 Traduction de l'article: Règles empiriques pour les expérimentateurs
Traduction de l'article: Règles empiriques pour les expérimentateursLes propriétaires de portails Web, du plus petit au plus grand, comme Amazon, Facebook, Google, LinkedIn, Microsoft et Yahoo, tentent d'améliorer leurs sites en optimisant diverses mesures, du nombre de réutilisation à leur temps et à leurs revenus. Nous avons été attirés par des milliers d'expériences sur Amazon, Booking.com, LinkedIn et Microsoft, et nous voulons partager les sept règles empiriques que nous avons déduites de ces expériences et de leurs résultats. Nous pensons que ces règles sont largement applicables à la fois lors de l'optimisation du Web et lors de l'analyse en dehors des expériences de contrôle. Bien qu'il y ait des exceptions.
Pour rendre ces règles plus significatives, nous donnerons de vrais exemples de nos travaux, dont la plupart seront publiés pour la première fois. Certaines règles ont été exprimées plus tôt (par exemple, «La vitesse est importante»), mais nous les avons complétées avec des hypothèses qui peuvent être utilisées dans la conception d'expériences, et partageons des exemples supplémentaires qui ont permis de mieux comprendre où la vitesse est particulièrement importante et dans quels domaines du Web. pages, il n'est pas critique.
Cet article a deux objectifs.
Premièrement : enseigner aux expérimentateurs les règles du bon goût, qui permettront d'optimiser les sites.
Deuxièmement : fournir à la communauté KDD de nouveaux sujets pour explorer l'applicabilité de ces règles, leur amélioration et l'existence d'exceptions.
Présentation
Les propriétaires de portails Web des plus petits aux plus grands géants tentent d'améliorer leurs sites. Les entreprises leaders utilisent des tests de benchmarking (tels que les tests A / B) pour évaluer les changements. Cela se fait par Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9] , Yahoo et Zynga [10].
Nous avons acquis une expérience dans l'optimisation de sites Web, en travaillant avec de nombreuses entreprises, notamment Amazon, Booking.com, LinkedIn et Microsoft. Par exemple, Bing et LinkedIn mènent à tout moment des centaines d'expériences parallèles [6; 11]. En raison de la variété et de la multiplicité des expériences auxquelles nous avons participé, des règles empiriques ont été développées, dont nous discuterons ici. Ils sont confirmés par de vrais projets, mais il y a des exceptions à toute règle (nous en parlerons également). Par exemple, la règle des 72 est un bon exemple d'une règle d'or utile dans le domaine financier. Il prétend que vous devez multiplier le pourcentage de croissance annuel par 72 pour déterminer approximativement combien d'années vous doublerez votre investissement. Dans des situations normales, la règle est très utile (lorsque le taux d'intérêt oscille entre 4 et 12%), mais dans d'autres domaines, elle ne fonctionne pas.
Étant donné que ces règles ont été formulées en fonction des résultats des expériences de contrôle, elles sont bien applicables pour l'optimisation du site et l'analyse simple, même si les expériences de contrôle ne sont pas effectuées sur les sites (bien que dans ce cas, il ne sera pas possible d'évaluer avec précision l'effet des modifications apportées).
Ce que vous trouverez dans cet article:
- Règles utiles pour expérimenter avec des sites Web. Ils sont encore en développement et nous devons en outre évaluer l'étendue de leur application et savoir s'il existe de nouvelles exceptions à ces règles. L'importance d'utiliser des expériences de contrôle a été discutée dans l'article «Expériences contrôlées en ligne à grande échelle» [11]
- Amélioration des règles précédentes. Des observations telles que «les questions de vitesse» ont déjà été exprimées par d'autres auteurs [12; 13] et nous [14]. Mais nous avons fait quelques hypothèses lors de la conception de l'expérience, et nous parlerons d'études qui démontrent que dans certaines zones de la page, la vitesse est particulièrement critique, et dans d'autres non. Nous avons également amélioré l'ancienne règle des «milliers d'utilisateurs», qui répond à la question du nombre de personnes nécessaires pour mener une expérience de contrôle.
- De vrais exemples d'expériences de contrôle sont publiés pour la première fois. Chez Amazon, Bing et LinkedIn, les expériences de contrôle sont utilisées dans le cadre du processus de développement [7; 11]. De nombreuses entreprises qui n'utilisent toujours pas d'expériences de contrôle peuvent grandement bénéficier d'exemples supplémentaires de travail avec des changements avec l'introduction de nouveaux paradigmes de développement [7, 15]. Les entreprises qui utilisent déjà des expériences de contrôle bénéficieront des informations décrites.
Contrôlez les expériences, les données et le processus d'extraction des connaissances à partir des données
Nous discuterons ici des expériences de contrôle en ligne dans lesquelles les utilisateurs sont divisés en groupes de manière aléatoire (par exemple, pour afficher diverses options de site). De plus, la division est effectuée sur une base continue, c'est-à-dire que chaque utilisateur aura la même expérience tout au long de l'expérience (il lui sera toujours montré la même version du site). L'interaction de l'utilisateur avec le site (clics, pages vues, etc.) est enregistrée et les mesures clés (CTR, nombre de sessions par utilisateur, revenus de l'utilisateur) sont calculées sur cette base. Des tests statistiques sont effectués pour analyser les mesures calculées. Et si la différence entre les métriques du groupe témoin (qui a vu l'ancienne version du site) et l'expérimental (qui a vu la nouvelle version) du groupe est statistiquement significative, alors nous pouvons également dire avec une forte probabilité que les modifications apportées affecteront les métriques observées dans l'expérience. Les détails sont décrits dans «Expériences contrôlées sur le Web: enquête et guide pratique» [16].
Nous avons participé à de nombreuses expériences dont les résultats étaient incorrects et avons consacré beaucoup de temps et d'efforts à comprendre les raisons et à trouver des moyens de les corriger. De nombreux pièges sont décrits dans les articles [17] and [18]. Nous voulons mettre en évidence certaines questions sur les données utilisées dans la conduite d'expériences de contrôle en ligne et sur le processus d'obtention de connaissances à partir de ces données:
- La source de données est les vrais sites dont nous avons parlé ci-dessus. Il n'y aura aucune information générée artificiellement. Tous les exemples sont basés sur une interaction réelle de l'utilisateur et les métriques sont calculées après la suppression des bots [16].
- Les groupes d'utilisateurs dans les exemples sont tirés au hasard de la distribution uniforme du public cible (c'est-à-dire les utilisateurs qui, par exemple, doivent cliquer sur le lien pour voir les changements à l'étude) [16]. La méthode d'identification de l'utilisateur dépend du site: si l'utilisateur n'est pas connecté, des cookies sont utilisés et s'il est connecté, alors son identifiant est utilisé.
- La taille des groupes d'utilisateurs, après avoir effacé les robots, varie de centaines de milliers à millions (les valeurs exactes sont indiquées dans les exemples). Dans la plupart des expériences, cela est nécessaire pour que les différences mineures de métriques aient une signification statistique élevée.
- Les résultats notés étaient statistiquement significatifs à une valeur de p <0,05, et généralement encore moins. Les résultats étonnants (dans la règle 1) ont été reproduits au moins une fois de plus, de sorte que la valeur p cumulative basée sur le test de probabilité cumulative de Fisher avait une valeur bien inférieure à ce qui était nécessaire.
- Chaque expérience est notre expérience personnelle, vérifiée par au moins un des auteurs pour la présence de pièges standards. Chaque expérience a été menée pendant au moins une semaine. Les parts d'audience qui ont démontré les options de site étaient stables pendant toute la période de l'expérience (afin d'éviter l'effet du paradoxe Simpson) et les ratios entre l'audience que nous avons observés au cours de l'expérience coïncidaient avec les ratios que nous avions fixés lors du lancement de l'expérience [17].
Règles d'or pour l'expérimentation
Les trois premières règles concernent l'impact des modifications sur les mesures clés:
- de petits changements peuvent avoir un impact important;
- le changement a rarement un grand effet positif;
- vos tentatives pour répéter les succès stellaires annoncés par d'autres sont plus susceptibles d'être moins réussies.
Les 4 règles suivantes sont indépendantes les unes des autres, mais chacune d'elles est très utile.
Règle n ° 1: de petits changements peuvent avoir un GRAND impact sur les mesures clés
Quiconque a rencontré la vie de sites sait que tout petit changement peut avoir un impact négatif important sur les mesures clés. Une petite erreur JavaScript peut rendre le paiement impossible, et de petits bugs qui détruisent la pile peuvent provoquer le crash du serveur. Mais nous nous concentrerons sur les changements positifs dans les mesures clés. La bonne nouvelle est qu'il existe de nombreux exemples où un petit changement a conduit à une amélioration des paramètres clés. Bryan Eisenberg a écrit que la suppression du champ de saisie du coupon sur le formulaire d'achat augmentait la conversion de 1000% sur le site Web de Doctor Footcare [20]. Jared Spool a écrit que la suppression de l'obligation de s'inscrire au moment de l'achat rapportait 300 millions de dollars par an à un grand détaillant [21].
Néanmoins, nous n'avons pas vu de changements aussi importants dans le processus d'expériences menées personnellement. Mais nous avons vu des améliorations significatives de petits changements avec un retour sur investissement étonnamment élevé (ratio élevé de profit sur le coût de l'effort investi).
Nous voulons également noter que nous discutons d'un effet stabilisé, pas d'un «flash sur le soleil» ou d'une fonctionnalité avec un effet spécial de nouvelles / viral. Un exemple de quelque chose que nous ne recherchons pas a été décrit dans le livre Yes!: 50 façons scientifiquement prouvées d'être persuasives [22]. Collen Szot, l'auteur d'une émission de télévision qui a battu un record de vente de 20 ans sur la chaîne de télévision Couch Store, a remplacé trois mots dans une barre d'information standard, entraînant une énorme augmentation du nombre d'achats. Au lieu de la phrase «Les opérateurs attendent, veuillez appeler maintenant», a déduit Collen «si les opérateurs sont occupés, veuillez rappeler à nouveau». Les auteurs expliquent cela par les preuves sociologiques suivantes: les téléspectateurs pensent que si la ligne est occupée, les gens comme eux qui regardent la chaîne d'information appellent également.
Si des astuces comme celle mentionnée ci-dessus sont utilisées régulièrement, leur effet est nivelé, car les utilisateurs s'y habituent. Dans les expériences de contrôle dans de tels cas, l'effet disparaît rapidement. Par conséquent, nous vous recommandons de mener une expérience pendant au moins deux semaines et de surveiller la dynamique. Bien que dans la pratique, de telles choses soient rares [11; 18]. Les situations dans lesquelles nous avons observé un effet positif de l'impact de ces changements étaient associées aux systèmes de recommandation lorsque le changement en soi donne un effet à court terme ou lorsque les ressources finales sont utilisées pour le traitement.
Par exemple, lorsque LinkedIn a modifié l'algorithme de fonctionnalité «Personnes que vous connaissez peut-être», il n'a généré qu'une augmentation ponctuelle des mesures de clic. De plus, même si l'algorithme fonctionnait beaucoup mieux, alors chaque utilisateur connaît un nombre fini de personnes, et après avoir contacté ses principales connaissances, l'effet de tout nouvel algorithme diminuera.
Exemple: ouverture de liens dans un nouvel onglet. Une série de trois expériences
En août 2008, MSN UK a mené une expérience pour plus de 900 000 utilisateurs, dans laquelle le lien vers HotMail s'est ouvert dans un nouvel onglet (ou une nouvelle fenêtre sur des navigateurs plus anciens). Nous avions précédemment rapporté [7] que ce changement minimal (une ligne de code) avait entraîné une augmentation de l'implication des utilisateurs MSN. L'engagement, mesuré en nombre de clics par utilisateur sur la page d'accueil, a augmenté de 8,9% parmi les utilisateurs qui ont cliqué sur HotMail.
En juin 2010, nous avons reproduit l'expérience sur un public de 2,7 millions d'utilisateurs MSN aux États-Unis, et les résultats étaient similaires. En fait, c'est aussi un exemple de fonctionnalité avec effet de nouveauté. Le premier jour de son déploiement auprès de tous les utilisateurs, 20% des avis étaient négatifs. Au cours de la deuxième semaine, la part des insatisfaits est tombée à 4%, et au cours des troisième et quatrième semaines - à 2%. L'amélioration des paramètres clés est restée stable tout au long de cette période.
En avril 2011, MSN aux États-Unis a mené une très grande expérience avec plus de 12 millions d'utilisateurs qui ont ouvert une page avec les résultats de la recherche dans un nouvel onglet. L'engagement, mesuré en clics sur l'utilisateur, a augmenté de 5%. C'était l'une des meilleures fonctionnalités liées à l'engagement des utilisateurs que MSN ait jamais implémentée, et c'était un changement trivial dans le code.
Tous les principaux moteurs de recherche expérimentent l'ouverture de liens dans de nouveaux onglets / fenêtres, mais les résultats de la «page de résultats de recherche» ne sont pas aussi impressionnants.
Exemple: couleur de police
En 2013, Bing a mené une série d'expériences avec les couleurs de police. L'option gagnante est illustrée à la figure 1 à droite. Voici comment les trois couleurs ont été modifiées:
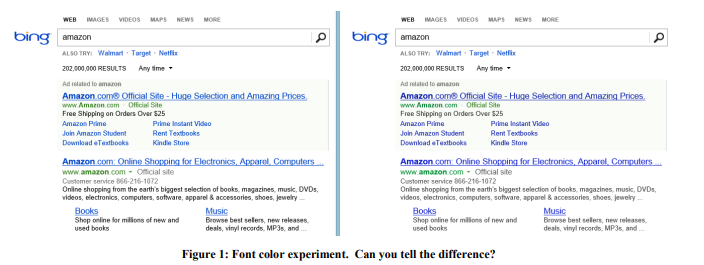
Le coût d'un tel changement? Pas cher: remplacez simplement plusieurs couleurs dans le fichier CSS. Et le résultat de l'expérience a montré que les utilisateurs atteignent leurs objectifs (une définition stricte du succès est un secret commercial) plus rapidement, et la monétisation de cette révision a augmenté de plus de 10 millions de dollars par an. Nous étions sceptiques quant à ces résultats étonnants, nous avons donc reproduit cette expérience sur un échantillon beaucoup plus important de 32 millions d'utilisateurs, et les résultats ont été confirmés.

Exemple: la bonne offre au bon moment
En 2004, la page de démarrage d'Amazon contenait deux emplacements, dont le contenu a été testé automatiquement, de sorte que le contenu qui améliore le mieux la mesure cible s'affiche plus souvent. L'offre d'obtenir une carte de crédit Amazon a atteint la première place, ce qui était surprenant car cette offre a généré très peu de clics par impression. Mais le fait est que cette application était très rentable, donc, malgré le petit CTR, la valeur attendue était très élevée. Mais juste si le lieu d'une telle annonce a été choisi avec succès? Non! En conséquence, la proposition, accompagnée d'un exemple simple de l'avantage, a été déplacée dans le panier que l'utilisateur voit après l'ajout du produit. Ainsi, l'avantage de cette proposition a été souligné sur l'exemple de chaque produit. Si l'utilisateur a ajouté des marchandises au panier, c'est une intention claire de faire un achat et il est temps pour une telle offre.

Une expérience de contrôle a montré qu'un changement aussi simple rapportait des dizaines de millions de dollars par an.
Exemple: antivirus
La publicité est une activité rentable et le logiciel "gratuit" installé par les utilisateurs contient souvent une partie malveillante qui obstrue les pages contenant des publicités. Par exemple, la figure 2 montre à quoi ressemble la page de résultats Bing pour un utilisateur avec un programme malveillant qui a ajouté beaucoup d'annonces à la page (surligné en rouge).
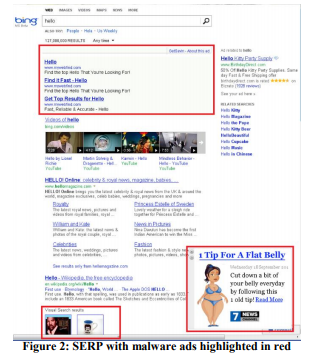
Les utilisateurs ne remarquent généralement même pas que tant de publicités sont affichées non pas par le site qu'ils visitent, mais par un code malveillant qu'ils ont accidentellement installé. L'expérience a été difficile à mettre en œuvre, mais idéologiquement relativement simple: changer les procédures de base qui modifient le DOM et limiter les applications capables de modifier la page. L'expérience a été menée auprès de 3,8 millions d'utilisateurs dont les ordinateurs avaient un code tiers qui éditait le DOM. Dans le groupe test, ces modifications ont été bloquées. Les résultats ont montré une amélioration de toutes les mesures clés, y compris une mesure indicative comme le nombre de sessions par utilisateur, c'est-à-dire les gens venaient plus souvent sur le site. De plus, les utilisateurs ont terminé leurs tâches avec plus de succès et plus rapidement, et les revenus annuels ont augmenté de plusieurs millions de dollars. La vitesse de chargement des pages, dont nous parlerons dans la règle n ° 4, a diminué de centaines de millisecondes pour les pages affectées par l'expérience.
Deux autres petits changements à Bing, qui sont strictement confidentiels, ont pris des jours à se développer, et chacun a entraîné une augmentation des revenus publicitaires de près de 100 millions de dollars par an. Dans un rapport trimestriel de Microsoft publié en octobre 2013, il déclarait: "Les revenus publicitaires de la recherche ont augmenté de 47% en raison de l'augmentation des bénéfices de chaque recherche et de chaque page." Ces deux changements ont contribué de manière significative à la croissance des bénéfices mentionnée.
Après ces exemples, vous pourriez penser que les organisations devraient se concentrer sur de nombreux petits changements. Mais ci-dessous, vous verrez que ce n'est pas du tout le cas. Oui, les éruptions se produisent sur la base de petits changements, mais elles sont très rares et inattendues: dans Bing, probablement une expérience sur 500 atteint un ROI aussi élevé et un résultat positif reproductible. Nous ne prétendons pas que ces résultats seront reproductibles sur d'autres domaines, nous voulons simplement transmettre l'idée: mener des expériences simples en vaut la peine et peut finalement conduire à une percée.
Le danger résultant de se concentrer sur de petits changements est l'incrémentalisme: une organisation qui se respecte devrait avoir un ensemble de changements avec un retour sur investissement potentiellement élevé, mais en même temps, il devrait y avoir plusieurs changements majeurs afin de toucher le gros lot [23].
Règle numéro 2: les modifications ont rarement un impact positif important sur les mesures clés
Comme le disait Al Pacino dans le film Every Sunday, la victoire est donnée centimètre par centimètre. Des centaines et des milliers d'expériences se déroulent chaque année sur des sites comme Bing. La plupart échouent et ceux qui réussissent affectent la mesure clé de 0,1% à 1,0%, ajoutant une baisse à l'impact global. Les petits changements avec un grand effet décrits dans la règle précédente se produisent, mais ils sont rares.
Il est important de noter deux choses:
- Les métriques clés ne sont pas quelque chose de spécifique se rapportant à une fonctionnalité individuelle qui peut être facilement améliorée, mais plutôt une métrique importante pour toute l'organisation: par exemple, le nombre de sessions par utilisateur [18] ou le temps nécessaire pour atteindre l'objectif utilisateur [24].
Lors du développement d'une fonctionnalité, il est très facile d'améliorer considérablement le nombre de clics sur cette fonctionnalité (ou toute autre mesure de fonctionnalité) en la mettant simplement en surbrillance ou en l'agrandissant. Mais pour augmenter le CTR de la page entière ou de l'expérience utilisateur entière - c'est là que réside le défi. La plupart des fonctionnalités ne génèrent que des clics sur la page, les redistribuant entre différentes zones. - Les mesures doivent être divisées en petits segments, de sorte qu'elles sont beaucoup plus faciles à optimiser. Par exemple, une équipe peut-elle facilement améliorer les métriques des requêtes météo sur Bing ou acheter des programmes TV sur Amazon? l'ajout d'un bon outil de comparaison. Cependant, une amélioration de 10% des mesures clés se dissoudra dans les mesures de l'ensemble du produit en raison de la taille du segment. Par exemple, une amélioration de 10% dans un segment de 1% affectera l'ensemble du projet d'environ 0,1% (environ, car si les mesures de segment sont différentes de la moyenne, alors l'effet peut également être différent).
L'importance de cette règle est grande car de fausses erreurs positives se produisent pendant les expériences. Ils ont deux types de raisons:
- Les premiers sont dus aux statistiques. Si nous menons mille expériences par an, alors la probabilité d'une erreur de faux positif de 0,05 conduit au fait que pour une métrique fixe, nous obtiendrons un résultat de faux positif des centaines de fois. Et si nous utilisons plusieurs métriques qui ne sont pas corrélées entre elles, ce résultat ne fait que se renforcer. Même les grands sites comme Bing n'ont pas suffisamment de trafic pour augmenter la sensibilité et tirer des conclusions avec une valeur de p inférieure pour les mesures telles que le nombre de sessions par utilisateur.
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
si nous avons une probabilité préliminaire de succès égale à ⅓ (comme nous l'avons dit dans [7], c'est la valeur moyenne parmi les expériences chez Microsoft), alors la probabilité postérieure d'une expérience statistiquement significative vraiment positive est de 89%. Et si l'expérience est l'une de celles dont nous avons parlé dans la première règle, lorsque seulement 1 sur 500 contient une solution révolutionnaire, la probabilité tombe à 3,1%.
Une conséquence amusante de cette règle est le fait qu'il est beaucoup plus facile de s'accrocher à quelqu'un que de se développer seul. Les décisions prises dans une entreprise qui se concentre sur la signification statistique sont plus susceptibles d'avoir un effet positif. Par exemple, si nous avons un taux de réussite des expériences de 10 à 20%, alors si nous prenons les tests des fonctionnalités qui ont réussi et déployées pour combattre dans d'autres moteurs de recherche, alors notre niveau de succès sera plus élevé. L'inverse est également vrai: les autres moteurs de recherche doivent également tester et mettre en œuvre les choses que Bing a implémentées.
Avec l'expérience, nous avons appris à ne pas faire confiance à des résultats qui semblent trop beaux pour être vrais. Les gens réagissent différemment à différentes situations. Ils soupçonnent que quelque chose n'allait pas et étudient les résultats négatifs des expériences avec leurs nouvelles fonctionnalités, posent des questions et plongent plus profondément dans la recherche des raisons de ce résultat. Mais si le résultat est simplement positif, alors les soupçons se dissipent et les gens commencent à célébrer, à ne pas étudier plus en profondeur et à ne pas rechercher d'anomalies.
Lorsque les résultats sont exceptionnellement remarquables, nous sommes habitués à suivre la loi de Twyman [27]: Tout ce qui semble intéressant ou différent est généralement faux.
La loi de Twyman peut être expliquée par l'inférence bayésienne. D'après notre expérience, nous savions qu'une percée est rare. Par exemple, plusieurs expériences ont considérablement amélioré notre métrique de guidage, le nombre de sessions par utilisateur. Imaginez que la distribution que nous rencontrons dans les expériences soit normale, centrée au point 0 et avec un écart type de 0,25%. Si l'expérience a montré + 2% à la valeur de la métrique clé, alors nous appelons la loi de Twyman et disons que c'est un résultat très intéressant, qui est à une distance de 8 écarts-types de la moyenne et a une probabilité de
10-15 , à l'exclusion d'autres facteurs. Même avec une signification statistique, l'attente préliminaire est si forte que nous retarderons la célébration du succès et approfondirons la recherche de la cause de l'erreur faussement positive du deuxième type. La loi de Twyman est souvent appliquée pour prouver que
=NP . Aujourd'hui, aucun éditeur de site ne sera content s'il reçoit de telles preuves. Très probablement, il répondra immédiatement par un modèle de réponse: "dans votre preuve que P = NP, une erreur a été commise à la page X".
Exemple: métrique en ligne de Surrogate Office
Cook et son équipe [17] ont parlé d'une expérience intéressante qu'ils ont menée avec Microsoft Office Online. L'équipe a testé un nouveau design de page dans lequel un bouton se détachait fortement, appelant à payer pour le produit. La métrique clé que l'équipe a voulu mesurer: le nombre d'achats par utilisateur. Mais le suivi des achats réels nécessitait une modification du système de facturation, et à l'époque c'était difficile à faire. Ensuite, l'équipe a décidé d'utiliser la métrique «clics menant à un achat» et d'appliquer la formule
( ) * = , où la conversion des clics à l'achat est effectuée.
À leur grande surprise, dans l'expérience, le nombre de clics a diminué de 64%. Ces résultats choquants ont forcé une analyse plus approfondie des données, et il s'est avéré que l'hypothèse d'une conversion stable du clic à l'achat est fausse. La page expérimentale, qui montrait le coût du produit, a attiré moins de clics, mais les utilisateurs qui y ont cliqué étaient mieux qualifiés et avaient une conversion beaucoup plus importante du clic à l'achat.
Exemple: plus de clics sur une page lente
JavaScript a été ajouté à la page des résultats de recherche Bing. Ce script ralentissait généralement la page, donc tout le monde s'attendait à voir un léger impact négatif sur les mesures clés de l'engagement, telles que le nombre de clics sur un utilisateur. Mais les résultats ont montré le contraire, il y a eu plus de clics! [18] Malgré la dynamique positive, nous avons suivi la loi de Twyman et résolu l'énigme. Les outils de suivi des clics sont basés sur des balises Web et certains navigateurs n'ont pas passé d'appel si l'utilisateur quittait la page. [28] Ainsi, JavaScript affecte la précision du nombre de clics.
Exemple: Bing Edge
Pendant plusieurs mois en 2013, Bing a changé son réseau de distribution de contenu d'Akamai à son propre Bing Edge. La commutation du trafic vers Bing Edge a été combinée avec de nombreuses autres améliorations. Plusieurs équipes ont indiqué qu'elles avaient amélioré les mesures clés: le CTR de la page d'accueil de Bing a augmenté, les fonctionnalités ont commencé à être utilisées plus souvent et les sorties ont commencé à décliner. Et il s'est avéré que toutes ces améliorations étaient liées au nombre de clics: Bing Edge a amélioré non seulement la vitesse de la page, mais également la délivrabilité des clics. Pour évaluer l'effet, nous avons lancé une expérience dans laquelle l'approche phare de suivi des clics a été remplacée par une approche avec un rechargement de page. Cette technique est utilisée dans la publicité et entraîne une légère perte de clics, ralentissant l'effet de chaque clic. Les résultats ont montré que le pourcentage de clics perdus a chuté de plus de 60%! Et la plupart des réalisations annoncées au cours de cette période sont le résultat d'une amélioration de la diffusion des clics.
Exemple: Recherche MSN Bing
La saisie semi-automatique est une liste déroulante qui offre des options pour compléter une demande pendant qu'une personne la tape. MSN prévoyait d'améliorer cette fonctionnalité avec un algorithme nouveau et amélioré (les équipes de développement des fonctionnalités sont toujours prêtes à expliquer pourquoi leur nouvel algorithme est a priori meilleur que l'ancien, mais ils sont souvent frustrés lorsqu'ils voient les résultats des expériences). L'expérience a été un grand succès; le nombre de recherches effectuées sur Bing avec MSN a considérablement augmenté. En suivant nos règles, nous avons commencé à comprendre et à découvrir que lorsque l'utilisateur cliquait sur l'invite, le nouveau code effectuait deux requêtes de recherche (dont l'une était immédiatement fermée par le navigateur dès que les résultats de la recherche apparaissaient).
Ainsi, l'explication de nombreux résultats positifs n'est peut-être pas aussi excitante. Et notre tâche est de trouver un impact réel sur l'utilisateur, et la règle de Twyman a vraiment aidé à cela et à comprendre de nombreux résultats expérimentaux.
Règle numéro 3. Votre avantage variera.
Il existe de nombreux exemples documentés d'expériences de contrôle réussies. Par exemple, «
Quel test a gagné? » Contient des centaines d'exemples de tests A / B et la liste est mise à jour chaque semaine.
Bien que ce soit un excellent générateur d'idées, ces exemples ont plusieurs problèmes:
- La qualité varie. Dans ces études, une personne d'une entreprise parle du résultat d'un test A / B. Y a-t-il eu une expertise? A-t-elle été effectuée correctement? Y a-t-il eu des émissions? La valeur de p était-elle suffisamment petite (nous avons vu des tests A / B publiés avec une valeur de p supérieure à 0,05, ce qui est généralement considéré comme statistiquement non significatif)? Y avait-il des écueils dont nous avons parlé plus tôt et que les auteurs du test n'ont pas vérifiés correctement?
- Ce qui fonctionne dans un domaine peut ne pas fonctionner dans un autre. Par exemple, Neil Patel [29] recommande d'utiliser le mot «gratuit» dans les publicités proposant une version d'essai de 30 jours au lieu d'une «garantie de remboursement de 30 jours». Cela peut fonctionner avec un produit et un public, mais nous pensons que le résultat dépendra grandement du produit et du public. Joshua Porter [30] déclare que "le rouge est meilleur que le vert" pour les boutons appelant à rejoindre "Get Started Now". Mais comme nous n'avons pas vu beaucoup de sites avec un bouton d'appel à l'action rouge, alors, apparemment, ce résultat n'est pas si bien reproduit.
- L'effet de la nouveauté et de la première fois. Nous obtenons de la stabilité dans nos expériences, et de nombreuses expériences dans de nombreux exemples n'ont pas été menées assez longtemps pour vérifier de tels effets.
- Interprétation incorrecte des résultats. Une raison cachée ou un facteur spécifique peut ne pas être reconnu ou mal compris. Nous donnons deux exemples. L'un d'eux est la première expérience de contrôle documentée.
Exemple 1 Le scorbut est une maladie causée par une carence en vitamine C. Il a tué plus de 100 000 personnes au cours des 16-18 siècles, la plupart d'entre eux des marins qui ont fait de longs voyages et qui sont restés en mer plus longtemps que les fruits et légumes ne pouvaient survivre. En 1747, le Dr James Lind a noté que le scorbut est moins affecté sur les navires en Méditerranée. Il a commencé à donner des citrons et des oranges à certains marins, laissant les autres au régime habituel. L'expérience a été très réussie, mais le médecin n'a pas compris la raison. À l'Hôpital Royal Maritime au Royaume-Uni, il a traité des patients atteints de scorbut avec du jus de citron concentré, qu'il a appelé rob. Le médecin l'a concentré par chauffage, ce qui a détruit la vitamine C. Lind a perdu confiance et a souvent eu recours à la saignée. En 1793, de vrais tests ont été effectués. et le jus de citron fait désormais partie du régime alimentaire quotidien des marins. Le scorbut a rapidement disparu et les marins britanniques sont encore appelés citronnelle.
Exemple 2 Marissa Mayer a parlé d'une expérience dans laquelle Google a augmenté le nombre de résultats sur une page de recherche de 10 à 30. Le trafic et les bénéfices des utilisateurs qui ont recherché sur Google ont chuté de 20%. Et comment a-t-elle expliqué cela? Comme, la page avait besoin d'une demi-seconde de plus pour être générée. Bien sûr, la productivité est un facteur important, mais nous soupçonnons que cela n'a affecté qu'une petite fraction des pertes. Voici notre vision des causes:
- Bing a mené des expériences de ralentissement isolées [11], au cours desquelles seules les performances ont changé. Un délai de réponse du serveur de 250 millisecondes a affecté les revenus d'environ 1,5% et le CTR de 0,25%. C'est une grande influence, et on peut supposer que 500 millisecondes affecteront respectivement les revenus et le CTR de 3% et 0,5%, mais pas de 20% (supposons qu'une approximation linéaire soit applicable ici). Les anciens tests de Bing [32] ont montré un effet similaire sur les clics et moins d'impact sur les revenus avec un délai de 2 secondes.
- Jake Brutlag de Google a écrit dans un article de blog sur une expérience [12] montrant que le ralentissement des résultats de recherche de 100 millisecondes à 400 a un effet significatif sur le nombre spécifique de recherches et varie entre 0,2% et 0,6%, ce qui fonctionne très bien. avec nos expériences, mais très loin des résultats de Marissa Mayer.
- BIng a mené une expérience avec l'affichage de 20 résultats de recherche au lieu de 10. La perte de profit a complètement éliminé l'ajout de publicité supplémentaire (ce qui a rendu la page encore un peu plus lente). Nous pensons que le rapport publicité / algorithmes de recherche est beaucoup plus important que les performances.
Nous sommes sceptiques quant aux nombreux résultats remarquables des tests A / B publiés dans diverses sources. Lors de la vérification des résultats des expériences, demandez-vous quel niveau de confiance avez-vous en eux? Et rappelez-vous, même si l'idée a fonctionné sur un site, il n'est pas nécessaire qu'elle fonctionne sur un autre. La meilleure chose que nous puissions faire est de parler de la reproduction des expériences et de leur succès ou échec. Ce sera très bénéfique pour la science.
Règle numéro 4: la vitesse signifie beaucoup
Les développeurs Web qui testent leurs fonctionnalités à l'aide d'expériences de contrôle ont rapidement réalisé que les performances ou la vitesse du site sont des paramètres critiques [13; 14; 33]. Même un léger retard dans le fonctionnement du site peut affecter les mesures clés du groupe de test.
La meilleure façon d'évaluer les effets des performances est de mener une expérience de ralentissement isolée, c'est-à-dire juste avec un retard supplémentaire. La figure 3 présente un graphique standard de la relation entre les performances et la mesure testée (CTR, taux de réussite unitaire et revenus). Généralement, plus le site est rapide, mieux c'est (plus haut sur ce graphique). En ralentissant le travail du groupe de test par rapport au groupe de contrôle, vous pouvez mesurer l'impact des performances sur la métrique qui vous intéresse. Il est important de noter:
- L'effet du ralentissement sur le groupe de test est mesuré ici et maintenant (ligne pointillée sur le graphique) et dépend du site et de l'audience. Si le site ou l'audience change, la dégradation des performances peut affecter différemment les mesures clés.
- L'expérience montre l'effet de la décélération sur les mesures clés. Cela peut être très utile lorsque vous essayez de mesurer l'effet d'une nouvelle fonctionnalité dont la première implémentation n'est pas efficace. Supposons qu'il améliore la métrique de M de X% et en même temps ralentit le site de T%. En utilisant l'expérience de décélération, nous pouvons évaluer l'effet de la décélération sur la métrique M, corriger l'effet de la caractéristique et obtenir l'effet prédit X '% (il est logique de supposer que ces effets ont la propriété d'additivité). Et nous pouvons donc répondre à la question: «Comment cela affectera-t-il la métrique clé si elle est mise en œuvre efficacement?».
- Nous pouvons supposer comment le fait que le site commencera à fonctionner plus rapidement et aidera à calculer le retour sur investissement des efforts d'optimisation affectera la métrique clé. En utilisant une approximation linéaire (le premier terme de la série de Taylor), nous pouvons supposer que l'effet sur la métrique est le même dans les deux directions. Nous supposons que le delta vertical est le même dans les deux sens et juste différent en signe. Par conséquent, en expérimentant la décélération sur différentes valeurs, nous pouvons approximativement imaginer comment l'accélération affectera ces mêmes valeurs. Nous avons effectué de tels tests chez Bing et notre théorie a été pleinement confirmée.
Quelle est l'importance des performances? Extrêmement important. Chez Amazon, un ralentissement de 100 millisecondes entraîne une baisse de 1% des ventes, comme l'a dit Greg Linded [34 p.10]. Et les intervenants de Bing et de Google [32] montrent un impact significatif des performances sur les mesures clés.
Exemple: expérience de ralentissement du serveur
Nous avons mené une expérience de deux semaines dans Bing pour ralentir le service de 100 millisecondes pour 10% des utilisateurs, de 250 millisecondes pour les autres 10% des utilisateurs. Il s'est avéré que toutes les 100 millisecondes d'accélération des services augmentaient les revenus de 0,6%. À partir de là, même une phrase est apparue qui reflète bien l'essence de notre organisation:
un ingénieur qui améliorera les performances du serveur de 10 millisecondes (1/30 de la vitesse de clignotement de nos yeux) gagnera à son entreprise plus d'un an de revenus. Chaque milliseconde compte.
Dans l'expérience décrite, nous avons ralenti le temps de réponse du serveur, puis ralenti le temps de fonctionnement de tous les éléments de la page. Mais la page a des parties plus importantes et il y a des parties moins importantes. Par exemple, les utilisateurs peuvent ne pas savoir que les éléments hors de la portée de l'écran n'ont pas encore été chargés. Mais y a-t-il des éléments immédiatement affichés qui peuvent être ralentis sans nuire à l'utilisateur? Comme vous le verrez ci-dessous, il existe de tels éléments.
Exemple: les performances du panneau droit ne sont pas si critiques
Dans Bing, certains éléments appelés instantanés sont situés dans le panneau de droite et sont chargés en retard (après l'événement window.onload). Nous avons récemment mené une expérience: les éléments du panneau droit ont ralenti de 250 millisecondes. Si cela a affecté les mesures clés, c'est si insignifiant que nous n'avons rien remarqué. Et l'expérience a impliqué près de 20 millions d'utilisateurs.
Le temps de chargement de la page (PLT) est souvent calculé à l'aide de l'événement window.onload, comme signe de la fin d'une activité utile du navigateur. Mais aujourd'hui, cette mesure présente un grave défaut lors de l'utilisation de navigateurs modernes. Comme l'a montré Steve Souders [32], le haut de la page Amazon s'affiche en 2 secondes, tandis que windows.onload se déclenche en 5,2 secondes. Schurman [32] a déclaré qu'ils pouvaient rendre la page de manière dynamique, il était donc important pour eux d'afficher l'en-tête très rapidement. L'inverse est également vrai: dans Gmail, windows.onload se déclenche après 3,3 secondes, alors qu'à ce moment-là seule la barre de téléchargement est apparue à l'écran, et tout le contenu sera affiché en 4,8 secondes.
Il existe des métriques liées au temps, par exemple: le temps jusqu'au premier résultat (par exemple, le temps jusqu'au premier tweet sur Twitter, le premier résultat de recherche sur la page des résultats). Mais le terme «performance perçue» est toujours utilisé pour décrire une telle vitesse de la page afin que l'utilisateur la perçoive suffisamment pleine. Le concept de «performance perçue» est plus facile à décrire intuitivement qu'à formuler strictement, par conséquent, aucun des navigateurs n'a prévu de mettre en œuvre l'événement
perception.ready() . Pour résoudre ce problème, de nombreuses hypothèses et hypothèses sont utilisées, par exemple:
- Heure du haut de la page (AFT) [37]. Mesuré comme le moment où tous les pixels supérieurs de la page sont affichés. L'implémentation est basée sur des heuristiques particulièrement complexes lorsqu'il s'agit de vidéos, de gifs, de galeries de défilement et d'autres contenus dynamiques qui modifient le haut de la page. Les seuils peuvent être réglés sur «pourcentage de pixels dessinés» pour éviter l'influence de petits éléments insignifiants qui peuvent augmenter la mesure mesurée.
- L'indice de vitesse [38] est une généralisation de l'AFT qui fait la moyenne du temps pendant lequel les éléments de page visibles apparaissent à l'écran. La vitesse ne souffre pas des petits éléments qui apparaissent en retard, mais elle est toujours affectée par le contenu dynamique qui change le haut de la page.
- Temps de phase de page et temps de disponibilité utilisateur [39]. Page Phase Time - Le temps requis pour chaque phase de rendu de page individuelle. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
Métrique
| Décalage
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2.1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
Conclusion
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
Littérature- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010.
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.