Dans le monde de l'apprentissage automatique, l'un des types de modèles les plus populaires est l'arbre décisif et les ensembles qui en découlent. Les avantages des arbres sont: facilité d'interprétation, il n'y a pas de restrictions sur le type de dépendance initiale, des exigences souples sur la taille de l'échantillon. Les arbres ont également un défaut majeur - la tendance à se recycler. Par conséquent, presque toujours les arbres sont combinés en ensembles: forêt aléatoire, amplification de gradient, etc. Des tâches théoriques et pratiques complexes consistent à composer des arbres et à les combiner en ensembles.
Dans le même article, nous examinerons la procédure pour générer des prédictions à partir d'un modèle d'ensemble d'arbres déjà formé, les fonctionnalités d'implémentation dans les
XGBoost populaires de renforcement de gradient
XGBoost et
LightGBM . Et le lecteur se familiarisera également avec la bibliothèque de
leaves pour Go, qui vous permet de faire des prédictions pour les ensembles d'arbres sans utiliser l'API C des bibliothèques d'origine.
D'où poussent les arbres?
Considérons d'abord les dispositions générales. Ils travaillent généralement avec des arbres, où:
- la partition dans un nœud se produit selon une caractéristique
- arbre binaire - chaque nœud a un descendant gauche et droit
- dans le cas d'un attribut matériel, la règle de décision consiste à comparer la valeur de l'attribut avec une valeur seuil
J'ai pris cette illustration de la
documentation XGBoost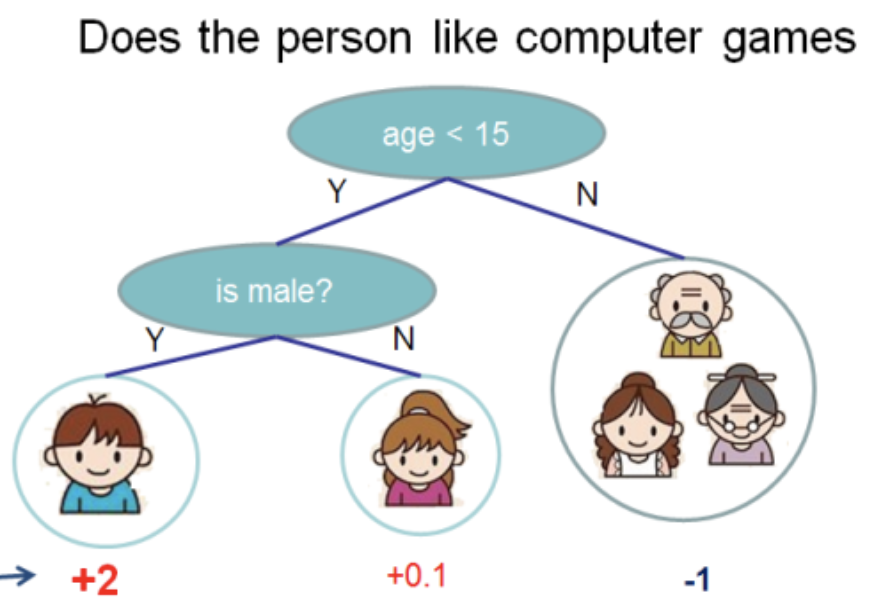
Dans cet arbre, nous avons 2 nœuds, 2 règles de décision et 3 feuilles. Sous les cercles, les valeurs sont indiquées - le résultat de l'application de l'arbre à un objet. Habituellement, une fonction de transformation est appliquée au résultat du calcul d'un arbre ou d'un ensemble d'arbres. Par exemple, un
sigmoïde pour un problème de classification binaire.
Pour obtenir des prédictions à partir de l'ensemble des arbres obtenus par boosting de gradient, vous devez ajouter les résultats des prédictions de tous les arbres:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
Ci-après, il y aura du
C++ , comme c'est dans cette langue que
XGBoost et
LightGBM sont écrits. Je vais omettre les détails non pertinents et essayer de donner le code le plus concis.
Ensuite, considérez ce qui est caché dans
Predict et comment la structure de données de l'arborescence est structurée.
XGBoost Trees
XGBoost a plusieurs classes (au sens de OOP) d'arbres. Nous parlerons de
RegTree (voir
include/xgboost/tree_model.h ), qui, selon la documentation, est le principal. Si vous ne laissez que les détails importants pour les prédictions, les membres de la classe semblent aussi simples que possible:
class RegTree {
La règle de
GetNext est implémentée dans la fonction
GetNext . Le code est légèrement modifié, sans affecter le résultat des calculs:
Deux choses découlent d'ici:
RegTree ne fonctionne qu'avec des attributs réels (type float )- les valeurs de caractéristique ignorées sont prises en charge
La pièce maîtresse est la classe
Node . Il contient la structure locale de l'arbre, la règle de décision et la valeur de la feuille:
class Node { public:
Les caractéristiques suivantes peuvent être distinguées:
- les feuilles sont représentées comme des nœuds pour lesquels
cleft_ = -1 - le champ
info_ représenté comme union , c'est- union -dire deux types de données (dans ce cas les mêmes) partagent un morceau de mémoire selon le type de nœud - le bit le plus significatif dans
sindex_ est responsable de l'endroit où l'objet dont la valeur d'attribut est ignorée
Afin de pouvoir tracer le chemin de l'appel de la méthode
RegTree::Predict à la réception de la réponse, je donnerai les deux fonctions manquantes:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
Dans la fonction
GetLeafIndex nous descendons les nœuds d'arbre dans une boucle jusqu'à ce que nous touchions la feuille.
Arbres LightGBM
LightGBM n'a pas de structure de données pour le nœud. Au lieu de cela, la structure de données de l'
Tree (
include/LightGBM/tree.h ) contient des tableaux de valeurs, où le numéro de nœud est utilisé comme index. Les valeurs des feuilles sont également stockées dans des tableaux séparés.
class Tree {
LightGBM prend en charge les fonctionnalités catégorielles. La prise en charge est fournie à l'aide d'un champ de bits, qui est stocké dans
cat_threshold_ pour tous les nœuds. Dans
cat_boundaries_ stocke à quel nœud quelle partie du champ de bits correspond. Le champ
threshold_ pour le cas catégorique est converti en
int et correspond à l'index dans
cat_boundaries_ pour rechercher le début du champ de bits.
Considérez la règle décisive pour un attribut catégoriel:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
On peut voir que, selon le type
missing_type valeur
NaN abaisse automatiquement la solution le long de la branche droite de l'arbre. Sinon,
NaN est remplacé par 0. La recherche d'une valeur dans un champ de bits est assez simple:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
c'est-à-dire, par exemple, pour l'attribut catégorique
int_fval=42 vérifié si le 41e bit (numérotation à partir de 0) est défini dans le tableau.
Cette approche présente un inconvénient important: si un attribut catégoriel peut prendre de grandes valeurs, par exemple 100500, alors pour chaque règle de décision pour cet attribut, un champ de bits sera créé jusqu'à 12564 octets!
Par conséquent, il est souhaitable de renuméroter les valeurs des attributs catégoriels afin qu'ils passent en continu de 0 à la valeur maximale .
Pour ma part, j'ai apporté des modifications explicatives à
LightGBM et les
LightGBM acceptées .
La gestion des attributs physiques n'est pas très différente de
XGBoost , et je vais ignorer cela par souci de concision.
leaves - bibliothèque de prévisions dans Go
XGBoost et
LightGBM des bibliothèques très puissantes pour construire des modèles de
LightGBM gradient sur des arbres de décision. Pour les utiliser dans un service backend, où des algorithmes d'apprentissage automatique sont nécessaires, il est nécessaire de résoudre les tâches suivantes:
- Formation périodique des modèles hors ligne
- Livraison de modèles dans le service backend
- Modèles de sondage en ligne
Pour écrire un service backend chargé,
Go est une langue populaire.
XGBoost ou
LightGBM via l'API C et cgo n'est pas la solution la plus simple - la construction du programme est compliquée, en raison d'une manipulation imprudente, vous pouvez attraper
SIGTERM , des problèmes avec le nombre de threads système (OpenMP dans les bibliothèques vs threads d'exécution).
J'ai donc décidé d'écrire une bibliothèque sur Pure
Go pour les prédictions en utilisant des modèles construits en
XGBoost ou
LightGBM . Cela s'appelle des
leaves .

Caractéristiques clés de la bibliothèque:
- Pour les modèles
LightGBM
- Lecture de modèles à partir d'un format standard (texte)
- Prise en charge des attributs physiques et catégoriels
- Prise en charge des valeurs manquantes
- Optimisation du travail avec des variables catégorielles
- Optimisation des prédictions avec des structures de données uniquement prédictives
- Pour les modèles
XGBoost
- Lecture de modèles à partir d'un format standard (binaire)
- Prise en charge des valeurs manquantes
- Optimisation des prédictions
Voici un programme
Go minimal qui charge un modèle à partir du disque et affiche une prédiction:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
L'API de la bibliothèque est minimale. Pour utiliser le modèle
XGBoost appelez simplement la méthode
leaves.XGEnsembleFromReader au lieu de celle ci-dessus. Les prédictions peuvent être effectuées par lots en appelant les
model.PredictCSR PredictDense ou
model.PredictCSR . Plus de scénarios d'utilisation peuvent être trouvés dans les
tests de feuilles .
Malgré le fait que
Go s'exécute plus lentement que
C++ (principalement en raison de l'exécution et des contrôles d'exécution plus lourds), grâce à un certain nombre d'optimisations, il a été possible d'atteindre une vitesse de prédiction comparable à l'appel de l'API C des bibliothèques d'origine.
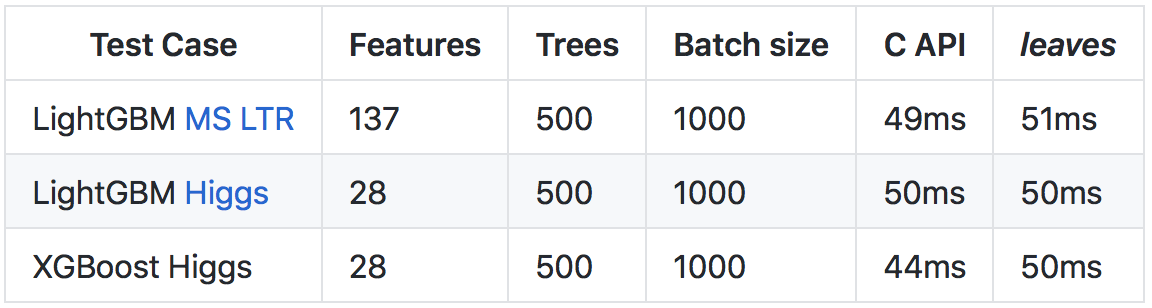
Plus de détails sur les résultats et la méthode des comparaisons sont dans le
référentiel sur github .
Voir la racine
J'espère que cet article ouvre la porte à l'implémentation d'arbres dans les
LightGBM XGBoost et
LightGBM . Comme vous pouvez le voir, les constructions de base sont assez simples, et j'encourage les lecteurs à profiter de l'open source - pour étudier le code quand il y a des questions sur son fonctionnement.
Pour ceux qui sont intéressés par le sujet de l'utilisation de modèles de renforcement de gradient dans leurs services dans la langue Go, je vous recommande de vous familiariser avec la bibliothèque de
feuilles . En utilisant des
leaves vous pouvez très facilement utiliser des solutions de pointe dans l'apprentissage automatique dans votre environnement de production, presque sans perte de vitesse par rapport aux implémentations C ++ originales.
Bonne chance!