récemment expliqué pourquoi nous avons créé notre propre segmenteur RFM, qui permet de faire une analyse RFM en 20 secondes , et a montré comment utiliser ses résultats dans le marketing.
Nous avons récemment expliqué pourquoi nous avons créé notre propre segmenteur RFM, qui permet de faire une analyse RFM en 20 secondes , et a montré comment utiliser ses résultats dans le marketing.
Maintenant, nous disons comment il est organisé.
Tâche: écrire un nouvel algorithme d'analyse RFM
Nous n'étions pas satisfaits des approches disponibles pour l'analyse RFM. Par conséquent, nous avons décidé de fabriquer notre propre segmenteur, qui:
- Cela fonctionne de manière complètement automatique.
- Construit de 3 à 15 segments.
- S'adapte à n'importe quel domaine d'activité du client (peu importe ce qu'il est: un magasin de fleurs ou d'outils électriques).
- Il détermine le nombre et l'emplacement des segments en fonction des données disponibles et non de paramètres prédéfinis qui ne peuvent pas être universels.
- Il sélectionne les segments afin qu'ils aient toujours des consommateurs (contrairement à certaines approches lorsque certains segments sont vides).
Comment résoudre le problème
Lorsque nous avons réalisé la tâche, nous avons réalisé qu'elle dépassait le pouvoir de l'homme et avons demandé l'aide de l'intelligence artificielle. Pour apprendre à la voiture à diviser les consommateurs en segments, nous avons décidé d'utiliser des méthodes de clustering .
Les méthodes de clustering sont utilisées pour rechercher une structure dans les données et sélectionner des groupes d'objets similaires en elles - exactement ce dont vous avez besoin pour l'analyse RFM.
Le regroupement fait référence aux méthodes d' apprentissage automatique de la classe « apprentissage sans professeur ». Une classe est appelée comme ça parce qu'il y a des données, mais personne ne sait quoi en faire, donc elle ne peut pas enseigner à une machine.
Nous n'avons pas pu trouver d'entreprises utilisant cette approche sur le marché. Bien qu'ils aient trouvé un article dans lequel l'auteur mène des recherches scientifiques sur ce sujet. Mais, comme nous l'avons compris par notre propre expérience, de la science aux affaires n'est pas du tout une étape.
Étape 1. Traitement des données
Les données doivent être préparées pour le clustering.
Tout d'abord, nous vérifions les valeurs incorrectes: valeurs négatives, etc.
Ensuite, nous éliminons les émissions - des consommateurs aux caractéristiques inhabituelles. Il y en a peu, mais ils peuvent grandement affecter le résultat, et pas pour le mieux. Pour les séparer, nous utilisons une méthode spéciale d'apprentissage automatique - Local Outlier Factor .

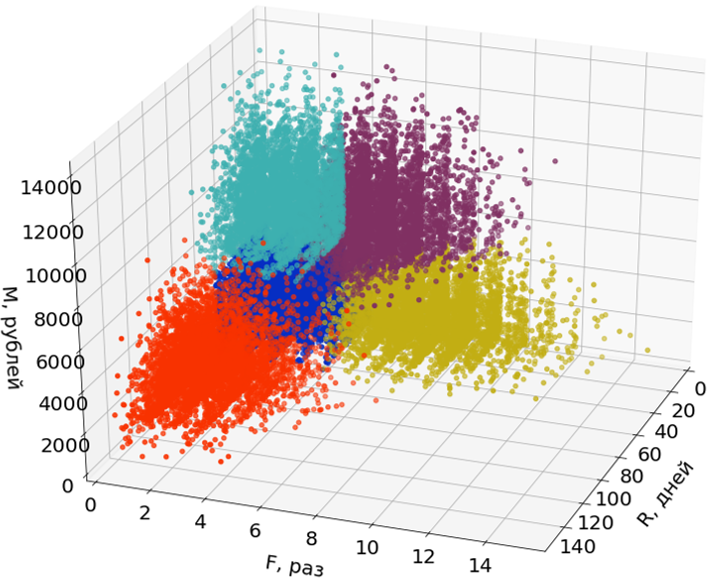
Ici, dans les images, j'utilise seulement deux des trois dimensions (R et M) de trois pour faciliter la perception.
Les émissions ne participent pas à la construction des segments, mais leur sont attribuées après la formation des segments.
Étape 2. Regroupement des consommateurs
Je vais clarifier la terminologie: par clusters, j'entends des groupes d'objets obtenus à la suite de l'utilisation d'algorithmes de clustering et des segments comme résultat final, c'est-à-dire le résultat d'une analyse RFM.
Il existe plusieurs dizaines d'algorithmes de clustering. Des exemples de certains d'entre eux peuvent être trouvés dans la documentation du paquet scikit-learn .
Nous avons essayé huit algorithmes avec diverses modifications. La plupart n'avaient pas assez de mémoire. Ou le temps de leur travail tendait vers l'infini. Presque tous les algorithmes qui ont réussi techniquement à faire face à la tâche ont donné des résultats terribles: par exemple, le populaire DBSCAN a considéré 55% des objets comme du bruit et a divisé le reste en 4302 grappes.
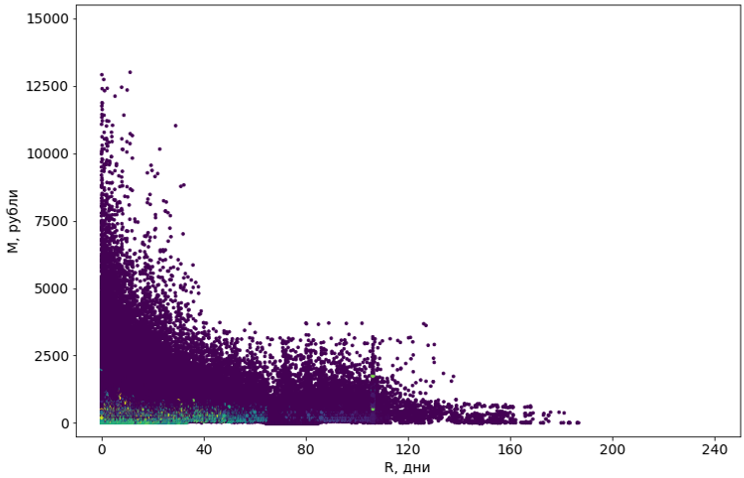
Les objets violets sont définis comme du «bruit»
En conséquence, nous avons choisi l'algorithme K-Means (K-means) car il ne recherche pas les groupes de points, mais regroupe simplement les points autour des centres. Il s'est avéré que c'était la bonne décision.
Mais d'abord, nous avons résolu quelques problèmes:
Instabilité. Il s'agit d'un problème connu avec la plupart des algorithmes de clustering, y compris K-Means. L'instabilité réside dans le fait qu'avec des lancements répétés, les résultats peuvent être différents, car un élément de hasard est utilisé.
Par conséquent, nous nous regroupons plusieurs fois, puis nous nous regroupons à nouveau, mais déjà au centre des grappes. En tant que centres finaux des clusters, nous prenons les centres des clusters résultants (c'est-à-dire les clusters formés par les centres des premiers clusters).
Le nombre de clusters. Les données peuvent être différentes et le nombre de clusters doit également être différent.
Pour trouver le nombre optimal de clusters pour chaque base de clients, nous effectuons un clustering avec un nombre différent de clusters, puis sélectionnons le meilleur résultat .
La vitesse. L'algorithme K-means n'est pas très rapide, mais acceptable (quelques minutes pour une base moyenne de plusieurs centaines de milliers de consommateurs). Cependant, nous l'exécutons plusieurs fois: d'une part, pour augmenter la stabilité, et d'autre part, pour sélectionner le nombre de clusters. Et le temps de fonctionnement augmente beaucoup.
Pour l'accélération, nous utilisons une modification du Mini Batch K-Means . Il recalcule les centres de cluster à chaque itération non pas pour tous les objets, mais uniquement pour un petit sous-échantillon. La qualité baisse un peu, mais le temps est considérablement réduit.
Dès que nous avons résolu ces problèmes, le clustering a commencé à se dérouler avec succès.
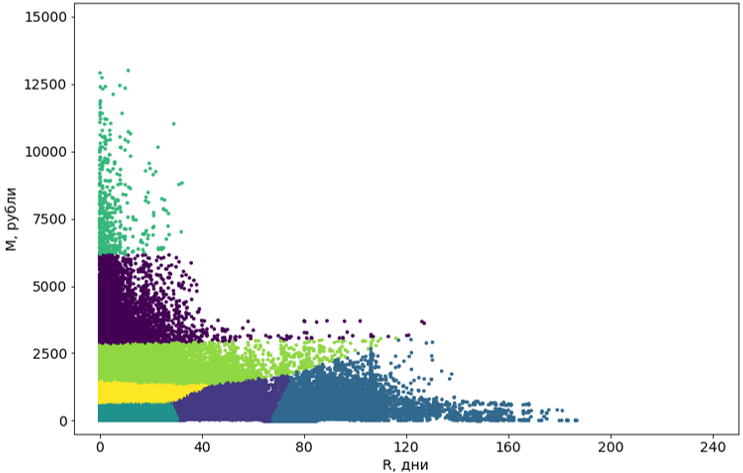
Étape 3. Post-traitement des clusters
Les grappes obtenues à l'aide de l'algorithme doivent être amenées sous une forme qui convient à la perception.
Tout d'abord, nous transformons ces grappes de courbes en rectangles. En fait, cela en fait des segments. La rectangularité des segments est une exigence de notre système et, en plus, ajoute de la compréhensibilité aux segments eux-mêmes. Pour convertir, nous utilisons un autre algorithme d'apprentissage automatique - l' arbre de décision .
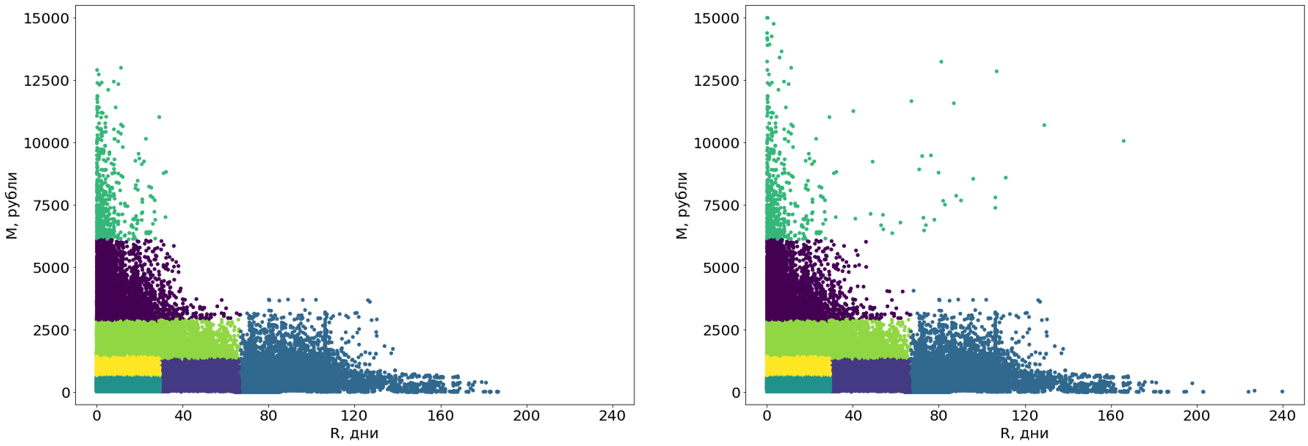
L'arbre de décision est construit sur des données sans valeurs aberrantes, et les valeurs aberrantes sont ensuite attribuées aux segments finis
Deuxièmement, nous avons fait une autre chose intéressante - la description des segments. Un algorithme spécial, utilisant un dictionnaire, décrit chaque segment en russe en direct, de sorte que les gens ne ressentent pas le désir de regarder des nombres sans âme.

Résultats des tests
Le produit est prêt. Mais avant de commencer à vendre, il doit être testé. Autrement dit, vérifiez si l'analyse RFM est effectuée comme prévu.
Nous savons que la meilleure façon de comprendre si nous avons fait quelque chose de valable est de découvrir l'utilité de l'analyse pour nos clients. Et nous le ferons. Mais c'est long, et les résultats seront plus tard, et nous voulons savoir comment nous avons réussi à faire face à la tâche, maintenant.
Par conséquent, en tant que mesure plus simple et plus rapide, nous avons utilisé la méthode du «groupe témoin historique».
Pour ce faire, nous avons pris plusieurs bases de données et les segmentées en utilisant l'analyse RFM à différents moments dans le passé: une base de données pour l'État il y a six mois, l'autre il y a un an, etc.
Sur la base de chaque segmentation pour chaque base, nous avons construit notre prévision des actions des clients du moment sélectionné au présent. Ils ont ensuite comparé ces prévisions avec le comportement réel des clients.

Exemple de test sur un groupe témoin historique avec une période de contrôle de six mois
Dans l'image:
- Les colonnes R, F et M indiquent classiquement les limites des segments le long de chaque axe. Ceci est le résultat d'une segmentation de base sous la forme dans laquelle elle était il y a six mois.
- La colonne "Taille" indique la taille du segment il y a six mois par rapport à la taille totale de la base de données.
- Les colonnes «Probabilité d'achat» et «Montant» sont des données sur le comportement réel des consommateurs au cours des six prochains mois.
- La probabilité d'achat est définie comme le rapport entre le nombre de consommateurs du segment ayant effectué un achat et le nombre total de consommateurs du segment.
- Montant - le montant total dépensé par les consommateurs du segment par rapport au montant dépensé par les consommateurs de tous les segments.
Les résultats sont cohérents. Par exemple, les clients des segments pour lesquels nous avions prédit une fréquence élevée d'achats achetaient en fait plus souvent.
Bien que nous ne puissions garantir le bon fonctionnement de l'algorithme à 100% sur la base de ces tests, nous avons décidé qu'il était réussi.
Que comprenons-nous
L'apprentissage automatique est vraiment capable d'aider une entreprise à résoudre des problèmes insolubles ou très mal résolus.
Mais le vrai défi n'est pas la compétition Kaggle. Ici, en plus d'obtenir une meilleure qualité dans une métrique donnée, vous devez réfléchir à la façon dont l'algorithme fonctionnera, s'il sera pratique pour les personnes et, en général, s'il est nécessaire de résoudre le problème en utilisant ML ou vous pouvez trouver un moyen plus simple.
Et enfin, l'absence d'une métrique formelle de qualité complique la tâche plusieurs fois, car il est difficile d'évaluer correctement le résultat.