La première édition du CTP de SQL Server 2019 a été présentée le 24 septembre, et permettez-moi de dire qu'elle regorge de toutes sortes d'améliorations et de nouvelles fonctionnalités (dont beaucoup peuvent être trouvées dans le formulaire d'aperçu dans la base de données Azure SQL). J'ai eu une occasion exceptionnelle de l'apprendre un peu plus tôt, ce qui m'a permis d'approfondir ma compréhension des changements, même superficiellement. Vous pouvez également lire les
dernières publications de l'équipe SQL Server et la
documentation mise à jour .
Sans entrer dans les détails, je vais discuter des nouvelles fonctionnalités du noyau suivantes: performances, dépannage, sécurité, disponibilité et développement. Pour le moment, j'ai un peu plus de détails que d'autres, et certains d'entre eux sont déjà prêts pour publication. Je reviendrai sur cette section, ainsi que sur de nombreux autres articles et documentation, et je les publierai. Je m'empresse de vous informer qu'il ne s'agit pas d'une revue complète, mais seulement d'une partie des fonctionnalités que j'ai réussi à «toucher», jusqu'au CTP 2.0. Il y a encore beaucoup à dire.
Performances
Variables du tableau: construction d'un plan différé
Les variables du tableau ont une mauvaise réputation, principalement dans le domaine de l'estimation des coûts. Par défaut, SQL Server suppose qu'une variable de table ne peut contenir qu'une seule ligne, ce qui conduit parfois à un choix de plan inadéquat lorsque la variable contiendra plusieurs fois plus de lignes. OPTION (RECOMPILE) est généralement utilisé comme solution de contournement, mais cela nécessite des modifications de code et il est inutile, par rapport aux ressources, d'effectuer une reconstruction à chaque fois, alors que le nombre de lignes est le plus souvent le même. Pour émuler la reconstruction, l'
indicateur de trace 2453 a été introduit, mais il nécessite également un lancement avec l'indicateur et ne fonctionne que lorsqu'un changement significatif des lignes se produit.
Au niveau de compatibilité 150, une construction différée est effectuée si des variables de table sont présentes et que le plan de requête n'est pas créé tant que la variable de table n'est pas remplie une fois. Le coût sera estimé sur la base des résultats de la première utilisation de la variable de table, sans reconstruction supplémentaire. Il s'agit d'un compromis entre la reconstruction constante pour obtenir le coût exact et l'absence totale de reconstruction à coût constant 1. Si le nombre de lignes reste relativement constant, alors c'est un bon indicateur (et encore mieux si le nombre dépasse 1), mais peut être moins rentable si il y a une grande variation dans le nombre de lignes.
J'ai présenté une analyse plus approfondie dans un article récent
Variables tabulaires: construction différée dans SQL Server , et Brent Ozar en a également parlé dans l'article
Variables tabulaires rapides (et nouveaux problèmes d'analyse des paramètres) .
Commentaires sur l'allocation de mémoire en mode chaîne
SQL Server 2017 a des commentaires d'allocation de mémoire par lots, qui sont décrits en détail
ici . Essentiellement, pour toute allocation de mémoire associée à un plan de requête qui inclut des instructions en mode batch, SQL Server évaluera la mémoire utilisée par la requête et la comparera avec la mémoire demandée. Si la mémoire demandée est trop petite ou trop importante, ce qui entraînera des vidanges dans tempdb ou un gaspillage de mémoire, au prochain démarrage, la mémoire allouée pour le plan de requête correspondant sera ajustée. Ce comportement réduira le volume alloué et augmentera la concurrence, ou l'augmentera, pour améliorer les performances.
Nous obtenons maintenant le même comportement pour les requêtes en mode chaîne, sous le niveau de compatibilité 150. Si la requête a été forcée de fusionner les données sur le disque, alors pour les lancements ultérieurs, la mémoire allouée sera augmentée. Si à la fin de la demande, la moitié de la mémoire requise était supérieure à celle allouée, alors pour les demandes suivantes, elle sera ajustée au fond. Bretn Ozar décrit cela plus en détail dans son article
Allocation de mémoire conditionnelle .
Mode batch pour le stockage ligne par ligne
À partir de SQL Server 2012, l'interrogation des tables avec des index de colonne a bénéficié d'une amélioration des performances du mode batch. Les améliorations des performances sont dues à un processeur de requêtes qui effectue un traitement par lots plutôt que par ligne. Les lignes sont également traitées par le noyau de stockage dans des packages, ce qui évite les instructions d'échange simultané. Paul White (
@SQL_Kiwi ) m'a rappelé que si vous utilisez une table vide avec stockage de colonnes pour rendre possible les opérations par lots, les lignes traitées seront collectées en paquets par une instruction invisible. Cependant, cette béquille peut annuler toute amélioration reçue du traitement par lots. Certaines informations à ce sujet figurent dans la
réponse à Stack Exchange .
Au niveau de compatibilité 150, SQL Server 2019 sélectionnera automatiquement le mode de traitement par lots dans certains cas, même en l'absence d'index de colonne. Vous pourriez penser que pourquoi ne pas simplement créer un index de colonne et un chapeau? Ou continuer à utiliser la béquille mentionnée ci-dessus? Cette approche a également été étendue aux objets traditionnels avec stockage de lignes, car les index de colonnes, pour plusieurs raisons, ne sont pas toujours possibles, y compris les limitations fonctionnelles (par exemple, les déclencheurs), la surcharge lors des opérations de mise à jour ou de suppression très chargées et le manque de prise en charge de fabricants tiers. Et rien de bon ne peut être attendu de cette béquille.
J'ai créé une table très simple avec 10 millions de lignes et un index cluster sur une colonne entière et j'ai exécuté cette requête:
SELECT sa5, sa2, SUM(i1), SUM(i2), COUNT(*) FROM dbo.FactTable WHERE i1 > 100000 GROUP BY sa5, sa2 ORDER BY sa5, sa2;
Le plan montre clairement les recherches d'index cluster et la concurrence, mais pas un mot sur l'index de colonne (comme le montre
SentryOne Plan Explorer ):
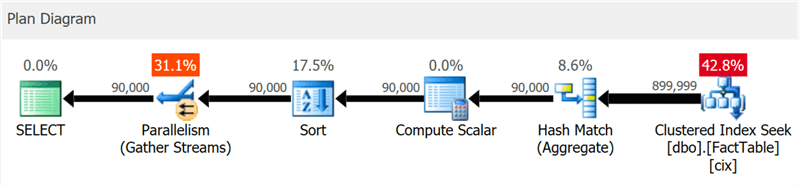
Mais si vous creusez un peu plus profondément, vous pouvez voir que presque tous les opérateurs ont été exécutés en mode batch, même le tri et les calculs scalaires:

Vous pouvez désactiver cette fonctionnalité en restant à un niveau de compatibilité inférieur en modifiant la configuration de la base de données ou en utilisant l'invite DISALLOW_BATCH_MODE dans la requête:
SELECT … OPTION (USE HINT ('DISALLOW_BATCH_MODE'));
Dans ce cas, un opérateur d'échange supplémentaire apparaît, tous les opérateurs sont exécutés en mode ligne par ligne et le temps d'exécution de la requête est presque triplé.

À un certain niveau, vous pouvez le voir dans le diagramme, mais dans l'arborescence des détails du plan, vous pouvez également voir l'influence d'une condition de sélection qui ne peut pas exclure des lignes jusqu'à ce que le tri soit effectué:

Le choix du mode batch n'est pas toujours une bonne étape - l'heuristique incluse dans l'algorithme de prise de décision prend en compte le nombre de lignes, les types d'opérateurs proposés et les bénéfices attendus du mode batch.
APPROX_COUNT_DISTINCT
Cette nouvelle fonction d'agrégation est destinée aux scénarios d'entreposage de données et est l'équivalent de COUNT (DISTINCT ()). Cependant, au lieu d'effectuer des tris coûteux pour déterminer la quantité réelle, la nouvelle fonction s'appuie sur des statistiques pour obtenir des données relativement précises. Vous devez comprendre que l'erreur se situe à moins de 2% du montant exact, et dans 97% des cas qui sont la norme pour les analyses de haut niveau, ce sont les valeurs affichées sur les indicateurs ou utilisées pour des estimations rapides.
Sur mon système, j'ai créé une table avec des colonnes entières qui comprenait des valeurs uniques dans la plage de 100 à 1 000 000 et des colonnes de lignes, avec des valeurs uniques dans la plage de 100 à 100 000. Elle n'avait pas d'index à l'exception de la clé primaire en cluster dans la première colonne entière. Voici les résultats de l'exécution de COUNT (DISTINCT ()) et APPROX_COUNT_DISTINCT () sur ces colonnes, à partir desquelles vous pouvez voir de légères différences (mais toujours à moins de 2%):
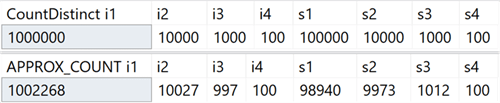
Le gain est énorme s'il y a des limitations de mémoire, ce qui s'applique à la plupart d'entre nous. Si vous regardez les plans de requête, dans ce cas particulier, vous pouvez voir une énorme différence dans la consommation de mémoire par l'opérateur de correspondance de hachage:

Notez que vous ne remarquerez généralement des améliorations significatives des performances que si vous êtes déjà lié à la mémoire. Sur mon système, l'exécution a duré un peu plus longtemps en raison de l'utilisation élevée du processeur de la nouvelle fonctionnalité:

Peut-être que la différence serait plus importante si j'avais des tables plus grandes, moins de mémoire disponible pour SQL Server, une concurrence plus élevée ou une combinaison des éléments ci-dessus.
Conseils pour utiliser le niveau de compatibilité dans une requête
Avez-vous une requête spéciale qui fonctionne mieux sous un certain niveau de compatibilité, différente de la base de données actuelle? Cela est désormais possible grâce à de nouveaux conseils de requête prenant en charge six niveaux de compatibilité différents et cinq modèles différents pour estimer le nombre d'éléments. Voici les niveaux de compatibilité disponibles, un exemple de syntaxe et un modèle de niveau de compatibilité utilisé dans chaque cas. Voyez comment cela affecte les notes, même pour les vues système:

En bref: il n'est plus nécessaire de se souvenir des indicateurs de trace ou de se demander si vous devez vous soucier de savoir si le correctif TF 4199 pour l'optimiseur de requête est distribué ou s'il a été annulé par un autre service pack. Notez que ces conseils supplémentaires ont également été récemment ajoutés pour SQL Server 2017 dans la mise à jour cumulative # 10 (voir
le blog de Pedro Lopez pour plus
de détails). Vous pouvez voir tous les conseils disponibles avec la commande suivante:
SELECT name FROM sys.dm_exec_valid_use_hints;
Mais n'oubliez pas que les conseils sont une mesure exceptionnelle, ils sont souvent adaptés pour sortir d'une situation difficile, mais ne doivent pas être planifiés pour une utilisation à long terme, car leur comportement peut changer avec les mises à jour ultérieures.
Dépannage
Profilage par défaut simplifié
La compréhension de cette amélioration nécessite quelques points à retenir. SQL Server 2014 a introduit la vue DMV sys.dm_exec_query_profiles, qui permet à l'utilisateur exécutant la requête de collecter des informations de diagnostic sur toutes les instructions dans toutes les parties de la requête. Les informations collectées deviennent disponibles après la fin de la requête et vous permettent de déterminer quels opérateurs ont réellement dépensé les principales ressources et pourquoi. Tout utilisateur qui n'a pas répondu à une demande spécifique pouvait recevoir ces données pour toute session dans laquelle l'instruction STATISTICS XML ou STATISTICS PROFILE était incluse, ou pour toutes les sessions, à l'aide de l'événement étendu query_post_execution_showplan, bien que cet événement, en particulier, puisse affecter les performances globales.
Dans Management Studio 2016, une fonctionnalité a été ajoutée qui vous permet d'afficher les flux de données passant par le plan de requête en temps réel sur la base des informations collectées à partir de DMV, ce qui le rend encore plus puissant pour le dépannage. Plan Explorer offre également la possibilité de visualiser les données passant par la requête, à la fois en temps réel et en mode lecture.
À partir de SQL Server 2016 Service Pack 1 (SP1), vous pouvez également activer une version allégée de la collecte de ces données pour toutes les sessions à l'aide de l'indicateur de trace 7412 ou de la propriété avancée query_thread_profile, qui vous permet d'obtenir immédiatement des informations à jour sur n'importe quelle session, sans avoir besoin de quoi que ce soit l'inclure explicitement (en particulier, les éléments qui affectent négativement les performances). Ceci est décrit plus en détail sur le
blog de Pedro Lopez .
Dans SQL Server 2019, cette fonctionnalité est activée par défaut, vous n'avez donc pas besoin d'exécuter de sessions avec des événements étendus ou d'utiliser des indicateurs de trace et des instructions STATISTICS dans une requête. Il suffit de regarder les données du DMV à tout moment pour toutes les sessions simultanées. Mais il est possible de désactiver ce mode à l'aide de LIGHTWEIGHT_QUERY_PROFILING, cependant, cette syntaxe ne fonctionne pas dans CTP 2.0 et sera corrigée dans les éditions futures.
Les statistiques d'index de colonnes en cluster sont désormais disponibles dans les bases de données clonées
Dans les versions actuelles de SQL Server, lors du clonage d'une base de données, seules les statistiques d'objets d'origine des index de colonnes en cluster sont utilisées, à l'exclusion des mises à jour apportées à la table après sa création. Si vous utilisez un clone pour configurer des requêtes et d'autres tests de performances, qui sont basés sur des puissances nominales, ces exemples peuvent ne pas fonctionner. Parikshit Savyani a décrit les limitations
de cette publication et a fourni une solution temporaire - avant de créer le clone, vous devez créer un script qui exécute DBCC SHOW_STATISTICS ... AVEC STATS_STREAM pour chaque objet. C'est cher et, bien sûr, facile à oublier.
Dans SQL Server 2019, ces statistiques mises à jour seront automatiquement disponibles dans le clone, vous pouvez donc tester divers scénarios de requête et obtenir des plans objectifs basés sur des statistiques réelles, sans exécuter manuellement STATS_STREAM pour toutes les tables.
Prévision de compression pour le stockage des colonnes
Dans les versions actuelles, la procédure sys.sp_estimate_data_compression_savings a la vérification suivante:
if (@data_compression not in ('NONE', 'ROW', 'PAGE'))
Cela signifie qu'il vous permet de vérifier la compression d'une ligne ou d'une page (ou de voir le résultat de la suppression de la compression actuelle). Dans SQL Server 2019, cette vérification ressemble maintenant à ceci:
if (@data_compression not in ('NONE', 'ROW', 'PAGE', 'COLUMNSTORE', 'COLUMNSTORE_ARCHIVE'))
C'est une excellente nouvelle car cela vous permet de prédire approximativement l'effet de l'ajout d'un index de colonne à une table qui ne l'a pas, ou de convertir des tables ou des partitions dans un format de stockage de colonne encore plus compressé, sans avoir à restaurer la table sur un autre système. J'avais une table avec 10 millions de lignes, pour laquelle j'ai effectué une procédure stockée avec chacun des cinq paramètres:
EXEC sys.sp_estimate_data_compression_savings @schema_name = N'dbo', @object_name = N'FactTable', @index_id = NULL, @partition_number = NULL, @data_compression = N'NONE';
Résultats:

Comme pour les autres types de compression, la précision dépend entièrement des lignes disponibles et de la représentativité du reste des données. Cependant, c'est un moyen assez puissant pour obtenir des résultats prévisibles sans trop de difficulté.
Nouvelle fonctionnalité pour obtenir des informations sur la page
Pendant longtemps, DBCC PAGE et DBCC IND ont été utilisés pour collecter des informations sur les pages contenant une section, un index ou une table. Mais ils ne sont pas documentés et ne sont pas pris en charge, et il peut être fastidieux d'automatiser la solution des tâches associées à plusieurs index ou pages.
Plus tard, une fonction d'administration dynamique (DMF) sys.dm_db_database_page_allocations est apparue, qui renvoie un ensemble représentant toutes les pages de l'objet spécifié. Encore non documenté et présentant des failles qui peuvent devenir un vrai problème sur les grands tableaux: même pour obtenir des informations sur une page, il faut lire toute la structure, ce qui peut être assez cher.
Dans SQL Server 2019, un autre DMF est apparu - sys.dm_db_page_info. Il retourne essentiellement toutes les informations de la page, sans les frais généraux de la distribution DMF. Cependant, pour utiliser la fonction dans les versions actuelles, vous devez connaître à l'avance le numéro de la page que vous recherchez. Peut-être que cette mesure a été prise intentionnellement, car c'est le seul moyen de garantir les performances. Donc, si vous essayez d'identifier toutes les pages d'un index ou d'une table, vous devez toujours utiliser la distribution DMF. Dans le prochain article, je décrirai cette question plus en détail.
La sécurité
Cryptage permanent à l'aide d'un environnement sécurisé (enclave)
À l'heure actuelle, le chiffrement permanent protège les données sensibles lors de la transmission et en mémoire par chiffrement / déchiffrement à chaque extrémité du processus. Malheureusement, cela conduit souvent à de sérieuses limitations lors de l'utilisation des données, telles que l'impossibilité d'effectuer des calculs et du filtrage, vous devez donc transférer l'ensemble des données du côté client pour effectuer, par exemple, une recherche par plage.
Un environnement sécurisé (enclave) est une zone de mémoire protégée où de tels calculs et filtrages peuvent être délégués (Windows utilise la
sécurité basée sur la
virtualisation ) - les données restent cryptées dans le noyau, mais peuvent être décryptées en toute sécurité ou cryptées dans un environnement sécurisé. Il vous suffit d'ajouter le paramètre ENCLAVE_COMPUTATIONS à la clé primaire à l'aide de SSMS, par exemple, en cochant la case "Autoriser les calculs dans un environnement sécurisé":
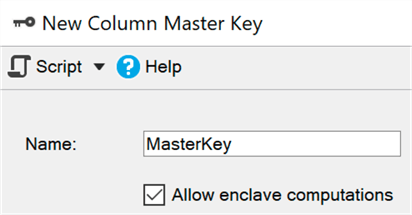
Maintenant, vous pouvez chiffrer les données presque instantanément, par rapport à l'ancienne méthode (dans laquelle l'assistant, la cmdlet Set-SqlColumnEncyption ou votre application, devrait récupérer complètement l'ensemble de la base de données, le chiffrer et le renvoyer):
ALTER TABLE dbo.Patients ALTER COLUMN SSN char(9)
Je pense que pour de nombreuses organisations, cette amélioration sera la principale nouvelle, mais dans le CTP actuel, certains de ces sous-systèmes sont toujours en cours d'amélioration, ils sont donc désactivés par défaut, mais
ici vous pouvez voir comment les activer.
Gestion des certificats dans Configuration Manager
La gestion des certificats SSL et TLS a toujours été difficile et de nombreuses personnes ont été obligées de faire le travail fastidieux de créer leurs propres scripts pour déployer et maintenir leurs certificats d'entreprise. Le gestionnaire de configuration mis à jour pour SQL Server 2019 vous aidera à afficher et à vérifier rapidement les certificats de n'importe quelle instance, à trouver les certificats qui expirent bientôt et à synchroniser les déploiements de certificats entre toutes les réplications du groupe de disponibilité ou tous les nœuds de l'instance de cluster de basculement.
Je n'ai pas essayé toutes ces opérations, mais elles devraient fonctionner pour les versions précédentes de SQL Server si la gestion provient de SQL Server 2019 Configuration Manager.
Classification et audit des données intégrés
L'équipe de développement SQL Server a ajouté la possibilité de classer les données dans SSMS 17.5, vous permettant d'identifier toutes les colonnes qui peuvent contenir des informations sensibles ou contredire diverses normes (HIPAA, SOX, PCI et GDPR, bien sûr). L'assistant utilise un algorithme qui propose des colonnes qui sont censées causer des problèmes, mais vous pouvez soit ajuster sa phrase en supprimant ces colonnes de la liste, soit ajouter la vôtre. Pour stocker la classification, des propriétés avancées sont utilisées; Le rapport SSMS intégré utilise les mêmes informations pour afficher ses données. En dehors du rapport, ces propriétés ne sont pas si évidentes.
SQL Server 2019 a introduit une nouvelle instruction pour ces métadonnées, déjà disponible dans la base de données Azure SQL, et appelée ADD SENSITIVITY CLASSIFICATION. Il vous permet de faire la même chose que l'assistant dans SSMS, mais les informations ne sont plus stockées dans la propriété étendue et tout accès à ces données est automatiquement affiché dans l'audit comme une nouvelle colonne XML data_sensitivity_information. Il contient tous les types d'informations qui ont été affectés lors de l'audit.
À titre d'exemple rapide, supposons que j'ai une table pour les entrepreneurs externes:
CREATE TABLE dbo.Contractors ( FirstName sysname, LastName sysname, SSN char(9), HourlyRate decimal(6,2) );
En regardant une telle structure, il devient clair que les quatre colonnes sont soit potentiellement vulnérables aux fuites, soit devraient être accessibles uniquement à un cercle restreint de personnes. Ici, vous pouvez vous débrouiller avec des autorisations, mais au moins vous devez vous concentrer sur elles. Ainsi, nous pouvons classer ces colonnes de différentes manières:
ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.FirstName, dbo.Contractors.LastName WITH (LABEL = 'Confidential – GDPR', INFORMATION_TYPE = 'Personal Info'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.SSN WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'National ID'); ADD SENSITIVITY CLASSIFICATION TO dbo.Contractors.HourlyRate WITH (LABEL = 'Highly Confidential', INFORMATION_TYPE = 'Financial');
Maintenant, au lieu de regarder sys.extended_properties, vous pouvez les voir dans sys.sensitivity_classifications:

Et si nous effectuons un échantillonnage d'audit (ou DML) pour ce tableau, nous n'avons pas besoin de changer quoi que ce soit spécifiquement; après avoir créé la classification,
SELECT * enregistrera dans le journal d'audit un enregistrement de ce type d'informations dans une nouvelle colonne data_sensitivity_information:
<sensitivity_attributes> <sensitivity_attribute label="Confidential - GDPR" information_type="Personal Info" /> <sensitivity_attribute label="Highly Confidential" information_type="National ID" /> <sensitivity_attribute label="Highly Confidential" information_type="Financial" /> </sensitivity_attributes>
Bien sûr, cela ne résout pas tous les problèmes de conformité aux normes, mais cela peut donner un réel avantage. L'utilisation de l'assistant pour identifier automatiquement les colonnes et traduire les appels sp_addextendedproperty en commandes ADD SENSITIVITY CLASSIFICATION peut grandement simplifier la tâche de conformité aux normes. Plus tard, j'écrirai un article séparé à ce sujet.
Vous pouvez également automatiser la création (ou la mise à jour) des autorisations en fonction de l'étiquette dans les métadonnées - la création d'un script SQL dynamique qui interdit l'accès à toutes les colonnes confidentielles (GDPR), qui vous permettra de gérer les utilisateurs, les groupes ou les rôlesb. Je travaillerai sur cette question à l'avenir.
La disponibilité
Création d'indices renouvelables en temps réel
Dans SQL Server 2017, il est devenu possible de suspendre et de reprendre la reconstruction de l'index en temps réel, ce qui peut être très utile si vous devez modifier le nombre de processeurs utilisés, continuer à partir du moment de la suspension après une panne, ou simplement combler l'écart entre les fenêtres de service. J'ai parlé de cette fonctionnalité dans un
article précédent .
Dans SQL Server 2019, vous pouvez utiliser la même syntaxe pour créer des index en temps réel, suspendre et continuer, ainsi que pour limiter le temps d'exécution (définir le temps de pause):
CREATE INDEX foo ON dbo.bar(blat) WITH (ONLINE = ON, RESUMABLE = ON, MAX_DURATION = 10 MINUTES);
Si cette requête fonctionne trop longtemps, alors pour faire une pause, vous pouvez exécuter ALTER INDEX dans une autre session (même si l'index n'existe pas encore physiquement):
ALTER INDEX foo ON dbo.bar PAUSE;
Dans les versions actuelles, le degré de parallélisme lors du renouvellement ne peut pas être réduit, comme c'est le cas pour la reconstruction. Lorsque vous essayez de réduire le DOP:
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 2);
Nous obtenons ce qui suit:
Msg 10666, Level 16, State 1, Line 3 Cannot resume index build as required DOP 4 (DOP operation was started with) is not available. Please ensure sufficient DOP is available or abort existing index operation and try again. The statement has been terminated.
En fait, si vous essayez de le faire, puis exécutez la commande sans paramètres supplémentaires, vous obtiendrez la même erreur, au moins sur les versions actuelles. Je pense que la tentative de renouvellement a été enregistrée quelque part et que le système a voulu la réutiliser. Pour continuer, vous devez spécifier la valeur DOP correcte (ou supérieure):
ALTER INDEX foo ON dbo.bar RESUME WITH (MAXDOP = 4);
Pour être clair: vous pouvez augmenter le DOP lors de la reprise d'une création d'index interrompue, mais pas la diminuer.
Un avantage supplémentaire de tout cela est que vous pouvez configurer la création et / ou le renouvellement d'index en temps réel comme mode par défaut à l'aide des clauses ELEVATE_ONLINE et ELEVATE_RESUMABLE pour la nouvelle base de données.
Création / reconstruction en temps réel d'index de colonnes en cluster
En plus de la création d'index renouvelables, nous avons également la possibilité de créer ou de reconstruire des index de colonnes en cluster en temps réel. Il s'agit d'un changement important, qui vous permet de ne plus consacrer le temps des fenêtres de service à la maintenance de ces indices ou (pour plus de certitude) de convertir les indices de ligne en colonne:
CREATE TABLE dbo.splunge ( id int NOT NULL ); GO CREATE UNIQUE CLUSTERED INDEX PK_Splunge ON dbo.splunge(id); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (DROP_EXISTING = ON, ONLINE = ON);
Un avertissement: si un index cluster traditionnel existant a été créé en temps réel, sa conversion en index de colonne cluster n'est également possible que dans ce mode. Si elle fait partie de la clé primaire, intégrée ou non ... CREATE TABLE dbo.splunge ( id int NOT NULL CONSTRAINT PK_Splunge PRIMARY KEY CLUSTERED (id) ); GO
Nous obtenons l'erreur suivante: Msg 1907, Level 16 Cannot recreate index 'PK_Splunge'. The new index definition does not match the constraint being enforced by the existing index.
Vous devez d'abord supprimer la contrainte afin de la convertir en un index de colonne en cluster, mais ces deux opérations peuvent être effectuées en temps réel: ALTER TABLE dbo.splunge DROP CONSTRAINT PK_Splunge WITH (ONLINE = ON); GO CREATE CLUSTERED COLUMNSTORE INDEX PK_Splunge ON dbo.splunge WITH (ONLINE = ON);
Cela fonctionne, mais les grandes tables sont susceptibles de prendre plus de temps que si la clé primaire était implémentée en tant qu'index cluster unique. Je ne peux pas dire avec certitude s'il s'agit d'une restriction intentionnelle ou simplement d'une limitation du CTP actuel.Rediriger une connexion de réplication d'un serveur secondaire vers un serveur principal
Cette fonction vous permet de configurer la redirection sans écouter, vous pouvez donc basculer la connexion vers le serveur principal, même si le secondaire est directement spécifié dans la chaîne de connexion. Cette fonction peut être utilisée lorsque la technologie de clustering ne prend pas en charge l'écoute, lors de l'utilisation d'AG sans cluster ou lorsqu'il existe un schéma de redirection complexe dans un scénario avec plusieurs sous-réseaux. Cela empêchera la connexion, par exemple, d'essayer d'écrire des opérations de réplication en mode lecture seule (et des échecs, respectivement).Développement
Fonctions supplémentaires du graphique
Les relations graphiques prennent désormais en charge l'instruction MERGE pour un nœud ou des tables de limites à l'aide de prédicats MERGE; Désormais, un opérateur peut mettre à jour une arête existante ou en insérer une nouvelle. La nouvelle restriction de bord vous permet de déterminer quels nœuds le bord peut se connecter.Utf-8
SQL Server 2012 a ajouté la prise en charge d'UTF-16 et de caractères supplémentaires en définissant le tri en spécifiant un nom avec le suffixe _SC, tel que Latin1_General_100_CI_AI_SC, pour utiliser les colonnes Unicode (nchar / nvarchar). Dans SQL Server 2017, vous pouvez importer et exporter des données UTF-8 depuis et vers ces colonnes à l'aide d'outils tels que BCP et BULK INSERT .Dans SQL Server 2019, il existe de nouvelles options de classement pour prendre en charge la rétention forcée des données UTF-8 dans leur forme d'origine. Vous pouvez donc facilement créer des colonnes char ou varchar et stocker correctement les données UTF-8 en utilisant le nouveau classement avec le suffixe _SC_UTF8, comme Latin1_General_100_CI_AI_SC_UTF8. Cela peut aider à améliorer la compatibilité avec les applications externes et les SGBD, sans coût de traitement et de stockage de nvarchar.Oeuf de Pâques que j'ai trouvé
Pour autant que je m'en souvienne, les utilisateurs de SQL Server se plaignent de ce vague message d'erreur: Msg 8152 String or binary data would be truncated.
Dans les versions CTP que j'ai expérimentées, un message d'erreur intéressant a été remarqué qui n'était pas là avant: Msg 2628 String or binary data would be truncated in table '%.*ls', column '%.*ls'. Truncated value: '%.*ls'
Je ne pense pas que quelque chose d'autre soit nécessaire ici; c'est une grande amélioration (quoique très tardive) qui promet de faire plaisir à beaucoup. Cependant, cette fonctionnalité ne sera pas disponible dans CTP 2.0; Je vous donne juste l'occasion de regarder un peu en avant. Brent Ozar a répertorié tous les nouveaux messages qu'il a trouvés dans le CTP actuel et les a assaisonnés de quelques commentaires utiles dans son article sys.messages: trouver des fonctionnalités supplémentaires .Conclusion
SQL Server 2019 offre de bonnes fonctionnalités supplémentaires qui aideront à améliorer le travail avec votre plate-forme de base de données relationnelle préférée, et il y a un certain nombre de changements dont je n'ai pas parlé. Mémoire économe en énergie, clustering pour les services d'apprentissage automatique, réplication et transactions distribuées sur Linux, Kubernetes, connecteurs pour Oracle / Teradata / MongoDB, les réplications synchrones AG ont augmenté pour prendre en charge Java (la mise en œuvre est similaire à Python / R) et, tout aussi important, un nouveau saut, intitulé Big Data Cluster. Pour utiliser certaines de ces fonctionnalités, vous devez vous inscrire en utilisant ce formulaire EAP .Livre à paraître de Bob Ward, Pro SQL Server sur Linux - Incluant le déploiement basé sur conteneur avec Docker et Kubernetes, peut donner quelques indices sur un certain nombre d'autres choses qui arriveront bientôt. Et cette publication de Brent Ozar parle d'un éventuel correctif à venir pour une fonction scalaire définie par l'utilisateur.Mais même dans ce premier CTP public, il y a quelque chose d'important pour presque tout le monde, et je vous invite à l'essayer vous-même!