
Aujourd'hui est le 27 septembre, ce qui
signifie que pendant les heures de travail (selon le fuseau horaire américain), nous pouvons nous attendre à la prochaine version de Kubernetes - 1.12 (cependant, son annonce officielle est parfois retardée). En général, il est temps de poursuivre la glorieuse tradition et de parler des changements les plus importants, ce que nous ferons en fonction des informations publiques du projet:
Kubernetes présente le tableau de suivi ,
CHANGELOG-1.12 , de nombreux problèmes, demandes de tirage et propositions de conception. Alors, quoi de neuf dans K8s 1.12?
Installations de stockage
Si vous identifiez une chose qui est mentionnée plus souvent que toute autre parmi tous les problèmes liés à la sortie de Kubernetes 1.12, ce sera peut-être l'
interface de stockage de conteneurs (CSI) , dont nous avons
déjà parlé l'autre jour. Pour cette raison, commençons par les modifications apportées à la prise en charge du stockage.
En tant que tels
, les plugins CSI ont conservé le statut bêta et devraient être stables pour la prochaine version de Kubernetes (1.13). Quoi de neuf dans le support CSI?
En février de cette année
, les travaux sur
le concept de topologie ont commencé dans la spécification CSI elle-même. En bref, la topologie est une information sur la segmentation des clusters (par exemple, par «racks» pour les installations sur site ou par «régions» et «zones» pour les environnements cloud), que les systèmes d'orchestration doivent connaître et prendre en compte. Pourquoi? Les volumes alloués par les fournisseurs de stockage ne seront pas nécessairement également accessibles dans tout le cluster, et par conséquent, la connaissance de la topologie est nécessaire pour planifier efficacement les ressources et prendre des décisions de provisionnement.
Le résultat de l'émergence des topologies dans CSI (
adopté dans la spécification le 1er juin) a été leur support dans Kubernetes 1.12:
Mais cela ne se termine pas avec les mises à jour liées à CSI. Une autre innovation importante dans la version 1.12 de Kubernetes est la
prise en charge des instantanés pour CSI (en état alpha). Des instantanés des volumes en tant que tels sont apparus dans la
version de K8s 1.8 . L'implémentation principale, qui comprend le contrôleur et le provisionneur (deux fichiers binaires séparés), a été décidée pour être transférée vers
un référentiel externe . Depuis lors, la prise en charge des volumes de GCE PD, AWS EBS, OpenStack Cinder, GlusterFS et Kubernetes hostPath a été ajoutée.
La nouvelle
proposition de conception vise à «poursuivre cette initiative en ajoutant la prise en charge des instantanés pour les pilotes de volume CSI» (la prise en charge des instantanés dans la spécification CSI est décrite
ici ). Étant donné que Kubernetes adhère au principe d'inclure un ensemble minimum de capacités dans l'API principale, cette implémentation (comme pour les instantanés dans le Volume Snapshot Controller) utilise CRD (
CustomResourceDefinitions ).
Et quelques nouvelles fonctionnalités pour les pilotes CSI:
- La version alpha de la capacité du pilote à s’inscrire dans l’API Kubernetes (afin de permettre aux utilisateurs de trouver plus facilement les pilotes installés dans le cluster et de permettre aux pilotes d’influencer les processus d’interaction de Kubernetes avec eux);
- Version alpha de la capacité du pilote à recevoir des informations sur le lecteur demandant le volume via
NodePublish .
Introduit dans la dernière version de Kubernetes, le
mécanisme de limitation dynamique des volumes sur les nœuds est passé de l'alpha à la bêta, en
recevant ... vous l'aurez deviné, la prise en charge de CSI, ainsi que d'Azure.
Enfin, la fonctionnalité de
propagation de l'espace de noms Mount , qui vous permet de monter le volume en tant que
rshared (de sorte que tous les répertoires de conteneurs montés soient visibles sur l'hôte) et a un statut bêta dans la version
K8s 1.10 , est déclarée stable.
Planificateur
Dans le planificateur, Kubernetes 1.12 améliore les performances grâce à la version alpha du
mécanisme de restriction de recherche dans un cluster de nœuds adapté à la planification de foyers
(nœuds réalisables) . Auparavant, pour chaque tentative de planification de chaque module,
kube-scheduler vérifiait la disponibilité de tous les nœuds et les transmettait pour évaluation, mais maintenant le planificateur ne trouvera qu'un certain nombre d'entre eux, puis arrêtera son travail. Dans le même temps, le mécanisme prévoit la sélection obligatoire de nœuds de différentes régions et zones, ainsi que la nécessité de visualiser différents nœuds dans différents cycles de planification (ne sélectionnez pas les 100 premiers nœuds à chaque démarrage). La décision de mettre en œuvre ce mécanisme a été prise, guidée par les résultats de l'analyse des données sur les performances de l'ordonnanceur (si le 90e centile montrait un temps de 30 ms pour un foyer, alors le 99e centile déjà 60 ms).
De plus, les fonctionnalités suivantes de l'ordonnanceur ont atteint la version bêta:
- Taint node by Condition , qui est apparu dans K8s 1.8 et permet de marquer un nœud avec un certain statut (pour d'autres actions) lorsque certains événements se produisent: maintenant le contrôleur de cycle de vie du nœud crée automatiquement des taches, et le planificateur les vérifie (au lieu de conditions );
DaemonSet foyer dans DaemonSet utilisant kube-scheduler (au lieu du contrôleur DaemonSet ): il a également été activé par défaut;- spécifiant une classe de priorité dans
ResourceQuota .
Noeuds de cluster
Une innovation intéressante a été l'apparition (dans l'état de la version alpha) de
RuntimeClass - une nouvelle ressource au niveau du cluster conçue pour servir les paramètres de l'
exécution du
conteneur (exécution du conteneur) .
RuntimeClasses sont attribuées aux pods via le même champ dans
PodSpec et implémentent la prise en charge de l'utilisation de plusieurs environnements exécutables au sein d'un cluster ou d'un nœud. Pourquoi?
«L'intérêt pour l'utilisation de différents temps d'exécution dans un cluster augmente. À l'heure actuelle, le principal facteur de motivation est les bacs à sable et le désir des conteneurs Kata et gVisor de s'intégrer à Kubernetes. D'autres modèles d'exécution tels que les conteneurs Windows ou même les environnements d'exécution distants nécessiteront également une prise en charge à l'avenir. RuntimeClass offre un moyen de choisir entre différents runtimes configurés dans un cluster et de modifier leurs propriétés (à la fois par le cluster et par l'utilisateur). »
Pour choisir entre les configurations prédéfinies, le
RuntimeHandler passé au CRI (Container Runtime Interface), qui est destiné à remplacer les annotations actuelles du foyer:

Et la configuration dans containerd pour kata-runtime ressemble à ceci:
[plugins.cri.containerd.kata-runtime] runtime_type = "io.containerd.runtime.v1.linux" runtime_engine = "/opt/kata/bin/kata-runtime" runtime_root = ""
Le critère
RuntimeClass pour la version alpha est une
validation CRI réussie.
En outre, le
mécanisme d'enregistrement des plug-ins locaux (y compris CSI) dans
Kubelet et
shareProcessNamespace (la fonctionnalité est devenue activée par défaut) est passé au statut de version bêta.
Réseaux
La principale nouveauté dans la partie réseau de Kubernetes est la
version alpha du support
SCTP (Stream Control Transmission Protocol). Ayant reçu un support dans
Pod ,
Service ,
Endpoint et
NetworkPolicy , ce protocole de télécommunication a rejoint les rangs de TCP et UDP. Avec la nouvelle fonctionnalité «applications qui nécessitent SCTP comme protocole L4 pour leurs interfaces, il sera plus facile de déployer sur des clusters Kubernetes; par exemple, ils pourront utiliser la découverte de services basée sur
kube-dns , et leur interaction sera contrôlée via
NetworkPolicy . " Les détails d'implémentation sont disponibles dans
ce document .
Deux fonctionnalités réseau introduites dans K8s 1.8 ont également atteint un statut stable: la
prise en charge des stratégies pour le trafic
EgressRules sortant dans l'API NetworkPolicy et l'
application des règles CIDR pour la source / destination via
ipBlockRule .
Mise à l'échelle
Les améliorations apportées à l'autoscaler horizontal Pod comprennent:
L'
échelle verticale des foyers , qui avant d'atteindre la version bêta manquait de tests utilisateur, ne s'arrête pas. Les auteurs l'ont jugée suffisante pour la sortie de K8s 1.12 et
rappellent que cette fonctionnalité est plus susceptible d'être ajoutée à Kubernetes (non incluse dans le noyau). Tout le développement est effectué dans un référentiel séparé, dans lequel la version bêta sera programmée pour coïncider avec la sortie de Kubernetes.
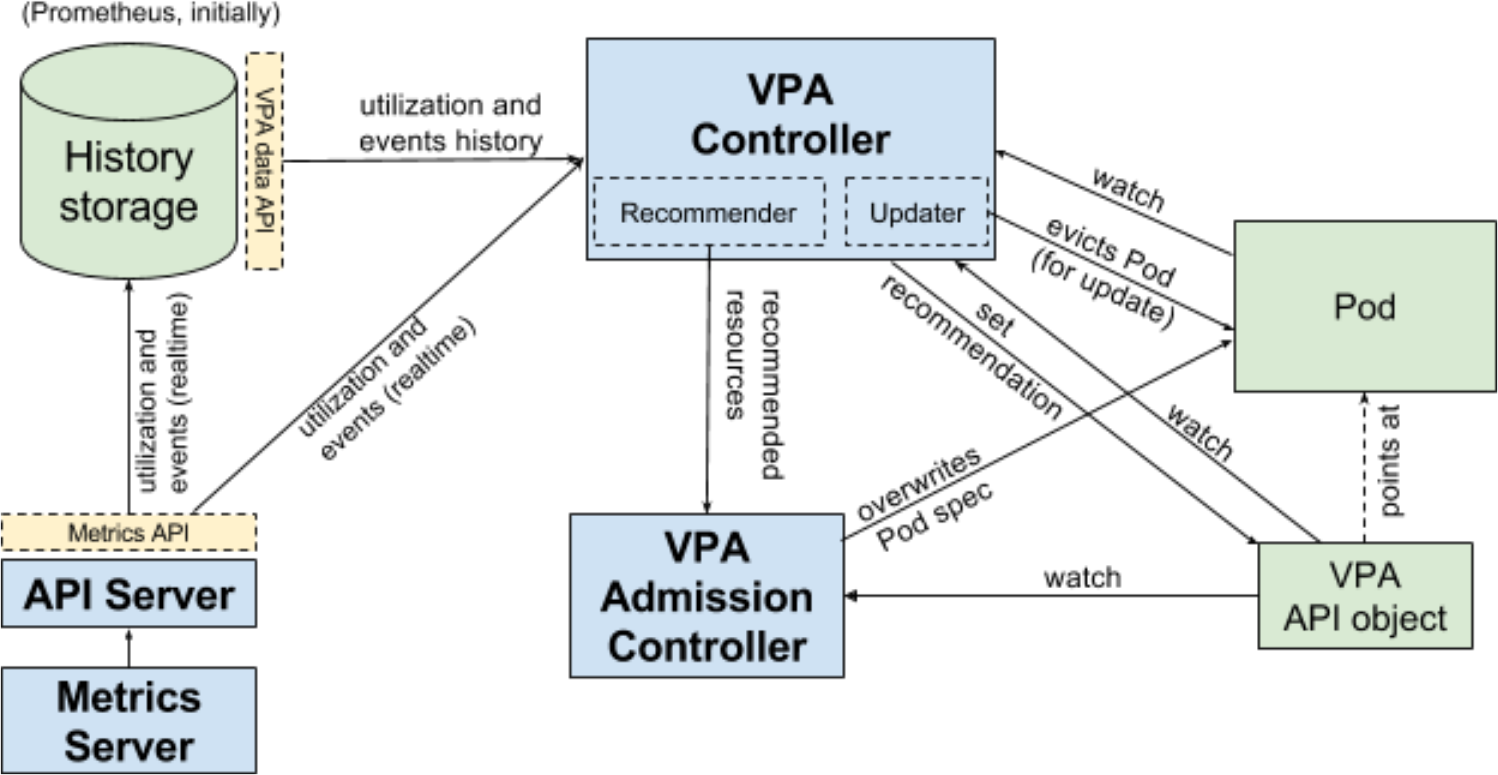 Flux de travail Vertical Pod Autoscaler (VPA) pour Kubernetes
Flux de travail Vertical Pod Autoscaler (VPA) pour KubernetesEnfin, K8s 1.12 inclut (sous forme alpha) les résultats des
travaux sur la "simplification de l'installation à l'aide de
ComponentConfig " (dans le cadre du cycle de vie sig-cluster), qui dure depuis près de deux ans. Malheureusement, pour une raison quelconque (une simple négligence?), L'accès au
document de proposition de conception avec des détails est fermé aux utilisateurs anonymes.
Autres changements
API
Deux nouvelles fonctionnalités sont implémentées dans le groupe api-machines:
dry-run à sec pour apiserver (version alpha), qui imite la validation et le traitement des demandes;- API de quota de ressources (immédiatement bêta) qui définit les ressources qui sont limitées par défaut (au lieu du comportement actuel lorsque la consommation des ressources est illimitée si aucun quota n'est défini).
Azure
Déclarée stable:
Les premières implémentations (versions alpha) sont ajoutées:
Kubectl
- Une version alpha du mécanisme de plug-in mis à jour a été implémentée, ce qui vous permet d'ajouter de nouvelles commandes ou de réécrire des sous-commandes existantes de n'importe quel niveau d'imbrication. Il est similaire à Git et examine les exécutables commençant par
kubectl- dans le $PATH l'utilisateur. Voir la proposition de conception pour plus de détails. - Une version bêta de l' idée d'isoler le
pkg/kubectl/genericclioptions de kubectl dans un référentiel indépendant a été implémentée. - La fonction d' impression côté serveur a été déclarée stable.
Autre
- La version alpha du nouveau mécanisme TTL after finish , conçue pour limiter la durée de vie des Jobs et Pods qui ont terminé leur exécution, est présentée . Après l'expiration du TTL spécifié, les objets seront automatiquement nettoyés sans intervention de l'utilisateur.
- La génération d'une clé privée et d'un CSR (TLS Bootstrap) pour signer un certificat au niveau du cluster dans Kubelet est déclarée stable.
- La rotation du certificat TLS du serveur dans Kubelet est passée au statut bêta.
PS
Lisez aussi dans notre blog: