Il y a quelques mois, dans l'une des rétrospectives, nous avons décidé d'essayer de lire ensemble.
Notre format:
- Choisissez un livre.
- Nous déterminons la partie à lire en une semaine. Choisissez un petit volume.
- Vendredi, nous discutons de ce que nous lisons.
- Nous lisons pendant les heures non travaillées, discutons pendant les heures de travail.
- Après avoir terminé le livre, nous choisissons conjointement les éléments suivants.
Ce qui donne:
- Motivation à lire et à lire.
- Développement des compétences (y compris pour l'avenir).
- Alignement des mentalités et de la terminologie au sein d'une équipe.
- La croissance de la confiance.
- Une autre raison de parler.
L'un des livres récents que nous lisons est
Designing Data-Intensive Applications . Oui, ce même livre avec un porc. Et tout le monde a tellement aimé ce livre que j'ai décidé de le relire ici afin que plus de gens le lisent.
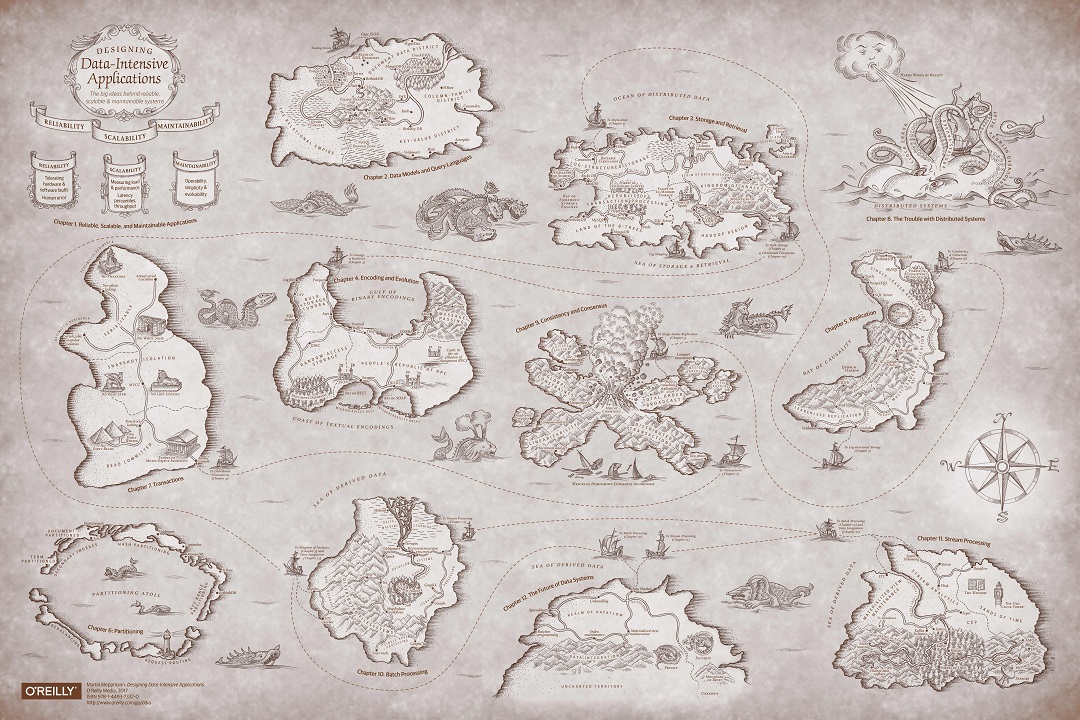 Carte en qualité originale
Carte en qualité originaleIl y a une traduction de ce livre en russe de l'éditeur Peter. Mais nous lisons dans l'original, donc je ne promets pas que les traductions des termes correspondront. De plus, nous n'avons délibérément pas traduit une partie des termes.
La première partie de l'ouvrage est consacrée aux bases des systèmes informatiques.
Le premier chapitre indique que les propriétés importantes de ces systèmes sont la fiabilité, l'évolutivité et la facilité de maintenance.
Le deuxième chapitre décrit différents modèles de données. Le SGBD relationnel et documentaire habituel, ainsi que les bases de données de graphiques et de colonnes moins connus sont décrits.
Les premiers chapitres sont à jour, établissent la portée du livre. Dans de nombreux endroits ci-dessous, l'auteur fait référence aux premiers chapitres. En toute justice, nous pouvons dire que le livre est plein de renvois.
Ce qui est surprenant dès les premiers chapitres, c'est le nombre de sources (il y a une bibliographie après chaque chapitre). Des liens vers des dizaines d'articles (blogues et scientifiques) et des livres sont scrupuleusement disposés dans tous les chapitres. Le nombre de sources pour certains chapitres dépasse la centaine.
Le troisième chapitre commence par le code source du magasin de valeurs-clés le plus simple:
Cela fonctionnera même, très bien en écriture, mais, bien sûr, non sans problèmes de lecture.
Et immédiatement, des options d'amélioration des performances sont proposées. Décrit les index de hachage, SSTable, b-tree et LSM-tree. Tout cela est expliqué sur les doigts, mais on montre comment telle ou telle structure est utilisée dans les bases de données familières.
Se concentrer sur la pratique est une autre caractéristique du livre. La plupart des exemples et des recettes sont si pratiques que je suis tombé sur presque tout ce qui est pertinent.
Le
quatrième chapitre décrit l'encodage: du JSON et XML standard à Protobuf et AVRO. Nous ne choisissons pas toujours le format consciemment, il est généralement imposé par l'une ou l'autre technologie dans son ensemble. Mais c'est cool de comprendre comment ça marche à l'intérieur, quelles sont les forces et les faiblesses du format.
L'auteur n'a pas utilisé spécifiquement le terme sérialisation, car ce terme a un sens de plus dans les bases de données.
Le contenu des chapitres est beaucoup plus riche que ma brève présentation. La première partie décrit également les différences entre OLTP et OLAP, comment la recherche en texte intégral et la recherche dans les bases de données de colonnes, REST et les courtiers de messages sont organisées.
La deuxième partie du livre parle des systèmes de traitement de données distribués. Presque tous les systèmes modernes qui sont plus ou moins chargés ont plusieurs répliques ou sous-systèmes (microservices).
Lorsque nous avons commencé à pratiquer la lecture ensemble, nous avons simplement discuté de nos notes, de nos endroits intéressants et de nos pensées. À un moment donné, nous avons réalisé que nous n'avions tout simplement pas assez de conversations, après discussion, tout est rapidement oublié. Ensuite, nous avons décidé de renforcer notre pratique et avons ajouté un remplissage de carte mentale. L'innovation avait juste ce livre. À partir de la deuxième partie, nous avons commencé à maintenir une carte mentale pour chaque chapitre. Par conséquent, chaque chapitre se poursuivra avec notre carte mentale. Nous avons utilisé coggle.it
Le cinquième chapitre décrit la réplication.
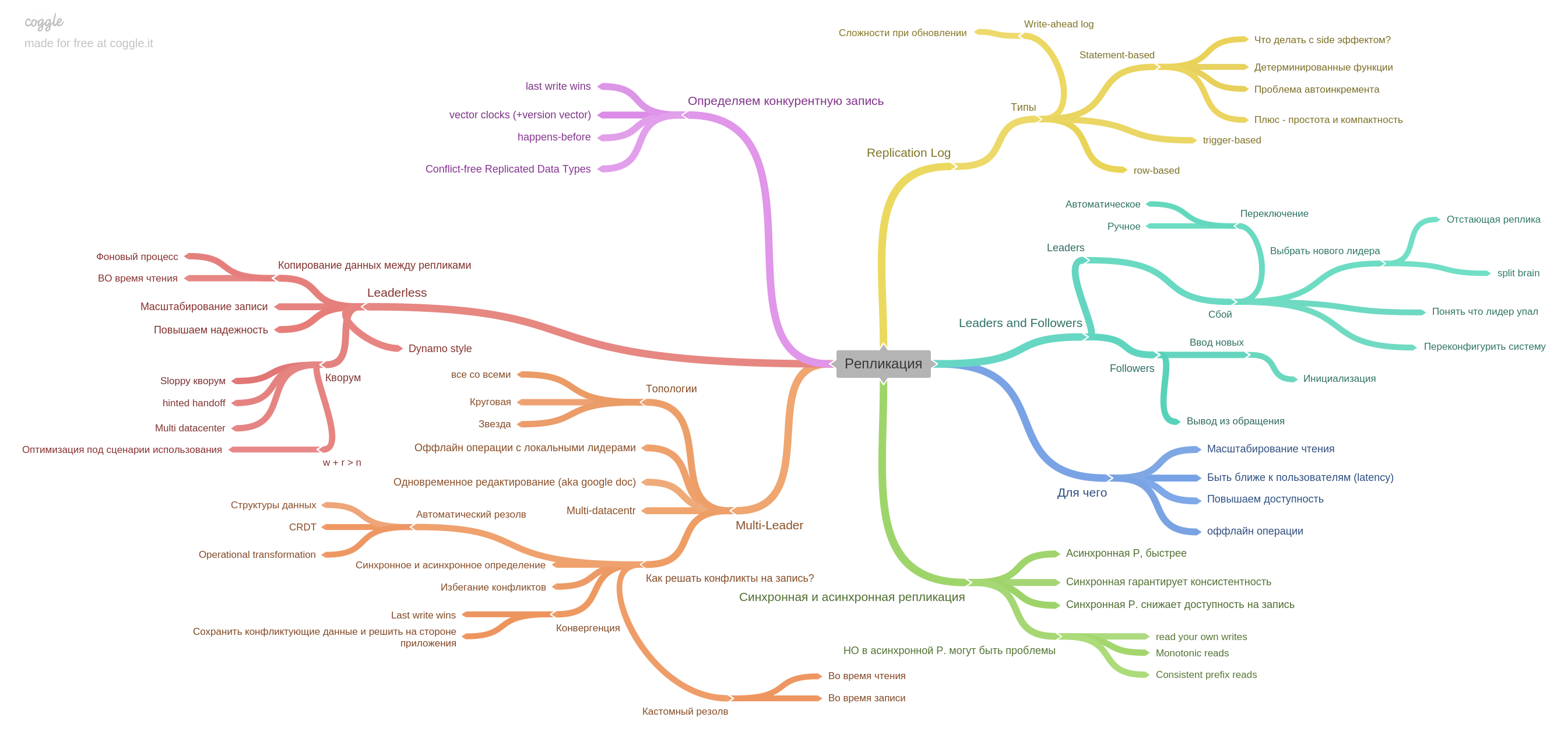
Ici, toutes les informations de base sur les répliques sont collectées: maître unique, multimaître, journal de réplication et comment vivre avec un record de concurrence dans des systèmes sans leader.
Le sixième chapitre décrit le partitionnement (aka sharding et un tas d'autres termes).
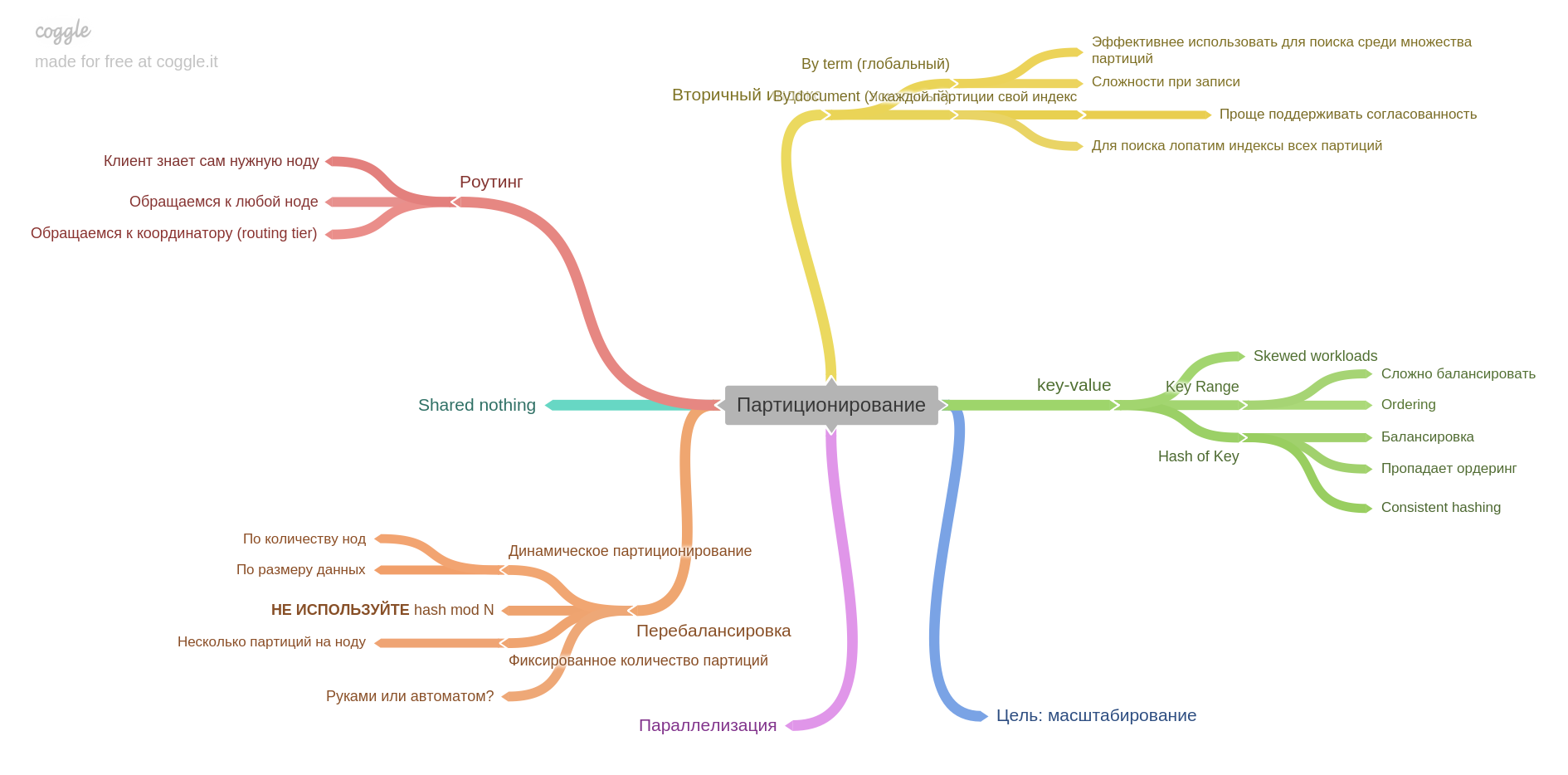
Vous apprendrez comment diviser les données en fragments, quels problèmes peuvent être résolus et lesquels obtenir, comment créer des index et équilibrer les données.
Septième chapitre : transactions.
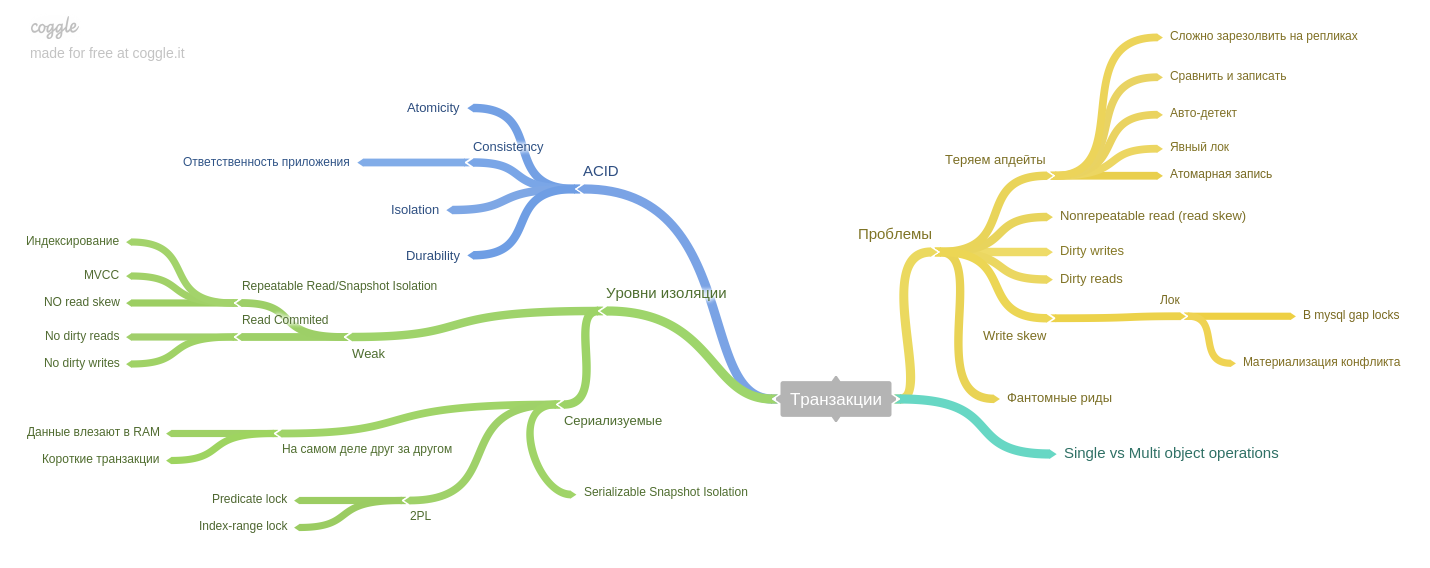
Les phénomènes (lecture asymétrique, écriture asymétrique, lectures fantômes, etc.) sont décrits et expliquent comment les niveaux d'isolement des bases de données de type ACID permettent d'éviter les problèmes.
Le huitième chapitre: sur les problèmes spécifiques aux systèmes distribués.
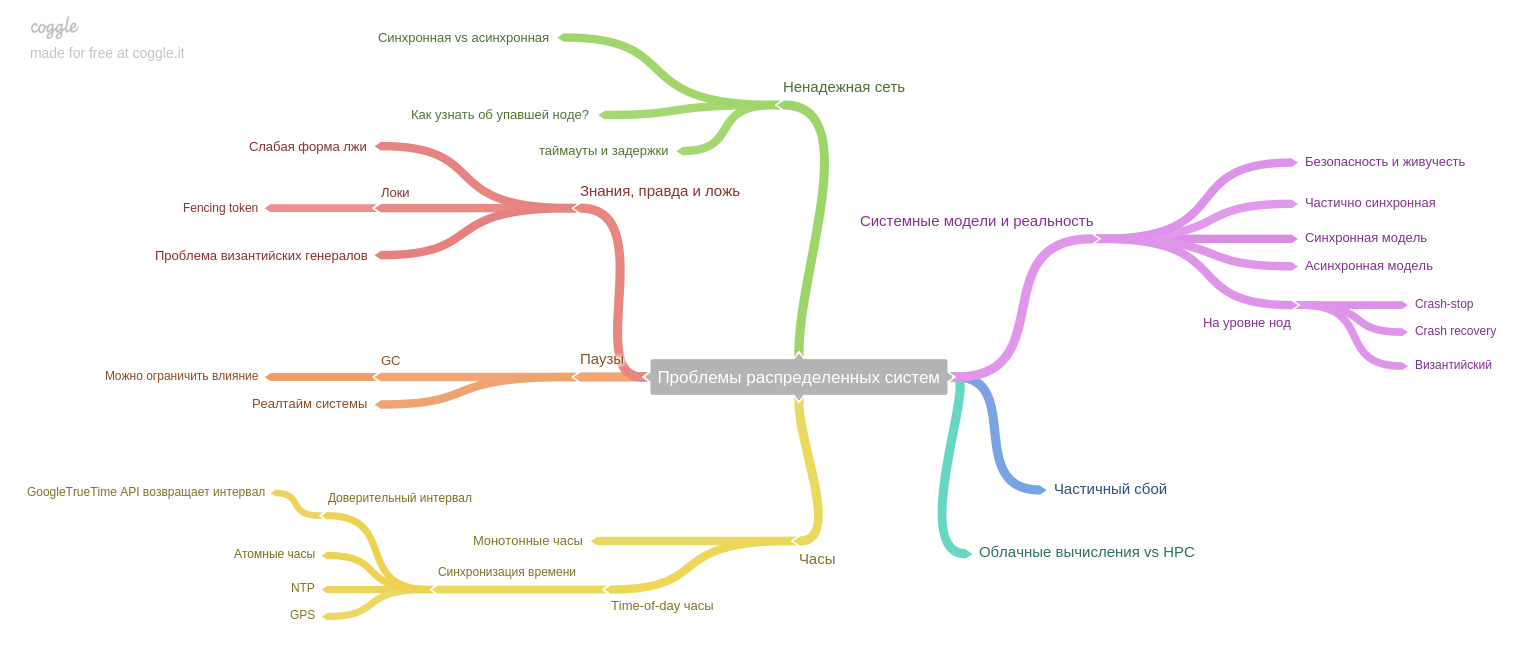
L'auteur insiste sur une idée importante: si auparavant le système fonctionnait sur une seule machine, et en cas de panne, l'ensemble du système cessait de fonctionner (et acceptait toute nouvelle donnée). Ainsi, les données après les pannes sont restées dans un état cohérent, mais aujourd'hui, à l'ère des répliques et des microservices, seule une partie du système s'arrête. Nous sommes donc confrontés à un nouveau problème: assurer la cohérence des données dans les conditions de défaillance partielle, des problèmes persistants avec un réseau peu fiable, etc.
Le neuvième chapitre décrit la cohérence et le consensus et introduit un concept important: la linéarisation. Je me souviens que la tête est entrée durement et s’insère dans ma tête)
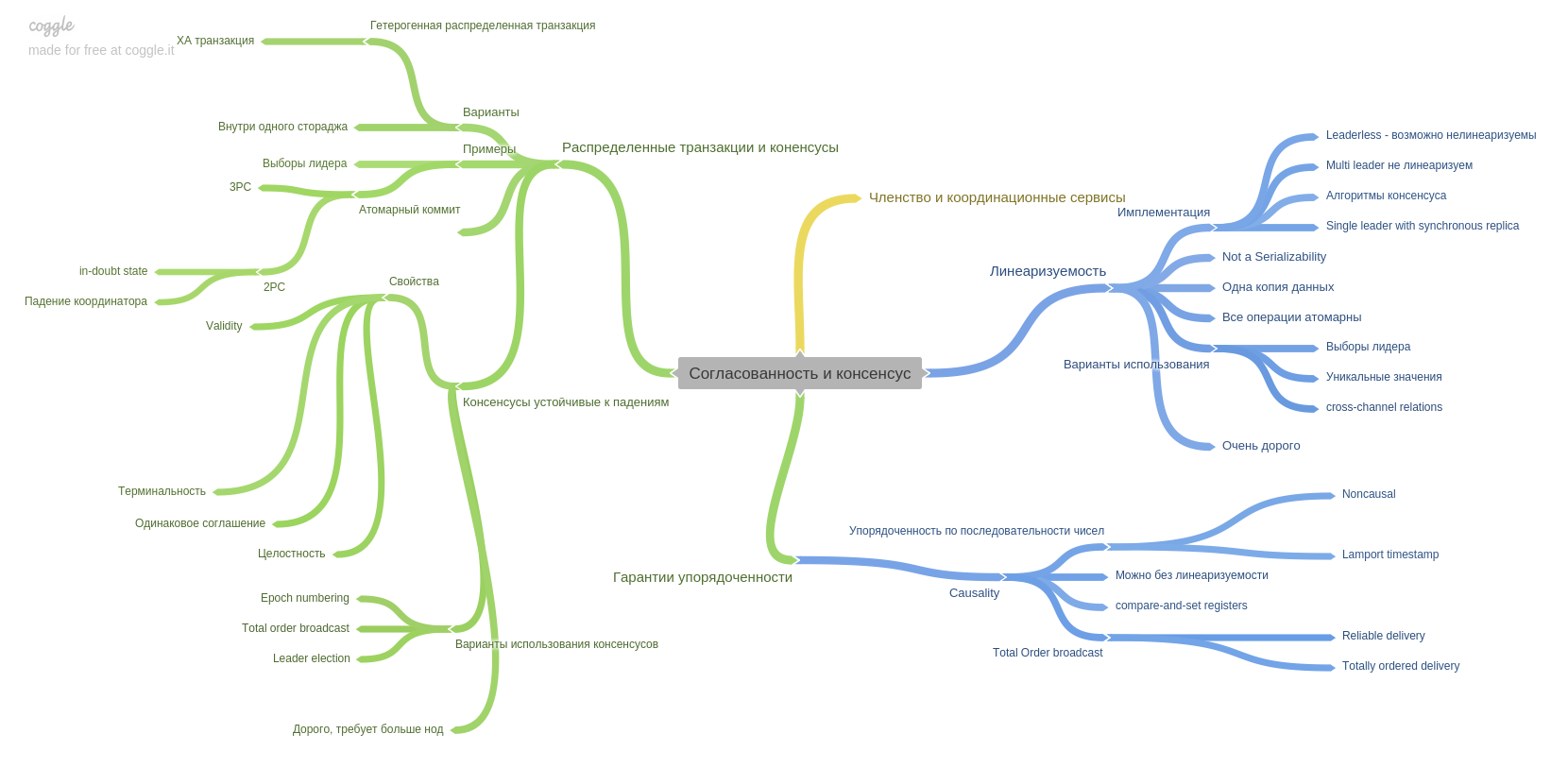
Ce chapitre décrit également la technique de validation en deux phases et ses points faibles. Dans ce chapitre également, vous découvrirez les garanties de commande. Comment et quels systèmes modernes peuvent vous fournir.
La troisième partie du livre est consacrée aux données dérivées (il n'y a pas de traduction établie). En conséquence, l'auteur exprime l'idée que tous les index, tables et vues matérialisées ne sont qu'un cache sur le journal. Seul le journal contient les données les plus pertinentes, tout le reste est en retard et est utilisé pour plus de commodité.
Le dixième chapitre.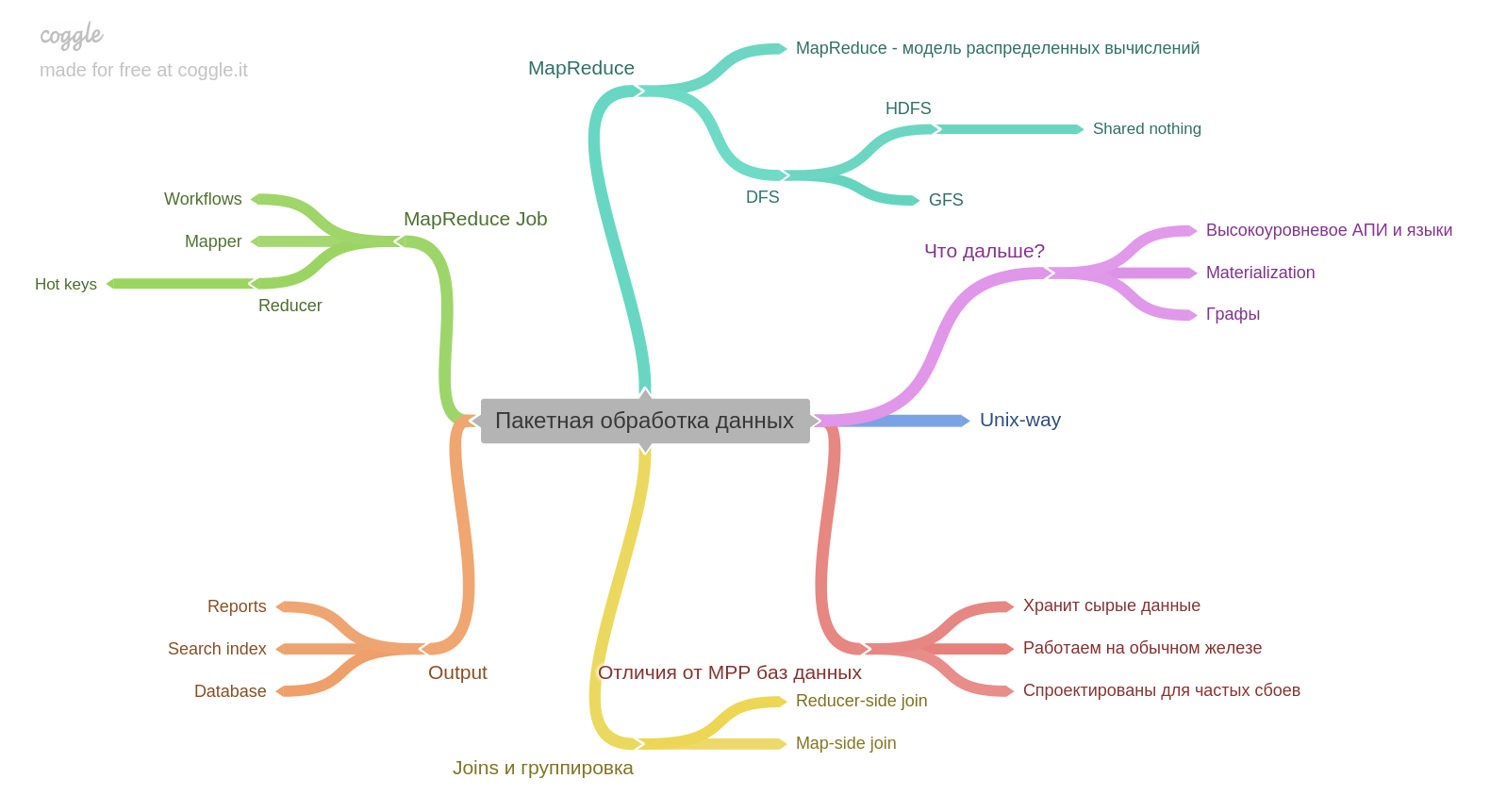
Si vous avez de l'expérience avec Hadoop ou MapReduce, vous en apprendrez peut-être peu. Mais je n'ai pas travaillé et c'était très intéressant. Un point important pour moi - le résultat du traitement par lots en soi peut devenir la base d'une autre base de données.
Chapitre 11. Traitement en continu des données.
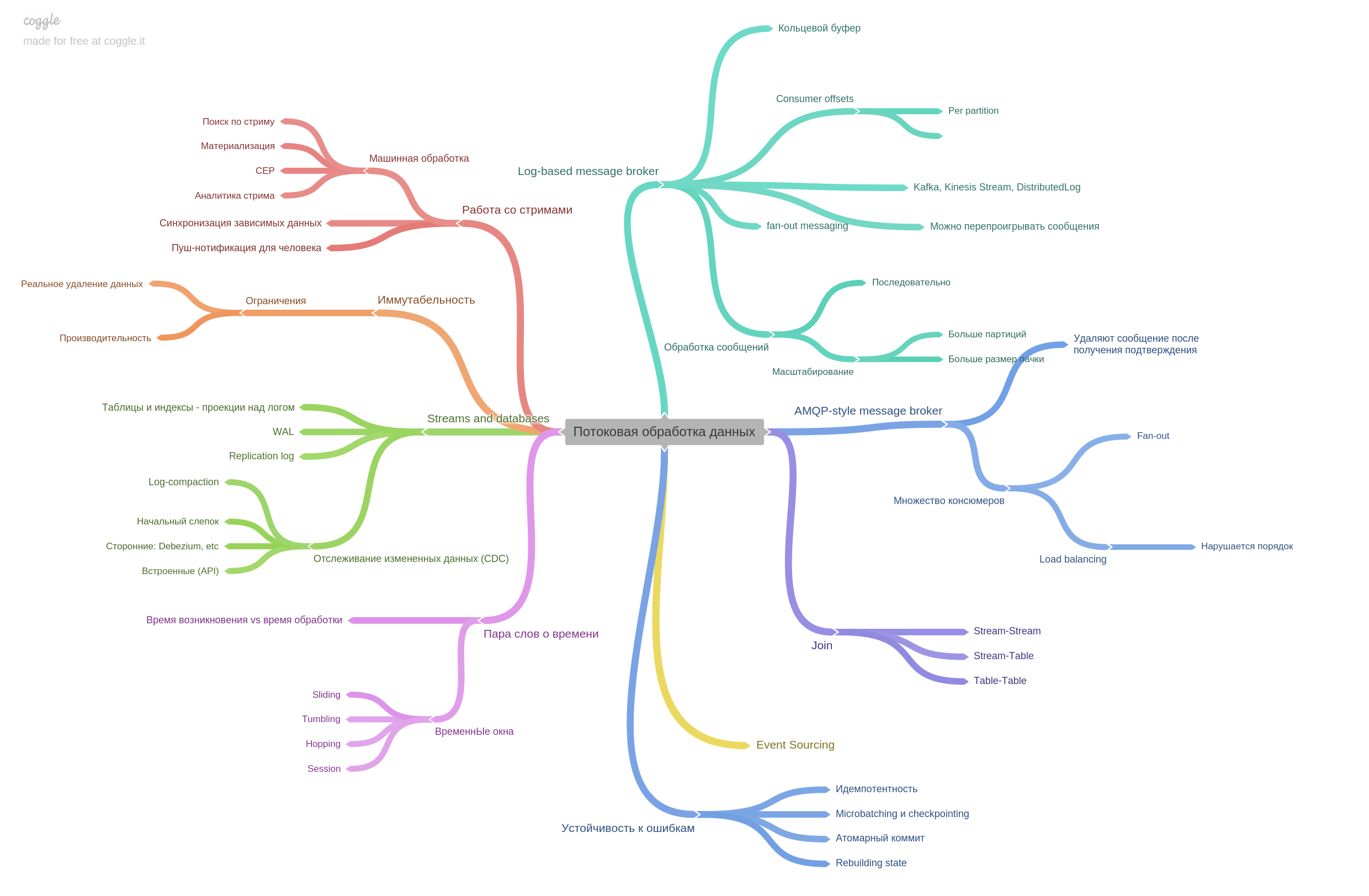
Les courtiers de messages sont décrits et en quoi le style AMPQ diffère de celui basé sur les journaux. En fait, le chapitre contient de nombreuses autres informations. C'était très intéressant à lire.
Le dernier chapitre concerne l'avenir. À quoi s'attendre, avec quoi les pensées des chercheurs et des ingénieurs sont déjà occupées.
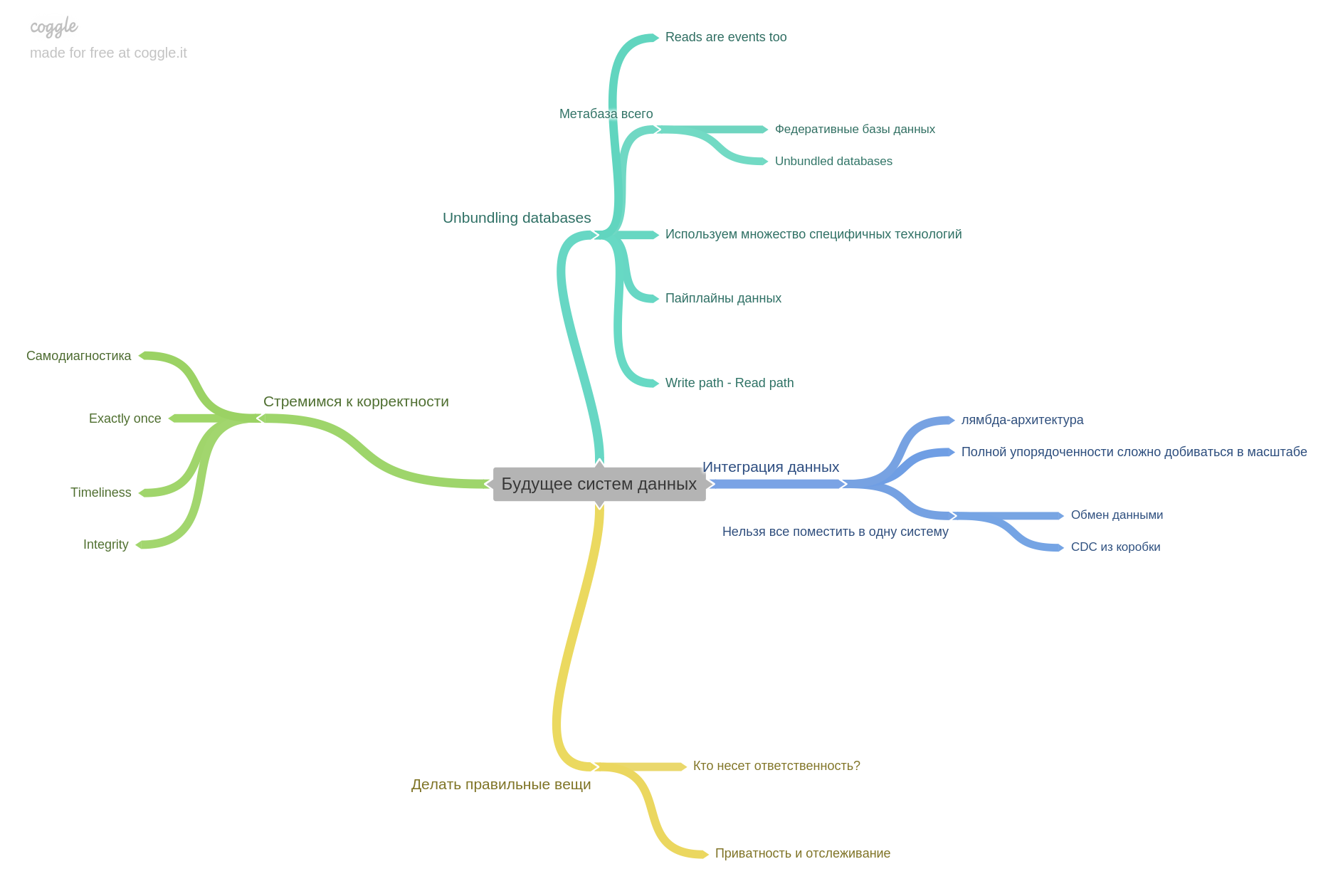
Ceci conclut mon examen. Il est important de comprendre que je n'ai fait qu'une partie des thèses pour chaque chapitre. Le livre a un contenu si dense qu'il n'est pas possible de le raconter brièvement mais complètement.
Personnellement, je pense que ce livre est le meilleur technique de ces dernières années. Je recommande fortement de le lire. Et pas seulement lire, mais travailler dur. Suivez les liens de la bibliographie, jouez avec de vrais SGBD.
Après avoir lu ce livre, vous pouvez facilement répondre à de nombreuses questions dans une interview à la base de données technique. Mais ce n'est pas la question. En tant que développeur, vous deviendrez plus cool, vous connaîtrez la structure interne, les forces et les faiblesses de diverses bases de données et penserez aux problèmes des systèmes distribués.
Je suis prêt à discuter dans les commentaires du livre lui-même et de notre pratique de lire ensemble.
Lisez des livres!