Aujourd'hui, nous allons parler de DevOps, ou plutôt, principalement d'Ops. Ils disent qu'il y a très peu de gens satisfaits du niveau d'automatisation de leurs opérations. Mais la situation semble être réparable. Dans cet article, Nikolai Ryzhikov parlera de son expérience avec l'expansion de Kubernetes.

Le matériel a été préparé sur la base du discours de Nikolai lors de la conférence d'automne DevOops 2017. Sous la coupe - transcription vidéo et texte du rapport.
Actuellement, Nikolai Ryzhikov travaille dans le secteur Santé-TI pour créer des systèmes d'information médicale. Membre de la communauté des programmeurs fonctionnels FPROG de Saint-Pétersbourg. Membre actif de la communauté Online Clojure, membre de la norme d'échange d'informations médicales HL7 FHIR. Programmation depuis 15 ans.
De quel côté avons-nous pour DevOps? Depuis 10 ans, notre formule DevOps est assez simple: les développeurs sont responsables des opérations, les développeurs sont déployés, les développeurs sont maintenus. Avec cet arrangement, qui a l'air un peu dur, vous deviendrez en tout cas DevOps. Si vous souhaitez implémenter rapidement et péniblement DevOps - rendez les développeurs responsables de votre production. Si les gars sont intelligents, ils commenceront à sortir et à tout comprendre.

Notre histoire: il y a longtemps, quand il n'y avait pas de Chef et d'automatisation, nous avions déjà déployé Capistrano automatique. Puis ils ont commencé à l'ennuyer pour qu'il fasse de la mode. Mais le chef est alors apparu. Nous y sommes passés et sommes partis pour le cloud: nous en avions assez de nos data centers. Puis Ansible est apparu, Docker s'est levé. Après cela, nous avons déménagé à Terraform avec le superviseur de docker Condo manuscrit sur Camel. Et maintenant, nous passons à Kubernetes.

Quelle est la pire chose au sujet des opérations? Très peu de gens sont satisfaits du niveau d'automatisation de leurs opérations. C'est effrayant, je confirme: nous avons dépensé beaucoup de ressources et d'efforts pour collecter toutes ces piles pour nous-mêmes, et le résultat n'est pas satisfaisant.
On a le sentiment qu'avec l'avènement de Kubernetes, quelque chose peut changer. Je suis attaché à la fabrication allégée et, de son point de vue, les opérations ne sont généralement pas utiles. Les opérations idéales sont l'absence ou le minimum d'opérations dans un projet. La valeur est créée lorsqu'un développeur crée un produit. Lorsqu'elle est prête, la livraison n'ajoute pas de valeur. Mais vous devez réduire les coûts.

Pour moi, l'idéal était toujours le heroku. Nous l'avons utilisé pour des applications simples, où le développeur pour déployer son service, il suffisait de dire git push et de configurer heroku. Ça prend une minute.

Comment être Vous pouvez acheter NoOps - également Heroku. Et je vous conseille d'acheter, sinon il y a une chance de dépenser plus d'argent pour le développement des opérations normales.
Il y a des gars Deis, ils essaient de faire quelque chose comme heroku sur Kubernetes. Il existe une fonderie de cloud, qui fournit également une plate-forme sur laquelle travailler.

Mais si vous vous embêtez avec quelque chose de plus complexe ou de plus grand, vous pouvez le faire vous-même. Maintenant, avec Docker et Kubernetes, cela devient une tâche qui peut être accomplie dans un délai raisonnable et à un coût raisonnable. Auparavant, c'était trop dur.

Un peu sur Docker et Kubernetes
L'un des problèmes des opérations est la répétabilité. La grande chose que le docker a apporté est en deux phases. Nous avons une phase de construction.
Le deuxième point qui plaît au docker est une interface universelle pour lancer des services arbitraires. Quelqu'un a assemblé Docker, a mis quelque chose à l'intérieur et les opérations suffisent à dire que Docker s'exécute et démarre.

Qu'est-ce que Kubernetes? Nous avons donc créé Docker et nous devons le lancer, l'intégrer, le configurer et le connecter à d'autres quelque part. Kubernetes vous permet de le faire. Il présente une série d'abstractions, appelées «ressources». Nous allons les parcourir rapidement et même essayer de créer.
Abstraction
La première abstraction est un POD ou un ensemble de conteneurs. Correctement fait, ce qui est exactement un
ensemble de conteneurs, et non un. Les ensembles peuvent fouiller entre eux des volumes qui se voient via localhost. Cela vous permet d'utiliser un modèle tel que sidecar (c'est lorsque nous lançons le conteneur principal, et il y a des conteneurs auxiliaires à proximité qui l'aident).
Par exemple, l'approche des ambassadeurs. C'est lorsque vous ne voulez pas que le conteneur pense où se trouvent certains services. Vous placez un conteneur à côté qui sait où se trouvent ces services. Et ils deviennent disponibles pour le conteneur principal sur localhost. Ainsi, l'environnement commence à ressembler à votre travail local.

Levons le POD et voyons comment il est décrit. Localement, vous pouvez développer un minikube. Il mange un tas de CPU, mais vous permet de soulever un petit cluster Kubernetes sur une virtualbox et de travailler avec.
Déployons POD. J'ai dit que Kubernetes appliquait et inondait le POD. Je peux voir quels PODs j'ai: je vois qu'un POD est déployé. Cela signifie que Kubernetes a lancé ces conteneurs.
Je peux même aller dans ce conteneur.
De ce point de vue, Kubernetes est fait pour les gens. En effet, ce que nous faisons constamment dans les opérations, dans la liaison Kubernetes, par exemple, en utilisant l'utilitaire kubectl, peut être fait facilement.
Mais le POD est mortel. Cela commence comme une course Docker: si quelqu'un l'arrête, personne ne le lèvera. En plus de cette abstraction, Kubernetes commence à construire ce qui suit - par exemple, un jeu de réplicas. C'est un tel superviseur qui surveille les POD, surveille leur nombre, et si les POD tombent, il les soulève. Il s'agit d'un important concept d'auto-guérison dans Kubernetes qui vous permet de dormir paisiblement la nuit.
Au-dessus du jeu de répliques, il y a une abstraction du déploiement - également une ressource qui vous permet de faire un déploiement sans temps. Par exemple, un jeu de répliques fonctionne. Lorsque nous déployons et modifions la version du conteneur, par exemple la nôtre, à l'intérieur du déploiement, un autre jeu de réplicas se lève. Nous attendons que ces conteneurs commencent, effectuons leurs contrôles de santé, puis nous passons rapidement au nouveau jeu de réplicas. Aussi classique et bonne pratique.

Prenons un service simple. Par exemple, nous avons un déploiement. À l'intérieur, il décrit le modèle de POD qu'il ramassera. Nous pouvons appliquer ce déploiement, voir ce que nous avons. Fonction cool de Kubernetes - tout se trouve dans la base de données, et nous pouvons regarder ce qui se passe dans le système.
Ici, nous voyons un déploiement. Si nous essayons de regarder les POD, nous voyons que certains POD ont augmenté. Nous pouvons prendre et retirer ce POD. Qu'arrive-t-il aux POD? L'un est détruit et le second monte immédiatement. Ce contrôleur de réplicas n'a pas trouvé le POD souhaité et en a lancé un autre.
De plus, s'il s'agit d'une sorte de service Web, ou si nos services doivent communiquer, nous avons besoin d'une découverte de service. Vous devez donner au service un nom et un point d'entrée. Kubernetes propose une ressource appelée service pour cela. Il peut gérer l'équilibrage de charge et être responsable de la découverte des services.

Voyons un service simple. Nous le connectons avec le déploiement et les POD via des étiquettes: un tel lien dynamique. Un concept très important dans Kubernetes: le système est dynamique. Peu importe dans quel ordre tout cela sera créé. Le service essaiera de trouver des POD avec de telles étiquettes et commencera leur équilibre de charge.
Appliquez le service, regardez quels services nous avons. Nous allons dans notre test POD, qui a été déclenché, et faisons nslookup. Kubernetes nous donne un DNS-ku à travers lequel les services peuvent se voir et se découvrir.
Le service est plutôt une interface. Il existe plusieurs implémentations différentes, car les tâches d'équilibrage de charge et de service sont assez compliquées: d'une part, nous travaillons avec des bases de données ordinaires, de l'autre avec des bases de données chargées, et certaines simples sont rendues assez simples. C'est également un concept important dans Kubernetes: certaines choses peuvent être appelées des interfaces plutôt que des implémentations. Ils ne sont pas fixés de manière rigide et différents, par exemple, les fournisseurs de cloud fournissent différentes implémentations. C'est-à-dire, par exemple, qu'il existe un volume persistant de ressources, qui est déjà implémenté dans chaque cloud particulier par ses moyens réguliers.
Ensuite, nous voulons généralement sortir le service Web. Kubernetes a une abstraction d'entrée. SSL y est généralement ajouté.

L'entrée la plus simple ressemble à ceci. Là, nous écrivons les règles: pour quelles URL, pour quels hôtes, vers quel service interne rediriger la demande. De la même manière, nous pouvons augmenter notre pénétration.
Après quoi, après vous être enregistré localement dans les hôtes, vous pouvez voir ce service à partir d'ici.
C'est une tâche tellement régulière: nous avons déployé un certain service Web, rencontré un peu Kubernetes.
Nous allons tout nettoyer, éliminer les entrées et examiner toutes les ressources.
Il existe un certain nombre de ressources, telles que configmap et secret. Ce sont des ressources purement informatives que vous pouvez monter dans un conteneur et y transférer, par exemple, le mot de passe de postgres. Vous pouvez associer cela à des variables d'environnement qui seront injectées dans le conteneur au démarrage. Vous pouvez monter le système de fichiers. Tout est assez pratique: tâches standard, belles solutions.
Il existe un volume persistant - une interface implémentée différemment par différents fournisseurs de cloud. Il est divisé en deux parties: il y a une revendication de volume persistante (demande), puis un EBS est créé qui se déplace vers le conteneur. Vous pouvez travailler avec un service avec état.

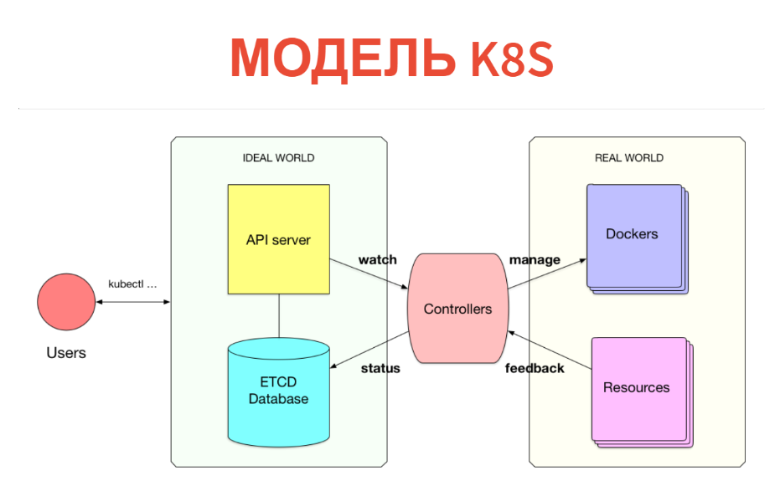
Mais comment ça marche à l'intérieur? Le concept lui-même est très simple et transparent. Kubernetes se compose de deux parties. L'une n'est qu'une base de données dans laquelle nous avons toutes ces ressources. Les ressources peuvent être considérées comme des tablettes: en particulier, ces instances sont simplement des enregistrements dans des tablettes. En plus de Kubernetes, un serveur API est configuré. Autrement dit, lorsque vous avez un cluster Kubernetes, vous communiquez généralement avec le serveur API (plus précisément, le client communique avec lui).
En conséquence, ce que nous avons créé (POD, services, etc.) est simplement écrit dans la base de données. Cette base de données est mise en œuvre par ETCD, c'est-à-dire afin qu'il soit stable au niveau de haute disponibilité.
Qu'est-ce qui vient ensuite? Plus loin, sous chaque type de ressources, il y a un certain contrôleur. Il s'agit simplement d'un service qui surveille son type de ressource et fait quelque chose dans le monde extérieur. Par exemple, un Docker s'exécute-t-il? Si nous avons des POD, pour chaque nœud, il existe un service kubelet qui surveille les POD connectés à ce nœud. Et tout ce qu'il fait est Docker exécuté après le prochain contrôle périodique si ce POD n'est pas là.
De plus, ce qui est très important - tout se passe en temps réel, donc la puissance de ce contrôleur est supérieure au minimum. Souvent, le contrôleur prend toujours les mesures et regarde ce qu'il a commencé. C'est-à-dire supprime les commentaires du monde réel et les écrit dans la base de données, afin que vous ou d'autres contrôleurs puissiez les voir. Par exemple, le même statut POD sera réécrit dans ETCD.
Ainsi, tout est implémenté dans Kubernetes. C'est très cool que le modèle d'information soit séparé de la salle d'opération. Dans la base de données via l'interface CRUD habituelle, nous déclarons ce qui devrait être. Ensuite, l'ensemble des contrôleurs essaie de tout arranger. Certes, cela ne se produit pas toujours.
Il s'agit d'un modèle cybernétique. Nous avons un certain préréglage, il y a une sorte de machine qui essaie de diriger le monde réel ou la machine à l'endroit qui est nécessaire. Cela ne se passe pas toujours comme ceci: nous devrions avoir une boucle de rétroaction. Parfois, une machine ne peut pas faire cela et doit se tourner vers une personne.
Dans les systèmes réels, nous pensons en abstractions du niveau suivant: nous avons des services, des bases de données et nous les connectons tous. Nous ne pensons pas aux POD et aux Ingresss, et nous voulons construire un nouveau niveau d'abstraction.

Pour que le développeur soit le plus simple possible: pour qu'il dise simplement: «Je veux démarrer tel ou tel service» et tout le reste s'est passé à l'intérieur.
Il y a une telle chose comme HELM. Ce n'est pas la bonne façon - un modèle de style ansible, où nous essayons simplement de générer un ensemble de ressources configurées et de les déposer dans un cluster Kubernetes.
Le problème, tout d'abord, est que cela ne se fait qu'au moment du laminage. Autrement dit, il ne peut pas mettre en œuvre beaucoup de logique. Deuxièmement, lors de l'exécution, cette abstraction disparaît. Lorsque je regarde mon cluster, je ne vois que des POD et des services. Je ne vois pas que tel ou tel service est déployé, que telle ou telle base avec réplication y soit élevée. J'y vois juste des dizaines de foyers. L'abstraction disparaît comme dans une matrice.

Modèle de solution interne
D'un autre côté, Kubernetes lui-même fournit déjà un modèle d'extension très intéressant et simple à l'intérieur. Nous pouvons déclarer de nouveaux types de ressources, par exemple le déploiement. Il s'agit d'une ressource créée au-dessus de POD ou d'un jeu de réplicas. Nous pouvons écrire un contrôleur sur cette ressource, mettre cette ressource dans la base de données et exécuter notre boucle cybernétique pour que tout fonctionne. Cela semble intéressant et il me semble que c'est la bonne façon d'étendre Kubernetes.

J'aimerais pouvoir simplement écrire un manifeste pour mon service de style heroku. Un exemple très simple: je veux déployer une sorte d'application dans mon environnement réel. Vous avez déjà des accords, SSL, des domaines achetés. Je voudrais juste donner aux développeurs l'interface la plus simple possible. Le manifeste me dit quel conteneur à soulever, quelles ressources ce conteneur a encore besoin. Il lance cette annonce dans le cluster, et tout commence à fonctionner.

À quoi cela ressemblera-t-il en termes de ressources et de contrôleurs personnalisés? Ici, nous aurons une application de ressources dans la base de données. Et le contrôleur d'application générera trois ressources. Autrement dit, il notera les règles en entrée sur la façon de router vers ce service, démarrera le service pour l'équilibrage de charge et lancera le déploiement avec une sorte de configuration.
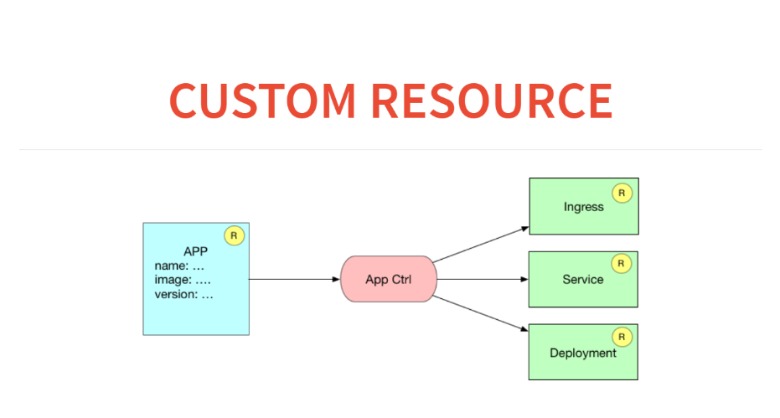
Avant de créer une ressource personnalisée dans Kubernetes, nous devons la déclarer. Pour cela, il existe une méta-ressource appelée CustomResourceDefinition.
Pour déclarer une nouvelle ressource dans Kubernetes, il nous suffit de publier une telle annonce. Considérez cette table de création.
Créé une table. Après cela, nous pouvons regarder à travers le kubectl obtenir ces ressources tierces que nous avons. Dès que nous l'avons annoncé, nous avons également reçu une bannière. Nous pouvons faire, par exemple, kubeclt obtenir des applications. Mais jusqu'à présent, aucune application.
Écrivons une application. Après cela, nous pouvons créer une instance de ressource personnalisée. Examinons-le dans YAML et créons-le par courrier à une URL spécifique.
Si nous courons et regardons kubectl, alors une application est apparue. Mais alors que rien ne se passe, cela réside simplement dans la base de données. Vous pouvez, par exemple, prendre et demander toutes les ressources de l'application.
Nous pouvons créer une deuxième ressource de ce type à partir du même modèle en changeant simplement le nom. Voici la deuxième ressource.
De plus, notre contrôleur devrait faire des modèles, similaires à ce que fait HELM. Autrement dit, après avoir reçu une description de notre application, je dois générer un déploiement de ressources et un service de ressources, ainsi que faire une entrée en entrée. C'est la partie la plus simple: ici à clojure se trouve erlmacro. Je passe la structure de données, il tire la fonction de déploiement, passe au débogage, qui est le pipeline. Et ceci est une fonction pure: un modèle simple. En conséquence, sous la forme la plus naïve, je pouvais immédiatement le créer, le transformer en utilitaire de console et commencer à le distribuer.
Nous faisons de même pour le service: la fonction service accepte la déclaration et génère pour nous la ressource Kubernetes.
Nous faisons de même pour la ligne en entrée.
Comment tout cela fonctionnera-t-il? Il y aura quelque chose dans le monde réel et il y aura ce que nous voulons. Ce que nous voulons - nous prenons la ressource d'application et générons sur elle ce qu'elle devrait être. Et maintenant, nous devons voir ce qui est. Ce que nous demandons via l'API REST. Nous pouvons obtenir tous les services, tous les déploiements.
Comment fonctionnera notre contrôleur personnalisé? Il recevra ce que nous voulons et ce qui est, prendre de cette div et appliquer à Kubernetes. Ceci est similaire à React. J'ai créé un DOM virtuel lorsque certaines fonctions génèrent simplement une arborescence d'objets JS. Et puis un certain algorithme calcule le patch et l'applique au vrai DOM.
Nous ferons de même ici. Cela se fait en 50 lignes de code. Vous voulez - tout est sur Github. En fin de compte, nous devrions obtenir la fonction de réconciliation-actions.
Nous avons une fonction de réconciliation-actions qui ne fait rien et calcule simplement cette div. Elle prend ce qui est, plus ce qui est nécessaire. Et ensuite, il indique ce qui doit être fait pour amener le premier au second.
Tirons-la. Il n'y a rien de mal avec elle, elle peut être affaiblie. Elle dit que vous devez créer un service d'entrée, y faire deux entrées, créer un déploiement 1 et 2, créer un service 1 et 2.
Dans ce cas, il ne devrait déjà y avoir qu'un seul service. Nous voyons par entrée qu'il ne reste qu'une seule entrée.
Il ne reste plus qu'à écrire une fonction qui applique ce patch au cluster Kubernetes. Pour ce faire, nous passons simplement des actions de réconciliation à la fonction de réconciliation, et tout s'appliquera. Et maintenant, nous voyons que le POD a augmenté, le déploiement est devenu et le service a commencé.
Ajoutons un autre service: exécutez à nouveau la fonction reconcile-actions. Voyons ce qui s'est passé. Tout a commencé, tout va bien.
Comment y faire face? Nous emballons tout cela dans un conteneur Docker. Après cela, nous écrivons une fonction qui se réveille périodiquement, fait un rapprochement et s'endort. La vitesse n'est pas très importante, elle peut dormir pendant cinq secondes et effectuer des actions de réconciliation moins souvent.
Notre contrôleur personnalisé n'est qu'un service qui se réveillera et calculera périodiquement le patch.
Maintenant, nous avons deux services zaddeloino, supprimons l'une des applications. Voyons comment notre cluster a réagi: tout va bien. Nous supprimons le second: tout est effacé.
Voyons à travers les yeux du développeur. Il lui suffit de dire que Kubernetes postule et nomme le nouveau service. Nous le faisons, notre contrôleur a tout ramassé et l'a créé.
Ensuite, nous collectons tout cela dans un service de déploiement, et nous jetons ce contrôleur personnalisé dans le cluster à l'aide des outils standard de Kubernetes. Nous avons créé une abstraction pour 200 lignes de code.
Tout cela ressemble à HELM, mais en fait plus puissant. Le contrôleur fonctionne en cluster: il voit la base, voit le monde extérieur et peut être rendu suffisamment intelligent.
Propre CI
Considérez les exemples d'extension Kubernetes. Nous avons décidé que CI devrait faire partie de l'infrastructure. C'est bien, c'est pratique du point de vue de la sécurité - un référentiel privé. Nous avons essayé d'utiliser jenkins, mais c'est un outil obsolète. Je voulais un pirate informatique CI. Nous n'avons pas besoin d'interfaces, nous adorons ChatOps: laissez-le simplement dire dans le chat si la version est tombée ou non. De plus, je voulais tout déboguer localement.

Nous nous sommes assis et avons écrit notre CI en une semaine. Tout comme une extension de Kubernetes. Si vous pensez à CI, alors ce n'est qu'un outil qui exécute une sorte de travail. Dans le cadre de ce travail, nous construisons quelque chose, exécutons des tests et déployons souvent.
Comment ça marche? Il est construit sur le même concept de contrôleurs personnalisés.
Tout d'abord, nous déposons dans Kubernetes une description des référentiels que nous suivons. Le contrôleur va juste à github et ajoute web-hook. Nous avons encore de l'introspection.Vient ensuite le hook Web, dont la seule tâche est de traiter le JSON entrant et de le déposer dans une ressource de construction personnalisée, qui s'ajoute également à la base de données Kubernetes. La ressource de génération est surveillée par le contrôleur de génération, qui lit le manifeste à l'intérieur du projet et lance le POD. Dans ce POD, tous les services nécessaires sont lancés.Dans POD, un agent très simple qui lit une déclaration dans le style de travis ou circleci, et dans YAML, un ensemble d'étapes. Il commence à les remplir. Puis à la fin de la construction, il lance son résultat dans Telegram.Une autre fonctionnalité que nous avons obtenue avec Kubernetes est que l'une des commandes lors de l'exécution de votre CI ou de la livraison continue peut être définie simplement pendant la mise en veille réelle 10, et votre POD se figera à cette étape. Vous exécutez kubectl, vous vous trouvez dans votre build et vous pouvez débuter.Autre fonctionnalité - tout est construit sur des dockers et vous pouvez déboguer le script localement en lançant le docker. Tout cela a pris deux semaines et 300 lignes de code.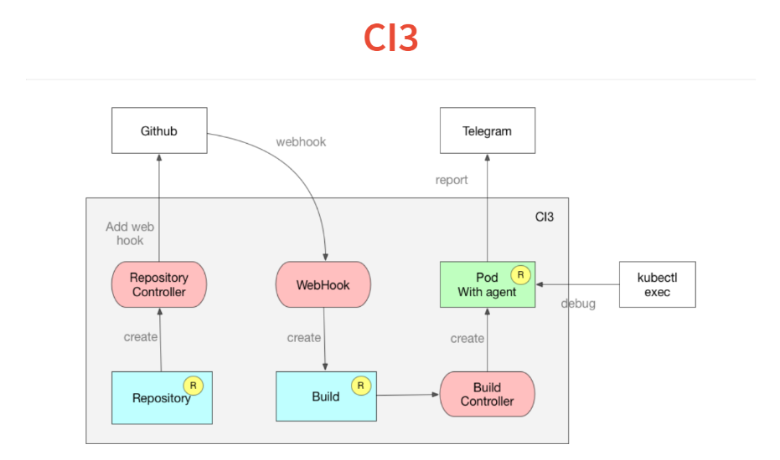
Travailler avec PostgreSQL
Notre produit est construit sur des postgres, nous utilisons toutes sortes de fonctionnalités intéressantes. Nous avons même écrit un certain nombre d'extensions. Mais nous ne pouvons pas utiliser RDS ou autre chose.Nous sommes en train de développer un opérateur pour un postgres indestructible. Je vais sonner l'architecture. Je veux dire: "Cluster, donnez-moi un postgres qui ne peut pas être tué." Ajoutez à cela que j'ai besoin de deux répliques asynchrones, une synchrone, des sauvegardes quotidiennes et jusqu'à un téraoctet. Je lance tout cela, puis mon contrôleur de cluster commence à faire de l'orchestration et à étendre mon conteneur. Il crée des ressources pginstance qui sont responsables de chaque istor postgres. Ce seront des postgres de cluster.En outre, le contrôleur de pginstance, assez simple, essaie simplement d'exécuter POD ou de s'y déployer avec ces postgres. Le cœur est un volume persistant. Toute cette machine prend le contrôle total des postgres. Vous lui donnez un Docker-container, qui ne contient que des postgres binaires. Tout le reste: le contrôleur lui-même fait la configuration et la création du cluster de démarrage postgres. Il le fait pour que nous puissions reconfigurer plus tard, et pour qu'il puisse configurer la réplication, les niveaux de journalisation, etc. Au début, le POD temporaire s'exécute sur le volume persistant et y crée un cluster postgres pour le maître.Ensuite, en plus de cela, le déploiement commence par maître. Ensuite, un volume persistant est créé de la même manière. Un autre POD passe au travers, effectue une sauvegarde de base, la tire et, en plus de cela, le déploiement commence par un esclave.Ensuite, le contrôleur de cluster crée une ressource de sauvegarde (après avoir été décrite avec les sauvegardes). Et le contrôleur de sauvegarde le prend déjà et le jette dans un S3.
Et ensuite?
Laissez-nous vous présenter le futur proche. Il peut arriver que tôt ou tard nous ayons des ressources personnalisées si intéressantes, des contrôleurs personnalisés que je dirai "Donnez-moi des postgres, donnez-moi du kafka, laissez-moi CI et commencez tout." Tout sera simple.Si nous ne parlons pas du futur proche, alors, en tant que programmeur déclaratif, je pense que seule la programmation logique ou relationnelle est supérieure à la programmation fonctionnelle. Là, notre sémantique des opérations est complètement distincte de la sémantique de l'information. Si nous examinons attentivement nos contrôleurs personnalisés que nous avons créés, nous avons, par exemple, une application de ressources dans notre base de données. Et nous en tirons trois autres ressources supplémentaires. Ceci est très similaire à la vue de la base de données. Ceci est une constatation des faits. Il s'agit d'une vue logique ou relationnelle.La prochaine étape pour Kubernetes est de donner une certaine illusion d'une base relationnelle ou logique au lieu d'une API REST hachée, où vous pouvez simplement écrire une règle. Tôt ou tard, tout circule dans la base de données, y compris les commentaires, les règles peuvent ressembler à ceci: "Si la charge a augmenté comme ça, alors augmentez la réplication comme ça." Nous aurons un petit sql ou une règle logique. Tout ce dont vous avez besoin est un moteur générique qui suivra. Mais c'est un brillant avenir.
— DevOops 2018 ! — .
«The DevOps Handbook» , «Learning Chef: A Guide to Configuration Management and Automation» , «How to containerize your Go code» «Liquid Software: How to Achieve Trusted Continuous Updates in the DevOps World» — . - .
: !
: 1 Vous pouvez réserver un billet pour DevOops 2018 à prix réduit.