Il semblerait que le sujet soit galvaudé - beaucoup a été dit et écrit sur la sauvegarde, donc il n'y a rien pour réinventer la roue, il suffit de la prendre et de la faire. Néanmoins, chaque fois que l'administrateur système d'un projet Web est confronté à la tâche de configurer des sauvegardes, pour beaucoup, il est suspendu dans l'air avec un gros point d'interrogation. Comment collecter correctement la sauvegarde des données? Où stocker les sauvegardes? Comment assurer le niveau nécessaire de stockage rétrospectif des copies? Comment unifier le processus de sauvegarde pour l'ensemble du zoo de différents logiciels?

Pour nous-mêmes, nous avons résolu ce problème pour la première fois en 2011. Ensuite, nous nous sommes assis et avons écrit nos scripts de sauvegarde. Au fil des ans, nous les avons utilisés uniquement et ils ont fourni avec succès un processus fiable de collecte et de synchronisation des sauvegardes des projets Web de nos clients. Les sauvegardes ont été stockées dans notre ou un autre stockage externe, avec la possibilité de régler pour un projet spécifique.
Je dois dire que ces scripts ont fonctionné au maximum. Mais plus nous progressions, plus nous avions de projets divers avec différents logiciels et référentiels externes que nos scripts ne prenaient pas en charge. Par exemple, nous n'avons pas pris en charge Redis et les sauvegardes à chaud MySQL et PostgreSQL qui sont apparues plus tard. Le processus de sauvegarde n'a pas été surveillé, il n'y a eu que des alertes par e-mail.
Un autre problème était le processus de support. Au fil des ans, nos scripts autrefois compacts se sont développés et se sont transformés en un énorme monstre maladroit. Et lorsque nous nous sommes réunis et avons publié une nouvelle version, cela valait la peine de déployer la mise à jour pour cette partie des clients qui utilisaient la version précédente avec une sorte de personnalisation.
En conséquence, au début de cette année, nous avons pris une décision ferme: remplacer nos anciens scripts de sauvegarde par quelque chose de plus moderne. Par conséquent, au début, nous nous sommes assis et avons écrit toute la liste de souhaits pour une nouvelle solution. Il s'est avéré approximativement ce qui suit:
- Sauvegardez les données des logiciels les plus fréquemment utilisés:
- Fichiers (copie discrète et incrémentielle)
- MySQL (sauvegardes à froid / à chaud)
- PostgreSQL (sauvegardes à froid / à chaud)
- Mongodb
- Redis
- Stockez les sauvegardes dans des référentiels populaires:
- Local
- FTP
- Ssh
- SMB
- Nfs
- Webdav
- S3
- Recevez des alertes en cas de problème pendant le processus de sauvegarde
- Avoir un seul fichier de configuration qui vous permet de gérer les sauvegardes de manière centralisée
- Ajoutez la prise en charge de nouveaux logiciels en connectant des modules externes
- Spécifiez des options supplémentaires pour la collecte des vidages
- Avoir la possibilité de restaurer des sauvegardes par des moyens réguliers
- Configuration initiale facile
Nous analysons les solutions disponibles
Nous avons examiné les solutions open source qui existent déjà:
- Bacula et ses fourchettes, par exemple, Bareos
- Amanda
- Borg
- Duplicaty
- Duplicité
- Rsnapshot
- Rdiff-backup
Mais chacun d'eux avait ses inconvénients. Par exemple, Bacula est surchargé de fonctions dont nous n'avons pas besoin, la configuration initiale est une tâche assez laborieuse en raison de la grande quantité de travail manuel (par exemple, pour écrire / rechercher des scripts de sauvegarde de base de données), et pour récupérer des copies, il est nécessaire d'utiliser des utilitaires spéciaux, etc.
En fin de compte, nous sommes arrivés à deux conclusions importantes:
- Aucune des solutions existantes ne nous convenait parfaitement;
- Il semble que nous-mêmes avions suffisamment d'expérience et de folie pour commencer à rédiger notre décision.
Nous l'avons donc fait.
La naissance de nxs-backup
Python a été choisi comme langage d'implémentation - il est facile à écrire et à maintenir, flexible et pratique. Il a été décidé de décrire les fichiers de configuration au format yaml.
Pour faciliter la prise en charge et l'ajout de sauvegardes de nouveaux logiciels, une architecture modulaire a été choisie où le processus de collecte des sauvegardes de chaque logiciel spécifique (par exemple, MySQL) est décrit dans un module distinct.
Prise en charge des fichiers, des bases de données et du stockage à distance
Actuellement, les types de sauvegardes de fichiers, bases de données et référentiels distants suivants sont pris en charge:
DB:
- MySQL (sauvegardes à chaud / à froid)
- PostgreSQL (sauvegardes à chaud / à froid)
- Redis
- Mongodb
Fichiers:
- Copie discrète
- Copie incrémentielle
Référentiels distants:
- Local
- S3
- SMB
- Nfs
- FTP
- Ssh
- Webdav
Sauvegarde discrète
Pour différentes tâches, des sauvegardes discrètes ou incrémentielles conviennent, par conséquent, elles ont implémenté les deux types. Vous pouvez spécifier la méthode à utiliser au niveau des fichiers et répertoires individuels.
Pour les copies discrètes (fichiers et bases de données), vous pouvez définir une rétrospective au format jours / semaines / mois.
Sauvegarde incrémentielle
Des copies incrémentielles des fichiers sont effectuées comme suit:
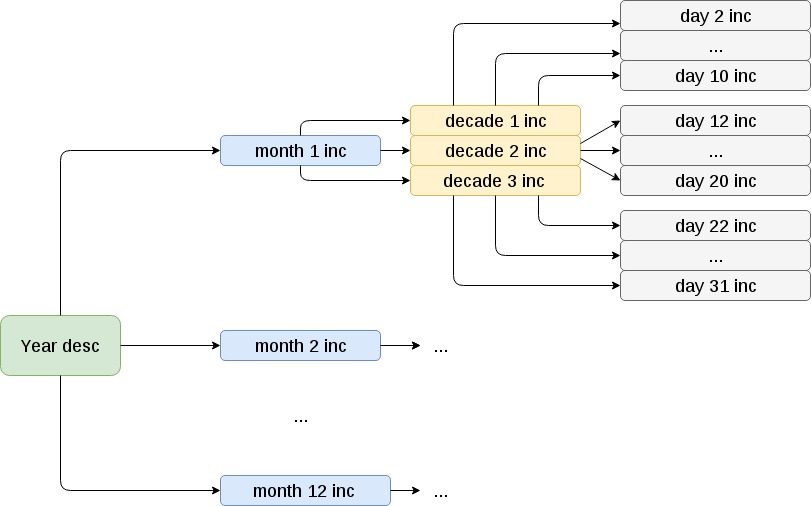
Au début de l'année, une sauvegarde complète est en cours. Ensuite, au début de chaque mois - une copie mensuelle incrémentielle par rapport à l'année. Au cours de la menstruation - décadale incrémentielle par rapport au mois. Dans chaque jour incrémentiel de dix jours par rapport à la période de dix jours.
Il convient de noter que, même s'il existe des problèmes lors de l'utilisation de répertoires contenant un grand nombre de sous-répertoires (des dizaines de milliers). Dans de tels cas, la collecte de copies est considérablement ralentie et peut prendre plus d'une journée. Nous nous attaquons activement à cette lacune.
Nous récupérons des sauvegardes incrémentielles
Il n'y a aucun problème avec la récupération à partir de sauvegardes discrètes - il suffit de prendre une copie pour la date requise et de la déployer avec le tar de console habituel. Les copies incrémentielles sont un peu plus compliquées. Pour récupérer, par exemple, le 24 juillet 2018, vous devez procéder comme suit:
- Développez une sauvegarde d'un an, même si dans notre cas elle commence à partir du 1er janvier 2018 (en pratique, cela peut être n'importe quelle date, selon le moment où il a été décidé d'implémenter des sauvegardes incrémentielles)
- Rouler sur lui une sauvegarde mensuelle pour juillet
- Rouler la sauvegarde de la décennie du 21 juillet
- Roll up sauvegarde quotidienne pour le 24 juillet
Dans le même temps, pour effectuer 2 à 4 points, vous devez ajouter le commutateur -G à la commande tar, indiquant ainsi qu'il s'agit d'une sauvegarde incrémentielle. Bien sûr, ce n'est pas le processus le plus rapide, mais si vous considérez qu'il n'est pas si souvent nécessaire de récupérer des sauvegardes et que la rentabilité est importante, un tel schéma s'avère assez efficace.
Exceptions
Souvent, vous devez exclure des fichiers ou des répertoires individuels des sauvegardes, par exemple, des répertoires avec un cache. Cela peut être fait en spécifiant les règles d'exception appropriées:
exemple de fichier de configuration- target: - /var/www/*/data/ excludes: - exclude1/exclude_file - exclude2 - /var/www/exclude_3
Rotation de sauvegarde
Dans nos anciens scripts, la rotation était implémentée de sorte que l'ancienne copie n'était supprimée qu'après que la nouvelle ait été correctement assemblée. Cela a entraîné des problèmes sur les projets où l'espace pour les sauvegardes, en principe, était alloué exactement pour une copie - une nouvelle copie n'a pas pu être collectée à cause d'un manque d'espace.
Dans la nouvelle implémentation, nous avons décidé de changer cette approche: supprimez d'abord l'ancienne et ensuite seulement collectez une nouvelle copie. Et le processus de collecte des sauvegardes doit être surveillé pour détecter tout problème.
Pour les sauvegardes discrètes, une archive est considérée comme une ancienne copie qui va au-delà du schéma de stockage spécifié au format jours / semaines / mois. Dans le cas des sauvegardes incrémentielles, les sauvegardes sont stockées par défaut pendant un an, et les anciennes copies sont supprimées au début de chaque mois, tandis que les archives du même mois de l'année dernière sont considérées comme des anciennes sauvegardes. Par exemple, avant de collecter une sauvegarde mensuelle le 1er août 2018, le système vérifiera s'il existe des sauvegardes pour août 2017 et, dans l'affirmative, il les supprimera. Cela permet une utilisation optimale de l'espace disque.
Journalisation
Dans tous les processus, et en particulier dans les sauvegardes, il est important de se tenir au courant et de savoir si quelque chose s'est mal passé. Le système conserve un journal de son travail et capture le résultat de chaque étape: début / fin des fonds, début / fin d'une tâche spécifique, résultat de la collecte d'une copie dans un répertoire temporaire, résultat de la copie / déplacement d'une copie d'un répertoire temporaire vers un emplacement permanent, résultat d'une rotation de sauvegarde, etc. ..
Les événements sont divisés en 2 niveaux:
- Info : niveau d'information - le vol est normal, l'étape suivante s'est terminée avec succès, une entrée d'information correspondante est effectuée dans le journal
- Erreur : niveau d'erreur - quelque chose s'est mal passé, l'étape suivante a échoué, un enregistrement d'erreur correspondant est créé dans le journal
Notifications par e-mail
À la fin de la collecte de sauvegarde, le système peut envoyer des notifications par e-mail.
2 listes de destinataires sont prises en charge:
- Les administrateurs sont ceux qui servent le serveur. Ils ne reçoivent que des notifications d'erreurs; ils ne sont pas intéressés par les notifications d'opérations réussies
- Utilisateurs professionnels - dans notre cas, ce sont des clients qui souhaitent parfois recevoir des notifications afin de s'assurer que tout va bien avec les sauvegardes. Ou, inversement, pas vraiment. Ils peuvent choisir de recevoir un journal complet ou uniquement un journal avec des erreurs.
Structure du fichier de configuration
La structure des fichiers de configuration est la suivante:
exemple de structure /etc/nxs-backup ├── conf.d │ ├── desc_files_local.conf │ ├── external_clickhouse_local.conf │ ├── inc_files_smb.conf │ ├── mongodb_nfs.conf │ ├── mysql_s3.conf │ ├── mysql_xtradb_scp.conf │ ├── postgresql_ftp.conf │ ├── postgresql_hot_webdav.conf │ └── redis_local_ftp.conf └── nxs-backup.conf
Ici /etc/nxs-backup/nxs-backup.conf est le fichier de configuration principal dans lequel les paramètres globaux sont indiqués:
fichier de configuration main: server_name: SERVER_NAME admin_mail: project-tech@nixys.ru client_mail: - '' mail_from: backup@domain.ru level_message: error block_io_read: '' block_io_write: '' blkio_weight: '' general_path_to_all_tmp_dir: /var/nxs-backup cpu_shares: '' log_file_name: /var/log/nxs-backup/nxs-backup.log jobs: !include [conf.d
Le tableau des tâches (travaux) contient une liste de tâches (travaux), qui sont une description de quoi exactement sauvegarder, où stocker et en quelle quantité. En règle générale, ils sont déplacés vers des fichiers séparés (un fichier par tâche), qui sont connectés via include dans le fichier de configuration principal.
Ils ont également pris soin d'optimiser au maximum le processus de préparation de ces fichiers et ont écrit un générateur simple. Par conséquent, l'administrateur n'a pas besoin de passer du temps à rechercher le modèle de configuration pour un service, par exemple, MySQL, mais il suffit d'exécuter la commande:
nxs-backup generate --storage local scp --type mysql --path /etc/nxs-backup/conf.d/mysql_local_scp.conf
La sortie génère le fichier /etc/nxs-backup/conf.d/mysql_local_scp.conf :
Contenu du fichier - job: PROJECT-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: '' db_port: '' socket: '' db_user: '' db_password: '' auth_file: '' target: - all excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump store: days: '' weeks: '' month: '' - storage: scp enable: yes backup_dir: /var/nxs-backup/databases/mysql/dump user: '' host: '' port: '' password: '' path_to_key: '' store: days: '' weeks: '' month: ''
Dans lequel il ne reste plus qu'à substituer quelques valeurs nécessaires.
Prenons un exemple. Supposons que sur notre serveur dans le répertoire / var / www, il existe deux sites de la boutique en ligne 1C-Bitrix (bitrix-1.ru, bitrix-2.ru), chacun travaillant avec sa propre base de données dans différentes instances MySQL (port 3306 pour bitrix_1_db et port 3307 pour bitrix_2_db).
La structure de fichiers d'un projet Bitrix typique est approximativement la suivante:
├── ... ├── bitrix │ ├── .. │ ├── admin │ ├── backup │ ├── cache │ ├── .. │ ├── managed_cache │ ├── .. │ ├── stack_cache │ └── .. ├── upload └── ...
En règle générale, le répertoire de téléchargement pèse beaucoup et ne fait qu'augmenter avec le temps, il sera donc sauvegardé de manière incrémentielle. Tous les autres répertoires sont discrets, à l'exception des répertoires avec cache et sauvegardes collectés par les outils Bitrix natifs. Laissez le schéma de stockage de sauvegarde pour ces deux sites devrait être le même, tandis que les copies des fichiers doivent être stockées localement et sur le stockage ftp distant, et la base de données doit être stockée uniquement sur le stockage smb distant.
Les fichiers de configuration résultants pour une telle configuration ressembleront à ceci:
bitrix-desc-files.conf (fichier de configuration avec description du travail pour la sauvegarde discrète) - job: Bitrix-desc-files type: desc_files tmp_dir: /var/nxs-backup/files/desc/dump_tmp sources: - target: - /var/www/*/ excludes: - bitrix/backup - bitrix/cache - bitrix/managed_cache - bitrix/stack_cache - upload gzip: yes storages: - storage: local enable: yes backup_dir: /var/nxs-backup/files/desc/dump store: days: 6 weeks: 4 month: 6 - storage: ftp enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: ftp_host user: ftp_usr password: ftp_usr_pass store: days: 6 weeks: 4 month: 6
bitrix-inc-files.conf (fichier de configuration avec description du travail pour la sauvegarde incrémentielle) - job: Bitrix-inc-files type: inc_files sources: - target: - /var/www/*/upload/ gzip: yes storages: - storage: ftp enable: yes backup_dir: /nxs-backup/files/inc host: ftp_host user: ftp_usr password: ftp_usr_pass - storage: local enable: yes backup_dir: /var/nxs-backup/files/inc
bitrix-mysql.conf (fichier de configuration avec description du travail pour les sauvegardes MySQL) - job: Bitrix-mysql type: mysql tmp_dir: /var/nxs-backup/databases/mysql/dump_tmp sources: - connect: db_host: localhost db_port: 3306 db_user: bitrux_usr_1 db_password: password_1 target: - bitrix_1_db excludes: - information_schema - performance_schema - mysql - sys gzip: no is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' - connect: db_host: localhost db_port: 3307 db_user: bitrix_usr_2 db_password: password_2 target: - bitrix_2_db excludes: - information_schema - performance_schema - mysql - sys gzip: yes is_slave: no extra_keys: '--opt --add-drop-database --routines --comments --create-options --quote-names --order-by-primary --hex-blob' storages: - storage: smb enable: yes backup_dir: /nxs-backup/databases/mysql/dump host: smb_host port: smb_port share: smb_share_name user: smb_usr password: smb_usr_pass store: days: 6 weeks: 4 month: 6
Options pour commencer à collecter des sauvegardes
Dans l'exemple précédent, nous avons préparé des fichiers de configuration de travail pour collecter les sauvegardes de tous les éléments à la fois: fichiers (discrets et incrémentiels), deux bases de données et les stocker sur des stockages locaux et externes (ftp, smb).
Il reste à gérer le tout. Le lancement est effectué par la commande:
nxs-backup start $JOB_NAME -c $PATH_TO_MAIN_CONFIG
Il existe plusieurs noms de tâches réservés:
- fichiers - exécution arbitraire de tous les travaux avec les types desc_files , inc_files (c'est-à-dire, essentiellement, seuls les fichiers sont sauvegardés )
- bases de données - exécution aléatoire de toutes les tâches avec les types mysql , mysql_xtradb , postgresql , postgresql_hot , mongodb , redis (c'est-à-dire, sauvegarder uniquement la base de données)
- externe - exécution aléatoire de toutes les tâches avec le type externe (exécution uniquement de scripts personnalisés supplémentaires, plus d'informations ci-dessous)
- all - imitation d'exécuter la commande une par une avec les fichiers de travail, les bases de données , externes (valeur par défaut)
Étant donné que nous devons obtenir des sauvegardes de données des fichiers et de la base de données en même temps (ou avec une différence minimale) en sortie, il est recommandé d'exécuter nxs-backup avec job all , ce qui garantira une exécution cohérente du travail décrit (Bitrix-desc- fichiers, Bitrix-inc_files, Bitrix-mysql).
Autrement dit, un point important - les sauvegardes ne seront pas collectées en parallèle, mais séquentiellement, l'une après l'autre, avec un décalage horaire minimum. De plus, au prochain démarrage, le logiciel lui-même vérifie le processus déjà en cours dans le système et s'il est détecté, il terminera automatiquement son travail avec la marque correspondante dans le journal. Cette approche réduit considérablement la charge sur le système. Moins - les sauvegardes des éléments individuels sont collectées non pas immédiatement, mais avec un certain décalage horaire. Mais alors que notre pratique montre que ce n'est pas critique.
Modules externes
Comme mentionné ci-dessus, grâce à l'architecture modulaire, les capacités du système peuvent être étendues à l'aide de modules utilisateur supplémentaires qui interagissent avec le système via une interface spéciale. L'objectif est de pouvoir à l'avenir ajouter la prise en charge des sauvegardes de nouveaux logiciels sans avoir à réécrire nxs-backup.
exemple de fichier de configuration - job: TEST-external type: external dump_cmd: '' storages: ….
Une attention particulière doit être accordée à la clé dump_cmd , où la valeur est la commande complète pour exécuter un script externe. De plus, à la fin de cette commande, il est prévu que:
- Une archive prête à l'emploi des données du logiciel sera collectée
- Les données seront envoyées à stdout au format json, sous la forme:
{ "full_path": "ABS_PATH_TO_ARCHIVE", "basename": "BASENAME_ARCHIVE", "extension": "EXTERNSION_OF_ARCHIVE", "gzip": true/false }
- Dans ce cas, les clés basename , extension , gzip sont nécessaires exclusivement pour la formation du nom de sauvegarde final.
- En cas de réussite du script, le code retour doit être 0 et tout autre en cas de problème.
Par exemple, supposons que nous ayons un script pour créer un instantané etcd /etc/nxs-backup-ext/etcd.py :
La configuration pour exécuter ce script est la suivante:
fichier de configuration - job: etcd-external type: external dump_cmd: '/etc/nxs-backup-ext/etcd.py' storages: - storage: local enable: yes backup_dir: /var/nxs-backup/external/dump store: days: 6 weeks: 4 month: 6
Dans ce cas, le programme lors de l'exécution du travail etcd-external :
- Exécutez le script /etc/nxs-backup-ext/etcd.py sans paramètres
- Une fois le script terminé, il vérifiera le code d'achèvement et la disponibilité des données nécessaires dans stdout
- Si toutes les vérifications réussissent, le même mécanisme est utilisé qu'avec les modules déjà intégrés, où la valeur de la clé full_path est utilisée comme tmp_path. Sinon, il terminera cette tâche avec la marque correspondante dans le journal.
Support et mise à jour
Le processus de développement et de prise en charge du nouveau système de sauvegarde a été mis en œuvre avec tous les canons de CI / CD. Plus de mises à jour et de modifications de script sur les serveurs de combat. Toutes les modifications passent par notre référentiel git central dans Gitlab, où l'assemblage de nouvelles versions des paquets deb / rpm est enregistré dans le pipeline, qui sont ensuite téléchargés dans nos référentiels deb / rpm. Et après cela, via le gestionnaire de packages, ils sont livrés aux serveurs clients finaux.
Comment télécharger nxs-backup?
Nous avons fait un projet open-source nxs-backup. Tout le monde peut le télécharger et l'utiliser pour organiser le processus de sauvegarde dans ses projets, ainsi que modifier selon ses besoins, écrire des modules externes.
Le code source de nxs-backup peut être téléchargé à partir du référentiel Github sur ce lien . Il y a également des instructions d'installation et de configuration.
Nous avons également préparé une image Docker et l' avons publiée sur DockerHub .
Si vous avez des questions pendant la configuration ou l'utilisation, écrivez-nous. Nous vous aiderons à comprendre et à finaliser les instructions.
Conclusion
Dans un avenir proche, nous mettrons en œuvre les fonctionnalités suivantes:
- Surveillance de l'intégration
- Chiffrement de sauvegarde
- Interface Web pour gérer les paramètres de sauvegarde
- Déployer des sauvegardes à l'aide de nxs-backup
- Et bien plus