TL; DR : l'auteur a compilé un collecteur NetFlow / sFlow de GoFlow , Kafka , ClickHouse , Grafana et une béquille sur Go.
Bonjour, je suis un exploiteur et j'aime vraiment savoir ce qui se passe dans l'infrastructure. Et j'aime aussi entrer dans les affaires des autres, et cette fois je suis monté dans le réseau.
Supposons que vous ayez votre propre équipement réseau et un sac de monolithes, de microservices et de monolithes de microservices collés à Internet avec leurs dépendances sous forme de bases de données, caches et serveurs FTP. Et parfois, certains habitants de ce sac commencent à jouer coquine dans un réseau.
Voici quelques exemples de ces farces:
- sauvegarde en dehors de la fenêtre prescrite dans 40 flux;
- erreurs de configuration lors de l'envoi d'une application dans un contrôleur de domaine vers le cache d'un autre contrôleur de domaine;
- questions de l'application dans le rack suivant au même cache "donnez-moi cet objet demi-mégaoctet du cache" deux cents fois par seconde.
Les compteurs SNMP des ports de commutateur ou des machines virtuelles ne donneront qu'une compréhension approximative de ce qui se passe, mais je veux une précision et une vitesse d'analyse des problèmes. Les protocoles NetFlow / IPFIX et sFlow viennent à la rescousse, qui génèrent des informations de trafic riches directement à partir de l'équipement réseau. Il reste à le mettre quelque part et à le traiter d'une manière ou d'une autre.
Parmi les collecteurs NetFlow disponibles, les suivants ont été pris en compte:
- flow-tools - je n'aimais pas le stockage dans les fichiers (il a fallu beaucoup de temps pour faire des sélections, en particulier opérationnelles pendant la réaction à l'incident) ou MySQL (avoir une table de milliards de lignes semble être une idée assez sombre);
- Elasticsearch + Logstash + Kibana est un groupe très gourmand en ressources, jusqu'à 6 cœurs du processeur âgé de 2,2 GHz pour recevoir 5000 flux par seconde. Cependant, Kibana vous permet de coller tout type de filtres dans le navigateur, ce qui est précieux;
- vflow - n'a pas aimé le format de sortie (JSON, qui sans modification ne peut pas être ajouté au même Elasticsearch);
- solutions en boîte - n'a pas aimé le prix élevé ou la petite différence par rapport à celui sélectionné.
Et il a été choisi décrit dans la présentation de Louis Poinsignon sur le RIPE 75 . Le schéma général d'un simple collecteur est le suivant:
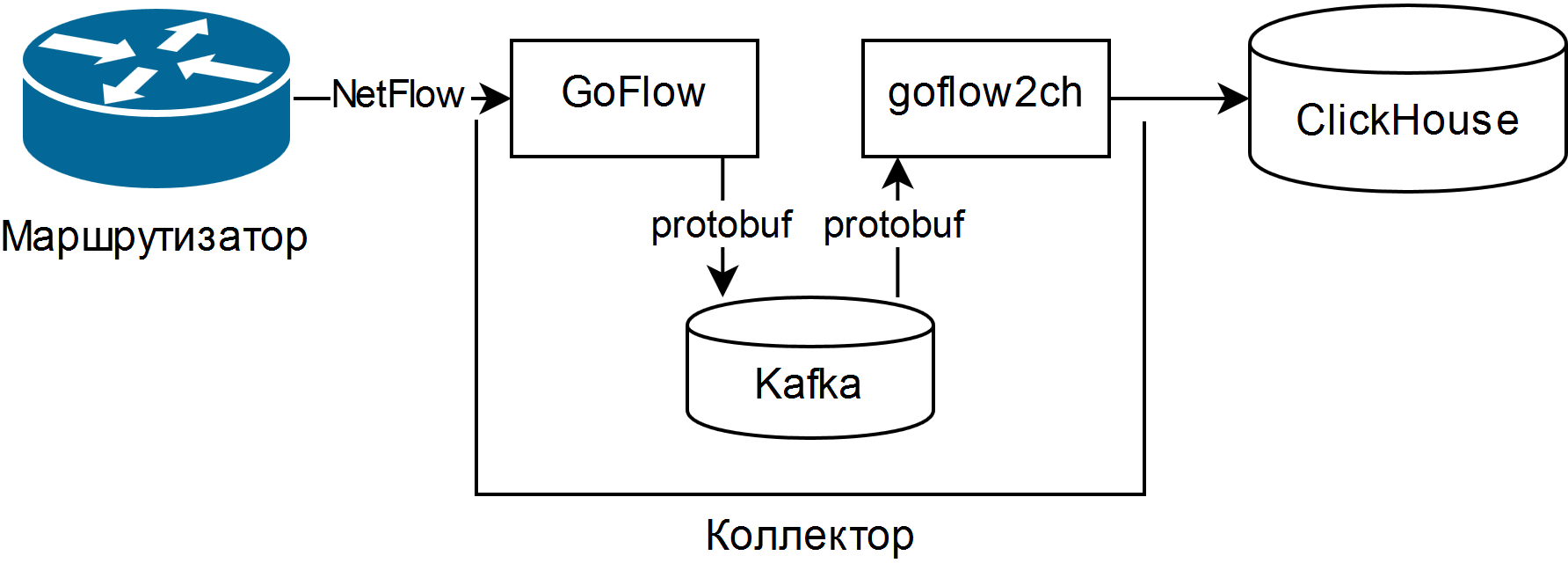
GoFlow analyse les paquets NetFlow / sFlow et les place dans un Kafka local au format protobuf. La «pelle» goflow2ch auto-écrite prend les messages de Kafka et les transfère à Clickhouse par lots pour une plus grande productivité. Le schéma ne traite pas du tout du problème de la haute disponibilité, mais pour chaque composant, il existe des moyens externes réguliers ou plus ou moins simples de le fournir.
Les tests ont montré que les coûts du processeur pour l'analyse et la maintenance des mêmes 5000 threads par seconde représentent environ un quart du cœur du processeur, et l'espace disque consommé est en moyenne de 11 à 14 octets par flux légèrement tronqué.
Pour afficher les informations, soit l'interface utilisateur Web pour ClickHouse appelée Tabix ou le plugin pour Grafana est utilisé .
Les avantages du régime:
- la possibilité de poser des questions arbitraires sur l'état du réseau en utilisant le dialecte SQL;
- faibles besoins en ressources et évolutivité horizontale. Les processeurs anciens / lents et les disques durs magnétiques feront l'affaire;
- si nécessaire, un pipeline de données à part entière est collecté pour analyser les événements du réseau, y compris en temps réel à l'aide de Kafka Streams, Flink ou analogues;
- la possibilité de modifier le stockage à tout moyen minimum.
Les inconvénients sont également décents:
- pour poser des questions, vous devez bien connaître SQL et son dialecte ClickHouse, il n'y a pas de rapports et de graphiques prêts à l'emploi;
- de nombreuses nouvelles pièces mobiles sous la forme de Kafka, Zookeeper et ClickHouse. Les deux premiers sont à Java, ce qui peut provoquer un rejet religieux. Pour moi personnellement, ce n'était pas un problème, car tout cela était déjà en quelque sorte utilisé dans l'organisation;
- avoir à écrire du code. Soit une «pelle» transférant les données de Kafka vers ClickHouse, soit un adaptateur pour l'enregistrement directement depuis GoFlow.
Caractéristiques rencontrées:
- Assurez-vous d'ajuster la rotation en fonction de la taille des données dans Kafka et ClickHouse, puis vérifiez que cela fonctionne vraiment. Dans Kafka, il y a une limite sur la taille de la partition de journal, et dans ClickHouse - partitionnement par une clé arbitraire. Une nouvelle partition toutes les heures et la suppression des partitions inutiles toutes les 10 minutes fonctionnent bien pour la surveillance opérationnelle et se font un script à partir de quelques lignes seulement;
- "Pelle" bénéficie de l'utilisation de groupes de consommateurs , vous permettant d'ajouter plus de "pelles" pour la tolérance d'échelle et de panne;
- Kafka vous permet de ne pas perdre de données lorsque la «pelle» ou ClickHouse se bloque (par exemple, à partir d'une demande lourde et / ou de ressources incorrectement limitées), mais il vaut mieux, bien sûr, configurer soigneusement la base de données;
- si vous collectez sFlow, n'oubliez pas que certains commutateurs modifient par défaut le taux d'échantillonnage des paquets lors de vos déplacements, et il est indiqué pour chaque flux.
En conséquence, un outil pour surveiller la situation du réseau à la fois en plus ou en moins en temps réel et dans la perspective historique, a été obtenu à partir de composants open source et de ruban électrique bleu. Malgré sa profondeur jusqu'aux genoux, il a déjà contribué à réduire le temps nécessaire pour résoudre plusieurs incidents à la fois.