
La mise à l'échelle d'un SGBD est un avenir en constante évolution. Les SGBD s'améliorent et évoluent mieux sur les plates-formes matérielles, tandis que les plates-formes matérielles elles-mêmes augmentent la productivité, le nombre de cœurs et la mémoire - Achilles rattrape la tortue, mais ne l'a toujours pas fait. Le problème de la mise à l'échelle du SGBD bat son plein.
Postgres Professional avait un problème avec la mise à l'échelle non seulement théoriquement, mais aussi pratiquement: avec ses clients. Et plus d'une fois. Un de ces cas sera discuté dans cet article.
PostgreSQL évolue bien sur les systèmes NUMA s'il s'agit d'une seule carte mère avec plusieurs processeurs et plusieurs bus de données. Quelques optimisations peuvent être lues
ici et
ici . Cependant, il existe une autre classe de systèmes, ils ont plusieurs cartes mères, dont l'échange de données s'effectue via une interconnexion, tandis qu'une instance du système d'exploitation fonctionne sur eux et pour l'utilisateur, cette conception ressemble à une seule machine. Et bien que formellement, ces systèmes puissent également être attribués à NUMA, mais ils sont essentiellement plus proches des superordinateurs, comme l'accès à la mémoire locale du nœud et l'accès à la mémoire du nœud voisin diffèrent radicalement. La communauté PostgreSQL estime que la seule instance Postgres exécutée sur de telles architectures est une source de problèmes, et il n'y a pas encore d'approche systématique pour les résoudre.
En effet, l'architecture logicielle utilisant la mémoire partagée est fondamentalement conçue pour le fait que le temps d'accès des différents processus à leur mémoire propre et distante est plus ou moins comparable. Dans le cas où nous travaillons avec de nombreux nœuds, le pari sur la mémoire partagée en tant que canal de communication rapide cesse de se justifier, car en raison de la latence, il est beaucoup "moins cher" d'envoyer une demande pour effectuer une certaine action sur le nœud (nœud) où des données intéressantes que d'envoyer ces données sur le bus. Par conséquent, pour les supercalculateurs et, en général, les systèmes à nombreux nœuds, les solutions de cluster sont pertinentes.
Cela ne signifie pas qu'il faut mettre un terme à la combinaison de systèmes multi-nœuds et d'une architecture de mémoire partagée Postgres classique. Après tout, si les processus postgres passent la plupart de leur temps à effectuer des calculs complexes localement, cette architecture sera même très efficace. Dans notre situation, le client avait déjà acheté un puissant serveur multi-nœuds, et nous devions y résoudre les problèmes de PostgreSQL.
Mais les problèmes étaient sérieux: les demandes d'écriture les plus simples (changer plusieurs valeurs de champ dans un enregistrement) ont été exécutées en quelques minutes à une heure. Comme il a été confirmé par la suite, ces problèmes se sont manifestés dans toute leur splendeur précisément en raison du grand nombre de cœurs et, par conséquent, du parallélisme radical dans l'exécution des requêtes avec un échange relativement lent entre les nœuds.
Par conséquent, l'article se révélera, pour ainsi dire, à deux fins:
- Partager l'expérience: que faire si dans un système à plusieurs nœuds la base de données ralentit sérieusement. Par où commencer, comment diagnostiquer où aller.
- Décrivez comment les problèmes du SGBD PostgreSQL lui-même peuvent être résolus avec un niveau de concurrence élevé. Notamment comment la modification de l'algorithme de prise de verrous affecte les performances de PostgreSQL.
Serveur et DB
Le système était composé de 8 lames avec 2 prises chacune. Au total, plus de 300 cœurs (hors hypertreading). Un pneu rapide (technologie propriétaire du fabricant) relie les pales. Ce n'est pas un supercalculateur, mais pour une instance du SGBD, la configuration est impressionnante.
La charge est également assez importante. Plus d'un téraoctet de données. Environ 3000 transactions par seconde. Plus de 1000 connexions aux postgres.
Ayant commencé à faire face aux attentes d'enregistrement horaire, la première chose que nous avons faite a été d'écrire sur le disque comme cause de retards. Dès que des retards incompréhensibles ont commencé, les tests ont commencé à se faire exclusivement sur
tmpfs . L'image n'a pas changé. Le disque n'y est pour rien.
Prise en main des diagnostics: vues
Les problèmes étant probablement dus à la forte concurrence des processus qui «frappent» les mêmes objets, la première chose à vérifier est les verrous. Dans PostgreSQL, il existe une vue
pg.catalog.pg_locks et
pg_stat_activity pour une telle vérification. Le second, déjà dans la version 9.6, a ajouté des informations sur ce que le processus attend (
Amit Kapila, Ildus Kurbangaliev ) -
wait_event_type . Les valeurs possibles pour ce champ sont décrites
ici .
Mais d'abord, comptez:
postgres=
Ce sont de vrais chiffres. Atteint jusqu'à 200 000 verrous.
Dans le même temps, de tels verrous étaient suspendus à la demande malheureuse:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
Lors de la lecture du tampon, le SGBD utilise le verrouillage de
share , tout en écrivant -
exclusive . Autrement dit, les verrous en écriture représentaient moins de 1% de toutes les demandes.
Dans la vue
pg_locks , les types de verrous ne ressemblent pas toujours à ceux décrits
dans la documentation utilisateur.
Voici la plaque d'allumettes:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
La requête SELECT mode FROM pg_locks a montré que CREATE INDEX (sans CONCURRENTLY) attendrait 234 INSERTs et 390 INSERTs pour le
buffer content lock . Une solution possible consiste à «apprendre» aux INSERT de différentes sessions à se croiser moins dans les tampons.
Il est temps d'utiliser la perf
L'utilitaire
perf collecte de nombreuses informations de diagnostic. En mode
record ... il écrit les statistiques des événements système dans des fichiers (par défaut, ils sont en
./perf_data ), et en mode
report , il analyse les données collectées, par exemple, vous pouvez filtrer les événements qui ne concernent que les
postgres ou un
pid donné:
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
En conséquence, nous verrons quelque chose comme
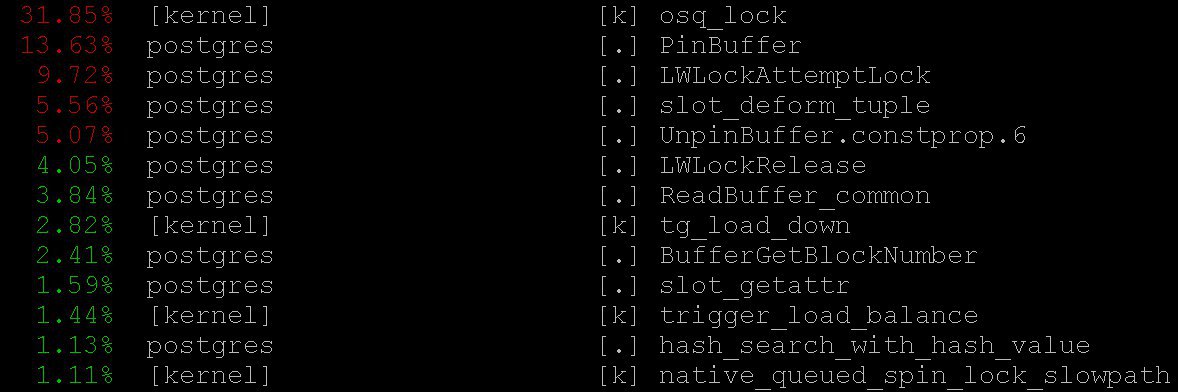
Comment utiliser
perf pour diagnostiquer PostgreSQL est décrit, par exemple,
ici , ainsi que dans le
wiki pg .
Dans notre cas, même le mode le plus simple a donné des informations importantes à
perf top -
perf top , qui fonctionne, bien sûr, dans l'esprit du système d'exploitation le
top performant. Avec
perf top nous avons vu que la plupart du temps, le processeur passe dans les
PinBuffer() base, ainsi que dans les fonctions
PinBuffer() et
LWLockAttemptLock(). .
PinBuffer() est une fonction qui augmente le compteur de références au tampon (mappage d'une page de données à la RAM), grâce à laquelle les processus postgres savent quels tampons peuvent être forcés et lesquels ne le peuvent pas.
LWLockAttemptLock() -
LWLock de capture de
LWLock .
LWLock est une sorte de verrou avec deux niveaux de
shared et d'
exclusive , sans définir d'
deadlock , les verrous sont pré-alloués à
shared memory , les processus en attente attendent dans une file d'attente.
Ces fonctions ont déjà été sérieusement optimisées dans PostgreSQL 9.5 et 9.6. Les verrous à l'intérieur d'eux ont été remplacés par l'utilisation directe des opérations atomiques.
Graphes de flamme
C’est impossible sans eux: même s’ils étaient inutiles, il vaudrait quand même la peine d’en parler - ils sont d’une beauté exceptionnelle. Mais ils sont utiles. Voici une illustration de
github , pas de notre cas (ni nous ni le client ne sommes encore prêts à divulguer les détails).

Ces belles images montrent très clairement ce que prennent les cycles du processeur. Le même
perf peut collecter des données, mais le
flame graph visualise intelligemment les données et construit des arbres basés sur les piles d'appels collectées. Vous pouvez en savoir plus sur le profilage avec des graphiques de flamme, par exemple,
ici , et télécharger tout ce dont vous avez besoin
ici .
Dans notre cas, une énorme quantité de
nestloop était visible sur les graphiques de flamme. Apparemment, les jointures d'un grand nombre de tables dans de nombreuses demandes de lecture simultanées ont provoqué un grand nombre de verrous de
access share .
Les statistiques collectées par
perf montrent où vont les cycles du processeur. Et bien que nous ayons vu que la plupart du temps du processeur passe sur les verrous, nous n'avons pas vu ce qui conduit exactement à de si longues attentes en matière de verrous, car nous ne voyons pas exactement où les attentes de verrouillage se produisent, car Le temps CPU n'est pas perdu à attendre.
Afin de voir les attentes elles-mêmes, vous pouvez créer une demande à la vue système
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
a révélé que:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(les astérisques ici remplacent simplement les détails de la demande que nous ne divulguons pas).
Vous pouvez voir les valeurs
buffer_content (blocage du contenu des tampons) et
buffer_mapping (blocage des composants de la plaque de hachage
shared_buffers ).
Pour obtenir de l'aide sur gdb
Mais pourquoi tant d'attentes pour ces types de serrures? Pour des informations plus détaillées sur les attentes, j'ai dû utiliser le débogueur
GDB . Avec
GDB nous pouvons obtenir une pile d'appels de processus spécifiques. En appliquant l'échantillonnage, c'est-à-dire Après avoir collecté un certain nombre de piles d'appels aléatoires, vous pouvez vous faire une idée des piles qui ont les attentes les plus longues.
Considérez le processus de compilation des statistiques. Nous considérerons la collecte «manuelle» de statistiques, bien que dans la vie réelle des scripts spéciaux soient utilisés pour le faire automatiquement.
Tout d'abord,
gdb doit être attaché au processus PostgreSQL. Pour ce faire, recherchez le
pid processus serveur, par exemple
$ ps aux | grep postgres
Disons que nous avons trouvé:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
et maintenant insérez le
pid dans le débogueur:
igor_le:~$gdb -p 2025
Une fois à l'intérieur du débogueur, nous écrivons
bt [c'est-à-dire
backtrace ] ou
where . Et nous obtenons beaucoup d'informations sur ce type:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
Après avoir collecté des statistiques, y compris des piles d'appels de tous les processus postgres, collectées à plusieurs reprises à différents moments, nous avons vu que le
buffer partition lock à l'intérieur du
relation extension lock duré 3706 secondes (environ une heure), c'est-à-dire qu'il se verrouille sur un morceau de la table de hachage du tampon , qui était nécessaire pour remplacer l'ancien tampon, afin de le remplacer par la suite par un nouveau correspondant à la partie étendue de la table. Un certain nombre de verrous de
buffer content lock de
buffer content lock étaient également perceptibles, ce qui correspondait à l'attente de verrouillage des pages de l'index de l'
B-tree pour l'insertion.

Au début, deux explications sont venues pour un temps d'attente aussi monstrueux:
- Quelqu'un d'autre a pris ce
LWLock et est resté. Mais c'est peu probable. Parce que rien de compliqué ne se passe à l'intérieur du verrou de partition tampon. - Nous avons rencontré un comportement pathologique de
LWLock . Autrement dit, malgré le fait que personne n'a pris le verrou trop longtemps, son attente a duré trop longtemps.
Patchs de diagnostic et traitement des arbres
En réduisant le nombre de connexions simultanées, nous déchargerions probablement le flux de demandes de verrous. Mais ce serait comme se rendre. Au lieu de cela,
Alexander Korotkov , l'architecte en chef de Postgres Professional (bien sûr, il a aidé à préparer cet article), a proposé une série de correctifs.
Tout d'abord, il était nécessaire d'avoir une image plus détaillée de la catastrophe. Peu importe la qualité des outils finis, les correctifs de diagnostic de leur propre fabrication seront également utiles.
Un correctif a été écrit qui ajoute une journalisation détaillée du temps passé dans l'
relation extension , ce qui se passe à l'intérieur de la fonction
RelationAddExtraBlocks() . Nous découvrons donc ce que le temps est passé à l'intérieur de
RelationAddExtraBlocks().Et à l'appui de lui, un autre correctif a été écrit dans
pg_stat_activity sur ce que nous faisons maintenant en ce qui
relation extension . Cela a été fait de cette façon: lorsque la
relation développe,
application_name devient
RelationAddExtraBlocks . Ce processus est désormais facilement analysé avec un maximum de détails à l'aide de
gdb bt et
perf .
En fait, les correctifs médicaux (et non diagnostiques) ont été écrits deux fois. Le premier correctif a changé le comportement des verrous de feuille de
B‐tree : auparavant, lors de la demande d'insertion, la feuille était bloquée en tant que
share , puis elle devenait
exclusive . Maintenant, il devient immédiatement
exclusive . Maintenant, ce correctif
a déjà été validé pour
PostgreSQL 12 . Heureusement, cette année,
Alexander Korotkov a reçu le
statut de committer - le deuxième committer PostgreSQL en Russie et le second dans l'entreprise.
La valeur
NUM_BUFFER_PARTITIONS a également été augmentée de 128 à 512 pour réduire la charge sur les verrous de mappage: la table de hachage du gestionnaire de tampons a été divisée en morceaux plus petits, dans l'espoir que la charge sur chaque pièce spécifique soit réduite.
Après avoir appliqué ce correctif, les verrous sur le contenu des tampons ont disparu, mais malgré l'augmentation de
NUM_BUFFER_PARTITIONS ,
buffer_mapping est resté, c'est-à-dire que nous vous rappelons de bloquer des morceaux de la table de hachage du gestionnaire de tampons:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
Et même ce n'est pas grand-chose. B - l'arbre n'est plus un goulot d'étranglement. L'extension du
heap- est apparue.
Traitement de la conscience
Ensuite, Alexander a avancé l'hypothèse et la solution suivantes:
Nous attendons beaucoup de temps sur le
buffer parittion lock du
buffer parittion lock lors de l'
buffer parittion lock tampon. Peut-être sur le même
buffer parittion lock il y a une page très demandée, par exemple, la racine d'un
B‐tree À ce stade, il existe un flux continu de demandes de
shared lock partir des demandes de lecture.
La file d'attente à
LWLock «pas juste». Étant donné que
shared lock peuvent être pris autant de fois que nécessaire, alors si le
shared lock déjà pris, les
shared lock suivants passent sans file d'attente. Ainsi, si le flux de verrous partagés est d'une intensité suffisante pour qu'il n'y ait pas de «fenêtres» entre eux, alors l'attente d'un
exclusive lock va presque à l'infini.
Pour résoudre ce problème, vous pouvez essayer d'offrir - un patch de comportement "gentlemanly" des verrous. Cela éveille la conscience des
shared locker et ils font honnêtement la queue lorsqu'ils ont déjà une
exclusive lock (il est intéressant que les serrures lourdes -
hwlock - n'aient pas de problèmes de conscience: elles font toujours la queue honnêtement)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
Tout va bien! Il n'y a pas de longues
insert . Bien que les verrous sur les morceaux des plaques de hachage soient restés. Mais que faire, ce sont les propriétés des pneus de notre petit supercalculateur.
Ce patch a également été
offert à la communauté . Mais quelle que soit l'évolution du sort de ces correctifs dans la communauté, rien ne les empêche d'accéder aux prochaines versions de
Postgres Pro Enterprise , conçues spécifiquement pour les clients avec des systèmes lourdement chargés.
Moral
Des verrous de
share légers à haute moralité -
exclusive blocs
exclusive sautent la file d'attente - ont résolu le problème des retards horaires dans un système à plusieurs nœuds. La balise de hachage du
buffer manager n'a pas fonctionné en raison d'un flux de
share lock trop important, ce qui n'a laissé aucune chance aux verrous nécessaires pour remplacer les anciens tampons et en charger de nouveaux. Les problèmes avec l'extension du tampon pour les tables de base de données n'étaient qu'une conséquence de cela. Avant cela, il était possible d'élargir le goulot d'étranglement avec l'accès à la racine de l'
B-treePostgreSQL n'a pas été conçu pour les architectures NUMA et les superordinateurs. L'adaptation à de telles architectures Postgres est un travail énorme qui nécessiterait (et éventuellement nécessiterait) les efforts coordonnés de nombreuses personnes et même d'entreprises. Mais les conséquences désagréables de ces problèmes architecturaux peuvent être atténuées. Et nous devons le faire: les types de charges qui ont entraîné des retards similaires à ceux décrits sont assez typiques, des signaux de détresse similaires provenant d'autres endroits continuent de nous parvenir. Des problèmes similaires sont apparus plus tôt - sur les systèmes avec moins de cœurs, seules les conséquences n'étaient pas si monstrueuses et les symptômes ont été traités avec d'autres méthodes et d'autres correctifs. Maintenant, un autre médicament est apparu - pas universel, mais clairement utile.
Ainsi, lorsque PostgreSQL travaille avec la mémoire de l'ensemble du système en tant que local, aucun bus à grande vitesse entre les nœuds ne peut se comparer au temps d'accès à la mémoire locale. Les tâches surgissent à cause de cela difficile, souvent urgent, mais intéressant. Et l'expérience de les résoudre est utile non seulement pour les décisifs, mais aussi pour toute la communauté.
