
Chacune des technologies créées à partir du moment où une personne a ramassé une pierre est obligée d'améliorer la vie d'une personne en remplissant ses fonctions principales. Cependant, toute technologie peut avoir des «effets secondaires», c'est-à-dire affecter une personne et le monde qui l'entoure d'une manière à laquelle personne au moment de la création de cette technologie ne pensait ou ne voulait penser. Un exemple frappant: des machines ont été créées et une personne a pu parcourir de longues distances à une vitesse plus rapide qu'auparavant. Mais en même temps, la pollution a commencé.
Aujourd'hui, nous parlerons de «l'effet secondaire» d'Internet, qui affecte non pas l'atmosphère terrestre, mais les esprits et les âmes des gens eux-mêmes. Le fait est que le World Wide Web est devenu un excellent outil de diffusion et d'échange d'informations, de communication entre des personnes physiquement éloignées les unes des autres et bien plus encore. Internet aide dans divers domaines de la société, de la médecine à la préparation banale pour l'épreuve de l'histoire. Cependant, le lieu où se rassemblent un grand nombre de voix et d'opinions, parfois anonymes, est malheureusement rempli de ce qui est si inhérent à la haine de l'homme.
Dans l'étude d'aujourd'hui, les scientifiques décomposent plusieurs algorithmes dont la tâche principale est d'identifier les messages offensants, grossiers et hostiles. Ils ont réussi à casser tous ces algorithmes, démontrant ainsi leur faible niveau d'efficacité et signalant les erreurs à corriger. Comment les scientifiques ont brisé ce qui aurait fonctionné, pourquoi ils l'ont fait et quelles conclusions nous devons tous tirer - nous chercherons des réponses à ces questions et à d'autres dans le rapport des chercheurs. Allons-y.
Contexte de l'étudeLes réseaux sociaux et autres formes d'interaction sur Internet entre les gens sont devenus partie intégrante de nos vies. Malheureusement, de nombreux utilisateurs de ces services comprennent trop littéralement une «liberté d'expression, de pensée et d'expression», couvrant cela de leur droit à un comportement indécent, familier et impoli sur le réseau. Chacun de nous, d'une manière ou d'une autre, a été confronté à «l'activité» de ces individus. Beaucoup sont même devenus l'objet de tels discours. Bien sûr, on ne peut nier qu’une personne a le droit de dire ce qu’elle pense. Cependant, exprimer vos pensées est une chose et insulter quelqu'un en est une autre. Outre la liberté d'expression, l'anonymat est également exploité, car vous pouvez dire n'importe quoi à n'importe qui, tout en restant incognito. En conséquence, vous ne serez pas puni pour votre comportement inapproprié.
Cela ne vaut pas la peine d'expliquer que les phrases «je ne l'aimais pas» et «c'est une baise complète **, l'auteur tue contre le mur» (c'est une option encore plus ou moins décente) ont des couleurs émotionnelles complètement différentes, bien qu'elles aient une essence commune - pour le commentateur Je n'aime pas ce qu'il a vu / lu / entendu, etc. Mais si vous interdisez à une personne d'exprimer ainsi son mécontentement, cela est-il considéré comme une violation de ses droits? Beaucoup diront oui. D'un autre côté, vaut-il la peine de continuer à fermer les yeux sur la haine exponentielle croissante sur Internet, ce qui, dans la plupart des cas, n'est pas justifié. La haine, en tant que telle, a sa place. Bien sûr, c'est une émotion très forte et incroyablement négative. Cependant, si une personne déteste celle qui a fait quelque chose de terrible (meurtre, viol et autres actes inhumains), cela peut tout de même être justifié. Mais quand la haine se manifeste dans l'adresse d'une personne complètement étrangère qui n'a rien commis d'immoral ou d'inhumain, c'est une histoire complètement différente.
Maintenant, de nombreuses entreprises et groupes de recherche ont décidé de créer leurs propres algorithmes qui peuvent analyser n'importe quel texte et dire où
le langage d'hostilité * est présent et dans quelle mesure il est exprimé. Les héros de nos jours ont décidé de tester ces algorithmes, en particulier l'API Google Perspective très promue, qui détermine l '«acidité» de la phrase, c'est-à-dire combien cette phrase peut être considérée comme une insulte.
Discours de haine * - comme le montre clairement le nom même de ce terme, il s'agit d'une combinaison de moyens linguistiques visant à exprimer une vive hostilité entre les interlocuteurs. Les formes de discours de haine les plus courantes sont: le racisme, le sexisme, la xénophobie, l'homophobie et d'autres formes d'hostilité à quelque chose d'autre.
Les principales tâches que les chercheurs se sont fixées sont d'étudier les algorithmes les plus populaires pour identifier les discours de haine, comprendre leurs méthodes de travail et essayer de les contourner.
Algorithmes de rechercheLes scientifiques ont choisi plusieurs algorithmes dont les bases de données sont différentes les unes des autres, ce qui nous permet également de déterminer la meilleure base de données. Certains algorithmes reposent davantage sur l'identification des
connotations sexuelles
* , d'autres - religieuses. Le point commun à tous les algorithmes est la source de leurs connaissances - Twitter. Selon les chercheurs, cela est loin d'être parfait, car ce service a certaines limites (par exemple, le nombre de caractères dans un message). Par conséquent, la base d'un algorithme efficace doit être remplie à partir de différents réseaux et services sociaux.
Connotation * - une méthode de coloration d'un mot ou d'une phrase avec des nuances sémantiques ou émotionnelles supplémentaires. Peut varier en fonction de la séparation linguistique, culturelle ou autre. Exemple: venteux - «la journée était venteuse» (le sens direct du mot), «il a toujours été une personne venteuse» (dans ce cas, cela signifie inconstance et frivolité).
Liste des algorithmes et de leurs fonctionnalités:
Detox : projet Wikipédia pour identifier un langage inapproprié dans les commentaires éditoriaux. Il fonctionne sur la base d'
une régression logistique * et d'un
perceptron multicouche * , utilisant des modèles
N-gramme * au niveau des lettres et des mots. La taille des N-grammes d'un mot varie de 1 à 3, et les lettres - de 1 à 5.
La régression logistique * est un modèle pour prédire la probabilité d'un événement en ajustant les données à une courbe logistique.
Un perceptron multicouche * est un modèle de perception de l'information, composé de trois couches principales: S - capteurs (réception d'un signal), A - éléments associatifs (traitement) et éléments réagissant R (réponse à un signal), ainsi qu'une couche supplémentaire A.
N-gram * est une séquence de n éléments.
Les données de la base de l'algorithme ont été collectées par des tiers et chacun des commentaires a été évalué par dix évaluateurs.
T1 : un algorithme avec une base divisée en trois types de commentaires de Twitter (discours de haine, insultes sans discours de haine et neutre). Les chercheurs disent que c'est la seule base avec une catégorisation similaire. Un discours de haine a été détecté en recherchant sur Twitter des modèles donnés. De plus, les résultats trouvés ont été évalués par trois employés de CrowdFlower (maintenant Figure Eight Inc., une étude sur l'apprentissage automatique et l'intelligence artificielle). La plupart de la base (76%) est constituée de phrases offensantes, tandis que le langage hostile ne prend que 5%.
T2 : un algorithme utilisant des réseaux de neurones profonds. L'accent principal a été mis sur la mémoire à court terme à long terme (LSTM). La base de cet algorithme est divisée en trois catégories: le racisme, le sexisme et rien. Les chercheurs ont combiné les deux premières catégories en une seule, formant une catégorie intégrale de langage hostile. La base de la base était de 16 000 tweets.
T1 * ,
T3 : un algorithme basé sur le réseau de neurones convolutionnels (CNN) et les unités de récurrence contrôlée (GRU), utilisant la base de connaissances T1, en la complétant par des catégories distinctes destinées aux réfugiés et aux musulmans (T3).
Performances de l'algorithmeLes performances des algorithmes ont été testées par deux méthodes. Dans le premier, ils ont fonctionné comme prévu à l'origine. Et dans le second, les algorithmes ont été formés à travers les bases de données de chacun d'eux, une sorte d'échange d'expérience.
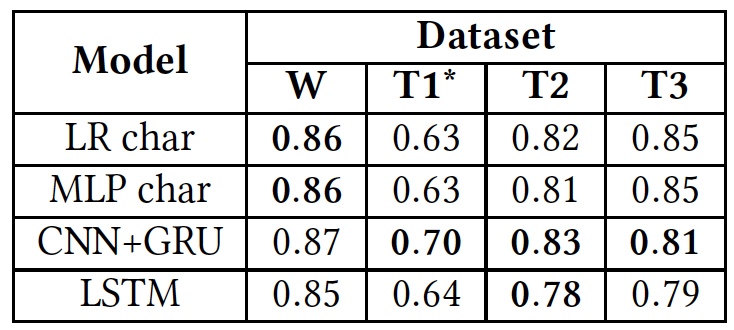 Résultats des tests (les résultats de l'utilisation des bases de données originales sont en gras).
Résultats des tests (les résultats de l'utilisation des bases de données originales sont en gras).Comme le montre le tableau ci-dessus, tous les algorithmes ont montré approximativement les mêmes résultats lorsqu'ils étaient appliqués à différents textes (bases de données). Cela suggère qu'ils ont tous étudié en utilisant le même type de texte.
La seule déviation significative est observée dans T1 *. Cela est dû au fait que la base de données de cet algorithme est extrêmement déséquilibrée, selon les scientifiques. Le discours de haine ne prend que 5%, comme nous le savons déjà. La division initiale en trois catégories de textes a été transformée en une division en deux, lorsque les «insultes, mais sans langage hostile» et les textes «neutres» ont été combinés en un seul groupe, occupant environ 80% de la base entière.
De plus, les chercheurs ont recyclé les algorithmes. Au début, les bases d'origine ont été utilisées. Après cela, chacun des algorithmes a dû travailler avec la base d'un autre algorithme, au lieu du sien.
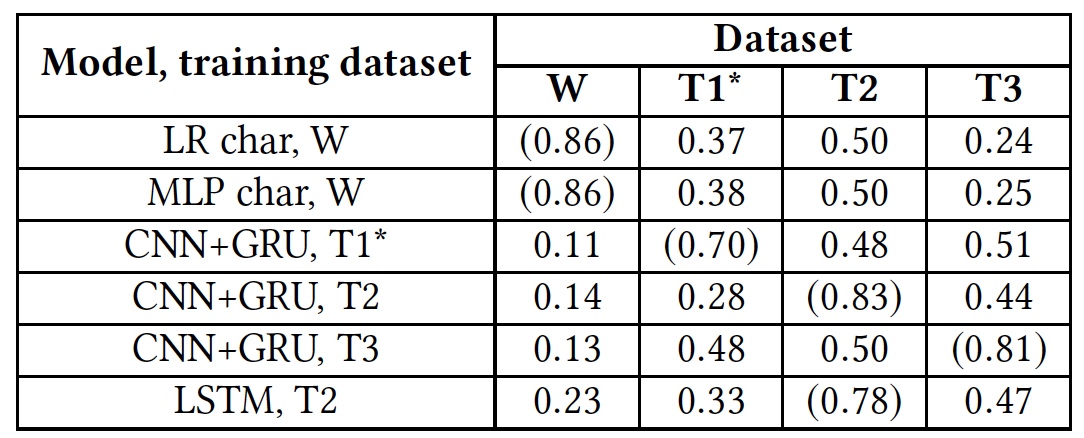 Résultats du test de recyclage (les résultats utilisant des bases de données natives sont indiqués entre parenthèses).
Résultats du test de recyclage (les résultats utilisant des bases de données natives sont indiqués entre parenthèses).Ce test a montré que tous les algorithmes n'étaient absolument pas préparés pour travailler avec des bases de données étrangères. Cela suggère que les indicateurs linguistiques du discours de haine ne se recoupent pas dans différentes bases de données, ce qui peut être dû au fait que dans différentes bases de données il y a très peu de mots correspondants, ou en raison d'inexactitudes dans l'interprétation de certaines phrases.
Insultes et discours de haineLes chercheurs ont décidé d'accorder une attention particulière à deux catégories de textes: offensants et hostiles. L'essentiel est que certains algorithmes les combinent en un seul tas, tandis que d'autres essaient de les séparer en groupes indépendants. Bien sûr, les insultes sont clairement un phénomène négatif, et elles peuvent être attribuées en toute sécurité à une catégorie d'hostilité. Cependant, la définition des insultes est un processus beaucoup plus compliqué que l'identification de la haine apparente dans le texte.
Pour tester les algorithmes pour détecter les insultes, la base T1 a été utilisée. Mais l'algorithme T1 * n'a pas participé à ce test, du fait qu'il est déjà préparé pour un tel travail, ce qui rend les résultats de sa vérification biaisés.
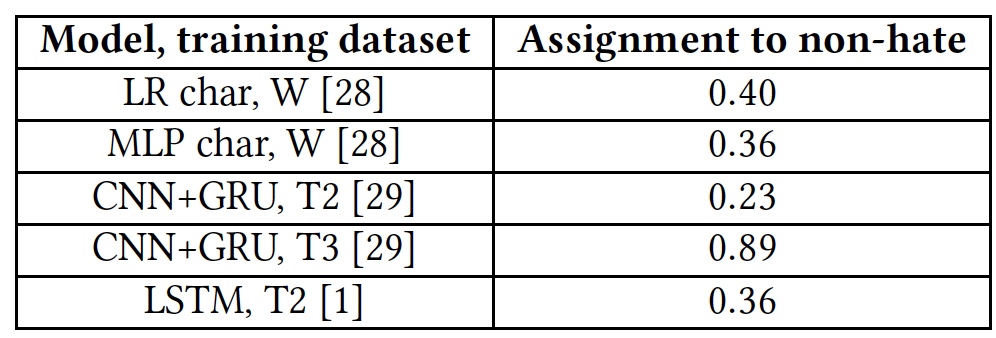 Résultats des tests pour la capacité de détecter les textes offensants.
Résultats des tests pour la capacité de détecter les textes offensants.Tous les algorithmes ont montré des résultats plutôt médiocres. L'exception était T3, mais pas au détriment de leurs talents. Le fait est que les mots qui ne sont pas familiers avec l'algorithme sont marqués avec la balise unk. Près de 40% des mots de chaque phrase étaient marqués avec cette balise, et l'algorithme les comptait automatiquement comme des insultes. Et cela, bien sûr, était loin d'être toujours juste. En d'autres termes, l'algorithme T3 n'a pas non plus fait face à la tâche compte tenu de son vocabulaire court.
L'un des principaux problèmes des algorithmes, les scientifiques considèrent le facteur humain. La plupart des bases de données de chacun des algorithmes sont collectées, analysées et évaluées par des personnes. Et ici, de fortes différences de résultats sont possibles. La même phrase peut sembler offensante pour certaines personnes ou neutre pour d'autres.
En outre, le manque d'algorithmes pour comprendre les phrases non standard qui peuvent contenir calmement un langage grossier, mais sans insultes ni langage d'hostilité, joue également un effet négatif.
Pour le démontrer, un test avec plusieurs phrases a été réalisé. Ensuite, le test a été répété, mais dans chacune des phrases, le mot très obscène «
f * ck » a été ajouté (marqué de la lettre
F dans le tableau).
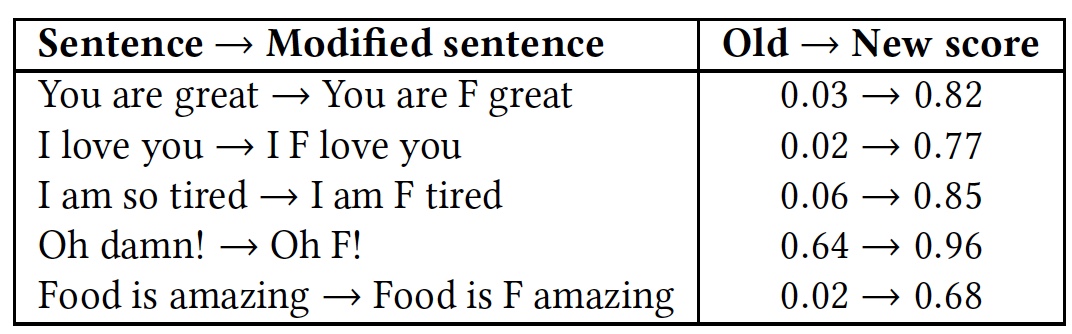 Résultats de reconnaissance comparative des phrases avec et sans le mot «f * ck».
Résultats de reconnaissance comparative des phrases avec et sans le mot «f * ck».Comme le montre le tableau, cela valait la peine d'ajouter un mot avec la lettre F, car tous les algorithmes ont immédiatement pris la phrase comme un langage d'hostilité. Bien que l'essence des phrases soit restée la même, amicale, mais la couleur émotionnelle est devenue plus prononcée.
Les tests de l'API Google Perspective décrits ci-dessus montrent des résultats similaires. Cet algorithme n'est pas non plus en mesure de distinguer un langage hostile des insultes et de l'insulte d'une simple épithète utilisée pour embellir émotionnellement une phrase.
Comment tromper l'algorithme?Comme cela arrive souvent, si quelqu'un casse quelque chose, ce n'est pas toujours mauvais. Et tout cela parce que lorsque nous cassons, nous révélons l'absence d'un système, son point faible, qui devrait être amélioré en évitant une répétition de la panne. Les modèles ci-dessus ne faisaient pas exception et les chercheurs ont décidé de voir comment leur travail pourrait être interrompu. Il s'est avéré que ce n'était pas aussi difficile que le pensaient les créateurs de ces algorithmes.
Le modèle de contournement de l'algorithme est simple: le cracker sait que ses textes sont vérifiés, il peut modifier les données d'entrée (texte) de manière à éviter la détection. Le cracker n'a pas accès à l'algorithme lui-même et à sa structure. Autrement dit, l'attaquant casse l'algorithme exclusivement au niveau de l'utilisateur.
Le contournement de l'algorithme (appelons-le le bon vieux mot «piratage») est divisé en trois types:
- Changer le mot: fautes de frappe intentionnelles et Leet, c'est-à-dire remplacer certaines lettres par des chiffres (par exemple: vous avez fière allure aujourd'hui! - Y0U 100K 6r347 70D4Y!);
- Modifiez l'espace entre les mots: ajoutez et supprimez des espaces;
- Ajoutez des mots à la fin d'une phrase.
Le premier programme de piratage - changer des mots - devrait réussir trois tâches: réduire le degré de reconnaissance d'un mot par un algorithme, éviter les corrections d'orthographe et maintenir la lisibilité des mots pour une personne.
Le programme échange les deux lettres du mot. La préférence est donnée aux lettres plus proches du milieu du mot et les unes des autres. Seules les première et dernière lettres du mot sont exclues. De plus, les mots sont modifiés avec un œil sur Leet, où certaines lettres sont remplacées par des chiffres: a - 4, e - 3, l - 1, o - 0, s - 5.
Afin de gérer ces astuces, les algorithmes ont été légèrement améliorés en introduisant une vérification orthographique et une transformation stochastique de la base de connaissances de formation. Autrement dit, non seulement les mots principaux étaient présents dans la base de données, mais aussi leur modification en réorganisant les lettres du formulaire.
Cependant, plus le mot est long, plus il existe d'options de réarrangement des lettres, ce qui élargit les capacités du programme de cracker.
La méthode de suppression ou d'ajout d'espaces a également ses propres caractéristiques. La suppression d'espaces convient mieux aux algorithmes opposés qui analysent des mots entiers. Mais les algorithmes qui analysent chaque lettre peuvent facilement faire face à l'absence d'espaces.
L'ajout d'espaces peut sembler une méthode très inefficace, mais cela peut encore tromper certains algorithmes. Les modèles qui considèrent les mots dans leur ensemble procèdent à une analyse lexicale de la phrase, en la décomposant en composants (jetons). Dans ce cas, l'espace sert de séparateur de mots, c'est-à-dire un élément important de l'analyse des phrases. S'il y a plus de lacunes que nécessaire, alors les mots entre eux deviennent méconnaissables pour l'algorithme. Dans le même temps, cette méthode de contournement conserve un haut degré de lisibilité des phrases pour une personne. La méthode fonctionne simplement: une lettre aléatoire dans le mot est sélectionnée, après quoi un espace est mis. En conséquence, un mot qui était auparavant connu de l'algorithme cesse de l'être. Exemple: "Haine" - "haine". Si vous supprimez toutes les lacunes du texte, la phrase entière deviendra pour l'algorithme un mot incompréhensible pour lui. Comme dans l'histoire où la fille a donné à sa mère un nouveau téléphone, et elle lui a écrit un SMS avec le texte: "Cher de laisser un blanc sur ce téléphone." Nous pouvons lire cette phrase, mais l'algorithme la percevra comme un seul mot, ce qu'il ne connaît bien sûr pas.
Cependant, si l'algorithme analyse les lettres séparément, il pourra reconnaître la phrase, donc cette méthode de piratage ne convient pas dans de tels cas.
Pour contrer ces attaques, les algorithmes ont également été recyclés. Pour lutter contre l'ajout d'espaces, la base de l'algorithme est passée par un programme d'introduction aléatoire d'espaces: un mot de n lettres peut être séparé par un espace de n-1 façons. Cependant, cela a conduit à une explosion combinatoire, lorsque la complexité de l'algorithme augmente fortement en raison de l'augmentation de la taille des données d'entrée. Par conséquent, l'apprentissage de l'algorithme basé sur la méthode bien connue d'ajout d'espaces est un exercice extrêmement difficile et inefficace.
La suppression d'espaces est également difficile. Si la base de l'algorithme est reconstituée avec des phrases qu'il connaît, mais sans espaces, cela ne fonctionnera efficacement que lorsqu'une telle phrase sera appliquée. Cela vaut la peine de remplacer quelques lettres ou un mot, et l'algorithme ne reconnaît rien.
Dans la méthode de piratage en ajoutant des mots, l'essentiel est de savoir comment fonctionne l'algorithme de reconnaissance. Il divise les mots en catégories, dit «bon» et «mauvais». Si la phrase en a plus de «bonnes», l'algorithme déterminera très probablement la phrase entière comme «bonne». Et vice versa. Si vous ajoutez un mot «bon» au hasard à l'expression «mauvais» dans le sens, vous pouvez tromper l'algorithme, et la signification de la phrase pour la personne qui le lit restera la même. Le programme de piratage génère des nombres aléatoires (de 10 à 50) ou des mots à la fin de chaque phrase. Une liste des mots anglais les plus courants fournis par Google a été choisie comme source de mots aléatoires.
 Un tableau des résultats de l'application des méthodes de piratage et de réaction des algorithmes ci-dessus (attaque A, formation AT basée sur le principe d'un programme d'attaque, vérification orthographique SC, vérification des espaces RW).
Un tableau des résultats de l'application des méthodes de piratage et de réaction des algorithmes ci-dessus (attaque A, formation AT basée sur le principe d'un programme d'attaque, vérification orthographique SC, vérification des espaces RW).Pour illustrer la solution de contournement en introduisant des mots supplémentaires, les chercheurs ont effectué un test en utilisant le mot «amour». Ce mot a été ajouté à la fin des phrases offensantes.
 Résultats des tests avec le mot "amour".
Résultats des tests avec le mot "amour".Le tableau montre que cette méthode a pu tromper tous les algorithmes qui analysent le mot entier. Les algorithmes qui analysent les lettres séparément ont également souffert, mais pas tant.
Google Perspective API , .
( ):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
. , , Google Perspective API . «love» .
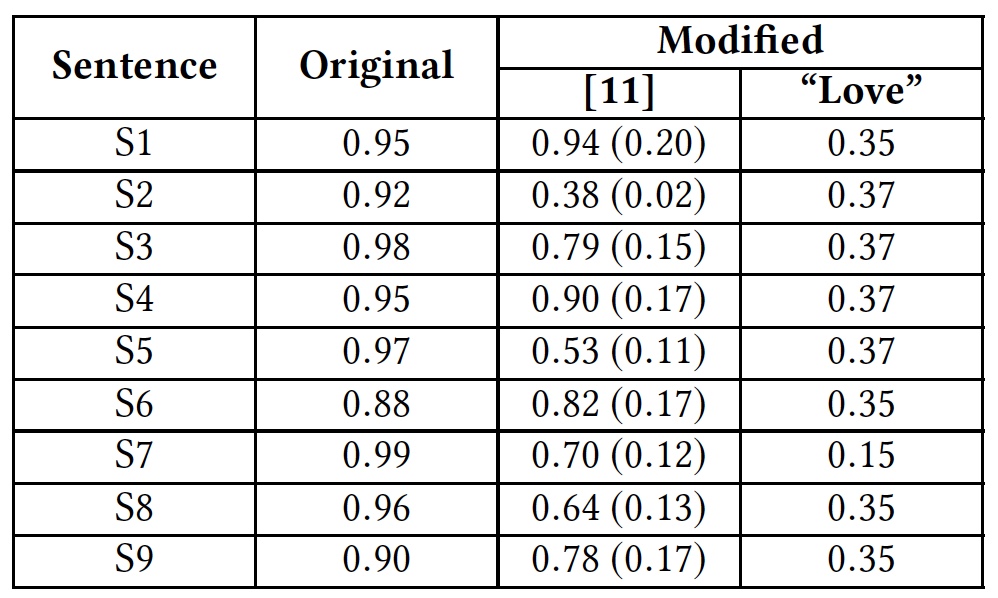 Google Perspective API: «» () .
Google Perspective API: «» () ., Google Perspective API.
,
.
, , , .
, , . ? ? , ? : , , , . , , ? C'est possible. , , . , — ?
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 ! . c Dell R730xd 5-2650 v4 9000 ?