Mes amis, bonjour.
Il est clairement admis que la majorité des projets de l'OIC sont essentiellement des actifs incorporels. Le projet ICO n'est pas une voiture Mercedes-Benz - il conduit peu importe qui l'aime ou non. Et l'influence principale sur l'ICO est due à l'humeur des gens - à la fois l'attitude envers le fondateur / fondateur de l'ICO et le projet lui-même.
Il serait bon de mesurer en quelque sorte l'attitude des gens envers le fondateur de l'ICO et / ou du projet ICO. Ce qui a été fait. Le rapport est ci-dessous.
Le résultat a été un outil pour recueillir les humeurs positives / négatives sur Internet, en particulier sur Twitter.
Mon environnement est Windows 10 x64, utilisé le langage Python 3 dans l'éditeur Spyder dans Anaconda 5.1.0, une connexion réseau filaire.
Collecte de données
Je vais avoir l'ambiance des publications Twitter. Tout d'abord, je vais découvrir ce que le fondateur de l'ICO fait maintenant et comment ils réagissent positivement à ce sujet avec l'exemple d'une paire de personnalités célèbres.
J'utiliserai la bibliothèque tweepy de python. Pour travailler avec Twitter, vous devez vous inscrire en tant que développeur, voir twitter / . Obtenez les critères d'accès Twitter.
Le code est le suivant:
import tweepy API_KEY = "vvvvEXQWhuF1fhAqAtoXRrrrr" API_SECRET = "vvvv30kspvqiezyPc26JafhRjRiZH3K12SGNgT0Ndsqu17rrrr" ACCESS_TOKEN = "vvvv712098-WBn6rZR4lXsnZCwcuU0aOsRkENSGpw2lppArrrr" ACCESS_TOKEN_SECRET = "vvvvlG7APRc5yGiWY5xFKfIGpqkHnXAvuwwVzMwyyrrrr" auth = tweepy.OAuthHandler(API_KEY, API_SECRET) auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET) api = tweepy.API(auth)
Maintenant, nous pouvons nous tourner vers l'API Twitter et en tirer quelque chose, ou vice versa. La chose a été faite début août. Vous devez obtenir quelques tweets pour trouver le projet actuel du fondateur. Recherche comme ceci:
import pandas as pd searchstring = searchinfo+' -filter:retweets' results = pd.DataFrame() coursor = tweepy.Cursor(api.search, q=searchstring, since="2018-07-07", lang="en", count = 500) for tweet in coursor.items(): my_series = pd.Series([str(tweet.id), tweet.created_at, tweet.text, tweet.retweeted], index=['id', 'title', 'text', 'retweeted']) result = pd.DataFrame(my_series).transpose() results = results.append(result, ignore_index = True) results.to_excel('results.xlsx')
Dans searchinfo, nous substituons le nom nécessaire et le transmettons. Le résultat a été enregistré dans le fichier excel results.xlsx.
Créatif
J'ai alors décidé de faire une création. Nous devons trouver les projets du fondateur. Les noms de projets sont des noms propres et sont en majuscules. Supposons que cela semble également vrai avec l'inscription d'une majuscule dans chaque tweet: 1) le nom du fondateur, 2) le nom de son projet, 3) le premier mot du tweet et 4) les mots étrangers. Les mots 1 et 2 se retrouvent fréquemment sur les tweets, et 3 et 4 sont rares, en fréquence nous sommes 3 et 4 et nous éliminons. Oui, il s'est également avéré que les liens apparaissent souvent dans les tweets, 5) nous les supprimerons également.
Il s'est avéré comme ceci:
import re import nltk nltk.download('stopwords') from nltk.corpus import stopwords from nltk.stem.porter import PorterStemmer corpus = [] for i in range(0, len(results.index)): review1 = [] mystr = results['text'][i]
Analyse de données créative
Dans la variable des noms, nous avons les mots, et dans la variable X - les endroits où ils sont mentionnés. "Désactiver" le tableau X - obtenez le nombre de références. Nous supprimons les mots rarement mentionnés. Enregistrez dans Excel. Et dans Excel, nous faisons un beau graphique à barres avec des informations sur la fréquence à laquelle les mots sont mentionnés dans quelle requête.
Nos super stars ICO sont Le Minh Tam et Mike Novogratz. Graphiques:
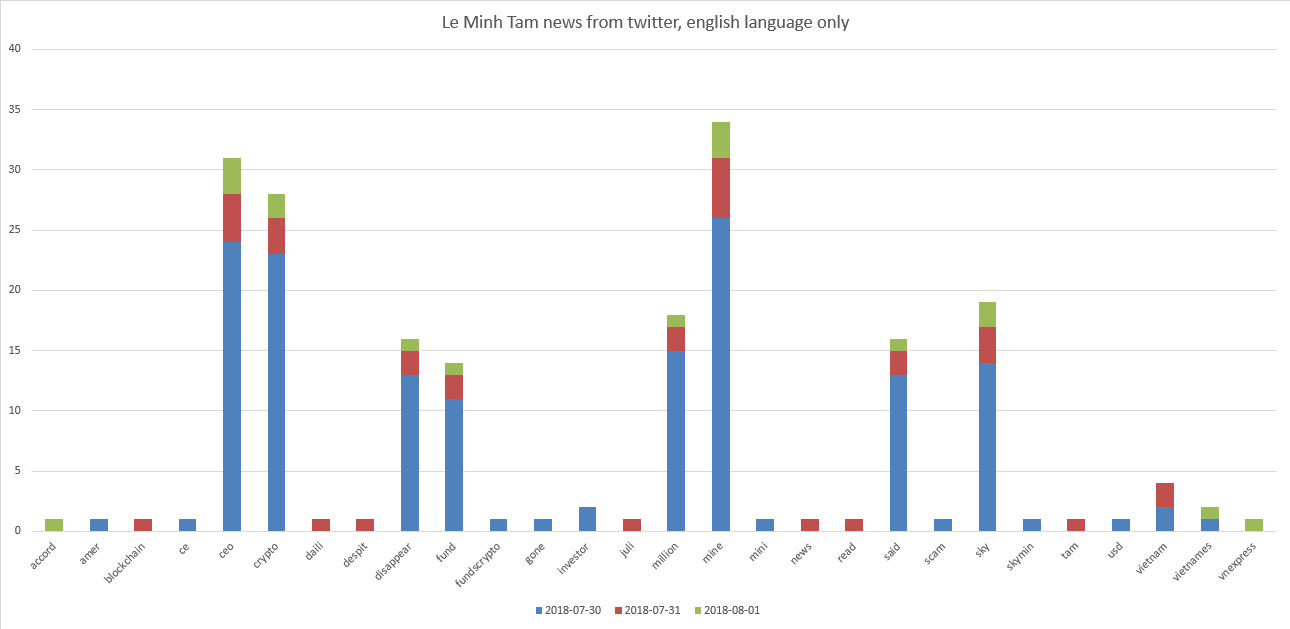
On peut voir que Le Minh Tam est lié à "ceo, crypto, mine, sky". Et un peu pour "disparaître, financer, millions".
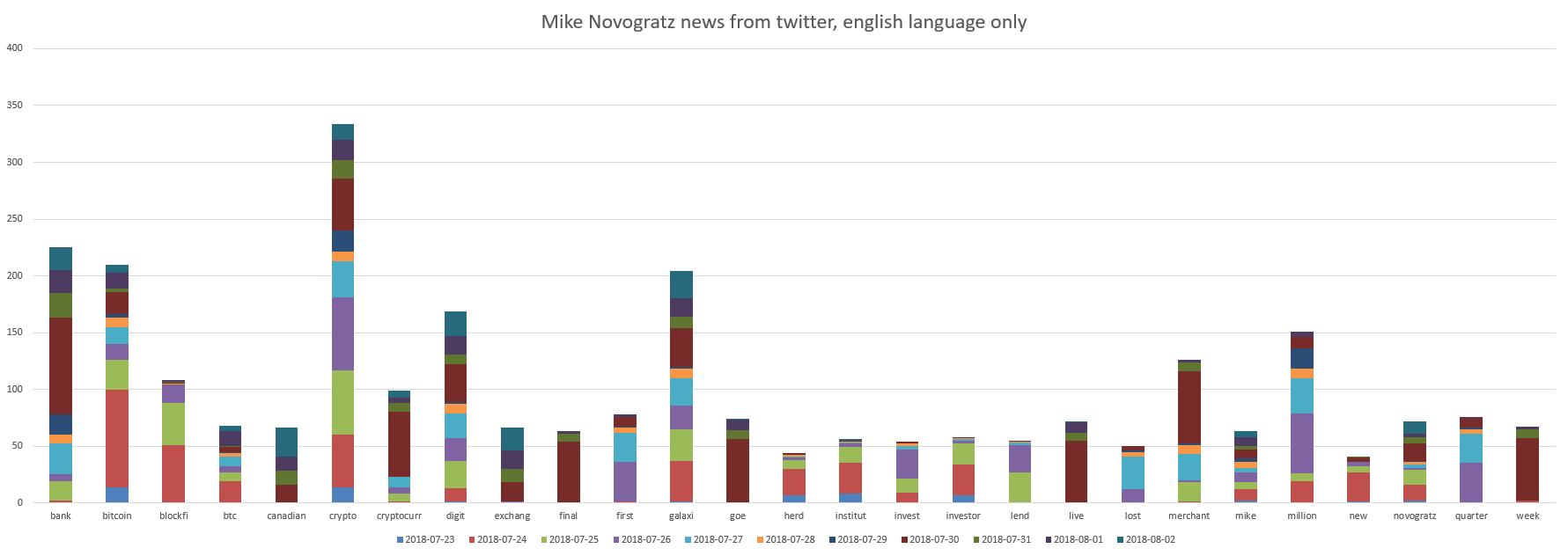
On peut voir que Mike Novogratz est lié à "banque, bitcoin, crypto, chiffre, galaxie".
Les données de X peuvent être versées dans un réseau neuronal et il peut apprendre à déterminer quoi que ce soit, mais vous pouvez:
Analyse des données
Et puis on s'arrête se moquer soyez créatif et commencez à utiliser la bibliothèque python TextBlob . La bibliothèque est un miracle comme elle est bonne.
Les gens intelligents disent qu'elle peut:
- Surligner les phrases
- faire le marquage des pièces
- analyser les humeurs (cela nous est utile ci-dessous),
- faire la classification (bayes naïfs, arbre de décision),
- traduire et définir la langue à l'aide de Google Translate,
- faire de la tokenisation (décomposer le texte en mots et phrases),
- identifier les fréquences des mots et des phrases,
- faire l'analyse
- détecter n-grammes
- révéler \ inflexion \ déclinaison \ conjugaison de mots (pluralisation et singularisation) et lemmatisation,
- orthographe correcte.
La bibliothèque vous permet d'ajouter de nouveaux modèles ou de nouvelles langues via des extensions et intègre WordNet. En un mot, la PNL est un enfant prodige .
Nous avons enregistré les résultats de la recherche dans le fichier results.xlsx ci-dessus. Téléchargez-le et parcourez-le avec la bibliothèque TextBlob à des fins d'évaluation de l'humeur:
from textblob import TextBlob results = pd.read_excel('results.xlsx') polarity = 0 for i in range(0, len(results.index)): polarity += TextBlob(results['text'][i]).sentiment.polarity print(polarity/i)
Super! Quelques lignes de code et un résultat spectaculaire.
Aperçu des résultats
Il s'avère qu'au début du mois d'août 2018, les tweets trouvés sur la requête «Le Minh Tam» montrent quelque chose qui s'est reflété négativement dans les tweets avec une note moyenne de tous les tweets moins 0,13 . Si nous regardons les tweets eux-mêmes, nous verrons par exemple "Le PDG de Crypto Mining a dit de disparaître avec 35 millions de dollars de fonds Le PDG de la société minière Crypto Sky Mining, Le Minh Tam a r ...".
Et l'ami de Mike Novogratz a fait quelque chose qui s'est reflété positivement dans les tweets avec une note moyenne de tous les tweets plus 0,03 . Vous pouvez l'interpréter pour que tout avance calmement.
Plan d'attaque
Aux fins de l'évaluation de l'OIC, il convient de surveiller les informations sur les fondateurs de l'OIC et sur l'OIC elle-même à partir de plusieurs sources. Par exemple:
Plan de surveillance d'une ICO:
- Créer une liste des noms des fondateurs de l'OIC et de l'OIC elle-même,
- Nous créons une liste de ressources pour le suivi,
- Nous créons un robot qui collecte des données pour chaque ligne de 1 - pour chaque ressource de 2, exemple ci-dessus,
- Nous faisons un robot qui évalue tous les 3, l'exemple ci-dessus,
- Sauvegardez les résultats 4 (et 3),
- Répétez les étapes 3 à 5 toutes les heures, de manière automatisée, les résultats de l'évaluation peuvent être publiés / envoyés / enregistrés quelque part,
- Nous surveillons automatiquement les sauts dans l'évaluation au paragraphe 6. S'il y a des sauts dans l'évaluation au paragraphe 6, c'est l'occasion de mener une étude supplémentaire de ce qui se passe de manière experte. Et suscitez la panique, ou vice versa, réjouissez-vous.
Eh bien, quelque chose comme ça.
PS Eh bien, ou achetez ces informations, par exemple ici thomsonreuters