Il y a quelques années, j'ai réalisé un projet de migration dans le réseau d'un de nos clients, la tâche était de changer de plateforme, qui répartit la charge entre les serveurs. Le schéma de prestation de services de ce client a évolué pendant près de 10 ans, parallèlement aux nouveaux développements dans l'industrie des centres de données, de sorte que le «pointilleux», dans le bon sens du terme, attendait du client une solution qui satisferait non seulement aux exigences de tolérance aux pannes des équipements réseau, des équilibreurs de charge et des serveurs. , mais posséderait également des propriétés telles que l'évolutivité, la flexibilité, la mobilité et la simplicité. Dans cet article, je vais essayer de présenter de manière cohérente, du plus simple au plus complexe, les principaux exemples d'utilisation d'équilibreurs de charge sans référence au fabricant, à leurs fonctionnalités et méthodes de couplage avec le réseau de transmission de données.
Les équilibreurs de charge sont désormais de plus en plus appelés contrôleurs de distribution d'applications (ADC). Mais si les applications s'exécutent sur le serveur, pourquoi devraient-elles être livrées quelque part? Pour des raisons de tolérance aux pannes ou de mise à l'échelle, l'application peut être exécutée sur plusieurs serveurs, dans ce cas, vous avez besoin d'une sorte de serveur proxy inverse qui cache la complexité interne aux consommateurs, sélectionne le serveur souhaité, lui envoie une demande et s'assure que le serveur renvoie le bon. , du point de vue du protocole, le résultat, sinon, il sélectionnera un autre serveur et y enverra une requête. Pour implémenter ces fonctions, l'ADC doit comprendre la sémantique du protocole de couche application avec lequel il fonctionne; cela vous permet de configurer des règles spécifiques à l'application pour la livraison du trafic, l'analyse du résultat et la vérification de l'état du serveur. Par exemple, une compréhension de la sémantique de HTTP rend la configuration possible lorsque des requêtes HTTP
GET /docs/index.html HTTP/1.1 Host: www.company.com Accept-Language: en-us Accept-Encoding: gzip, deflate
sont envoyés à un groupe de serveurs avec compression ultérieure des résultats, mise en cache et demandes
POST /api/object-put HTTP/1.1 HOST: b2b.company.com X-Auth: 76GDjgtgdfsugs893Hhdjfpsj Content-Type: application/json
traitées selon des règles complètement différentes.
La compréhension de la sémantique du protocole vous permet d'organiser une session au niveau des objets du protocole d'application, par exemple, en utilisant des en-têtes HTTP, un cookie RDP ou des requêtes multiplex pour remplir une session de transport avec de nombreuses requêtes utilisateur si le niveau d'application du protocole le permet.
Le champ d'application de l'ADC est parfois déraisonnablement imaginé uniquement en servant le trafic HTTP, en fait, la liste des protocoles pris en charge pour la plupart des fabricants est beaucoup plus large. Même en travaillant sans comprendre la sémantique du protocole de couche application, ADC peut être utile pour résoudre diverses tâches, par exemple, j'ai participé à la construction d'une batterie de serveurs virtuelle autosuffisante de serveurs SMTP, pendant les attaques de spam, le nombre d'instances augmente à l'aide du contrôle de rétroaction sur la longueur de la file d'attente de messages pour fournir un temps satisfaisant pour vérifier les messages avec des algorithmes gourmands en ressources. Lors de l'activation, le serveur s'est inscrit auprès d'ADC et a reçu sa portion de nouvelles sessions TCP. Dans le cas de SMTP, ce schéma de fonctionnement était pleinement justifié en raison de l'entropie élevée des connexions au niveau du réseau et du transport; pour une répartition uniforme de la charge lors des attaques de spam ADC, seul le support TCP est requis. Un schéma similaire peut être utilisé pour créer une batterie de serveurs à partir de serveurs de bases de données, de grappes de serveurs DNS, DHCP, AAA ou d'accès distant très chargés lorsque les serveurs peuvent être considérés comme équivalents dans le domaine et lorsque leurs caractéristiques de performances ne diffèrent pas trop les unes des autres. Je n'irai pas plus loin dans le sujet des fonctionnalités de protocole, cet aspect est trop étendu pour être mentionné dans l'introduction, si quelque chose semble intéressant - écrivez, c'est peut-être l'occasion pour un article avec une présentation plus approfondie d'une application, et maintenant passons au point.
Le plus souvent, ADC ferme la couche de transport, de sorte que la session TCP de bout en bout entre le consommateur et le serveur devient composite, le consommateur établit une session avec ADC et ADC avec l'un des serveurs.
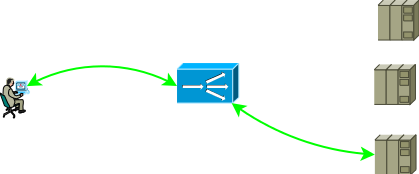 Fig.1
Fig.1Les paramètres de configuration et d'adressage du réseau doivent permettre une telle amélioration du trafic afin que deux parties de la session TCP passent par l'ADC. L'option la plus simple pour rendre le trafic de la première partie à venir à l'ADC est d'attribuer une adresse de service à l'une des adresses de l'interface ADC, avec la deuxième partie, les options suivantes sont possibles:
- ADC comme passerelle par défaut pour le réseau de serveurs;
- Diffuser vers les adresses des consommateurs ADC dans l'une de ses adresses d'interface.
En fait, une vue légèrement plus réaliste du premier schéma d'application ressemble à ceci, c'est la base à partir de laquelle nous commencerons:
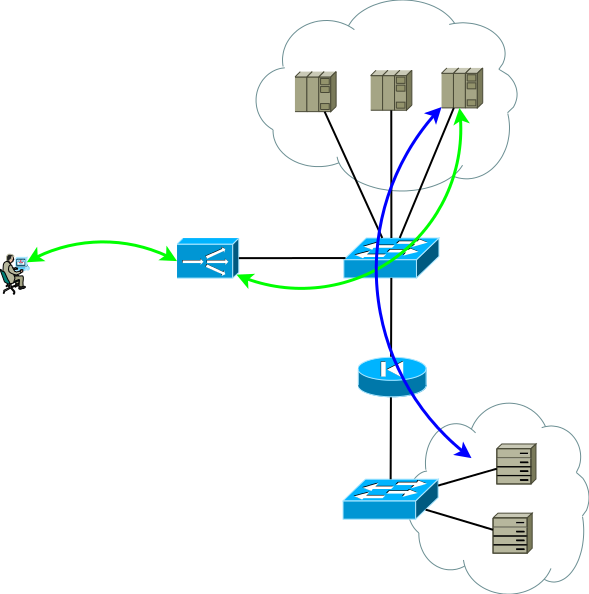 Fig.2
Fig.2Le deuxième groupe de serveurs peut être des bases de données, un back-end d'application, un stockage réseau ou un front-end pour un autre ensemble de services en cas de décomposition d'une application classique en micro-services. Ce groupe de serveurs peut être un domaine de routage distinct, avec ses propres politiques, situé dans un autre centre de données ou être complètement isolé pour des raisons de sécurité. Les serveurs sont rarement situés dans un segment; le plus souvent, ils sont placés dans des segments pour leur destination avec des politiques d'accès clairement réglementées, la figure le montre comme un pare-feu.
Des études montrent que les applications multiniveaux modernes génèrent plus de trafic Ouest-Est et il est peu probable que tout le trafic intra-code / inter-segments passe par l'ADC. Les commutateurs de la figure 2 ne sont pas nécessairement physiques - les domaines de routage peuvent être implémentés à l'aide d'entités virtuelles, appelées virtual-router, vrf, vr, vpn-instance ou une table de routage virtuelle pour différents fabricants.
Soit dit en passant, il existe une variante de couplage avec le réseau, sans nécessiter de symétrie des flux de trafic du consommateur vers l'ADC et de l'ADC vers les serveurs, il est demandé dans les cas de sessions de longue durée, dans lesquelles une très grande quantité de trafic est transmise dans un sens, par exemple, le streaming ou diffuser du contenu vidéo. Dans ce cas, l'ADC ne voit que le flux du client vers les serveurs, ce flux est délivré à l'adresse de l'interface ADC et après un traitement simple, qui consiste à remplacer l'adresse MAC par l'interface MAC de l'un des serveurs, la requête est envoyée au serveur où l'adresse de service est affectée à l'une des interfaces logiques. Le trafic inverse du serveur vers le consommateur contourne l'ADC conformément à la table de routage du serveur. La prise en charge d'un seul domaine de diffusion pour tous les frontaux peut être très difficile, en outre, la capacité d'ADC à analyser les réponses et à prendre en charge la sessionnabilité dans ce cas est très limitée, en fait il ne s'agit que d'un commutateur, donc cette option n'est pas envisagée plus loin, bien que certaines soient étroites les tâches peuvent être utilisées.
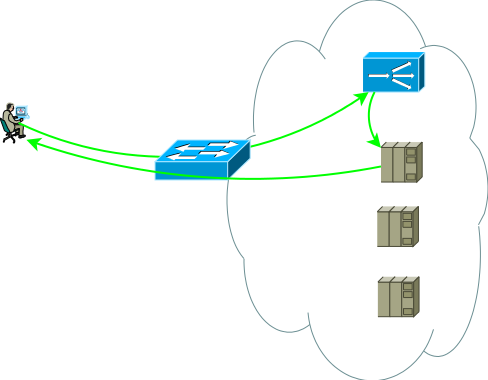 Fig.3
Fig.3Donc, nous avons un centre de données de base, illustré à la figure 2, réfléchissons aux problèmes qui peuvent pousser le centre de données de base à l'évolution, je vois deux sujets d'analyse:
- Supposons que le sous-système de commutation soit entièrement réservé, ne pensons pas comment ni pourquoi, le sujet est trop étendu. Les applications s'exécutent sur plusieurs serveurs et sont sauvegardées à l'aide d'ADC, mais comment réserver l'ADC lui-même?
- Si l'analyse montre que la prochaine charge de pointe saisonnière peut dépasser les capacités d'ADC, vous pensez bien sûr à l'évolutivité.
Ces tâches sont similaires dans la mesure où, au cours de leur résolution, le nombre d'instances ADC augmentera certainement. Dans le même temps, la tolérance aux pannes peut être organisée selon le schéma Actif / Sauvegarde et Actif / Actif, et la mise à l'échelle ne peut être effectuée qu'en fonction du schéma Actif / Actif. Essayons de les résoudre individuellement et voyons quelles sont les propriétés des différentes solutions.
Les ADC de nombreux fabricants peuvent être considérés comme des éléments d'une infrastructure réseau, RIP, OSPF, BGP - tout cela est là, ce qui signifie que vous pouvez créer un schéma de sauvegarde Active / Backup trivial. L'ADC actif transmet les préfixes de service au routeur en amont et en reçoit l'itinéraire par défaut pour remplir sa table et transférer vers le centre de données vers la table de routage virtuelle correspondante. L'ADC de sauvegarde fait de même, mais, en utilisant la sémantique du protocole de routage sélectionné, génère des annonces moins attrayantes. Avec cette approche, les serveurs peuvent voir la véritable adresse IP du consommateur, car il n'y a aucune raison d'utiliser la traduction d'adresse. Ce schéma fonctionne également correctement s'il y a plus d'un routeur en amont, mais afin d'éviter une situation où l'ADC actif perd la connexion par défaut et la connectivité avec le routeur, tout en recevant toujours la valeur par défaut de l'ADC de sauvegarde et continue de l'annoncer vers le centre de données, essayez d'éviter la proximité entre ADC et l'utilisation de routes statiques.
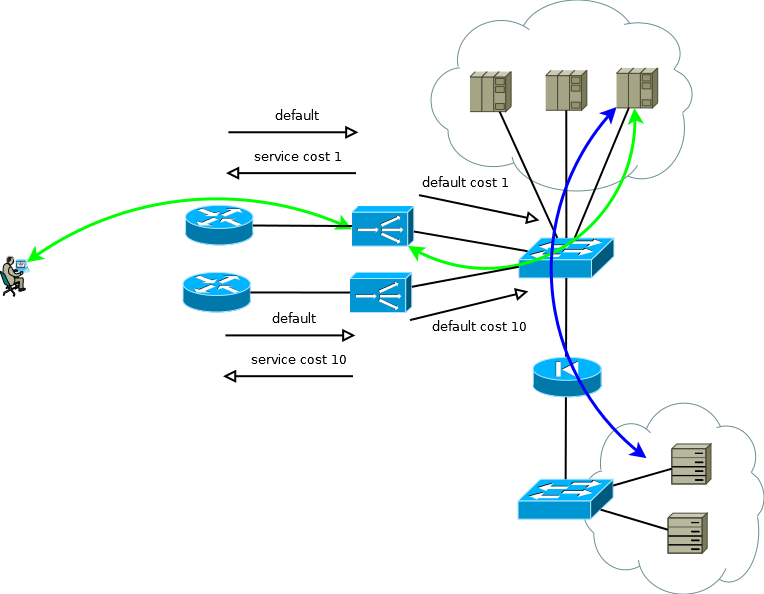 Fig.4
Fig.4Si les serveurs n'ont pas besoin de fonctionner avec de vraies adresses IP de consommateur, ou si le protocole de couche application vous permet de l'intégrer dans des en-têtes, tels que HTTP, le schéma se transforme en Actif / Actif avec une dépendance presque linéaire des performances sur le nombre d'ADC. Dans le cas de plusieurs routeurs en amont, il faut veiller à ce que le trafic entrant arrive en portions plus ou moins uniformes. Cette tâche peut être facilement résolue si dans le domaine de routage ECMP le transfert commence vers ces routeurs, s'il est difficile ou si le domaine de routage n'est pas desservi par vous - vous pouvez utiliser des connexions à maillage complet entre ADX et les routeurs afin que le transfert ECMP commence directement vers eux.
 Fig.5
Fig.5Au début de cette partie, j'ai écrit que la tolérance aux pannes et la mise à l'échelle sont deux grandes différences. Les solutions à ces problèmes ont un niveau d'utilisation des ressources différent, si vous concevez un schéma actif / de secours, vous devez accepter le fait que la moitié des ressources seront inactives. Et s'il vous arrive de devoir passer à la prochaine étape quantitative, soyez prêt à multiplier les ressources nécessaires par deux à l'avenir.
Les avantages d'Active / Active commencent à apparaître lorsque vous utilisez plus de deux appareils. Supposons que vous deviez garantir les performances de 8 unités arbitraires (8 000 connexions par seconde ou 8 millions de sessions simultanées) et fournir un scénario de défaillance de périphérique unique, dans la version Active / Active, vous n'avez besoin que de trois instances ADC d'une capacité de 4, dans le cas d'Active / Standby - deux par 8. Si vous traduisez ces nombres en ressources inactives, vous obtenez un tiers à la moitié. Le même principe de calcul peut être utilisé pour estimer la proportion de connexions rompues pendant une période de défaillance partielle. Avec une augmentation du nombre d'instances Active / Active, les calculs deviennent encore plus agréables, et le système a la possibilité d'augmenter progressivement la productivité au lieu de Active / Standby par étapes.
Il sera correct de mentionner une autre façon de schémas de travail actif / actif ou actif / veille - le clustering. Mais il ne sera pas très correct de consacrer beaucoup de temps à cela, car j'ai essayé d'écrire sur les approches et non sur les fonctionnalités des fabricants. Lorsque vous choisissez cette solution, vous devez comprendre clairement les choses suivantes:
- L'architecture de cluster impose parfois des restrictions sur telle ou telle fonctionnalité, dans certains projets c'est fondamental, dans certains cela peut devenir important à l'avenir, tout dépend du fabricant et chaque solution doit être élaborée individuellement;
- Le cluster est souvent un domaine d'erreur, il y aura des erreurs dans le logiciel.
- Le cluster est facile à assembler, mais très difficile à démonter. La technologie a moins de mobilité - vous ne pouvez pas contrôler certaines parties du système.
- Vous tombez dans l'étreinte tenace de votre fabricant.
Néanmoins, il y a des choses positives:
- Le cluster est facile à installer et à utiliser.
- Parfois, vous pouvez vous attendre à une utilisation des ressources presque optimale.
Ainsi, notre centre de données de la figure 5 continue de croître, la tâche que vous devrez peut-être résoudre consiste à augmenter le nombre de serveurs. Il n'est pas toujours possible de le faire dans un centre de données existant, alors supposez qu'un nouvel emplacement spacieux avec des serveurs supplémentaires soit apparu.
 Fig.6
Fig.6Un nouveau site peut ne pas être très loin, vous pourrez alors résoudre le problème en renouvelant les domaines de routage. Un cas plus général, qui n'exclut pas l'apparition du site dans une autre ville ou dans un autre pays, posera de nouveaux défis pour le datacenter:
- Utilisation des canaux entre les sites;
- Différence de temps de traitement pour les demandes envoyées par ADC pour traitement aux serveurs proches et distants.
Le maintien d'un large canal entre les sites peut être une entreprise très coûteuse, et le choix d'un emplacement ne sera plus une tâche triviale - un site surchargé avec un temps de réponse court ou gratuit avec un grand. En y réfléchissant, vous serez amené à créer une configuration de centre de données géographiquement distribuée. Cette configuration, d'une part, est conviviale pour les consommateurs, car elle vous permet de recevoir un service à un point proche de vous, d'autre part, elle peut réduire considérablement les exigences pour la bande de canaux entre les sites.
Dans le cas où les vraies adresses IP ne doivent pas être accessibles aux serveurs, ou lorsque le protocole de couche application permet de les transmettre dans les en-têtes, le dispositif d'un centre de données géographiquement distribué n'est pas très différent de ce que j'ai appelé le centre de données de base. ADC sur n'importe quel site peut envoyer des demandes de traitement à des serveurs locaux ou les envoyer pour traitement à un voisin, la diffusion de l'adresse du consommateur rend cela possible. Une attention particulière devrait être accordée à la surveillance du volume de trafic entrant afin de maintenir la quantité d'ADC dans le site adéquate à la proportion du trafic que le site reçoit. La traduction d'adresse du consommateur vous permet d'augmenter / diminuer le nombre d'ADC ou même de déplacer des instances entre les sites en fonction des changements dans la matrice de trafic entrant, ou pendant la migration / le lancement. Malgré sa simplicité, le schéma est assez flexible, présente des caractéristiques de fonctionnement agréables et est facilement reproduit pour plus de deux sites.
 Fig. 7
Fig. 7Si vous travaillez avec un protocole qui permet de transférer des demandes, comme dans le cas de la redirection HTTP, cette fonctionnalité peut être utilisée comme un levier supplémentaire pour contrôler la charge du canal entre les sites, comme un mécanisme pour effectuer une maintenance de routine sur les serveurs ou comme une méthode de construction de batteries de serveurs Active / Backup sur différents sites. Au moment voulu, automatiquement ou après certains événements déclencheurs, ADC peut supprimer le trafic des serveurs locaux et déplacer les consommateurs vers un site voisin. Il vaut la peine de porter une attention particulière au développement de cet algorithme afin que le travail coordonné de l'ADC exclue la possibilité de transmission mutuelle des demandes ou de résonance.
Le cas est particulièrement intéressant lorsque les serveurs ont besoin de véritables adresses IP de consommateurs et que le protocole de couche application n'a pas la capacité de transmettre des en-têtes supplémentaires, ou lorsque les ADC fonctionnent sans comprendre la sémantique du protocole de couche application. Dans ce cas, il n'est pas possible de fournir une connexion cohérente entre les segments de session TCP en déclarant simplement une route dans ADC par défaut. Si vous procédez ainsi, les serveurs du premier site commenceront à utiliser l'ADC local comme passerelle par défaut pour les sessions provenant du deuxième site, la session TCP ne sera pas établie dans ce cas car l'ADC du premier site ne verra qu'une seule épaule de la session.
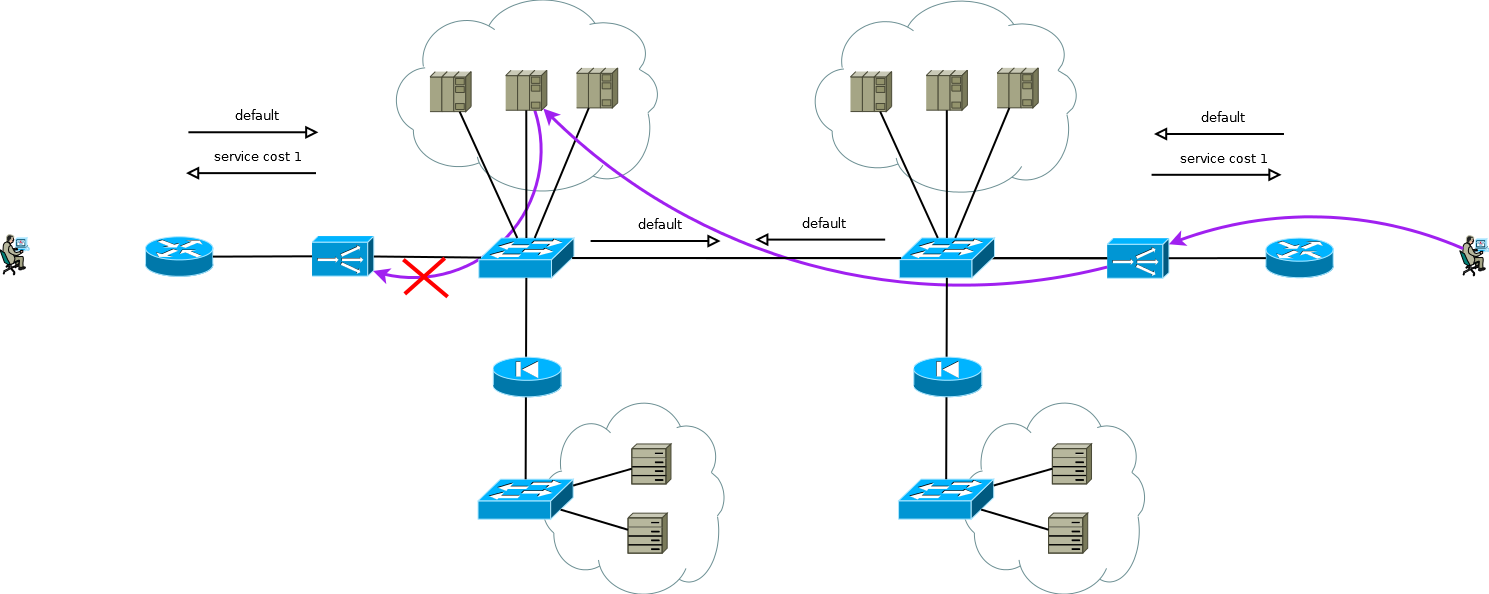 Fig. 8
Fig. 8Il existe une petite astuce qui vous permet toujours d'exécuter Active / Active ADC en combinaison avec des batteries de serveurs Active / Active sur différents sites (je ne considère pas le cas d'Active / Backup sur deux sites, une lecture attentive de ce qui précède vous permettra de résoudre ce problème sans autre discussion). L'astuce consiste à utiliser sur l'ADC du deuxième site non pas les adresses de l'interface du serveur, mais l'adresse ADC logique, qui correspond à la batterie de serveurs sur le premier site. Dans le même temps, les serveurs reçoivent le trafic comme s'il provenait de l'ADC local et utilisent la passerelle par défaut locale. Pour conserver ce mode de fonctionnement sur l'ADC, vous devez activer la fonction mémoire de l'interface à partir de laquelle le premier paquet pour la configuration de la session TCP est venu. Différents fabricants appellent cette fonction différemment, mais l'essence est la même - rappelez-vous l'interface dans la table d'état de session et utilisez-la pour le trafic de réponse sans prêter attention à la table de routage. Le schéma est entièrement fonctionnel et vous permet de répartir la charge de manière flexible sur tous les serveurs disponibles où qu'ils se trouvent. Dans le cas de deux sites ou plus, la défaillance d'un ADC n'affecte pas la disponibilité du service dans son ensemble, mais exclut complètement la possibilité de traiter le trafic sur les serveurs de site avec des ADC défaillants, cela doit être gardé à l'esprit lors de la prévision du comportement et de la charge lors d'échecs partiels.
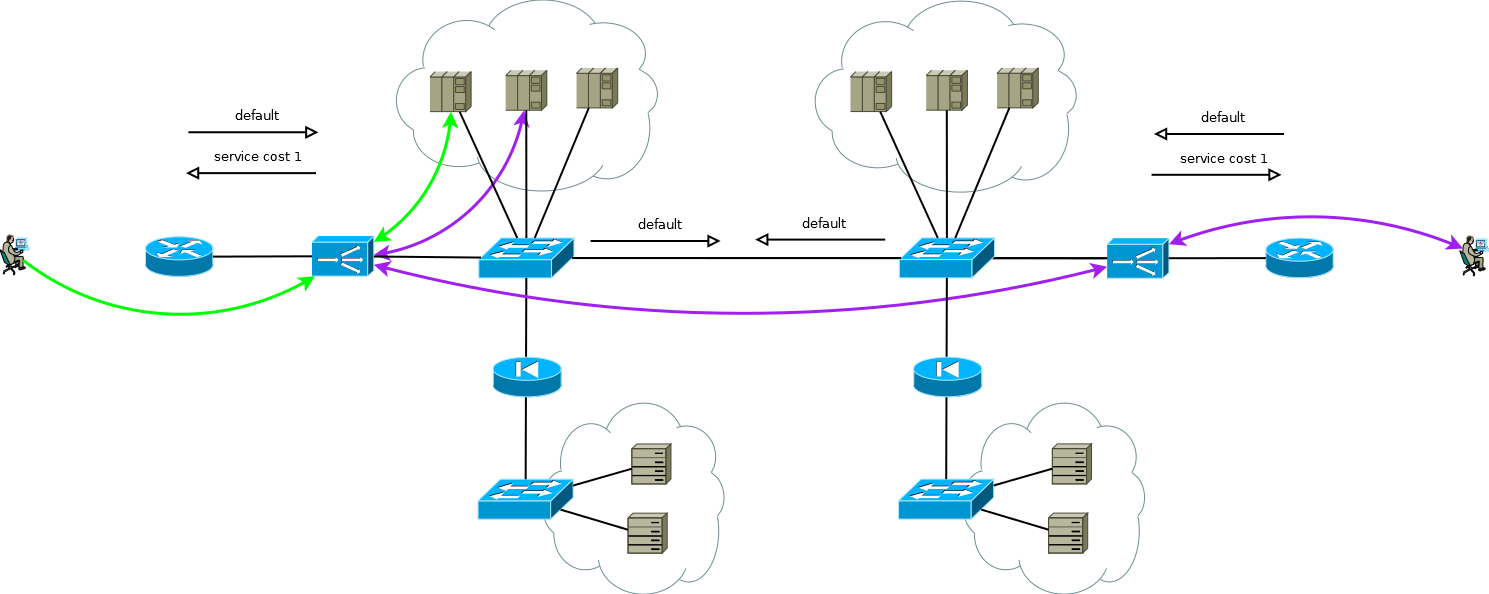 Fig. 9
Fig. 9Les services de notre client ont fonctionné à peu près de la même manière lorsque j'ai commencé à travailler sur un projet de migration vers la nouvelle plateforme ADC. Il n'était pas difficile de recréer simplement le comportement des appareils de l'ancienne plateforme sur la nouvelle dans le cadre d'un schéma éprouvé et convivial, c'est ce qu'ils attendaient de nous.
Mais regardez à nouveau la figure 9, voyez-vous ce qui peut être optimisé là-bas?
Le principal inconvénient de travailler avec la chaîne ADC est qu'elle consomme les ressources de deux ADC pour traiter une partie des sessions. Dans le cas de ce client, le choix était absolument conscient, il était dû aux spécificités des applications et à la nécessité de pouvoir redistribuer très rapidement (de 20 à 50 secondes) la charge entre serveurs de sites différents. À différentes périodes, le double traitement a nécessité en moyenne 15 à 30% des ressources ADC, ce qui suffit à penser à l'optimisation. Après avoir discuté de ce point avec les ingénieurs du client, nous avons proposé de remplacer la prise en charge de la table de session ADC par la liaison d'interface avec le routage source sur les serveurs utilisant PBR sur la pile IP Linux. En tant que clé, nous avons considéré des options telles que:
- adresse IP supplémentaire sur les serveurs sur une interface commune pour chaque ADC;
- interface adresse IP sur les serveurs sur un 802.1q distinct pour chaque ADC;
- Réseau de tunnel de superposition distinct sur les serveurs pour chaque ADC.
Les première et deuxième options affectent en quelque sorte le réseau dans son ensemble. Parmi les effets secondaires de l'option numéro un, il nous a semblé inacceptable qu'une augmentation multiple du nombre d'ADC, de tables ARP sur les commutateurs, et la deuxième option nécessiterait une augmentation du nombre de domaines de diffusion de bout en bout entre les sites ou des instances individuelles de tables de routage virtuelles. La nature locale de la troisième option nous a semblé très attrayante et nous nous sommes mis au travail, ce qui a abouti à un contrôleur simple qui automatise la configuration des tunnels sur les serveurs et l'ADC, ainsi que la configuration PBR sur la pile IP des serveurs Linux.
 Fig. 10
Fig. 10Au moment où j'écrivais, la migration était terminée, le client a obtenu ce qu'il voulait - une nouvelle plate-forme, simplicité, flexibilité, évolutivité et, à la suite du passage à une superposition, simplifiant la configuration de l'équipement réseau dans le cadre de la maintenance de ces services - au lieu de plusieurs copies de tables virtuelles et de grands domaines de diffusion, il s'est avéré que - IP .
Chers collègues qui travaillent avec les fabricants d'ADC, ce paragraphe se concentre davantage sur vous. Certains de vos produits sont bons, mais essayez de faire attention à une intégration plus étroite avec les applications sur les serveurs, l'automatisation de leurs paramètres et l'orchestration de l'ensemble du processus de développement et de fonctionnement. Cela me semble sous la forme d'une interaction contrôleur-agent classique, apportant des modifications à l'ADC, l'utilisateur lance l'appel du contrôleur aux agents enregistrés, c'est ce que nous avons fait avec le client, mais «prêt à l'emploi».De plus, certains clients peuvent trouver commode de passer d'un modèle PULL d'interaction avec des serveurs à un modèle PUSH. Les capacités d'application sur les serveurs sont très larges, il est donc parfois plus facile d'organiser une vérification sérieuse spécifique à l'application du service sur l'agent lui-même. Si la vérification donne un résultat positif, l'agent transmet des informations, par exemple, sous une forme similaire à la communauté de coûts BGP, pour une utilisation dans des algorithmes de calcul pondérés.Souvent, différents départements de l'organisation effectuent la maintenance du serveur et de l'ADC; le passage à un modèle d'interaction PUSH peut être intéressant car ce modèle élimine le besoin de coordination entre les départements sur une interface interhumaine. Les services auxquels le serveur participe peuvent être transférés directement de l'agent à l'ADC sous la forme de quelque chose de similaire à la BGP Flow-Spec avancée.Il y a encore beaucoup à écrire. Pourquoi suis-je tout cela ... Étant dans un choix libre, nous prenons une décision en faveur d'une option plus pratique, plus adaptée ou en faveur d'une option qui élargit la fenêtre d'opportunité afin de minimiser nos risques. Les grands acteurs de l'industrie Internet inventent quelque chose de complètement innovant pour résoudre leurs problèmes, quelque chose qui dicte demain, les petits acteurs et les entreprises ayant une expérience dans le développement de logiciels utilisent de plus en plus des technologies et des produits qui permettent une personnalisation approfondie pour eux-mêmes. De nombreux fabricants d'équilibreurs de charge notent une baisse de la demande pour leurs produits. En d'autres termes, les serveurs et applications qui les exécutent, commutateurs et routeurs il y a quelque temps, ont déjà changé qualitativement et sont entrés dans l'ère SDN. Les équilibreurs sont au seuilprenez cette mesure lorsque la porte est ouverte, sinon vous risquez de perdre un avantage concurrentiel et de vous déplacer vers la périphérie.