
Il y a un peu plus d'un an, nous avons
examiné l'application
Splunk Machine Learning Toolkit , avec laquelle vous pouvez analyser les données machine sur la plate-forme Splunk à l'aide de divers algorithmes d'apprentissage machine.
Aujourd'hui, nous voulons parler de ces mises à jour qui sont apparues au cours de la dernière année. De nombreuses nouvelles versions ont été publiées, divers algorithmes et visualisations ont été ajoutés qui permettront de faire passer l'analyse des données dans Splunk à un nouveau niveau.
De nouveaux algorithmes
Avant de parler des algorithmes, il convient de noter qu'il existe une
API ML-SPL avec laquelle vous pouvez charger n'importe quel algorithme open source de plus de 300 algorithmes Python. Cependant, pour cela, vous devez pouvoir programmer dans une certaine mesure en Python.
Par conséquent, nous ferons attention aux algorithmes qui n'étaient auparavant disponibles qu'après avoir manipulé Python, mais qui sont maintenant intégrés dans l'application et peuvent être facilement utilisés par tout le monde.
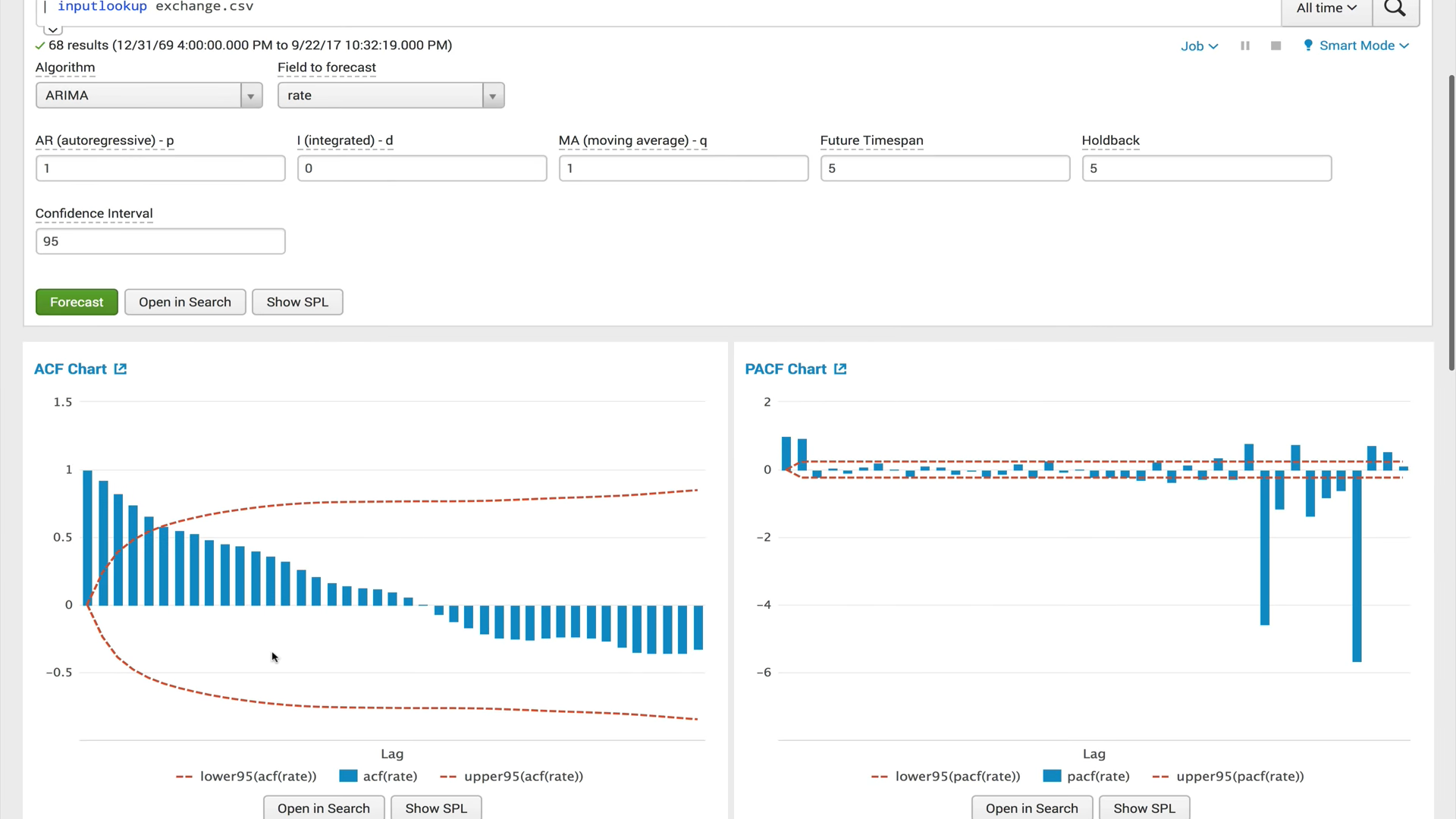
 ACF (fonction d'autocorrélation)
ACF (fonction d'autocorrélation)Une fonction d'autocorrélation montre la relation entre une fonction et sa copie décalée par la quantité de décalage temporel. ACF vous aide à trouver des sections en double ou à déterminer la fréquence du signal, caché en raison du bruit et des vibrations qui se chevauchent à d'autres fréquences.
PACF (fonction d'autocorrélation partielle)La fonction d'autocorrélation privée montre la corrélation entre les deux variables, moins l'effet de toutes les valeurs d'autocorrélation internes. L'autocorrélation privée à un certain décalage est similaire à l'autocorrélation ordinaire, mais son calcul exclut l'influence de l'autocorrélation avec des décalages plus petits. En pratique, l'autocorrélation privée fournit une image plus «nette» des dépendances périodiques.
ARIMA (processus intégré d'autorégression et de moyenne mobile)Le modèle ARIMA est l'un des modèles les plus populaires pour construire des prévisions à court terme. Les valeurs autorégressives expriment la dépendance de la valeur actuelle des séries chronologiques par rapport aux précédentes, et la moyenne mobile du modèle détermine l'effet des erreurs de prévision précédentes (également appelées bruit blanc) sur la valeur actuelle.
 Classificateur de renforcement de gradient et régresseur de renforcement de gradient
Classificateur de renforcement de gradient et régresseur de renforcement de gradientL'amplification du gradient est une méthode d'apprentissage automatique utilisée pour les problèmes de régression et de classification qui crée un modèle de prédiction sous la forme d'un ensemble de modèles faibles, généralement des arbres de décision. Il construit le modèle par étapes, lorsque chaque algorithme suivant cherche à compenser les lacunes de la composition de tous les algorithmes précédents. Initialement, le concept de boost est apparu dans les travaux en relation avec la question de savoir s'il est possible, avec de nombreux algorithmes d'apprentissage mauvais (légèrement différents de la définition aléatoire), d'en obtenir un bon. Au cours des 10 dernières années, la stimulation est restée l'une des méthodes d'apprentissage automatique les plus populaires, avec les réseaux de neurones. Les principales raisons sont la simplicité, la polyvalence, la flexibilité (la capacité de construire diverses modifications) et, surtout, une capacité de généralisation élevée.
X-moyensL'algorithme de clustering X-means est un algorithme avancé de k-means qui détermine automatiquement le nombre de clusters en fonction du critère d'information bayésien (BIC). Cet algorithme est pratique à utiliser lorsqu'il n'y a pas d'informations préliminaires sur le nombre de clusters dans lesquels ces données peuvent être divisées.
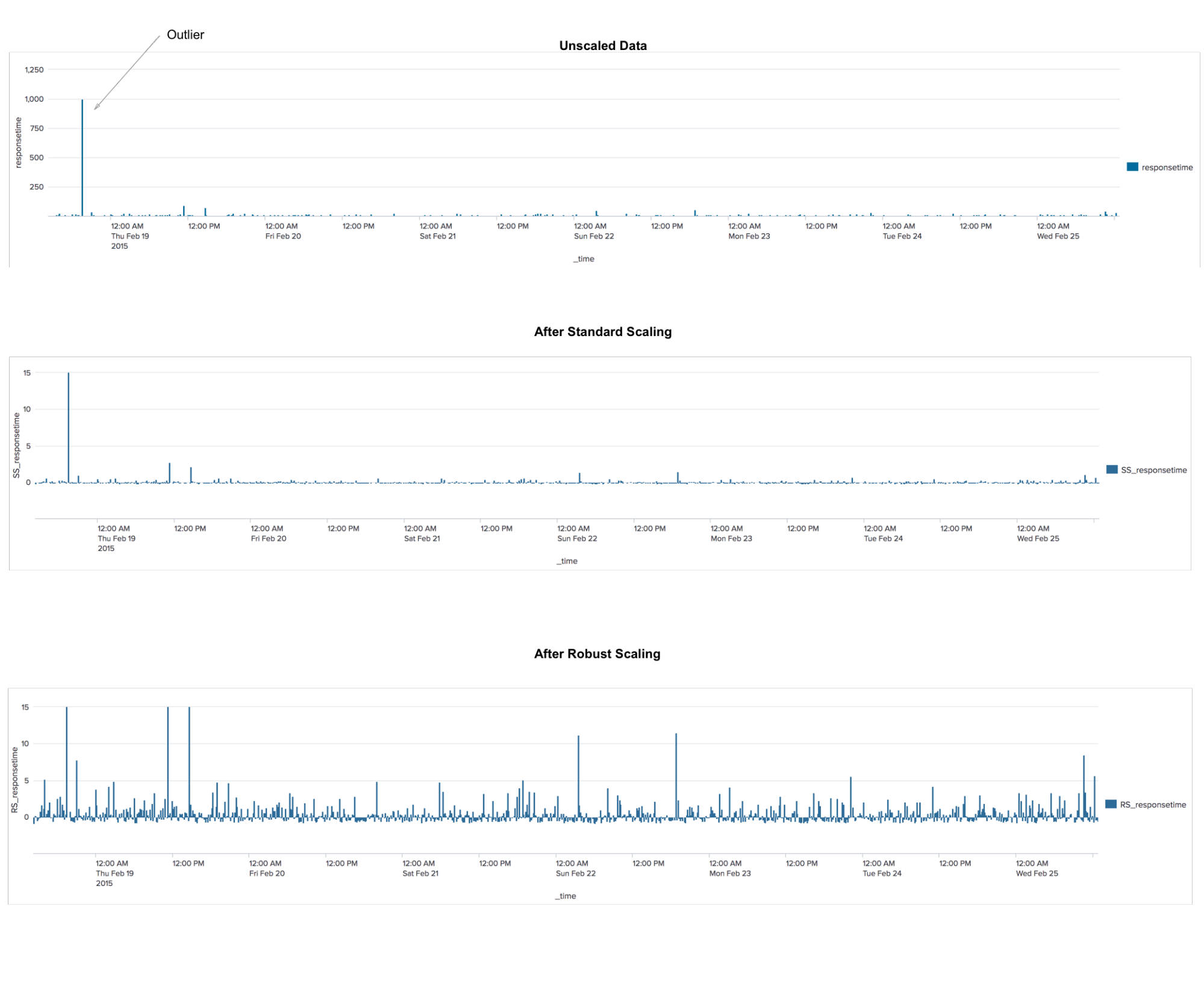
RobustscalerIl s'agit d'un algorithme de prétraitement des données. L'application est similaire à l'algorithme StandardScaler, qui transforme les données de sorte que pour chaque caractéristique, la moyenne est 0 et la variance est 1, ce qui fait que toutes les caractéristiques ont la même échelle. Cependant, cette mise à l'échelle ne garantit pas la réception de valeurs minimales et maximales spécifiques des attributs. RobustScaler est similaire à StandardScaler en ce que, du fait de son application, les fonctionnalités auront la même échelle. Cependant, RobustScaler utilise la médiane et les quartiles au lieu de la moyenne et de la variance. Cela permet à RobustScaler d'ignorer les valeurs aberrantes ou les erreurs de mesure, ce qui peut être un problème pour d'autres méthodes de mise à l'échelle.
 TFIDF
TFIDFUne mesure statistique utilisée pour évaluer l'importance d'un mot dans le contexte d'un document qui fait partie d'une collection de documents. Le principe est le suivant: si un mot est souvent trouvé dans un document, alors qu'il est rarement trouvé dans tous les autres documents, ce mot est donc d'une grande importance pour le document lui-même.
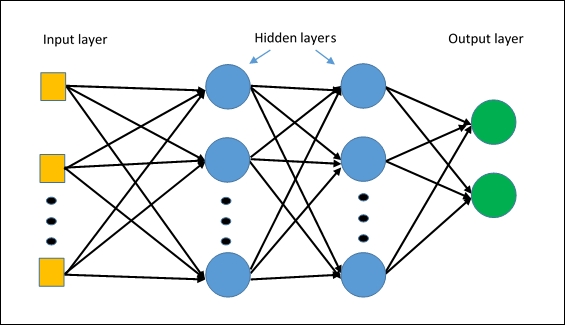
MLPClassifierLe premier algorithme de réseau neuronal de Splunk. L'algorithme est construit sur la base d'un
perceptron multicouche , qui capturera les relations non linéaires dans les données.
Administration
Dans les nouvelles versions, l'administration de l'application a considérablement changé.
Premièrement, un
modèle de rôle d'accès à divers modèles et expériences a été ajouté.
Deuxièmement, une nouvelle interface de
gestion des modèles a été introduite. Maintenant, vous pouvez facilement voir quels types de modèles vous avez, vérifier les paramètres de chaque modèle (par exemple, quelles variables ont été utilisées pour le former) et afficher ou mettre à jour les paramètres de partage pour chaque modèle.
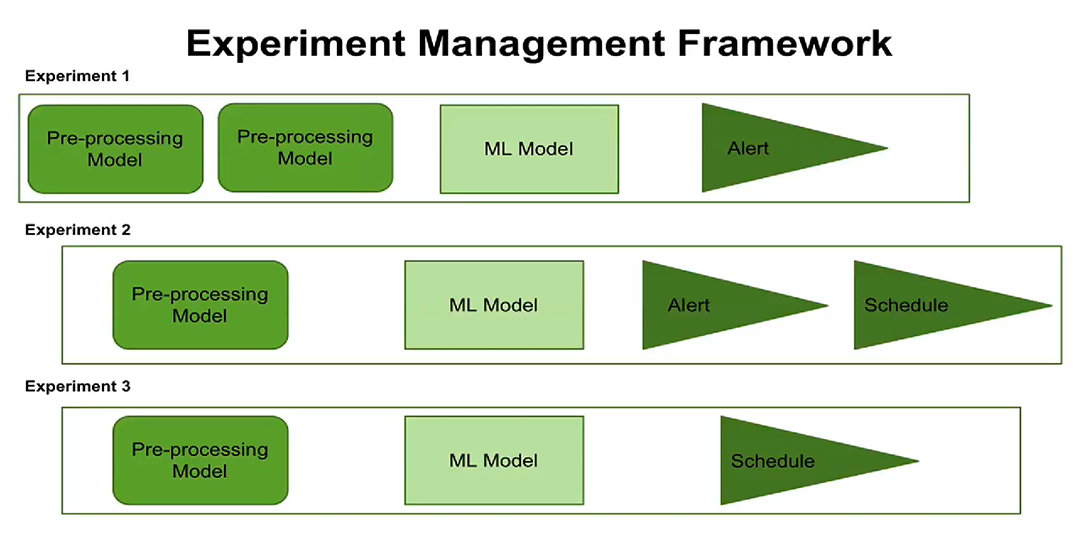
Troisièmement, l'émergence du concept de gestion de l'expérience. Vous pouvez maintenant
configurer l'exécution des expériences sur un calendrier, configurer des alertes. Les utilisateurs peuvent voir quand chaque test doit être exécuté, quelles étapes de traitement et quels paramètres sont configurés pour chaque test.
Le nouveau concept de gestion des expériences vous donne maintenant la possibilité de créer et de gérer plusieurs expériences à la fois, pour enregistrer quand ces expériences ont été effectuées et quels résultats ont été obtenus.
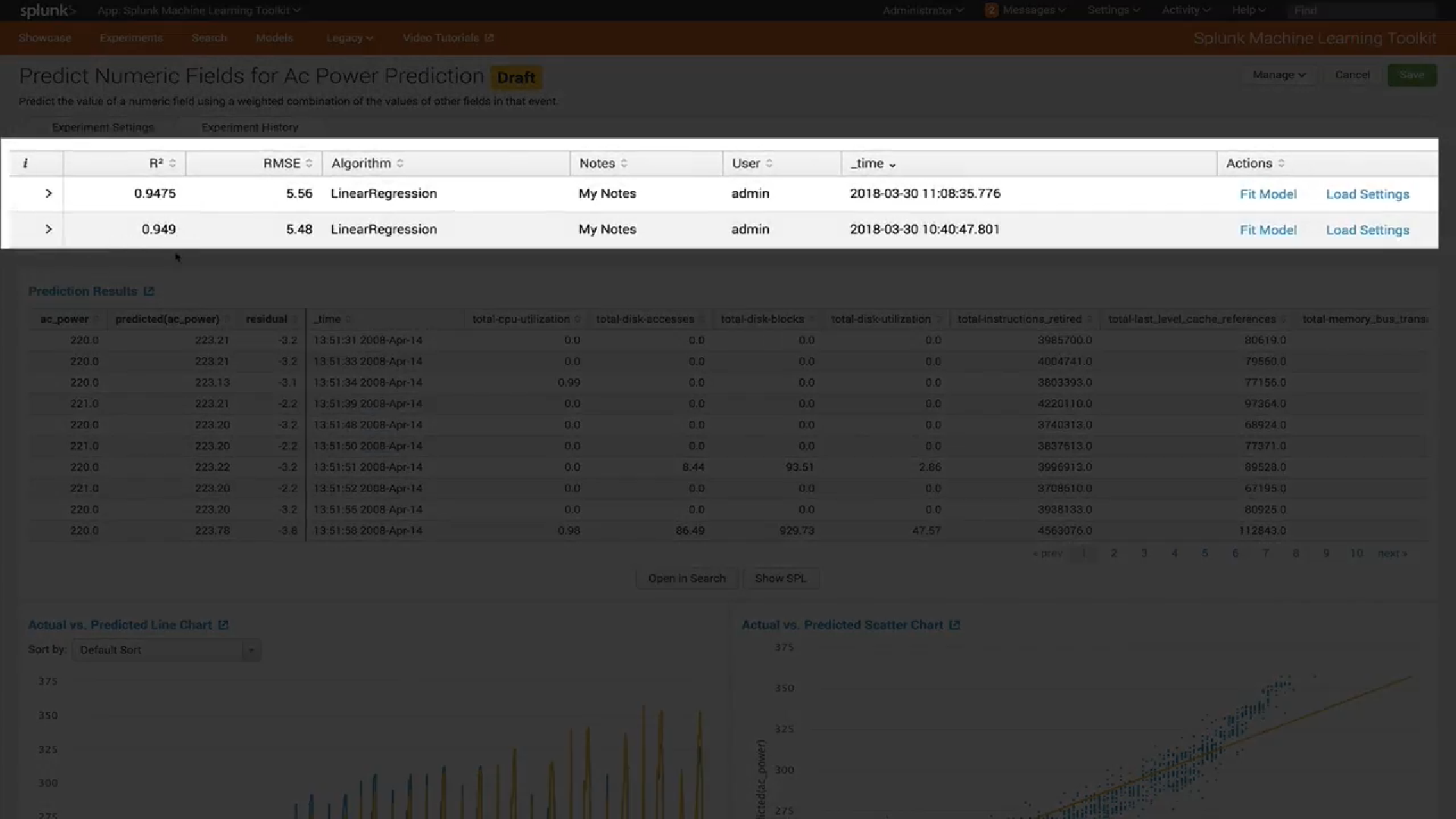
Visualisation
Dans la dernière version de MLTK 3.4, un nouveau type de visualisation a été ajouté. Le fameux
Box Plot ou, comme nous l'appelons aussi, "Boxes with a moustache".
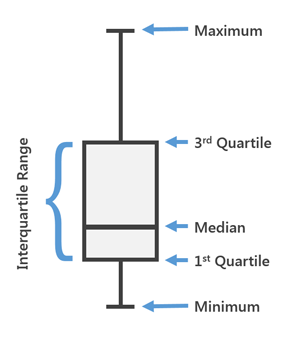
Box Plot est utilisé dans les statistiques descriptives, en l'utilisant, vous pouvez facilement voir la médiane (ou, si nécessaire, la moyenne), les quartiles inférieur et supérieur, les valeurs minimale et maximale de l'échantillon et des valeurs aberrantes. Plusieurs de ces cases peuvent être dessinées côte à côte pour comparer visuellement une distribution avec une autre. Les distances entre les différentes parties de la boîte vous permettent de déterminer le degré de dispersion (dispersion) et l'asymétrie des données et d'identifier les valeurs aberrantes.
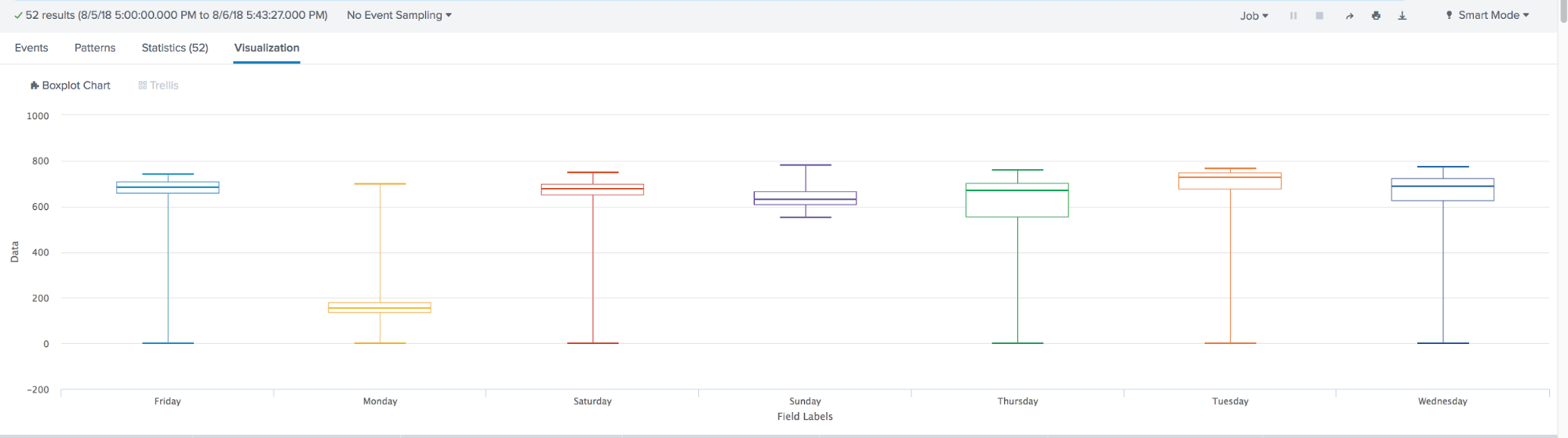
En résumé, au cours de l'année, l'apprentissage automatique chez Splunk a fait un grand pas en avant. Apparu:
- De nombreux nouveaux algorithmes intégrés, tels que: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-means, RobustScaler, TFIDF, MLPClassifier;
- Modèle d'accès basé sur les rôles et capacité de gérer des modèles et des expériences;
- Graphique de boîte de visualisation
