Bonjour à tous!
Aujourd'hui, je vais vous dire comment nous, à
hh.ru, considérons les statistiques manuelles sur les expériences. Nous verrons d'où proviennent les données, comment nous les traitons et quels pièges nous rencontrons. Dans cet article, je partagerai une architecture et une approche communes, il y aura un minimum de scripts et de code réels. Le public principal est les analystes débutants qui s'intéressent à la structure de l'infrastructure d'analyse des données dans hh.ru. Si ce sujet est intéressant - écrivez dans les commentaires, nous pouvons nous plonger dans le code dans les articles suivants.
Vous pouvez lire comment les mesures automatiques pour les expériences A / B sont prises en compte dans notre
autre article .

Quelles données analysons-nous et d'où viennent-elles
Nous analysons les journaux d'accès et tous les journaux personnalisés que nous écrivons nous-mêmes.
95.108.213.12 - - [13 / août / 2018: 04: 00: 02 +0300] 200 "GET / employeur / 2574971 HTTP / 1.1" 12012 "-" "Mozilla / 5.0 (compatible; YandexBot / 3.0; + http: / /yandex.com/bots) "" - "" gardabani.headhunter.ge "" 0,063 "-" "1534122002.858" - "" 192.168.2.38:1500 "" [0,064] "{15341220027959c8c01c51a6e01b682f} 200 https 1 -" " - "- - [35827] [0,000 0]
178.23.230.16 - - [13 / août / 2018: 04: 00: 02 +0300] 200 "GET / vacancy / 24266672 HTTP / 1.1" 24229 " hh.ru/vacancy/24007186?query=bmw " "Mozilla / 5.0 ( Macintosh; Intel Mac OS X 10_10_5) AppleWebKit / 603.3.8 (KHTML, comme Gecko) Version / 10.1.2 Safari / 603.3.8 "-" "hh.ru" "0.210" "last_visit = 1534111115966 :: 1534121915966; hhrole = anonyme; régions = 1; tmr_detect = 0% 7C1534121918520; total_searches = 3; unique_banner_user = 1534121429.273825242076558 "" 1534122002.859 "" - "" 192.168.2.239:1500 "" [0.208] "{1534122002649b7eef2e901d8c9c0469} 200 https 1 -" - "- - [35927] [0.001 0]
Dans notre architecture, chaque service écrit des journaux localement, puis via les journaux client-serveur auto-écrits (y compris les journaux d'accès nginx) sont collectés sur un référentiel central (ci-après la journalisation). Les développeurs ont accès à cette machine et peuvent enregistrer manuellement les journaux si nécessaire. Mais comment, dans un délai raisonnable, peut engloutir plusieurs centaines de gigaoctets de journaux? Bien sûr, versez-les dans du hadoop!
D'où viennent les données dans hadoop?
Hadoop stocke non seulement les journaux de service, mais télécharge également la base de données prod. Chaque jour, dans hadoop, nous téléchargeons certaines des tables nécessaires à l'analyse.
Les journaux de service entrent dans hadoop de trois manières.
- Chemin vers le front - cron est lancé depuis le stockage des journaux la nuit et rsync télécharge les journaux bruts sur hdfs.
- La manière est à la mode - les journaux des services sont versés non seulement dans le stockage commun, mais aussi dans kafka, où flume les lit, fait le prétraitement et les enregistre dans hdfs.
- Le chemin est à l'ancienne - dans les jours qui ont précédé kafka, nous avons écrit notre propre service, qui lit les journaux bruts du stockage, les extrait du prétraitement et les télécharge sur hdfs.
Examinons chaque approche plus en détail.
Chemin du front
Cron exécute un script bash standard.
Comme nous nous en souvenons, dans le référentiel de journaux, tous les journaux sont sous forme de fichiers ordinaires, la structure des dossiers est approximativement la suivante: /logging/java/2018/08/10/{service_nameasure/*.log
Hadoop stocke ses fichiers dans approximativement la même structure de dossiers hdfs-raw / banner-versions / year = 2018 / month = 08 / day = 10
année, mois, jour que nous utilisons comme partitions.
Ainsi, il suffit de former les bons chemins (lignes 3-4), puis de sélectionner tous les journaux nécessaires (ligne 6) et d'utiliser rsync pour les remplir dans hadoop (ligne 8).
Les avantages de cette approche:- Développement rapide
- Tout est transparent et clair.
Inconvénients:Manière à la mode
Puisque nous téléchargeons les journaux dans le référentiel avec un script auto-écrit, il était logique de visser la possibilité de les télécharger non seulement sur le serveur, mais aussi sur kafka.
Avantages- Journaux en ligne (les journaux dans hadoop apparaissent lorsque vous remplissez kafka)
- Vous pouvez faire un prétraitement
- Il supporte bien la charge et vous pouvez télécharger de gros journaux
Inconvénients- Configuration plus difficile
- Je dois écrire du code
- Plus de parties du processus de coulée
- Surveillance et analyse plus complexes des incidents
Façon à l'ancienne
Il ne diffère de la mode qu'en l'absence de kafka. Par conséquent, il hérite de tous les inconvénients et seulement certains des avantages de l'approche précédente. Un service distinct (ustats-uploader) en java lit périodiquement les fichiers nécessaires, les prétraite et les télécharge sur hadoop.
Avantages- Vous pouvez faire un prétraitement
Inconvénients- Configuration plus difficile
- Je dois écrire du code
Et donc les données sont entrées dans hadoop et prêtes pour l'analyse. Arrêtons-nous un peu et rappelons-nous ce qu'est le hadoop et pourquoi des centaines de gigaoctets peuvent y être consommés beaucoup plus rapidement qu'un grep ordinaire.
Hadoop
Hadoop est un entrepôt de données distribué. Les données ne se trouvent pas sur un serveur séparé, mais sont réparties entre plusieurs machines et sont également stockées non pas dans une seule instance, mais dans plusieurs - cela a été fait pour garantir la fiabilité. La base de la vitesse de traitement des données réside dans un changement d'approche par rapport aux bases de données conventionnelles.
Dans le cas d'une base de données régulière, nous en extrayons les données et les envoyons au client, qui effectue une sorte d'analyse et renvoie le résultat à l'analyste. Ainsi, pour compter plus rapidement, nous devons avoir de nombreux clients et paralléliser les demandes (par exemple, pour diviser les données par mois - et chaque client peut lire les données de son mois).
Dans hadoop, l'inverse est vrai. Nous envoyons le code (exactement ce que nous voulons calculer) aux données, et ce code est exécuté sur le cluster. Comme nous le savons, les données se trouvent sur de nombreuses machines, de sorte que chaque machine exécute uniquement du code sur ses données et renvoie le résultat au client.
Beaucoup ont probablement entendu parler de la
réduction de
carte , mais l'écriture de code pour l'analyse n'est pas très pratique et rapide, tandis que l'écriture en SQL est beaucoup plus simple. Par conséquent, il est apparu des services qui peuvent transformer SQL en carte-réduire de manière transparente pour l'utilisateur, et l'analyste peut ne pas soupçonner comment sa demande est réellement considérée.
Dans hh.ru, nous utilisons pour cela ruche et presto. Hive a été le premier, mais nous passons progressivement à presto, car il est beaucoup plus rapide pour nos demandes. En tant qu'interface graphique, nous utilisons hue et zeppelin.
Il est plus pratique pour moi de considérer les analyses en python dans jupyter, cela nous permet de le lire en un seul clic et d'obtenir des tableaux Excel correctement formatés à la sortie, ce qui fait gagner beaucoup de temps. Écrivez dans les commentaires, ce sujet fait l'objet d'un article séparé.
Revenons à l'analyse elle-même.
Comment comprendre ce que nous voulons considérer?
Le chef de produit est venu avec la tâche de calculer les résultats de l'expérience
Nous envoyons une newsletter par e-mail dans laquelle nous envoyons les offres d'emploi appropriées pour le candidat (tout le monde aime-t-il de tels mailings?). Nous avons décidé de changer un peu la conception de la lettre et voulons savoir si elle s'est améliorée. Pour cela nous considérerons:
- le nombre de transitions vers les postes vacants à partir de la lettre;
- rétroaction après la transition
Permettez-moi de vous rappeler que tout ce que nous avons, c'est un journal d'accès et une base de données. Nous devons formuler nos mesures en termes de clics sur les liens.
Nombre de transitions vers un poste vacant à partir d'une lettre
La transition est une demande GET vers
hh.ru/vacancy/26646861 . Pour comprendre d'où vient la transition, nous ajoutons des balises utm de la forme? Utm_source = email_campaign_123. Pour les demandes GET dans le journal d'accès, il y aura des informations sur les paramètres, et nous ne pouvons filtrer les transitions qu'à partir de notre liste de diffusion.
Le nombre de réponses après la transition
Ici, nous pourrions simplement calculer le nombre de réponses aux offres d'emploi à partir de la newsletter, mais les statistiques seraient incorrectes, car les réponses pourraient être affectées par autre chose, à l'exception de notre lettre, par exemple, une annonce dans ClickMe a été achetée pour une offre d'emploi, et donc le nombre de réponses considérablement grandi.
Nous avons deux options pour formuler le nombre de réponses:
- La réponse est un POST sur hh.ru/applicant/vacancy_response/popup?vacancy_id=26646861 , qui a un référent hh.ru/vacancy/26646861?utm_source=email_campaign_123 .
- La nuance de cette approche est que si l'utilisateur est passé à un poste vacant, puis a fait un peu le tour du site et a ensuite répondu à un poste vacant, nous ne le comptons pas.
- Nous pouvons nous souvenir de l'ID de l'utilisateur qui est passé à hh.ru/vacancy/26646861 et calculer le nombre d'avis pour le poste vacant pendant la journée sur la base de la base de données.
Le choix de l'approche est déterminé par les besoins de l'entreprise, généralement la première option est suffisante, mais tout dépend de ce que le chef de produit attend.
Pièges pouvant survenir
- Toutes les données ne sont pas dans hadoop, vous devez ajouter des données de la base de données prod. Par exemple, dans les journaux, généralement uniquement l'ID, et si vous avez besoin d'un nom - il se trouve dans la base de données. Parfois, vous devez rechercher un utilisateur par resume_id, et cela est également stocké dans la base de données. Pour ce faire, nous déchargeons une partie de la base de données dans hadoop afin que la jointure soit plus simple.
- Les données peuvent être des courbes. C'est généralement un désastre pour hadoop et la façon dont nous y chargeons les données. Selon les données, une valeur vide peut être nulle, aucune, aucune, une chaîne vide, etc. Vous devez être prudent dans chaque cas, car les données sont vraiment différentes, chargées de différentes manières et à différentes fins.
- Compte long pour toute la période. Par exemple, nous devons calculer nos transitions et nos réponses pour le mois. Cela représente environ 3 téraoctets de journaux. Même hadoop prendra cela pendant un certain temps. Habituellement, écrire une demande de travail à 100% la première fois est assez difficile, nous l'écrivons donc par essais et erreurs. Chaque fois, attendre 20 minutes, c'est très long. Façons de résoudre:
- Débogage de la demande sur les journaux en 1 jour. Étant donné que nous avions partitionné les données dans hadoop, il est assez rapide de calculer quelque chose pour 1 jour de journaux.
- Téléchargez les journaux nécessaires dans la table temporaire. En règle générale, nous comprenons les URL qui nous intéressent et nous pouvons créer une table temporaire pour les journaux à partir de ces URL.
Personnellement, la première option me convient mieux, mais, parfois, je dois faire une table temporaire, cela dépend de la situation. - Distorsions dans les métriques finales
- Il est préférable de filtrer les journaux. Vous devez faire attention, par exemple, au code de réponse, à la redirection, etc. Mieux vaut moins de données, mais plus précises, dont vous êtes sûr.
- Le moins d'étapes intermédiaires possible dans la métrique. Par exemple, le passage à un poste vacant est une étape (demande GET pour / vacancy / 123). La réponse est deux (transition vers la vacance + POST). Plus la chaîne est courte, moins il y a d'erreurs et plus précisément la métrique. Parfois, il arrive que les données entre les transitions soient perdues et il est généralement impossible de calculer quelque chose. Pour résoudre ce problème, nous devons réfléchir à ce que nous allons considérer et comment avant de développer une expérience. Votre journal séparé des événements nécessaires aide beaucoup. Nous pouvons filmer les événements nécessaires, et ainsi la chaîne d'événements sera plus précise, et le comptage est plus facile.
- Les bots peuvent générer un tas de transitions. Vous devez comprendre où les bots peuvent aller (par exemple, sur les pages où l'autorisation est requise, ils ne devraient pas l'être) et filtrer ces données.
- Grosses bosses - par exemple, dans l'un des groupes, il peut y avoir un candidat, ce qui génère 50% de toutes les réponses. Il y aura une asymétrie des statistiques, ces données doivent également être filtrées.
- Il est difficile de formuler ce qu'il faut considérer en termes de journal d'accès. Cela permet de connaître la base de code, l'expérience et les outils de développement Chrome. Nous lisons la description de la métrique du produit, la répétons avec nos mains sur le site et voyons quelles transitions sont générées.
Enfin, parlons de l'apparence du résultat des calculs.
Résultat du calcul
Dans notre exemple, il existe 2 groupes et 2 mesures qui forment un entonnoir.
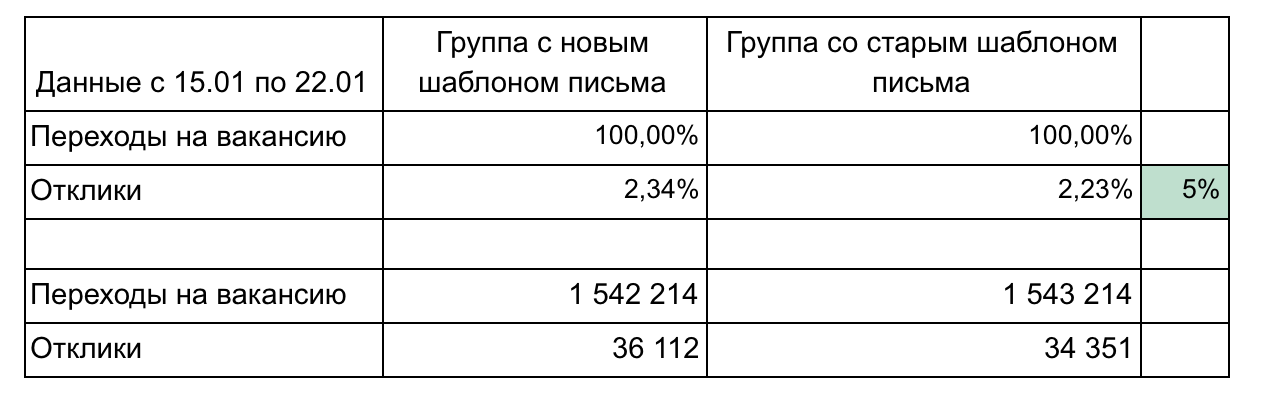
Recommandations pour la communication des résultats:
- Ne surchargez pas les pièces jusqu'à ce que vous en ayez besoin. Simple et plus petit, c'est mieux (par exemple, ici, nous pourrions afficher chaque poste vacant séparément ou les clics par jour). Concentrez-vous sur une chose.
- Des détails peuvent être nécessaires lors des résultats de la démonstration, alors réfléchissez aux questions que vous pourriez poser et préparez les détails. (Dans notre exemple, le détail peut être fonction de la vitesse de transition après l'envoi de l'e-mail - 1 jour, 3 jours, une semaine, regroupement des postes vacants par domaine professionnel)
- N'oubliez pas la signification statistique. Par exemple, une variation de 1% avec 100 clics et 15 clics est insignifiante et pourrait être aléatoire. Utilisez des calculatrices
- Automatisez autant que possible, car vous devrez compter plusieurs fois. Habituellement, au milieu d'une expérience, on veut déjà comprendre comment les choses se passent. Après l'expérience, des questions peuvent se poser et vous devrez clarifier quelque chose. Ainsi, il faudra compter 3-4 fois, et si chaque calcul est une séquence de 10 requêtes puis une copie manuelle pour exceller, cela fera mal et passera beaucoup de temps. Apprenez le python, cela vous fera gagner une tonne de temps.
- Utilisez une représentation graphique des résultats lorsque cela est justifié. Les outils intégrés de ruche et de zeppelin vous permettent de créer des graphiques simples hors de la boîte.
Il est nécessaire de considérer assez souvent diverses mesures, car nous émettons presque toutes les tâches dans le cadre d'une expérience A / B. Il n'y a rien de compliqué dans les calculs, après 2-3 expériences, une compréhension vient de la façon de procéder. N'oubliez pas que les journaux d'accès stockent de nombreuses informations utiles qui peuvent faire économiser de l'argent aux entreprises, vous aider à promouvoir votre idée et prouver laquelle des options de changement est la meilleure. L'essentiel est de pouvoir obtenir ces informations.