Le 19 septembre, s'est
tenue à Moscou
la première métaphase thématique HUG (Highload ++ User Group), dédiée aux microservices. Le rapport «Fonctionnement des microservices: la taille importe même si vous disposez de Kubernetes» a été livré au cours duquel nous avons partagé la vaste expérience de Flant dans l'exploitation de projets avec l'architecture de microservices. Tout d'abord, il sera utile à tous les développeurs qui envisagent d'appliquer cette approche dans leur projet actuel ou futur.

Nous présentons la
vidéo avec le rapport (50 minutes, beaucoup plus informatif que l'article), ainsi que l'extrait principal de celui-ci sous forme de texte.
NB: La vidéo et la présentation sont également disponibles à la fin de cette publication. Présentation
Habituellement, une bonne histoire a une intrigue, une intrigue principale et un dénouement. Ce rapport ressemble plus à un complot et tragique. Il est également important de noter qu'il fournit un aperçu du
fonctionnement des microservices.
Je vais commencer par un tel calendrier, dont l'auteur (en 2015)
était Martin Fowler:
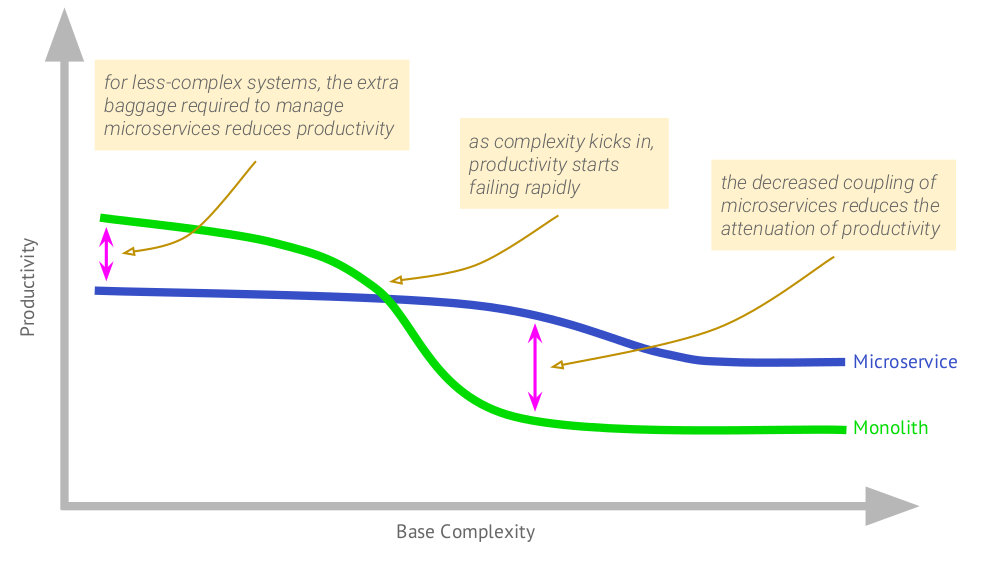
Il montre comment dans le cas d'une application monolithique qui a atteint une certaine valeur, la productivité du travail commence à décliner. Les microservices diffèrent en ce que la productivité initiale avec eux est plus faible, cependant, à mesure que la complexité augmente, la dégradation de l'efficacité pour eux n'est pas aussi perceptible.
Je vais compléter ce graphique pour le cas d'utilisation de Kubernetes:
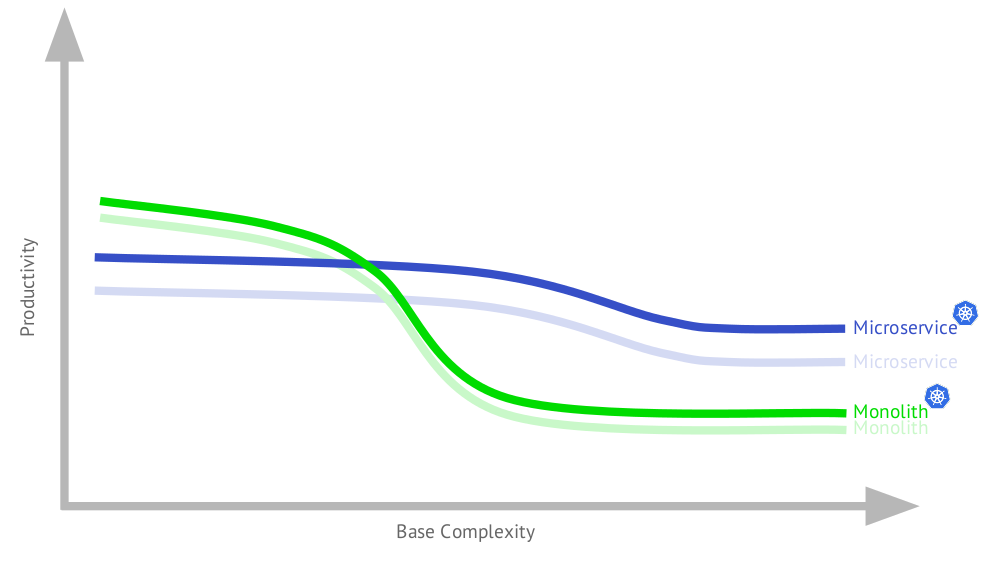
Pourquoi l'application de microservice s'est-elle améliorée? Parce qu'une telle architecture met en avant de sérieuses exigences d'architecture, qui à leur tour sont parfaitement couvertes par les capacités de Kubernetes. D'autre part, une partie de cette fonctionnalité sera également utile pour le monolithe, en particulier pour la raison que le monolithe typique aujourd'hui n'est pas exactement un monolithe (les détails seront plus loin dans le rapport).
Comme vous pouvez le voir, le calendrier final (lorsque les applications monolithiques et microservices dans l'infrastructure avec Kubernetes) ne sont pas très différents de l'original. Ensuite, nous parlerons des applications exécutées à l'aide de Kubernetes.
Microservice utile et nuisible
Et voici l'idée principale:

Qu'est-ce qu'une architecture de microservice
normale ? Cela devrait vous apporter de réels avantages et augmenter l'efficacité du travail. Si vous revenez au tableau, le voici:
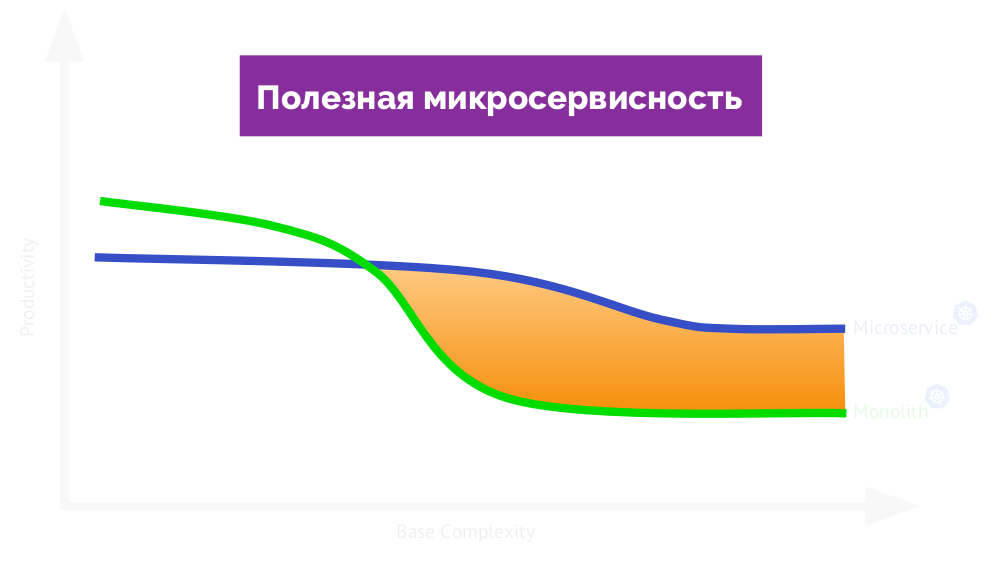
Si vous l'appelez
utile , alors de l'autre côté du graphique il y aura un microservice
nuisible (interfère avec le travail):
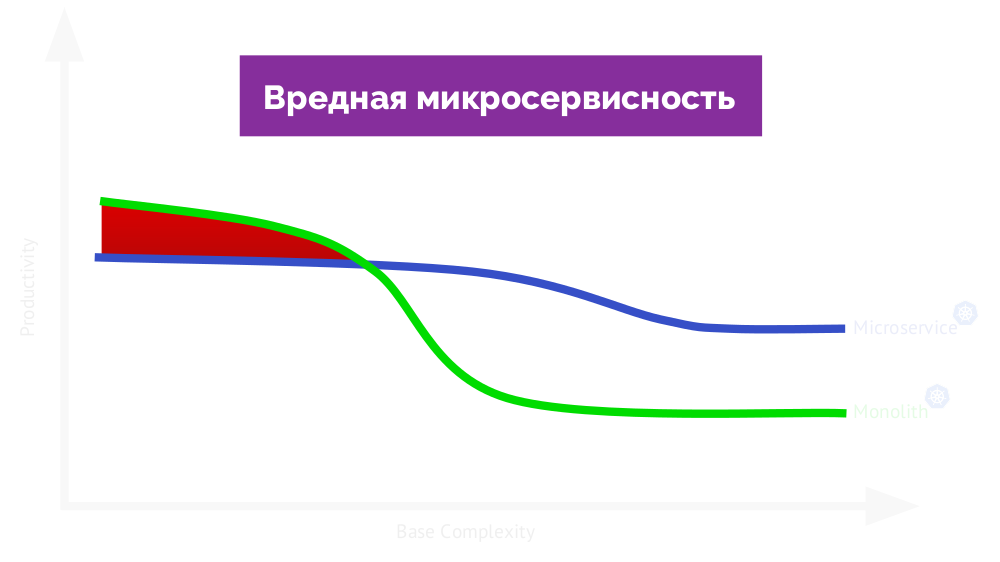
Revenons à «l'idée principale»: vaut-il la peine de faire confiance à mon expérience? Depuis le début de cette année, j'ai examiné
85 projets . Tous n'étaient pas des microservices (environ un tiers à la moitié d'entre eux possédaient une telle architecture), mais c'est toujours un grand nombre. Nous (sociétés Flant), en tant que sous-traitants, parvenons à voir une grande variété d'applications développées à la fois dans les petites entreprises (avec 5 développeurs) et les grandes (~ 500 développeurs). Un avantage supplémentaire est que nous voyons comment ces applications vivent et se développent au fil des ans.
Pourquoi des microservices?
À la question sur les avantages des microservices, le Martin Fowler déjà mentionné a une
réponse très précise :
- limites claires de la modularité;
- déploiement indépendant;
- liberté de choix de la technologie.
J'ai beaucoup discuté avec des architectes et des développeurs de logiciels et demandé pourquoi ils avaient besoin de microservices. Et compilé sa liste de leurs attentes. Voici ce qui s'est passé:
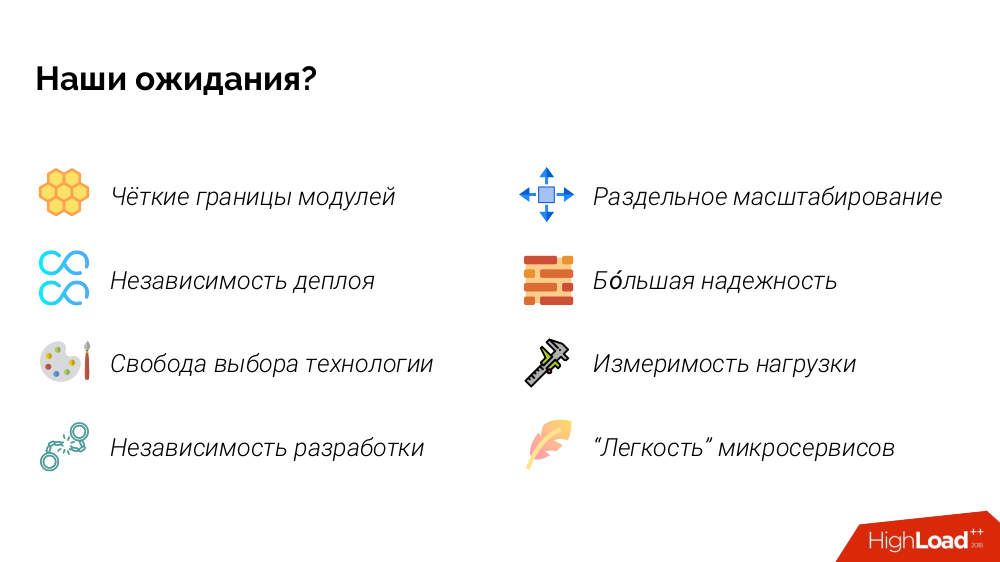
Si vous décrivez «en sensations» certains des points, alors:
- limites claires des modules: nous avons ici un terrible monolithe, et maintenant tout sera soigneusement disposé dans les référentiels Git, dans lesquels tout est «sur les étagères», pas mélangé avec chaud et doux;
- Indépendance de déploiement: nous serons en mesure de déployer des services de manière indépendante, pour accélérer le développement (publier de nouvelles fonctionnalités en parallèle);
- indépendance de développement: nous pouvons donner ce microservice à cette équipe / développeur, et à l'autre, afin que nous puissions développer plus rapidement;
- une plus grande fiabilité: si une dégradation partielle se produit (un microservice sur 20 tombe), un seul bouton cessera de fonctionner et le système dans son ensemble continuera de fonctionner.
Architecture de microservice typique (nuisible)
Pour expliquer pourquoi en réalité tout ne se passe pas comme prévu, je présenterai une image
collective de l'architecture de microservices basée sur l'expérience de nombreux projets différents.
Un exemple serait une boutique en ligne abstraite sur le point de concurrencer Amazon ou au moins OZON. Son architecture de microservices ressemble à ceci:
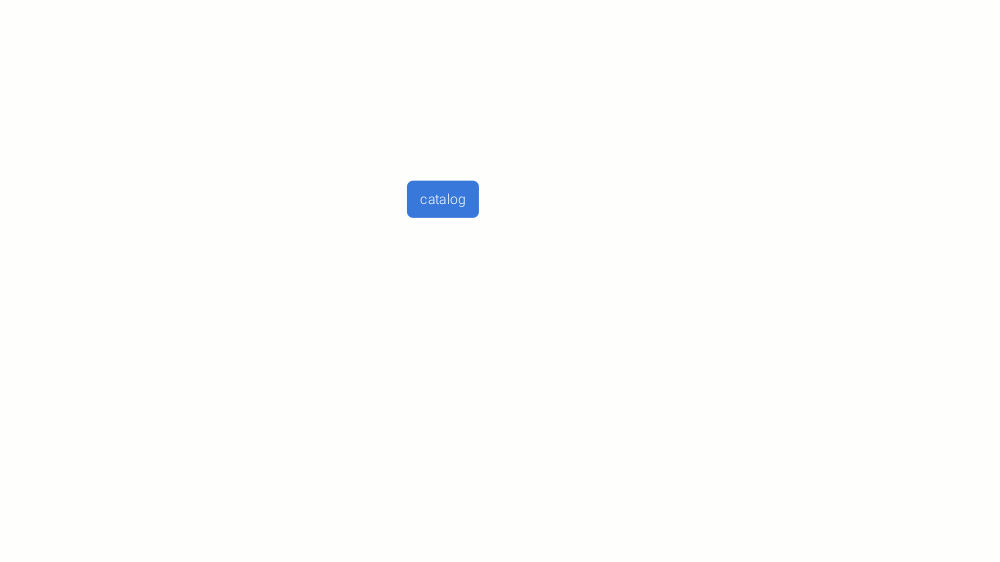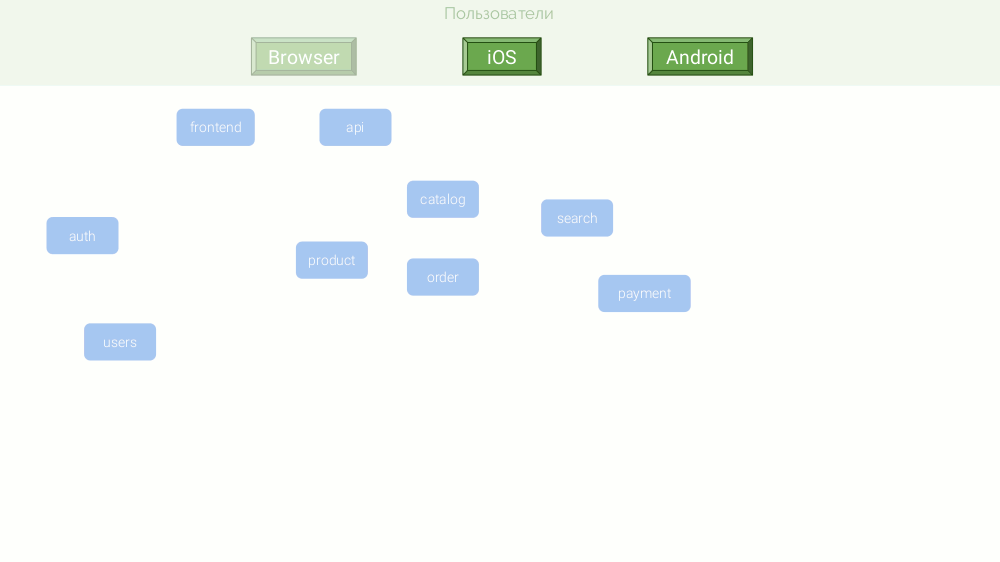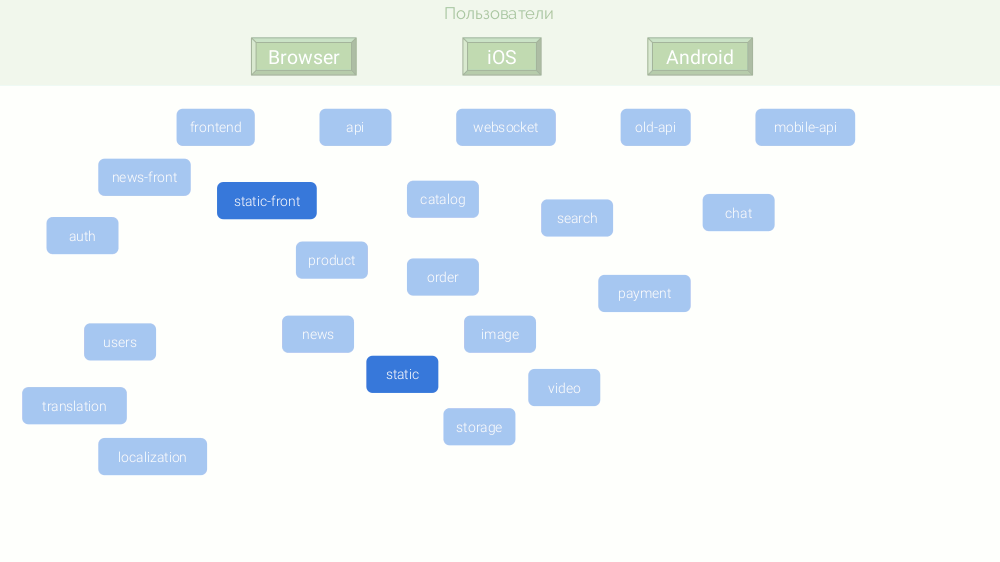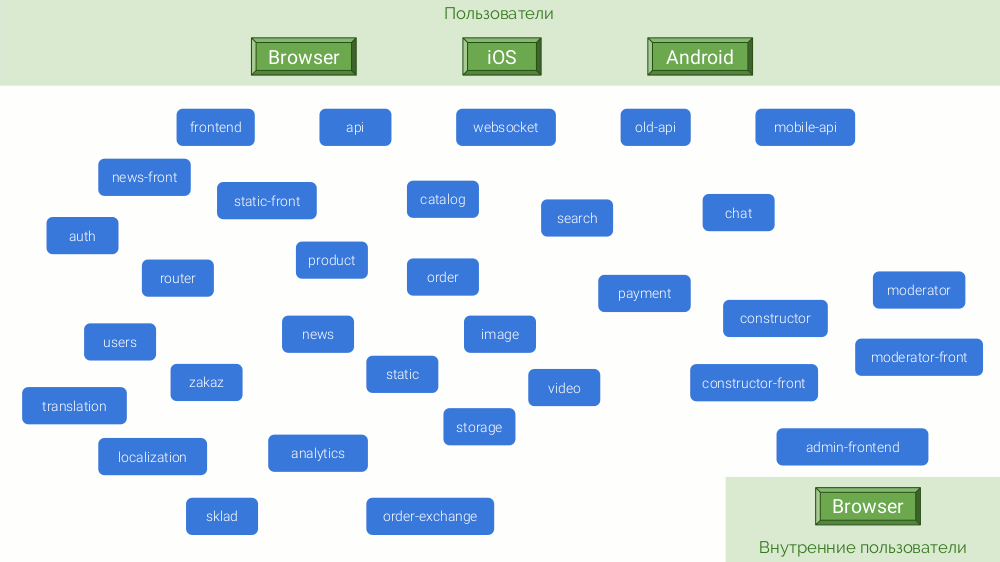
Pour une combinaison de raisons, ces microservices sont écrits sur différentes plateformes:

Étant donné que chaque microservice devrait avoir une autonomie, beaucoup d'entre eux ont besoin de leur propre base de données et cache. L'architecture finale est la suivante:
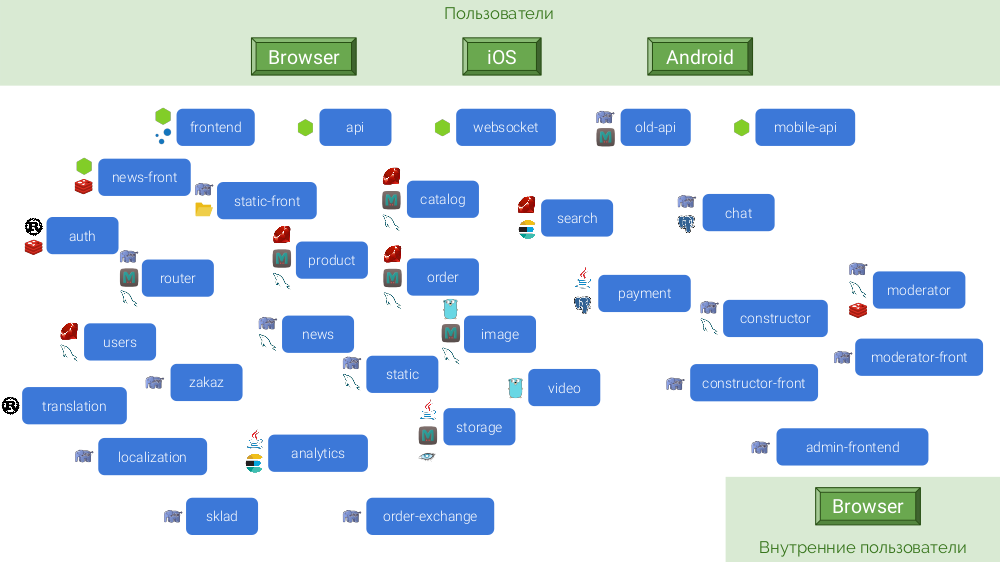
Quelles en sont les conséquences?
Fowler
a un article sur ce sujet - sur le «retour sur investissement» pour l'utilisation des microservices:

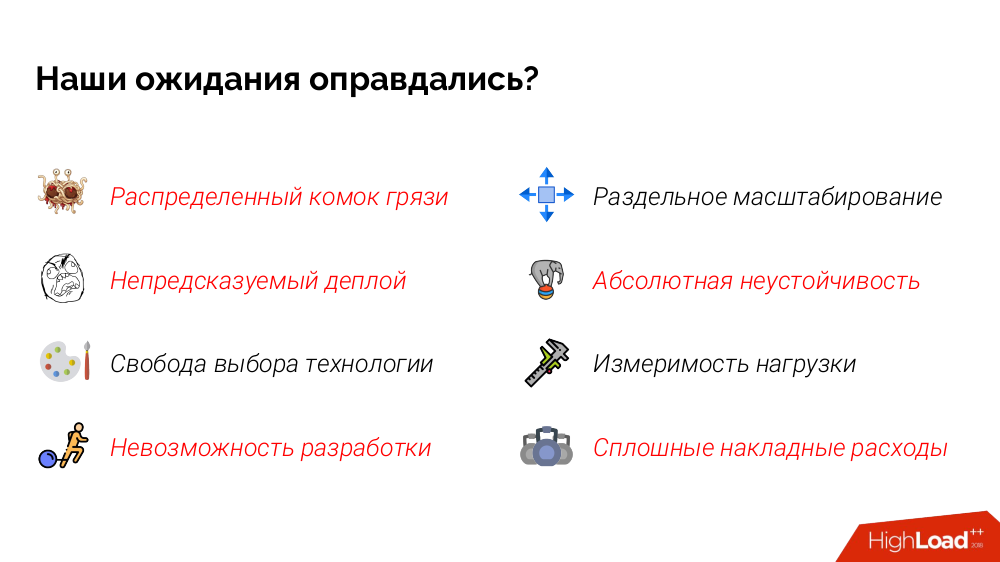
Et nous verrons si nos attentes sont satisfaites.
Limites claires des modules ...
Mais
combien de microservices devons-nous vraiment réparer pour déployer le changement? Peut-on même comprendre comment tout fonctionne sans traceur distribué (après tout, toute demande est traitée par la moitié des microservices)?
Il y a un «
gros morceau de boue », mais ici nous obtenons un morceau de boue distribué. À l'appui de ceci, voici un exemple d'illustration du déroulement des requêtes:
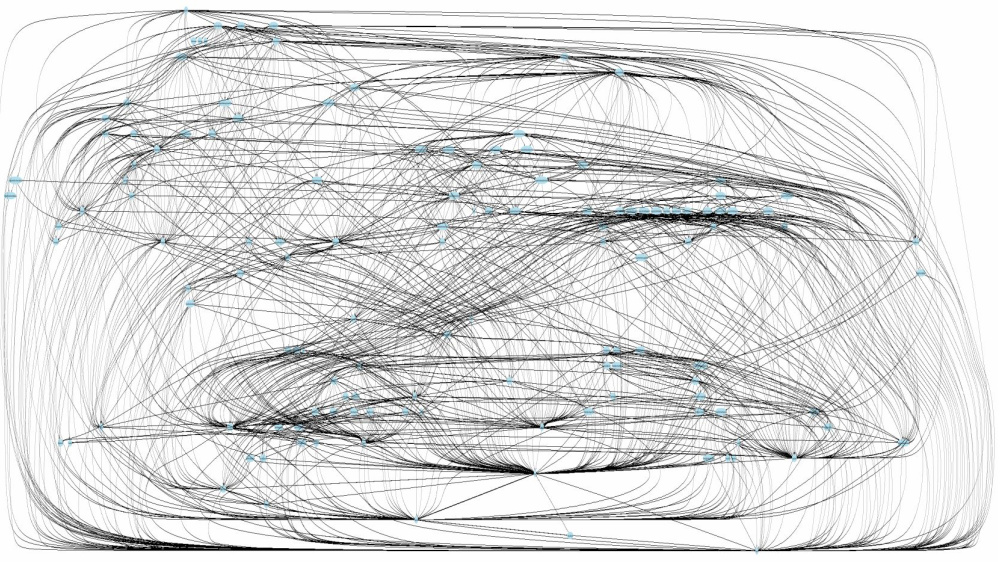
Indépendance de déploiement ...
Techniquement, c'est chose faite: on peut rouler chaque microservice séparément. Mais dans la pratique, vous devez tenir compte du fait que de
nombreux microservices sont toujours
déployés et nous devons prendre en compte l'
ordre de leur déploiement . Dans le bon sens, nous devons généralement tester dans un circuit séparé si nous déployons la version dans le bon ordre.
Liberté de choisir la technologie ...
Elle est là. Il ne faut que se rappeler que souvent la liberté frise l'anarchie. Il est très important ici de ne pas choisir des technologies simplement pour «jouer» avec elles.
Indépendance de développement ...
Comment réaliser un circuit de test pour l'ensemble de l'application (à partir de tant de composants)? Mais vous devez toujours le maintenir à jour. Tout cela conduit au fait que le
nombre réel de boucles de test , que nous pouvons en principe contenir,
est minime .
Mais déployer tout cela localement? .. Il s'avère que souvent le développeur fait son travail de façon indépendante, mais au hasard, car il doit attendre la sortie du circuit de test.
Mise à l'échelle séparée ...
Oui, mais il est limité dans le domaine des SGBD utilisés. Dans l'exemple d'architecture donné, Cassandra n'aura pas de problèmes, mais MySQL et PostgreSQL l'auront.
Plus de fiabilité ...
Non seulement qu'en fait, la défaillance d'un microservice brise souvent le bon fonctionnement de l'ensemble du système, il y a aussi un nouveau problème:
il est très difficile de rendre chaque microservice tolérant aux pannes . Parce que les microservices utilisent différentes technologies (memcache, Redis, etc.), tout le monde a besoin de réfléchir et d'implémenter tout, ce qui, bien sûr, est possible, mais nécessite d'énormes ressources.
Mesurabilité de la charge ...
Tout est vraiment bien avec ça.
Légèreté des microservices ...
Nous avons non seulement eu d'énormes
frais généraux de réseau (requêtes DNS, etc.), mais aussi en raison des nombreuses sous-requêtes, nous avons commencé à
répliquer les données (caches de stockage), ce qui a conduit à une quantité importante de stockage.
Et voici le résultat de la satisfaction de nos attentes:
Mais ce n'est pas tout!
Parce que:
- Nous avons probablement besoin d'un bus de messages.
- Comment faire une sauvegarde cohérente au bon moment? La seule vraie option est de désactiver le trafic pour cela. Mais comment le faire en production?
- Si nous parlons de soutenir plusieurs régions, l'organisation de la durabilité dans chacune d'elles est une tâche qui prend beaucoup de temps.
- Il y a un problème de modifications centralisées. Par exemple, si nous devons mettre à jour la version de PHP, nous devons nous engager dans chaque référentiel (et il y en a des dizaines).
- L'augmentation de la complexité opérationnelle est exponentielle.
Que faire de tout ça?
Commencez avec une application monolithique . L'expérience de Fowler
suggère que presque toutes les applications de microservices réussies ont commencé avec un monolithe, qui est devenu trop volumineux, après quoi il a été brisé. Dans le même temps, presque tous les systèmes construits en tant que microservice depuis le tout début ont connu de graves problèmes tôt ou tard.
Une autre pensée précieuse est que pour qu'un projet avec une architecture de microservices réussisse, vous devez très bien connaître
à la fois le domaine et comment créer des microservices . Et la meilleure façon de connaître le sujet est de faire un monolithe.
Mais que faire si nous sommes déjà dans cette situation?
La première étape pour résoudre un problème consiste à être d'accord avec lui et à comprendre qu'il s'agit d'un problème, que nous ne voulons plus souffrir.
Si dans le cas d'un monolithe envahi par la végétation (lorsque nous avons épuisé les possibilités d'acheter des ressources pour celui-ci), nous le coupons, alors dans ce cas, nous obtenons l'histoire inverse: quand un microservice excessif n'aide plus, mais interfère -
coupez l'excès et agrandissez !
Par exemple, pour l'image collective évoquée ci-dessus ...
Débarrassez-vous des microservices les plus douteux:

Combinez tous les microservices chargés de générer le frontend:

... dans un microservice, écrit dans un langage / cadre (moderne et normal, comme vous le pensez vous-même):

Il aura un ORM (un SGBD) et d'abord quelques applications:
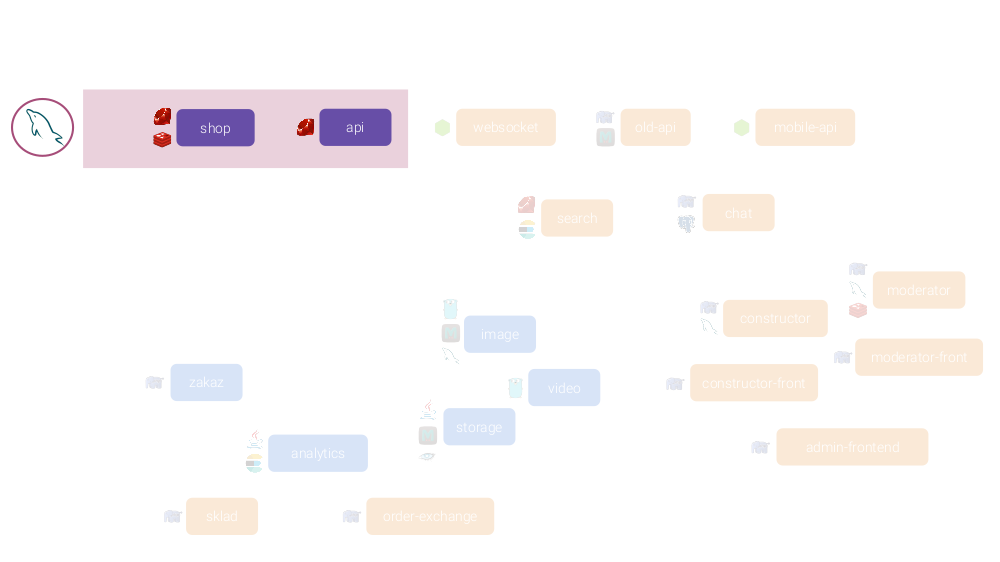
... en général, beaucoup plus peut y être transféré, ayant obtenu le résultat suivant:

De plus, dans Kubernetes, nous exécutons tout cela dans des instances distinctes, ce qui signifie que nous pouvons toujours mesurer la charge et les mettre à l'échelle séparément.
Résumer
Regardez l'image plus large. Très souvent, tous ces problèmes avec les microservices surviennent du fait que quelqu'un a pris sa tâche, mais voulait "jouer aux microservices".
Dans le mot «microservices», la partie «micro» est superflue . Ils ne sont "micro" que parce qu'ils sont plus petits qu'un énorme monolithe. Mais ne les considérez pas comme quelque chose de petit.
Et pour la dernière pensée, revenons à l'horaire d'origine:

La note qui lui est écrite
(en haut à droite) se résume au fait que les
compétences de l'équipe qui réalise votre projet sont toujours primaires - elles joueront un rôle clé dans votre choix entre des microservices et un monolithe. Si l'équipe n'a pas assez de compétences, mais qu'elle commence à faire des microservices, l'histoire sera définitivement fatale.
Vidéos et diapositives
Vidéo du discours (~ 50 minutes; malheureusement, elle ne transmet pas les nombreuses émotions des visiteurs, qui ont largement déterminé l'humeur du reportage, mais en l'état):
Présentation du rapport:
PS
Autres reportages sur notre blog:
Vous pouvez également être intéressé par les publications suivantes: