
Ceci est le dernier article d'une série d'articles de formation pour les développeurs dans le domaine de l'intelligence artificielle. Il décrit les étapes pour créer un modèle d'apprentissage en profondeur pour la génération de musique, en choisissant le bon modèle et le prétraitement des données, et décrit les procédures de configuration, de formation, de test et de modification de BachBot.
Génération de musique - Réflexion sur une tâche
La première étape pour résoudre de nombreux problèmes à l'aide de l'intelligence artificielle (IA) consiste à réduire le problème à un problème de base qui peut être résolu au moyen de l'IA. Un de ces problèmes est la prédiction de séquence, qui est utilisée dans les applications de traduction et de traitement en langage naturel. Notre tâche de générer de la musique peut être réduite au problème de prédire une séquence, et la prédiction sera effectuée pour une séquence de notes de musique.
Sélection du modèle
Il existe plusieurs types de réseaux de neurones différents qui peuvent être considérés comme des modèles: les réseaux de neurones à distribution directe, les réseaux de neurones récurrents et les réseaux de neurones à mémoire à long terme.
Les neurones sont les éléments abstraits de base qui se combinent pour former des réseaux de neurones. Essentiellement, un neurone est une fonction qui reçoit des données en entrée et génère le résultat.
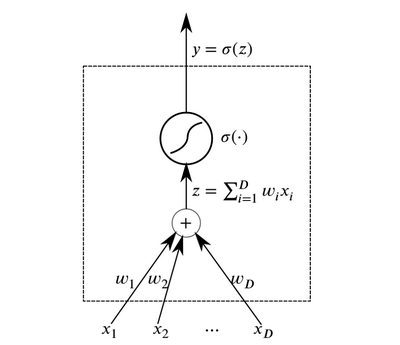 Neuron
NeuronDes couches de neurones qui reçoivent les mêmes données à l'entrée et ont des sorties connectées peuvent être combinées pour construire un
réseau neuronal à propagation directe . Ces réseaux de neurones présentent des résultats élevés en raison de la composition des fonctions d'activation non linéaires lors du passage de données à travers plusieurs couches (ce que l'on appelle le deep learning).
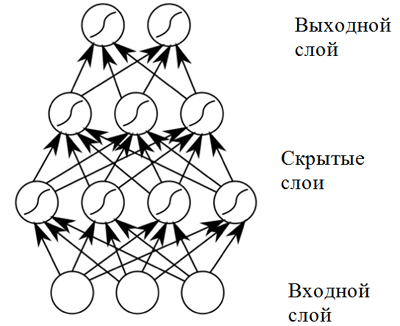 Réseau de neurones à distribution directe
Réseau de neurones à distribution directeUn réseau de neurones à distribution directe donne de bons résultats dans une large gamme d'applications. Cependant, un tel réseau neuronal présente un inconvénient qui ne permet pas de l'utiliser dans une tâche liée à la composition musicale (prédiction de séquence): il a une dimension fixe de données d'entrée, et les compositions musicales peuvent avoir des longueurs différentes. De plus,
les réseaux de neurones à distribution directe ne prennent pas en compte les entrées des pas de temps précédents, ce qui les rend peu utiles pour résoudre le problème de prédiction de séquence! Un modèle appelé
réseau neuronal récurrent est mieux adapté à cette tâche.
Les réseaux de neurones récursifs résolvent ces deux problèmes en introduisant des liens entre les nœuds cachés: dans ce cas, au pas de temps suivant, les nœuds peuvent recevoir des informations sur les données au pas de temps précédent.
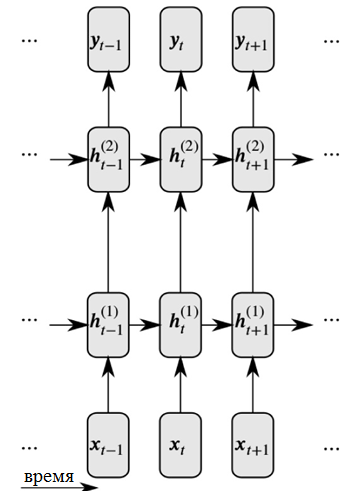 Représentation détaillée d'un réseau neuronal récurrent
Représentation détaillée d'un réseau neuronal récurrentComme vous pouvez le voir sur la figure, chaque neurone reçoit maintenant une entrée de la couche neuronale précédente et de l'heure précédente.
Les réseaux de neurones récursifs traitant de grandes séquences d'entrée rencontrent ce que l'on appelle le
problème du gradient de fuite : cela signifie que l'influence des pas de temps antérieurs disparaît rapidement. Ce problème est caractéristique de la tâche de la composition musicale, car il existe d'importantes dépendances à long terme dans les œuvres musicales qui doivent être prises en compte.
Pour résoudre le problème d'un gradient de fuite, une modification du réseau récurrent, appelé
réseau de neurones à mémoire à court terme (ou réseau de neurones LSTM), peut être utilisée . Ce problème est résolu en introduisant des cellules de mémoire, qui sont soigneusement surveillées par trois types de «portes». Cliquez sur le lien suivant pour plus d'informations:
Informations générales sur les réseaux de neurones LSTM .
Ainsi, BachBot utilise un modèle basé sur le réseau neuronal LSTM.
Prétraitement
La musique est une forme d'art très complexe et comprend diverses dimensions: hauteur, rythme, tempo, nuances dynamiques, articulation et plus encore. Pour simplifier la musique aux fins de ce projet
, seules la hauteur et la durée des sons sont prises en compte . De plus, tous les choraux ont été
transposés sur la tonalité en do majeur ou en la mineur, et les durées des notes ont été
quantifiées dans le temps (arrondies) au multiple le plus proche de la seizième note. Ces mesures ont été prises pour réduire la complexité des compositions et augmenter les performances du réseau, tandis que le contenu de base de la musique est resté inchangé. Les opérations de normalisation des tonalités et des durées des notes ont été effectuées à l'aide de la bibliothèque music21.
def standardize_key(score): """Converts into the key of C major or A minor. Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474 """
Le code utilisé pour normaliser les caractères clés dans les œuvres collectées, les clés en do majeur ou la mineur sont utilisées dans la sortieLa quantification temporelle au multiple le plus proche de la seizième note a été effectuée à l'aide de la fonction
Stream.quantize () de la bibliothèque
music21 . Voici une comparaison des statistiques associées à un ensemble de données avant et après son traitement préliminaire:
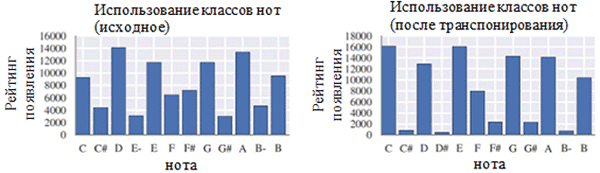 Utiliser chaque classe de notes avant (à gauche) et après le prétraitement (à droite). Une classe de notes est une note quelle que soit son octave.
Utiliser chaque classe de notes avant (à gauche) et après le prétraitement (à droite). Une classe de notes est une note quelle que soit son octave.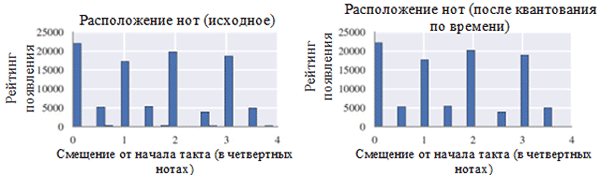 Emplacement des notes avant (à gauche) et après le prétraitement (à droite)
Emplacement des notes avant (à gauche) et après le prétraitement (à droite)Comme le montre la figure ci-dessus, la transposition de la tonalité originale des chorals à la tonalité de do majeur ou de do mineur (la mineur) a considérablement influencé la classe des notes utilisées dans les œuvres collectées. En particulier, le nombre d'occurrences de notes dans les clés dans les clés majeures (do majeur) et la mineur (la mineur) (do, mi, mi, fa, sol, a, b) a augmenté. Vous pouvez également observer de petits pics pour les notes F # et G # en raison de leur présence dans la séquence ascendante de la mélodique A mineur (A, B, C, D, E, F # et G #).
En revanche, la quantification du temps a eu un effet beaucoup plus faible. Cela peut s'expliquer par la haute résolution de quantification (similaire à l'arrondi à de nombreux chiffres significatifs).
Codage
Une fois les données prétraitées, il est nécessaire de coder les chorales dans un format qui peut être facilement traité à l'aide d'un réseau de neurones récurrent. Le format requis est une
séquence de jetons . Pour le projet BachBot, le codage a été choisi au niveau des notes (chaque token représente une note) au lieu du niveau des accords (chaque token représente un accord). Cette solution a réduit la taille du dictionnaire de 128
4 accords possibles à 128 notes possibles, ce qui a permis d'augmenter l'efficacité du travail.
Un schéma de codage original pour les compositions musicales a été créé pour le projet BachBot. Le choral est divisé en pas de temps correspondant aux doubles croches. Ces étapes sont appelées cadres. Chaque image contient une séquence de tuples représentant la valeur de la hauteur d'une note au format d'une interface d'instrument de musique numérique (MIDI) et un signe de liaison de cette note à une note précédente de la même hauteur (note, signe de reliure). Les notes dans le cadre sont numérotées par ordre décroissant de hauteur (soprano → alt → ténor → basse). Chaque trame peut également avoir une trame qui marque la fin d'une phrase; Fermata est représenté par un point (.) Au-dessus de la note. Les symboles
START et
END sont ajoutés au début et à la fin de chaque choral. Ces symboles provoquent l'initialisation du modèle et permettent à l'utilisateur de déterminer quand la composition se termine.
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
ENDUn exemple d'encodage de deux accords. Chaque accord dure un huitième temps d'une mesure, le deuxième accord est accompagné d'une ferme. La séquence "|||" marque la fin du cadre def encode_score(score, keep_fermatas=True, parts_to_mask=[]): """ Encodes a music21 score into a List of chords, where each chord is represented with a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]). If `keep_fermatas` is True, all `has_fermata`s will be False. All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`. Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames. """ encoded_score = [] for chord in (score .quantize((FRAMES_PER_CROTCHET,)) .chordify(addPartIdAsGroup=bool(parts_to_mask)) .flat .notesAndRests):
Code utilisé pour coder la tonalité music21 à l'aide d'un schéma de codage spécialTâche de modèle
Dans la partie précédente, une explication a été donnée montrant que la tâche de composition automatique peut être réduite à la tâche de prédire une séquence. En particulier, un modèle peut prédire la prochaine note la plus probable sur la base des notes précédentes. Pour résoudre ce type de problème, un réseau de neurones avec une mémoire à court terme à long terme (LSTM) est le mieux adapté. Formellement, le modèle devrait prédire P (x
t + 1 | x
t , h
t-1 ), la distribution de probabilité pour les prochaines notes possibles (x
t + 1 ) en fonction du jeton actuel (x
t ) et de l'état caché précédent (h
t-1 ) . Fait intéressant, la même opération est effectuée par des modèles de langage basés sur des réseaux de neurones récurrents.
En mode composition, le modèle est initialisé avec le jeton
START , après quoi il sélectionne le prochain jeton le plus probable à suivre. Après cela, le modèle continue de sélectionner le prochain jeton le plus probable en utilisant la note précédente et l'état caché précédent jusqu'à ce qu'un jeton END soit généré. Le système contient des éléments de température qui ajoutent un certain degré d'aléatoire pour empêcher BachBot de composer la même pièce encore et encore.
Fonction de perte
Lors de la formation d'un modèle pour la prédiction, il existe généralement une fonction qui doit être minimisée (appelée fonction de perte). Cette fonction décrit la différence entre la prédiction du modèle et la propriété de vérité terrain. BachBot minimise la perte d'entropie croisée entre la distribution prédite (x
t + 1 ) et la distribution réelle de la fonction objectif. L'utilisation de l'entropie croisée comme fonction de perte est un bon point de départ pour un large éventail de tâches, mais dans certains cas, vous pouvez utiliser votre propre fonction de perte. Une autre approche acceptable consiste à essayer d'utiliser diverses fonctions de perte et à appliquer un modèle qui minimise la perte réelle lors de la vérification.
Formation / tests
Lors de la formation d'un réseau neuronal récursif, BachBot a utilisé la correction de jeton avec la valeur x
t + 1 au lieu d'appliquer la prédiction du modèle. Ce processus, connu sous le nom d'apprentissage obligatoire, est utilisé pour assurer la convergence, car les prédictions du modèle produiront naturellement de mauvais résultats au début de la formation. En revanche, lors de la validation et de la composition, la prédiction du modèle x
t + 1 doit être réutilisée comme entrée pour la prochaine prédiction.
Autres considérations
Pour augmenter l'efficacité de ce modèle, les méthodes pratiques suivantes, communes aux réseaux de neurones LSTM, ont été utilisées: troncature de gradient normalisée, méthode d'élimination, normalisation des paquets et méthode de propagation par erreur temporelle tronquée (BPTT).
La méthode de troncature de gradient normalisée élimine le problème de croissance incontrôlée de la valeur de gradient (l'inverse du problème de gradient de fuite, qui a été résolu en utilisant l'architecture des cellules de mémoire LSTM). En utilisant cette technique, les valeurs de gradient qui dépassent un certain seuil sont tronquées ou mises à l'échelle.
La méthode d'exclusion est une technique dans laquelle certains neurones
sélectionnés au hasard sont déconnectés (exclus) lors de la formation du réseau. Cela évite le sur-ajustement et améliore la qualité de la généralisation. Le problème du surajustement se pose lorsque le modèle est optimisé pour l'ensemble de données d'apprentissage et, dans une moindre mesure, applicable pour des échantillons en dehors de cet ensemble. La méthode d'exclusion aggrave souvent la perte pendant la formation, mais l'améliore au stade de la vérification (voir ci-dessous).
Le calcul du gradient dans un réseau neuronal récurrent pour une séquence de 1000 éléments est équivalent en coût aux passages avant et arrière dans le réseau neuronal à distribution directe de 1000 couches.
La méthode de
propagation de retour d'erreur tronquée (BPTT) dans le temps est utilisée pour réduire le coût de mise à jour des paramètres pendant la formation. Cela signifie que les erreurs ne se propagent que pendant un nombre fixe de pas de temps comptés à partir du moment actuel. Veuillez noter que les dépendances d'apprentissage à long terme sont toujours possibles avec la méthode BPTT, car les états latents ont déjà été révélés à de nombreux pas de temps précédents.
Paramètres
Voici une liste de paramètres pertinents pour les modèles de réseaux de neurones récurrents / réseaux de neurones avec une mémoire à court terme:
- Le nombre de couches . L'augmentation de ce paramètre peut augmenter l'efficacité du modèle, mais il faudra plus de temps pour le former. De plus, trop de couches peuvent entraîner un sur-ajustement.
- La dimension de l'état latent . L'augmentation de ce paramètre peut augmenter la complexité du modèle, mais cela peut entraîner un sur-ajustement.
- Dimension des comparaisons vectorielles
- La longueur de la séquence / le nombre de trames avant de tronquer la propagation inverse de l'erreur dans le temps.
- Probabilité d'exclusion des neurones . La probabilité avec laquelle un neurone sera exclu du réseau au cours de chaque cycle de mise à jour.
La méthodologie de sélection de l'ensemble optimal de paramètres sera discutée plus loin dans cet article.
Implémentation, formation et tests
Sélection de la plateforme
Actuellement, il existe de nombreuses plates-formes qui vous permettent d'implémenter des modèles d'apprentissage automatique dans différents langages de programmation (y compris même JavaScript!). Les plates-formes populaires incluent
scikit-learn ,
TensorFlow et
Torch .
La bibliothèque Torch a été choisie comme plate-forme pour le projet BachBot. Au début, la bibliothèque TensorFlow a été essayée, mais à cette époque, elle utilisait de vastes réseaux de neurones récurrents, ce qui a entraîné un débordement de la RAM du GPU. Torch est une plate-forme de calcul scientifique propulsée par le langage de programmation rapide LuaJIT *. La plate-forme Torch contient d'excellentes bibliothèques pour travailler avec les réseaux de neurones et l'optimisation.
Mise en œuvre du modèle et formation
L'implémentation variera évidemment en fonction de la langue et de la plateforme sur lesquelles vous choisirez. Pour savoir comment BachBot implémente des réseaux de neurones avec une mémoire à long terme et à court terme à l'aide de Torch, consultez les scripts utilisés pour entraîner et définir les paramètres de BachBot. Ces scripts sont disponibles sur le site Web de
Feynman Lyang GitHub.Un bon point de départ pour naviguer dans le référentiel est le
script 1-train.zsh . Avec lui, vous pouvez trouver le chemin d'accès au fichier
bachbot.py .
Plus précisément, le script principal pour définir les paramètres du modèle est le fichier
LSTM.lua . Le script de formation du modèle est le fichier
train.lua .
Optimisation hyperparamétrique
Pour rechercher les valeurs optimales des hyperparamètres, la méthode de recherche de grille a été utilisée en utilisant la grille de paramètres suivante.
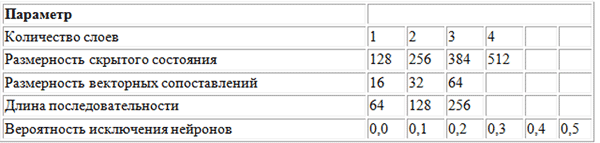 Grille de paramètres utilisée par BachBot dans la recherche de grille
Grille de paramètres utilisée par BachBot dans la recherche de grilleUne recherche dans la grille est une recherche complète de toutes les combinaisons possibles de paramètres. D'autres méthodes suggérées pour optimiser les hyperparamètres sont la recherche aléatoire et l'optimisation bayésienne.
L'ensemble optimal d'hyperparamètres détectés à la suite d'une recherche dans la grille est le suivant: nombre de couches = 3, dimension de l'état caché = 256, dimension des comparaisons vectorielles = 32, longueur de séquence = 128, probabilité d'élimination des neurones = 0,3.
Ce modèle a atteint une perte d'entropie croisée de 0,324 pendant l'entraînement et de 0,477 au stade de la vérification. Le graphique de la courbe d'apprentissage montre que le processus d'apprentissage converge après 30 itérations (≈28,5 minutes lors de l'utilisation d'un seul GPU).
Les graphiques de perte pendant l'entraînement et pendant la phase de vérification peuvent également illustrer l'effet de chaque hyperparamètre. La probabilité d'éliminer les neurones nous intéresse particulièrement:
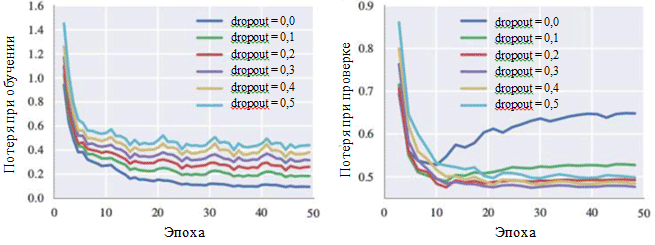 Courbes d'apprentissage pour divers paramètres de méthode d'exclusion
Courbes d'apprentissage pour divers paramètres de méthode d'exclusionOn peut voir sur la figure que la méthode d'élimination évite vraiment l'apparition de sur-ajustement. Bien qu'avec une probabilité d'exclusion de 0,0, la perte pendant l'entraînement est minime, au stade de la vérification, la perte a une valeur maximale. Des valeurs de probabilité élevées entraînent une augmentation des pertes lors de la formation et une diminution des pertes au stade de la vérification. La valeur minimale de la perte lors de la phase de vérification lors de l'utilisation de BachBot a été fixée avec une probabilité d'exception de 0,3.
Méthodes d'évaluation alternatives (facultatif)
Pour certains modèles - en particulier pour les applications créatives telles que la composition de musique - la perte peut ne pas être une mesure appropriée du succès du système. Au lieu de cela, la perception humaine subjective peut être le meilleur critère.
Le but du projet BachBot est de composer automatiquement une musique qui ne se distingue pas des propres compositions de Bach. Pour évaluer le succès des résultats, une enquête auprès des utilisateurs sur Internet a été réalisée. L'enquête a pris la forme d'un concours dans lequel les utilisateurs étaient invités à déterminer quelles œuvres appartenaient au projet BachBot et lesquelles appartenaient à Bach.
Les résultats de l'enquête ont montré que les participants à l'enquête (759 personnes avec différents niveaux de formation) étaient en mesure de distinguer avec précision entre deux échantillons dans seulement 59 pour cent des cas. C'est seulement 9 pour cent de plus que le résultat d'une estimation aléatoire! Essayez vous-même l'
enquête BachBot !
Adapter le modèle à l'harmonisation
Maintenant, BachBot peut calculer P (x
t + 1 | x
t , h
t-1 ), la distribution de probabilité pour les prochaines notes possibles en fonction de la note actuelle et de l'état caché précédent. Ce modèle de prédiction séquentielle peut ensuite être adapté pour harmoniser la mélodie. Un tel modèle adapté est nécessaire pour harmoniser la mélodie, modulée à l'aide d'émotions, dans le cadre d'un projet musical avec diaporama.
Lorsque vous travaillez avec l'harmonisation du modèle, une mélodie prédéfinie est fournie (généralement c'est une partie soprano), et après cela, le modèle devrait composer de la musique pour le reste des morceaux. Pour accomplir cette tâche, une recherche «best-first» gourmande est utilisée avec la restriction que les notes de mélodie sont fixes. Les algorithmes gourmands impliquent des décisions optimales d'un point de vue local. Voici donc une stratégie simple utilisée pour l'harmonisation:
Supposons que x t sont des jetons dans l'harmonisation proposée. Au pas de temps t, si la note correspond à la mélodie, alors x t est égal à la note donnée. Sinon, x t est égal à la note suivante la plus probable conformément aux prédictions du modèle. Le code de cette adaptation du modèle est disponible sur le site Web de Feynman Lyang GitHub: HarmModel.lua , harmonize.lua .
Ce qui suit est un exemple d'harmonisation de la berceuse Twinkle, Twinkle, Little Star avec BachBot, en utilisant la stratégie ci-dessus.
 Harmonisation de la berceuse de Twinkle, Twinkle, Little Star avec BachBot (dans la partie soprano). Des parties d'alto, de ténor et de basse étaient également remplies de BachBot
Harmonisation de la berceuse de Twinkle, Twinkle, Little Star avec BachBot (dans la partie soprano). Des parties d'alto, de ténor et de basse étaient également remplies de BachBotDans cet exemple, la mélodie de la berceuse Twinkle, Twinkle, Little Star est donnée dans la partie soprano. Après cela, les parties d'alto, de ténor et de basse ont été remplies en utilisant BachBot en utilisant une stratégie d'harmonisation. Et
voici comment ça sonne .
Malgré le fait que BachBot a montré de bonnes performances dans l'exécution de cette tâche, il existe certaines limitations associées à ce modèle. Plus précisément, l'algorithme
ne regarde pas vers l'avant dans la mélodie et utilise uniquement la note actuelle de la mélodie et le contexte passé pour générer des notes ultérieures. Lors de l'harmonisation d'une mélodie par des personnes, ils peuvent couvrir toute la mélodie, ce qui simplifie la dérivation d'harmonisations appropriées. Le fait que ce modèle ne soit pas capable de le faire peut entraîner des
surprises en raison des restrictions d'utilisation des informations ultérieures qui provoquent des erreurs. Pour résoudre ce problème, la
recherche dite de
faisceau peut être utilisée.
Lorsque vous utilisez la recherche de faisceau, diverses lignes de mouvement sont vérifiées. Par exemple, au lieu d'en utiliser une seule, la note la plus probable, qui est actuellement en cours, quatre ou cinq notes les plus probables peuvent être considérées, après quoi l'algorithme continue son travail avec chacune de ces notes. L'examen des différentes options peut aider le modèle à se
remettre des erreurs . La recherche par faisceau est couramment utilisée dans les applications de traitement du langage naturel pour créer des phrases.
Les mélodies modulées à l'aide d'émotions peuvent désormais passer par un tel modèle d'harmonisation pour les compléter.