Bonjour, Habr! Je vous présente la traduction de l'article «
Apprentissage du modèle Morphable du visage 3D à partir d'images 2D ».

Le modèle morphable tridimensionnel du visage (3D Morphable Model, ci-après 3DMM) est un modèle statistique de la structure et de la texture du visage, qui est utilisé par vision par ordinateur, infographie, dans l'analyse du comportement humain et en chirurgie plastique.
L'unicité de chaque caractéristique du visage fait de la modélisation d'un visage humain une
tâche non triviale . 3DMM est créé pour obtenir un modèle de visage dans un espace de correspondances explicites. Cela signifie une correspondance ponctuelle entre le modèle résultant et d'autres modèles qui permettent le morphing. De plus, les transformations de bas niveau, telles que les différences entre un visage masculin et une expression faciale neutre féminine à partir d'un sourire, devraient être reflétées dans 3DMM.

Des chercheurs de l'Université du Michigan proposent la dernière méthode 3DMM d'apprentissage en profondeur. Utilisant la haute efficacité des réseaux de neurones profonds pour implémenter des cartographies non linéaires, leur méthode permet d'obtenir du 3DMM à partir d'une image 2D capturée dans un environnement arbitraire.
Approches antérieures
En règle générale, les 3DMM sont obtenus à l'aide d'un ensemble de numérisations de visages 3D et d'un ensemble d'images 2D des mêmes visages. L'approche généralement acceptée consiste à utiliser la réduction dimensionnelle dans l'enseignement avec un enseignant, qui est effectuée à l'aide de l'analyse en composantes principales (ACP) sur un ensemble de données de formation composé de scans de visage 3D et d'images 2D correspondantes. Lorsque vous utilisez des modèles linéaires tels que PCA, les transformations non linéaires et les variations faciales ne peuvent pas être reflétées dans 3DMM. De plus, pour modéliser des textures 3D précises de visages, une grande quantité d '«informations 3D» est nécessaire. Ainsi, l'utilisation de cette approche est inefficace.
Méthode proposée
L'idée de la
méthode proposée est d'utiliser des réseaux de neurones profonds ou, plus précisément,
des réseaux de neurones convolutifs (qui sont mieux adaptés au problème considéré et sont moins coûteux en temps de calcul que les perceptrons multicouches) pour obtenir 3DMM. Un réseau neuronal de codage (encodeur) prend une image de visage en entrée et génère des paramètres de texture de visage et d'albédo avec lesquels deux réseaux de neurones de décodage (décodeurs) évaluent la texture et l'albédo.
Comme mentionné précédemment, la 3DMM linéaire présente un certain nombre de problèmes, tels que la nécessité de numérisations de visages 3D, l'impossibilité d'utiliser des images prises sous un angle arbitraire et la précision limitée de la présentation due à l'utilisation de l'ACP linéaire. À son tour, la méthode proposée permet d'obtenir un modèle 3DMM non linéaire basé sur des images 2D de faces à haute résolution,
prises sous un angle arbitraire .
Vue en plan
Dans leur approche, les chercheurs utilisent une carte faciale 2D détaillée pour représenter sa texture et son albédo. Ils soutiennent que la prise en compte des informations spatiales joue un rôle important, car ils utilisent des réseaux de neurones convolutifs, et les images frontales du visage contiennent peu d'informations sur les côtés. C'est pourquoi leur choix s'est porté sur la représentation planaire.
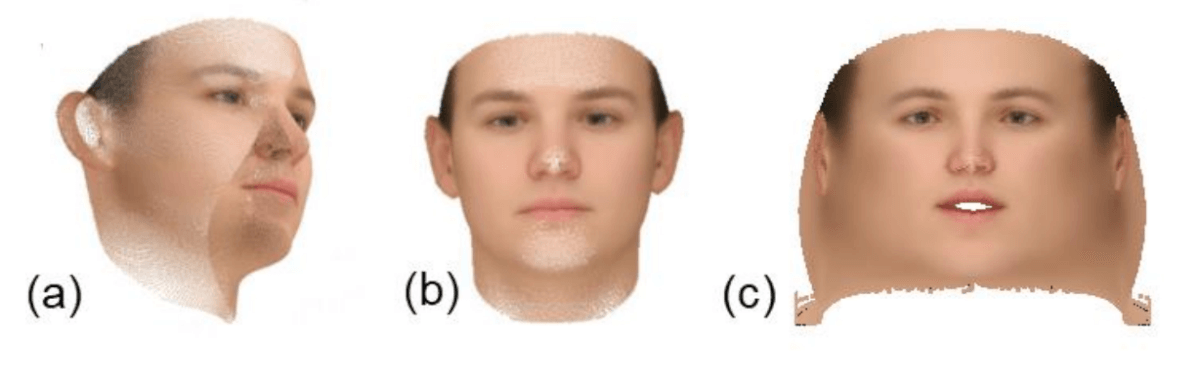
Trois vues différentes de l'albédo. (a) - représentation 3D, (c) - albédo comme image frontale 2D d'un visage, (c) - représentation planaire.
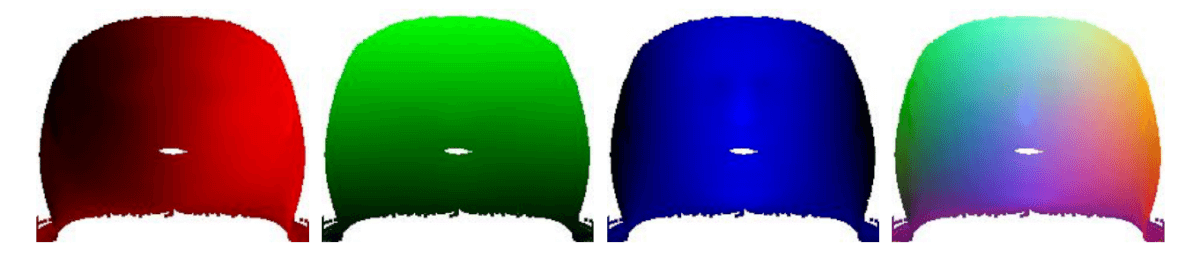
Vue plane. x, y, z et représentation sommaire de la texture.
Architecture de réseau neuronal
Les chercheurs ont conçu un réseau neuronal qui, en prenant une image en entrée, la code en un vecteur de texture, d'albédo et d'éclairage. Les vecteurs cachés codés pour l'albédo et la texture sont décodés à l'aide de deux décodeurs, qui sont utilisés des réseaux de neurones convolutifs. En sortie, les décodeurs diffusent l'éclat du visage, son albédo et sa texture de visage 3D. À l'aide de ces paramètres, une couche de rendu différenciable génère un modèle de visage en combinant les paramètres de texture 3D, d'albédo, d'éclairage et d'emplacement de caméra obtenus par l'encodeur. L'architecture est présentée dans le schéma ci-dessous.
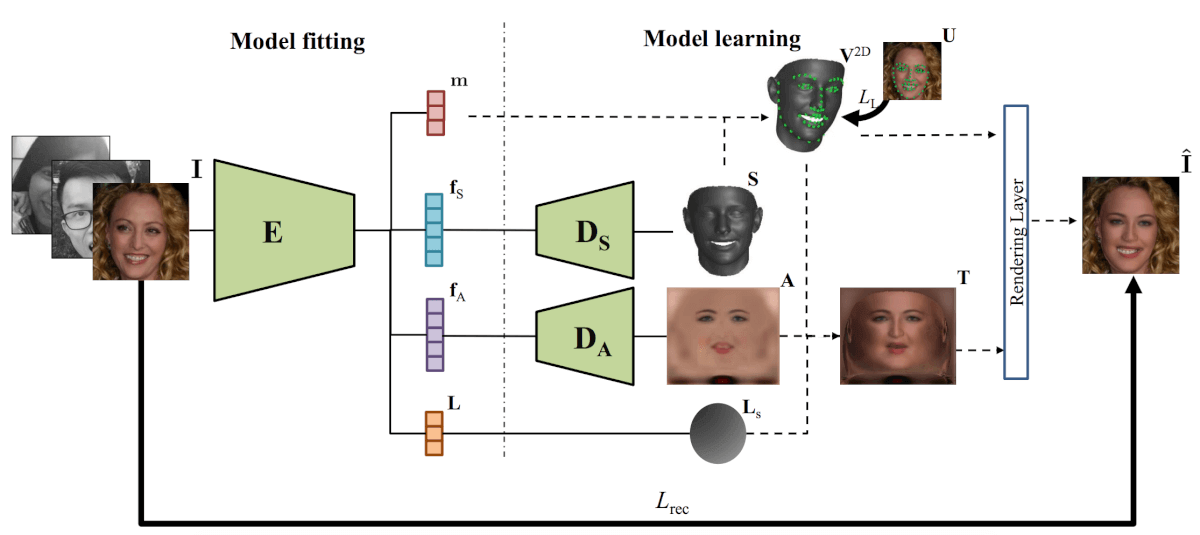
L'architecture de la méthode proposée pour l'obtention de 3DMM non linéaire
Le 3DMM non linéaire stable résultant peut être utilisé pour le chevauchement de faces 2D et la résolution du problème de la reconstruction de faces en trois dimensions.
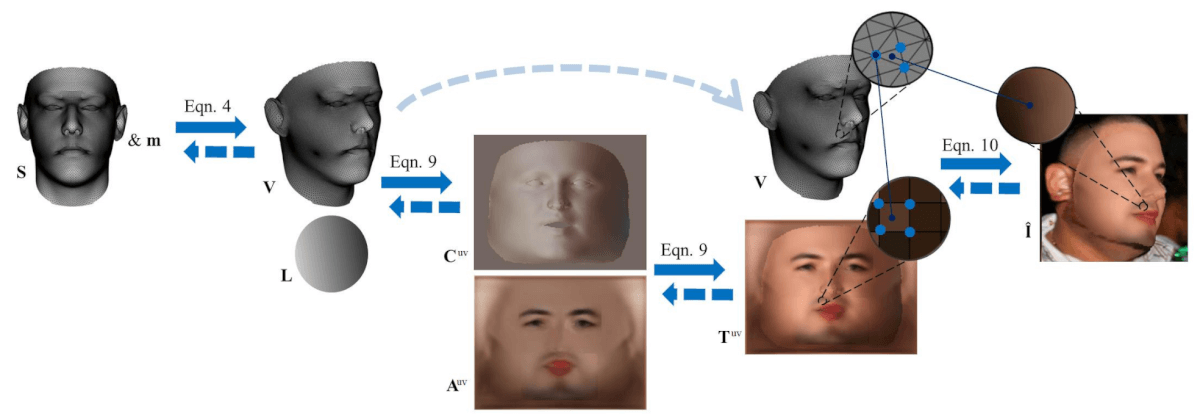
Présentation de la couche de rendu
Comparaison avec d'autres méthodes
La méthode considérée a été comparée à d'autres méthodes en prenant comme exemple les tâches suivantes:
superposition 2D, reconstruction et édition de faces 3D . La méthode proposée est supérieure aux autres approches modernes pour résoudre ces problèmes. Les résultats de la comparaison sont présentés ci-dessous.
Superposition de faces 2D
L'une des applications de la méthode est la superposition de visages, qui devrait améliorer considérablement l'analyse des visages dans un certain nombre de tâches (par exemple, la reconnaissance des visages). L'imposition faciale n'est pas une tâche facile, mais la méthode considérée montre des résultats élevés lors de sa résolution.

Résultats de superposition 2D. Les marques invisibles sont marquées en rouge. La méthode considérée reflète des postures, un éclairage et des expressions faciales inhabituels.
Reconstitution de visage 3D
La méthode considérée a également été comparée à l'aide de la reconstruction faciale 3D et a montré des résultats exceptionnels par rapport à d'autres méthodes.

Comparaison quantitative des résultats de la reconstruction 3D

Les résultats de la reconstruction 3D par rapport à la méthode de Sela et al. La méthode proposée sauve les poils du visage et d'autres caractéristiques du visage beaucoup mieux que cette méthode.

Les résultats de la reconstruction 3D en comparaison avec VRN de Jackson et d'autres sur l'exemple du célèbre ensemble de données CelebA.

Les résultats de la reconstruction 3D par rapport à la méthode de Tewari et autres Comme vous pouvez le voir, la méthode proposée résout le problème de compression du visage en présence de différentes textures (comme les poils du visage).
Édition de visage
La méthode discutée divise l'image du visage en éléments séparés et vous permet de changer le visage en les manipulant. Les résultats de cette méthode lors de la modification des faces ont été évalués sur l'exemple de tâches telles que la modification de l'éclairage et l'ajout d'éléments de face supplémentaires.

Les résultats de l'ajout d'une barbe. La première colonne contient l'image d'origine, la suivante - différents degrés de changement dans la barbe.

Comparaison avec la méthode de Shu et al. (Deuxième ligne). Comme vous pouvez le voir, la méthode proposée donne des images plus réalistes, et en plus, l'identité du visage est mieux préservée.
Conclusion
La méthode proposée sera vraisemblablement largement utilisée, car elle vous permet d'obtenir une 3DMM précise et stable. Bien que la 3DMM ait été répandue depuis sa création, jusqu'à l'avènement de la méthode en question, il n'y avait aucun moyen efficace d'obtenir ce modèle en utilisant des images 2D sous un angle arbitraire.
La méthode proposée utilise des réseaux de neurones profonds comme approximateur pour la modélisation durable des visages humains avec toutes leurs caractéristiques. Une telle façon inhabituelle d'obtenir 3DMM vous permet de manipuler l'image et peut être utilisée dans de nombreuses tâches, dont certaines ont été présentées à l'article.
Traduction - Boris Rumyantsev.