Ce rapport d'Alexey Milovidov, chef de l'équipe de développement ClickHouse, est un aperçu des quelques systèmes de bases de données bien connus. Certains d'entre eux sont dépassés, certains ont arrêté leur développement et sont abandonnés. Alexey attire l'attention sur des solutions architecturales intéressantes dans les exemples répertoriés, comprend leur sort et explique les exigences auxquelles votre projet open source doit répondre.
- Mon rapport portera sur les bases de données. Permettez-moi de vous demander tout de suite, quelle carte de métro apparaît sur cette diapositive? Toutes les lignes vont dans un sens.
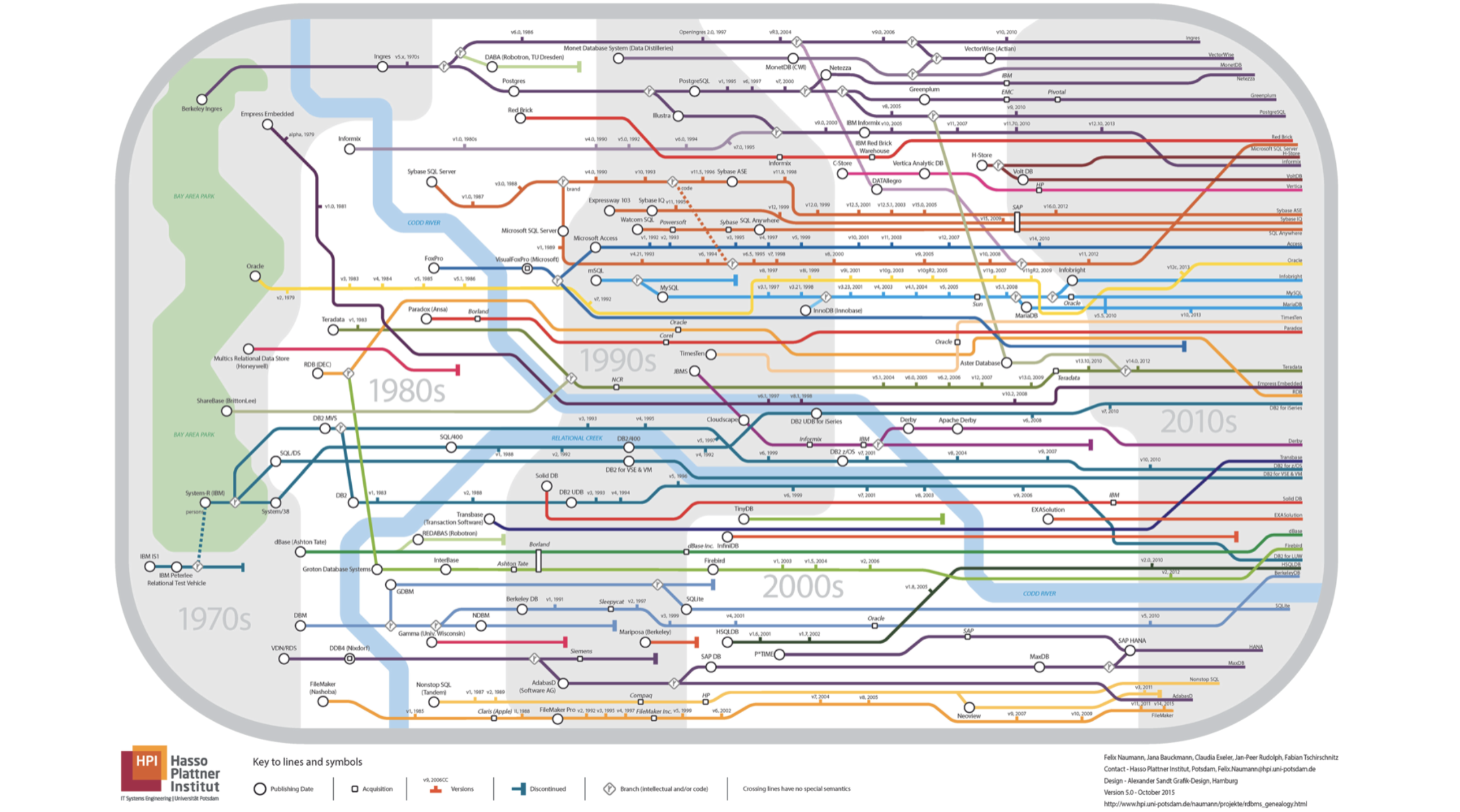
Tout va mal, ce n'est pas du tout souterrain, c'est le pedigree des bases de données relationnelles. Si vous regardez bien, vous verrez que la rivière est la rivière
Kodda .
Je n'en parlerai pas. Quoi de plus ennuyeux que de parler de MySQL, PostgreSQL ou quelque chose comme ça? Au lieu de cela, je parlerai de la création de bases de données.

Assemblage manuel. Des systèmes quasiment inconnus de personne. Ils sont conçus par une seule personne ou abandonnés depuis longtemps.

Le premier exemple est EventQL. Veuillez lever la main si vous avez déjà entendu parler de ce système. Pas une seule personne, sauf ceux qui travaillent chez Yandex et ont déjà écouté mon rapport. Ce n'est donc pas en vain que j'ai inclus ce système dans ma revue.

Il s'agit d'un moteur de base de données à colonnes réparties conçu pour le traitement et l'analyse d'événements. Il effectue des requêtes SQL très rapides, open source depuis le 26 juillet 2016, écrites en C ++, ZooKeeper est utilisé pour la coordination, il n'y a pas de dépendances en plus. Cela me rappelle quelque chose. Notre merveilleux système, tout le monde connaît déjà le nom. EventQL est quelque chose comme ClickHouse, mais en mieux. Distribué, massivement parallèle, orienté colonne, évolue en pétaoctets, demandes de portée rapide - tout est clair, nous avons tout. Prise en charge presque complète de SQL 2009, insertions et mises à jour en temps réel, distribution automatique des données à travers le cluster et même le langage ChartSQL pour décrire les graphiques. Comme c'est génial! C’est ce que nous promettons à tout le monde et ce que nous n’avons pas.
Néanmoins, le dernier commit il y a presque un an, il y a un site qui ne se charge pas, il faut regarder via web.archive.org.
Demandez sur GitHub - quels sont vos plans de développement, que se passera-t-il ensuite? Personne n'a répondu.
Le système a deux développeurs. L'un est un développeur backend, le second est un frontend. Je ne montrerai pas lequel d'entre eux devinera peut-être vous-même. Fabriqué par DeepCortex. Le nom semble familier, mais il existe de nombreuses entreprises avec le mot Deep et le mot Cortex. DeepCortex est une société inconnue de Berlin. Le système a été développé depuis 2014, il a été développé en interne pendant longtemps, puis il a été publié en open source et abandonné un an plus tard.

Cela ressemble à ceci: ils l'ont jetée en l'air et ont pensé, soudain, quelqu'un la remarquerait ou elle s'envolerait quelque part. Malheureusement non.
Un autre inconvénient est la licence AGPL, qui est relativement peu pratique. Même si cela n'impose pas de restrictions sérieuses à l'utilisation de votre entreprise, il est encore souvent redouté, le service juridique peut avoir quelques points à redire.
J'ai commencé à chercher ce qui s'est passé, pourquoi cela ne se développe pas. J'ai regardé le compte du développeur, en principe tout va bien, la personne vit, continue de valider, cependant, toutes les validations sur le référentiel privé. Ce qui s'est passé n'est pas clair.

Soit la personne a déménagé dans une autre entreprise et a perdu tout intérêt pour le soutien, soit les priorités de l'entreprise ont changé, soit certaines circonstances de la vie. Peut-être que l'entreprise elle-même ne se sentait pas très mal et que l'open source était faite juste au cas où. Ou tout simplement fatigué. Je ne connais pas la réponse exacte. Si quelqu'un le sait, dites-le moi.

Mais tout cela n'a pas été fait en vain. Tout d'abord, ChartSQL pour la description déclarative des graphiques. Maintenant, quelque chose de similaire est utilisé dans le système de visualisation de données Tabix pour ClickHouse. EventQL a un blog, cependant, il est actuellement indisponible, vous devez parcourir web.archive.org, il y a des fichiers .txt. Le système est mis en œuvre de manière très compétente, et si vous êtes intéressé, vous pouvez lire le code et voir des solutions architecturales intéressantes.
C'est tout pour elle pour l'instant. Et le prochain système gagne tout le monde, ce que je considérerai, car il a le meilleur nom, le plus délicieux. Système Alenka.
Je voulais ajouter une photo de l'emballage en chocolat, mais je crains qu'il y ait des problèmes de droits d'auteur. Qu'est-ce qu'Alenka?

Il s'agit d'un SGBD analytique qui exécute des requêtes sur des accélérateurs graphiques. Openors, licence Apache 2, 1103 étoiles, écrit en CUDA, un petit C ++, un développeur de Minsk. Il existe même un pilote JDBC. Ouverture depuis 2012. Cependant, depuis 2016, le système ne se développe plus pour une raison quelconque.

Il s'agit d'un projet personnel, pas la propriété de l'entreprise, mais vraiment un projet d'une seule personne. Il s'agit d'un tel prototype de recherche pour explorer les possibilités de traitement rapide des données sur le GPU. Il y a des tests intéressants de Mark Litvinchik, si vous êtes intéressé, vous pouvez consulter le blog. Probablement, beaucoup ont déjà vu ses tests là-bas que ClickHouse est le plus rapide.

Je n'ai aucune réponse pourquoi le système est abandonné, juste des suppositions. Maintenant, une personne travaille pour nVidia, ce n'est probablement qu'une coïncidence.

Ceci est un excellent exemple, car il augmente l'intérêt, les horizons, vous pouvez voir et comprendre comment vous pouvez le faire, comment le système peut fonctionner sur le GPU.
Mais si vous êtes intéressé par ce sujet, il existe un tas d'autres options. Par exemple, le système MapD.
Qui a entendu parler de MapD? Offenser. C'est une startup audacieuse, développant également une base de données GPU. Récemment sorti en open source sous la licence Apache 2. Je ne sais pas à quoi ça sert, bien ou vice versa. Cette startup connaît un tel succès qu'elle est déclinée en open source ou vice versa, va bientôt fermer.
Il y a un PGStorm. Si vous connaissez tous PostgreSQL, alors vous devriez entendre parler de PGStorm. Également open source, développé par une seule personne. Parmi les systèmes fermés, il y a BrytlytDB, Kinetica et la société russe Polymatic, qui fabrique le système de Business Intelligence. Analytique, visualisation et tout ça. Et pour le traitement des données, il peut aussi utiliser des accélérateurs graphiques, ça peut être intéressant à voir.

Est-il possible de faire quelque chose de plus cool qu'un GPU? Par exemple, il y avait un système qui traitait les données sur un FPGA. C'est Kickfire. Elle a livré sa solution sous forme de fer avec le logiciel immédiatement. Certes, la société a été fermée il y a longtemps, cette solution était assez chère et ne pouvait pas rivaliser avec d'autres armoires de ce type lorsqu'un fournisseur vous propose cette armoire, et tout fonctionne comme par magie.
De plus, il existe des processeurs qui contiennent des instructions pour accélérer SQL - SQL in Silicon dans les nouveaux modèles de processeur SPARC. Mais vous n'avez pas besoin de penser que vous écrivez Join dans Assembler, ce n'est pas là. Il existe des instructions simples qui effectuent la décompression en utilisant des algorithmes simples et un peu de filtrage. En principe, il peut non seulement accélérer SQL. Par exemple, les processeurs Intel disposent d'un ensemble d'instructions SSE 4.2 pour le traitement des chaînes. Lorsqu'il est apparu en 2008, le site Web d'Intel avait un article intitulé «Utilisation de nouvelles instructions de processeur Intel pour accélérer le traitement XML». C'est à peu près la même chose ici. Des instructions utiles pour accélérer une base de données peuvent également être utilisées.
Une autre option très intéressante consiste à transférer partiellement la tâche de filtrage des données sur SSD. Maintenant, les SSD sont devenus assez puissants, c'est un petit ordinateur avec un contrôleur, et vous pouvez essentiellement y télécharger votre code si vous essayez vraiment. Vos données seront lues à partir du SSD, mais elles seront filtrées immédiatement et transféreront uniquement les données nécessaires à votre programme. Très cool, mais tout cela est encore au stade de la recherche. Voici un article sur VLDB, lisez.
De plus, un certain ViyaDB.

Il a été ouvert il y a tout juste un mois. "Base de données analytique pour les données non triées." Pourquoi «non trié» est mis dans le nom, on ne sait pas pourquoi mettre un tel accent. Quoi, dans d'autres bases de données uniquement avec celles triées, pouvez-vous travailler?
Tout va bien, le code source sur GitHub, licence Apache 2.0, écrit en C ++ le plus moderne, tout va bien. Un développeur, mais rien.

Ce que j'ai le plus aimé, où vous pouvez prendre un exemple, c'est l'excellente préparation au lancement. Par conséquent, je suis surpris que personne n'ait entendu parler. Il y a un site merveilleux, il y a de la documentation, il y a un article sur Habré, il y a un article sur Medium, LinkedIn, Hacker News. Et alors? Tout cela est-il vain? Vous n'avez regardé rien de tout cela. Ici, ils disent, Habr n'est pas un gâteau. Eh bien, peut-être, mais c'est une bonne chose.
À quoi ressemble ce système?

Données en RAM, le système fonctionne avec des données agrégées. La pré-agrégation est en cours. Système de requêtes analytiques. Il existe une prise en charge SQL initiale, mais elle commence tout juste à être développée, au départ, les requêtes devaient être écrites dans une sorte de JSON. Parmi les fonctionnalités intéressantes, vous lui faites une demande, et il écrit du code pour C ++ dans votre demande elle-même, ce code est généré, compilé, chargé dynamiquement et traite vos données. Comment votre demande serait-elle traitée de la manière la plus optimale possible? Code C ++ idéalement spécialisé écrit pour votre demande. Il y a une mise à l'échelle et Consul est utilisé pour la coordination. C'est aussi un plus, comme vous le savez, il fait plus frais que ZooKeeper. Ou pas. Je ne suis pas sûr, mais il semble que oui.
Certaines des prémisses à partir desquelles ce système procède sont quelque peu contradictoires. Je suis un grand passionné de diverses technologies et je ne veux gronder personne. C'est juste mon opinion, peut-être que je me trompe.
La prémisse est que pour enregistrer constamment de nouvelles données dans le système, y compris rétroactivement, il y a une heure, il y a un jour, un événement il y a une semaine. Et en même temps, exécutez immédiatement des requêtes analytiques sur ces données.

L'auteur affirme que pour cela, le système doit nécessairement être en mémoire. Ce n'est pas le cas. Si vous êtes intéressé par pourquoi, vous pouvez lire l'article «Evolution des structures de données dans Yandex.Metrica». Une personne dans la pièce lisait.
Il n'est pas nécessaire de stocker des données dans la RAM. Je ne dirai pas ce qui doit être fait et quel système installer si vous souhaitez résoudre ce problème.

À quoi pouvez-vous apprendre? Une solution architecturale intéressante est la génération de code en C ++. Si vous êtes intéressé par ce sujet, vous pouvez prêter attention à un tel projet de recherche DBToaster. EPFL Institute Research, disponible sur GitHub, Apache 2.0. Code Scala, vous y donnez une requête SQL, ce code génère pour vous des sources C ++, qui liront et traiteront les données quelque part de la manière la plus optimale. Probablement, mais pas sûr.

Ce n'est qu'une approche pour la génération de code, pour le traitement des requêtes. Il existe une approche encore plus populaire - la génération de code LLVM. L'essentiel est que votre programme, pour ainsi dire, écrit dynamiquement du code dans Assembler. Eh bien, pas vraiment, sur LLVM. Il y a MemSQL comme exemple. Il s'agit à l'origine d'une base de données OLTP, mais elle convient également parfaitement à l'analyse. Fermé, propriétaire, C ++ y était à l'origine utilisé pour la génération de code. Ensuite, ils sont passés à LLVM. Pourquoi? Vous avez écrit du code C ++, vous devez le compiler et cela prend cinq secondes précieuses pour ce faire. Et bien, si vos demandes sont plus ou moins les mêmes, vous pouvez générer le code une fois. Mais en matière d'analyse, vous avez là des demandes ad hoc, et il est fort possible qu'à chaque fois, elles ne soient pas seulement différentes, mais aient même une structure différente. Si la génération de code est sur LLVM, cela prend des millisecondes ou des dizaines de millisecondes, différemment, parfois plus.
Un autre exemple est Impala. Utilise également LLVM. Mais si nous parlons de ClickHouse, il y a aussi de la génération de code, mais ClickHouse repose principalement sur le traitement des requêtes vectorielles. Un interprète, mais qui fonctionne sur des tableaux, il fonctionne donc très rapidement, comme des systèmes comme kdb +.
Un autre exemple intéressant. Le meilleur logo de ma critique.

Le premier et le seul système de gestion de bases de données open source relationnelles conçu spécifiquement pour l'entreposage de données et l'intelligence d'affaires. Disponible sur GitHub, la licence Apache 2. Auparavant, il y avait une GPL, mais elle a été modifiée et correctement effectuée. Il est écrit en Java. Dernier engagement il y a six ans. Initialement, le système a été développé par l'organisation à but non lucratif Eigenbase, l'objectif de l'organisation était de développer un cadre, une base de code extensible au maximum pour les bases de données qui ne sont pas seulement OLTP, mais par exemple, une pour l'analyse, LucidDB lui-même et l'autre StreamBase pour le traitement des données en streaming.

Que s'est-il passé il y a six ans? Bonne architecture, base de code bien extensible, plus d'un développeur. Grande documentation. Rien ne se charge maintenant, mais vous pouvez le voir via WebArchive. Excellent support SQL.

Mais quelque chose ne va pas. L'idée est bonne, mais cela a été fait par une organisation à but non lucratif pour certains dons, et quelques startups étaient à proximité. Pour une raison quelconque, tout était courbé. Ils n'ont pas pu trouver de financement, il n'y avait pas de passionnés et toutes ces startups ont fermé il y a longtemps.
Mais pas si simple. Tout cela n'a pas été vain.

Il existe un tel cadre - Apache Calcite. Il s'agit d'une sorte de frontend pour les bases de données SQL. Il peut analyser les requêtes, analyser, effectuer toutes sortes de transformations d'optimisation, élaborer un plan d'exécution des requêtes et fournir un pilote JDBC prêt à l'emploi.
Imaginez que vous vous réveilliez soudainement, que vous étiez de bonne humeur et que vous ayez décidé de développer votre SGBD relationnel. On ne sait jamais, ça arrive. Maintenant, vous pouvez prendre Apache Calcite, il vous suffit d'ajouter le stockage de données, la lecture des données, le traitement des requêtes, la réplication, la tolérance aux pannes, le partage, tout est simple. Apache Calcite est basé sur la base de code LucidDB, qui était un système si avancé qu'ils en ont pris tout le frontend, qui est maintenant utilisé sous une forme légèrement adaptée dans presque tous les produits Apache, Hive, Drill, Samza, Storm et même MapD, malgré le fait que il est écrit en C ++, en quelque sorte connecté ce code en Java.

Tous ces systèmes intéressants utilisent Apache Calcite.
Le système suivant est InfiniDB. De ces noms étourdi.

Il y avait Calpont, à l'origine InfiniDB, un système propriétaire, et c'est ainsi que les directeurs des ventes ont contacté notre entreprise et nous ont vendu ce système. C'était intéressant d'y participer. Ils disent qu'un SGBD analytique, merveilleux, plus rapide que Hadoop, orienté colonne, naturellement, toutes les requêtes fonctionneront rapidement. Mais alors, ils n'avaient pas de cluster, le système n'était pas évolutif. Je dis qu'il n'y a pas de cluster - nous ne pouvons pas acheter. Je regarde, après six mois, la version d'InfiniDB 4.0 est sortie, nous avons ajouté l'intégration avec Hadoop, la mise à l'échelle, tout va bien.
Six mois se sont écoulés et le code source est disponible en open source. J'ai alors pensé à quoi j'étais assis, à développer quelque chose, nous devons le prendre, il y a quelque chose de prêt.
Ils ont commencé à chercher comment s'adapter, utiliser. Un an plus tard, l'entreprise a fait faillite. Mais le code source est disponible.
C'est ce qu'on appelle l'open source post mortem. Et c'est bien. Si une entreprise ne se sent pas très bien, il est nécessaire qu’au moins un héritage demeure, pour que d’autres puissent l’utiliser.

C'était en vain. Basé sur la source InfiniDB, MariaDB dispose désormais d'un moteur de table appelé ColumnStore. En fait, c'est InfiniDB. L'entreprise n'est plus là, les gens travaillent maintenant ailleurs, mais l'héritage demeure et c'est merveilleux. Tout le monde connaît MariaDB. Si vous l'utilisez et que vous devez fixer rapidement le moteur analytique orienté colonne, vous pouvez utiliser ColumnStore. En secret, je dirai que ce n'est pas la meilleure solution. Si vous avez besoin de la meilleure solution, vous savez à qui vous adresser et quoi utiliser.
Un autre système avec le mot Infini dans le nom. Ils ont un logo étrange, cette ligne semble pliée. Et une autre police incompréhensible, pour une raison quelconque, il n'y a pas d'anticrénelage, comme s'il était peint dans Paint. Et toutes les lettres sont grosses, probablement pour intimider les concurrents.

Je suis un passionné de toutes sortes de technologies, très respectueux de toutes sortes de solutions intéressantes. Je ne plaisante pas, pas besoin de réfléchir.
À quoi ressemblait ce système? Ce n'est plus un système analytique, c'est OLTP. Un système de traitement des transactions à des échelles extrêmes. Il existe un site, les avantages de ce système est que le site se charge. Parce que quand je regarde tous les autres, je suis habitué au fait qu'il y aura un parking de domaine ou autre chose. Les sources sont disponibles. Maintenant la GPL. C'était AGPL, mais heureusement, l'auteur l'a rapidement changé. Écrit en C ++, plus d'un développeur, posté en open source en novembre 2013, et déjà abandonné en janvier 2014. Un mois et demi. Pourquoi? À quoi ça sert? Pourquoi faire ça?

Base de données OLTP avec support SQL initial, un projet personnel, aucune entreprise n'est derrière. L'auteur lui-même à Hackers News dit qu'il a publié en open source dans l'espoir d'attirer des passionnés qui travailleront sur ce produit.

Cet espoir est toujours voué à l'échec. Vous avez une idée, vous êtes génial, vous êtes passionné. Vous devez donc faire cette idée. Il est peu probable que quelqu'un d'autre s'en inspire. Ou vous devrez travailler dur pour inspirer quelqu'un. Il est donc difficile d'espérer que de nulle part à l'autre bout du monde, une personne apparaîtra qui commencera à ajouter le code de quelqu'un d'autre sur GitHub.
Deuxièmement, peut-être simplement sous-estimer la complexité. Le développement d'un SGBD n'est pas une aventure de 20 minutes. C'est difficile, long, cher.
Il s'agit d'un cas très intéressant, beaucoup ont entendu RethinkDB. Cet exemple n'est pas une base analytique, pas OLTP, mais orientée document.

Ce système a changé son concept à plusieurs reprises. Repensé. Disons qu'en 2011, il a été écrit qu'il s'agit d'un moteur pour MySQL, qui est cent fois plus rapide sur SSD, comme il a été écrit sur le site officiel. Ensuite, il a été dit qu'il s'agissait d'un système avec protocole memcached, également optimisé pour SSD. Et après un certain temps, c'est une base de données pour les applications en temps réel. Autrement dit, afin de vous abonner aux données et de recevoir des mises à jour directement en temps réel. Disons toutes sortes de chats interactifs, de jeux en ligne. Une tentative de trouver une niche. -, JSON. MongoDB. . MongoDB , ? MongoDB . , , «PostgreSQL ».
? — . . , .
RethinkDB? , RAFT. , , , . JSON, - LINQ . ReQL, ++, , ++.

. . , , , , . , , . 20938 GitHub. - .

, , , , , . Pourquoi? Qu'est-ce qui ne va pas?

, 2009 , , , . , , 2016 . , , , . , , RethinkDB, , , The Linux Foundation. AGPL Apache 2, . , — .

, , , , , , . , .
, , . , - , , , , .
. , , . , XML 15 .
- , 2000-, . , XML . - - , . , .

, Sedna. XML , . , . , . , Sedna, , , , . , .
2013, , . XML , , .
— .
— , , . garret.ru, , . , . , , , . .

. 2014 — IMCS, PostgreSQL, . PostgreSQL, SQL, , . select, . -, . , , , . , . , , , - . , .
, - ? .

, , ? , — . : , - , . , . .
— . , , . , , .
— . , -. - , — , , , -.
, , , .
— , ? , - .
, , . . , , , .
— - - . -, KPHP.
— . , , , .

, , : , , , ? — . , . , . ? : , .
. , , . , .
. , - , , multimodel DB, , , OLTP, , , , . , ? , , - . - -, , , , . , .
Support fiable de la société mère. Il n'y a aucun commentaire. Pas une licence restrictive, pour que les autres entreprises ne fassent pas peur au service juridique, ces gens ont peur de tout. Les avantages de votre système doivent provenir de raisons fondamentales. Disons que si vous avez une base de données pour le traitement XML, ce n'est pas très bien. Peut-être que personne d'autre n'a besoin de stocker des données en XML. Et si vous avez une base de données orientée document, c'est une autre. Tout le monde a besoin de conserver des documents, quoi qu'il en soit. De plus, le soutien au développement communautaire est très important pour une bonne source ouverte. Cela signifie non seulement que vous devez conserver les demandes d'extraction. Cela signifie - vous avez besoin que les gens sentent que vous êtes, vous existez, répondez aux questions, le produit se développe. C'est ce qui fera une bonne source open source. C'est tout, merci.