Nous avons
commencé à étudier les groupes de contrôle (Cgroups) dans Red Hat Enterprise Linux 7 - un mécanisme au niveau du noyau qui vous permet de contrôler l'utilisation des ressources système, avons brièvement passé en revue les fondements théoriques et passons maintenant à la pratique de la gestion des ressources CPU, mémoire et E / S.
Cependant, avant de changer quoi que ce soit, il est toujours utile de savoir comment tout est organisé maintenant.
Il existe deux outils avec lesquels vous pouvez voir l'état des groupes de contrôle actifs dans le système. Tout d'abord, il s'agit de systemd-cgls - une commande qui affiche une liste arborescente de cgroups et de processus en cours d'exécution. Sa sortie ressemble à ceci:
Ici, nous voyons les groupes de contrôle de niveau supérieur: user.slice et system.slice. Nous n'avons pas de machines virtuelles, par conséquent, sous charge, ces groupes de niveau supérieur reçoivent 50% des ressources CPU (car la tranche de machine n'est pas active). Il y a deux tranches enfants dans user.slice: user-1000.slice et user-0.slice. Les tranches d'utilisateurs sont identifiées par l'ID utilisateur (UID), il peut donc être difficile d'identifier le propriétaire, sauf pour l'exécution de processus. Dans notre cas, les sessions ssh montrent que l'utilisateur 1000 est mrichter et l'utilisateur 0 est root, respectivement.
La deuxième commande que nous utiliserons est systemd-cgtop. Il montre une image de l'utilisation des ressources en temps réel (la sortie de systemd-cgls, soit dit en passant, est également mise à jour en temps réel). À l'écran, cela ressemble à ceci:
Il y a un problème avec systemd-cgtop - il affiche des statistiques uniquement pour les services et tranches pour lesquels la comptabilité d'utilisation des ressources est activée. La comptabilité est activée en créant des fichiers de configuration de dépôt dans les sous-répertoires appropriés dans / etc / systemd / system. Par exemple, le drop-in dans la capture d'écran ci-dessous permet l'utilisation du CPU et de la mémoire pour le service sshd. Pour ce faire vous-même, créez simplement le même drop-in dans un éditeur de texte. De plus, la comptabilité peut également être activée avec la commande systemctl set-property sshd.service CPUAccounting = true MemoryAccounting = true.
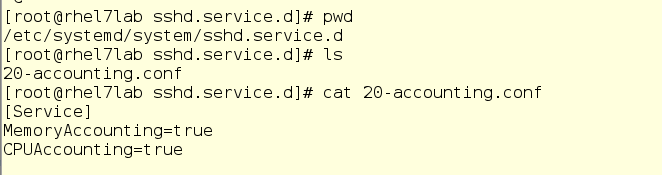
Après avoir créé le drop-in, vous devez entrer la commande systemctl daemon-reload, ainsi que la commande systemctl restart <service_name> pour le service correspondant. En conséquence, vous verrez des statistiques sur l'utilisation des ressources, mais cela créera une charge supplémentaire, car les ressources seront également dépensées pour la comptabilité. Par conséquent, la comptabilité doit être incluse avec soin et uniquement pour les services et les groupes de contrôle qui doivent être contrôlés de cette manière. Cependant, souvent au lieu de systemd-cgtop, vous pouvez le faire avec les commandes top ou iotop.
Changez les boules CPU pour le plaisir et utilement
Voyons maintenant comment un changement dans la boule du processeur (partages CPU) affecte les performances. Par exemple, nous aurons deux utilisateurs non privilégiés et un service système. L'utilisateur avec la connexion mrichter a un UID de 1000, qui peut être vérifié en utilisant le fichier / etc / passwd.
Ceci est important car les tranches d'utilisateurs sont nommées par UID et non par nom de compte.
Passons maintenant au répertoire de dépôt et voyons s'il y a déjà quelque chose pour sa tranche.
Non, il n'y a rien. Bien qu'il y ait autre chose - jetez un œil aux choses liées à foo.service:
Si vous connaissez les fichiers d'unité systemd, vous verrez ici un fichier d'unité tout à fait ordinaire qui exécute la commande / usr / bin / sha1sum / dev / zero en tant que service (en d'autres termes, un démon). Pour nous, l'important est que foo prenne littéralement toutes les ressources processeur que le système lui permettra d'utiliser. De plus, ici, nous avons un paramètre drop-in pour le service foo, la valeur des boules CPU est égale à 2048. Par défaut, comme vous vous en souvenez, il est utilisé avec la valeur 1024, donc sous charge foo recevra une double part des ressources CPU dans le system.slice , sa tranche de niveau supérieur parent (puisque foo est un service).
Maintenant, exécutez foo via systemctl et voyez ce que la commande supérieure nous montre:
Puisqu'il n'y a pratiquement aucun autre élément fonctionnel dans le système, le service foo (pid 2848) consomme presque tout le temps processeur d'un processeur.
Introduisons maintenant mrichter dans l'équation de l'utilisateur. D'abord, nous lui avons coupé une boule CPU jusqu'à 256, puis il se connecte et démarre foo.exe, en d'autres termes, le même programme, mais en tant que processus utilisateur.
Alors mrichter a lancé foo. Et voici ce que la commande supérieure montre maintenant:
Étrange, hein? L'utilisateur mrichter semble obtenir environ 10 pour cent du temps processeur, car il a = 256 billes, et foo.service en a jusqu'à 2048, non?
Maintenant, nous introduisons dorf dans l'équation. Il s'agit d'un autre utilisateur ordinaire avec une bille CPU standard égale à 1024. Il exécutera également foo, et encore une fois, nous verrons comment la distribution du temps du processeur va changer.
dorf est un utilisateur de la vieille école, il commence juste le processus, sans aucun script intelligent ni rien d'autre. Et encore une fois, nous regardons la sortie de haut:
Alors ... jetons un coup d'œil à l'arborescence cgroups et essayons de comprendre ce qui est quoi:
Si vous vous souvenez, généralement dans un système, il existe trois groupes de contrôle de niveau supérieur: système, utilisateur et machine. Puisqu'il n'y a pas de machines virtuelles dans notre exemple, seules les tranches système et utilisateur restent. Chacun d'eux a une CPU-boule de 1024, et donc sous charge, il reçoit la moitié du temps processeur. Étant donné que foo.service vit dans System et qu'il n'y a aucun autre candidat pour le temps CPU dans cette tranche, foo.service reçoit 50% des ressources CPU.
De plus, les utilisateurs dorf et mrichter vivent dans la tranche utilisateur. La première balle est 1024, la seconde - 256. Par conséquent, dorf obtient quatre fois plus de temps processeur que mrichter. Voyons maintenant ce que le top montre: foo.service - 50%, dorf - 40%, mrichter - 10%.
En traduisant cela dans un langage de cas d'utilisation, nous pouvons dire que dorf a une priorité plus élevée. Par conséquent, les groupes de contrôle sont configurés de sorte que l'utilisateur mrichter coupe les ressources pendant le temps dont il a besoin. En effet, après tout, alors que mrichter était dans le système seul, il a reçu 50% du temps du processeur, car dans la tranche utilisateur, personne d'autre n'a concouru pour les ressources CPU.
En fait, les balles CPU sont un moyen de fournir un certain «minimum garanti» de temps processeur, même pour les utilisateurs et les services de priorité inférieure.
De plus, nous avons un moyen de fixer un quota dur pour les ressources CPU, une certaine limite en chiffres absolus. Nous le ferons pour l'utilisateur mrichter et verrons comment la distribution des ressources change.
Maintenant, tuons les tâches de l'utilisateur dorf, et voici ce qui se passe:
Pour mrichter, la limite CPU absolue est de 5%, donc foo.service obtient le reste du temps processeur.
Continuez l'intimidation et arrêtez foo.service:
Ce que nous voyons ici: mrichter a 5% du temps processeur, et les 95% restants du système sont inactifs. La moquerie formelle, oui.
En fait, cette approche vous permet de pacifier efficacement les services ou les applications qui aiment subitement basculer et tirer toutes les ressources du processeur pour elles-mêmes au détriment des autres processus.
Nous avons donc appris à contrôler la situation actuelle avec les groupes de contrôle. Maintenant, nous creusons un peu plus et voyons comment les cgroup sont implémentés au niveau du système de fichiers virtuel.
Le répertoire racine de tous les cgroups en cours d'exécution se trouve dans / sys / fs / cgroup. Lorsque le système démarre, il se remplit au démarrage des services et autres tâches. Lors du démarrage et de l'arrêt des services, leurs sous-répertoires apparaissent et disparaissent.
Dans la capture d'écran ci-dessous, nous sommes allés dans un sous-répertoire pour le contrôleur CPU, à savoir dans la tranche système. Comme vous pouvez le voir, le sous-répertoire de foo n'est pas encore là. Exécutez foo et vérifiez quelques éléments, à savoir son PID et sa boule de CPU actuelle:
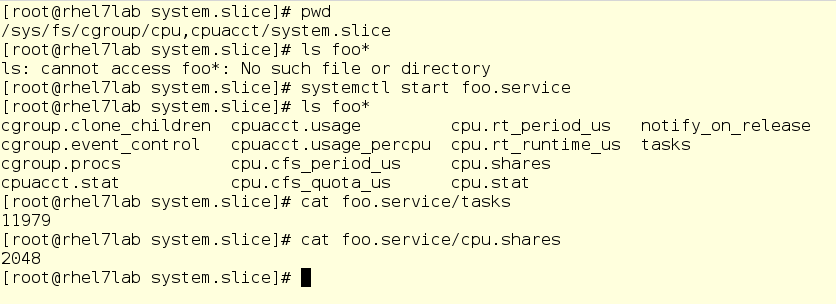
Avertissement important: ici, vous pouvez modifier les valeurs à la volée. Oui, en théorie, ça a l'air cool (et en réalité aussi), mais cela peut se transformer en un gros gâchis. Par conséquent, avant de changer quoi que ce soit, pesez soigneusement tout et ne jouez jamais sur des serveurs de combat. Mais de toute façon, un système de fichiers virtuel est quelque chose à approfondir lorsque vous apprenez comment fonctionnent les groupes de contrôle.