Les éditeurs de texte modernes peuvent non seulement émettre un bip et ne pas quitter le programme. Il s'avère qu'un métabolisme très complexe bout en eux. Vous voulez savoir quelles astuces sont effectuées pour recalculer rapidement les coordonnées, comment les styles, les plis et les enveloppements logiciels sont attachés au texte et comment tout est mis à jour, qu'est-ce que la structure de données fonctionnelles et la file d'attente prioritaire ont à voir avec cela, ainsi que comment tromper l'utilisateur - bienvenue au chat!

L'article est basé sur le
rapport d' Alexei Kudryavtsev avec Joker 2017. Alexei écrit Intellij IDEA dans JetBrains depuis environ 10 ans. Sous la coupe, vous trouverez la vidéo et la transcription textuelle du rapport.
Structures de données à l'intérieur des éditeurs de texte
Pour comprendre comment l'éditeur fonctionne, écrivons-le.

Voilà, notre éditeur le plus simple est prêt.
À l'intérieur de l'éditeur, le texte est plus facile à stocker dans un tableau de caractères ou, ce qui est le même (en termes d'organisation de la mémoire), dans la classe Java StringBuffer. Pour obtenir du caractère par décalage, nous appelons la méthode StringBuffer.charAt (i). Et pour y insérer le caractère que nous avons tapé sur le clavier, nous appelons la méthode StringBuffer.insert (), qui insère le caractère quelque part au milieu.
Ce qui est le plus intéressant, malgré toute la simplicité et l'idiotie de cet éditeur, c'est la meilleure idée que l'on puisse inventer. C'est à la fois simple et presque toujours rapide.
Malheureusement, un problème d'échelle se pose avec cet éditeur. Imaginez que nous y imprimions beaucoup de texte et que nous allons insérer une autre lettre au milieu. Les événements suivants se produiront. Nous devons de toute urgence libérer de l'espace pour cette lettre en déplaçant toutes les autres lettres d'un caractère vers l'avant. Pour ce faire, nous décalons cette lettre d'une position, puis de la suivante et ainsi de suite, jusqu'à la fin du texte.
Voici à quoi cela ressemblerait en mémoire:
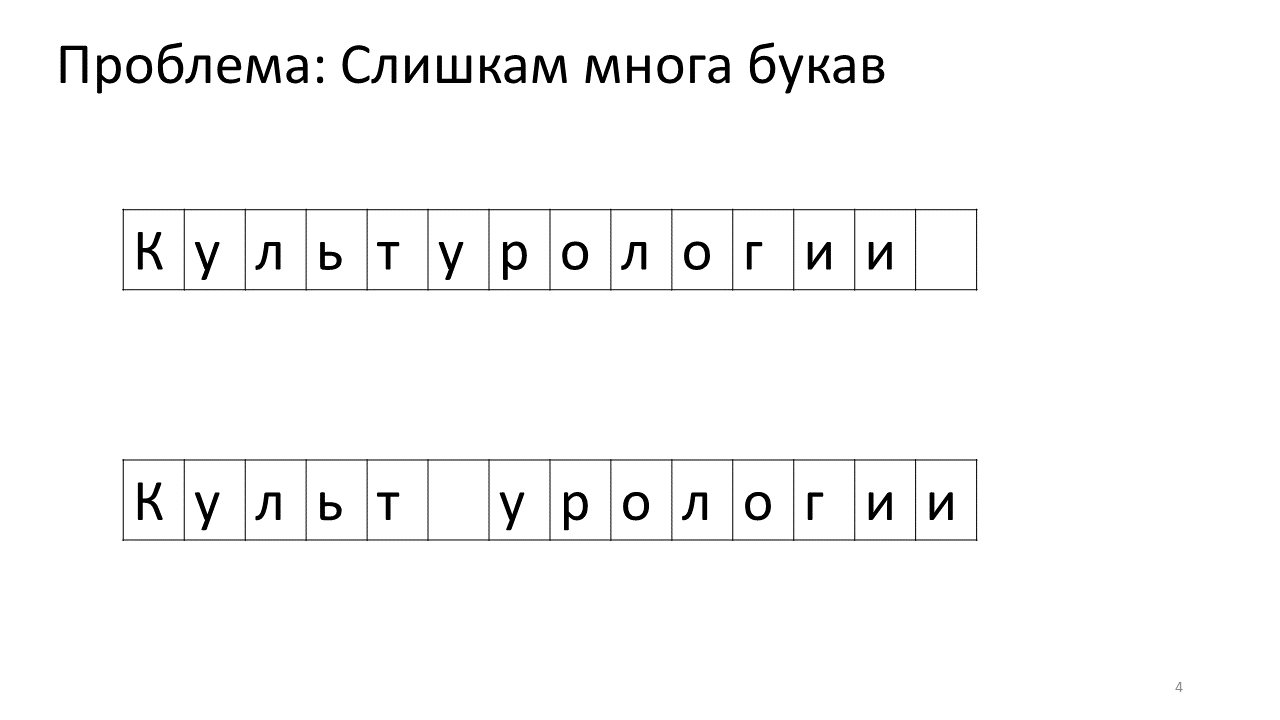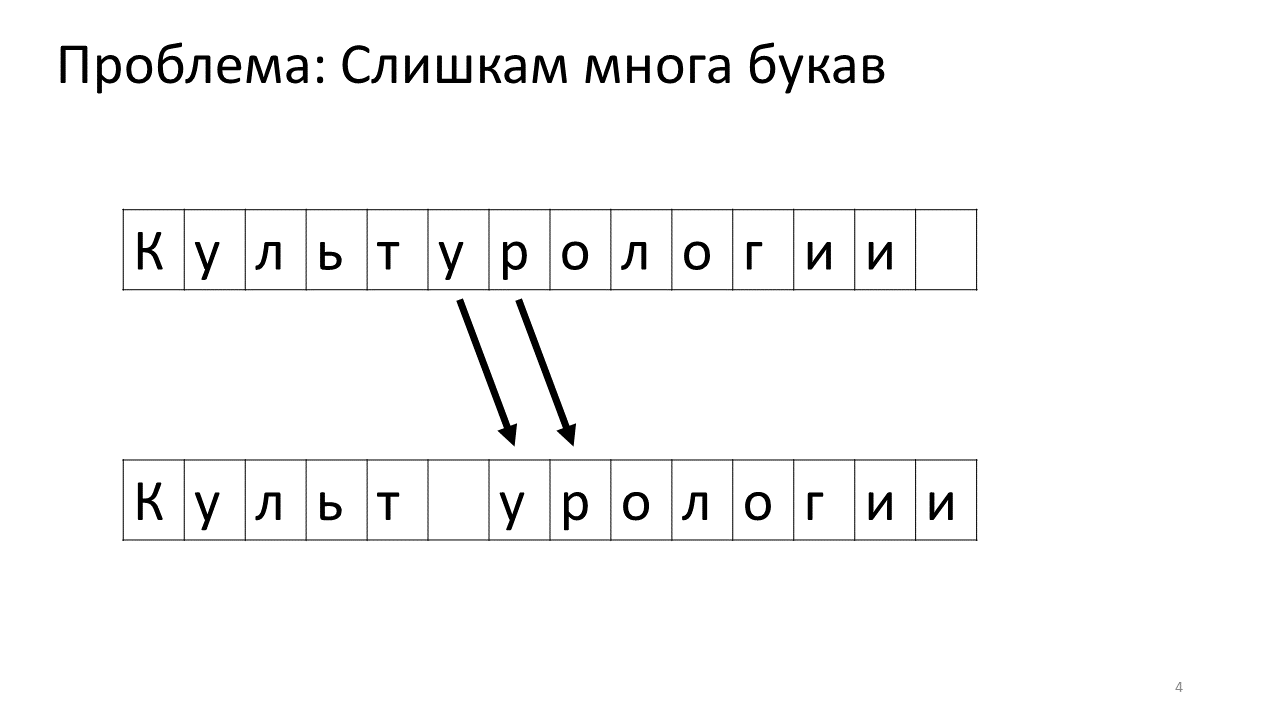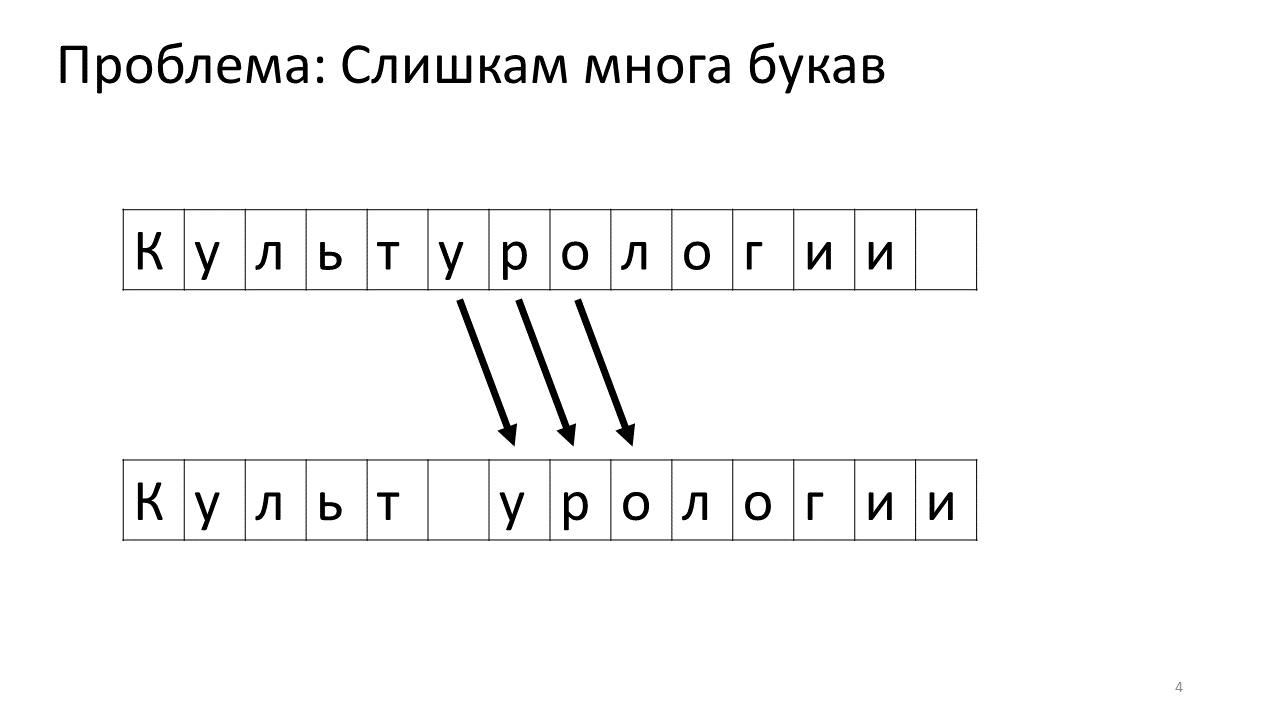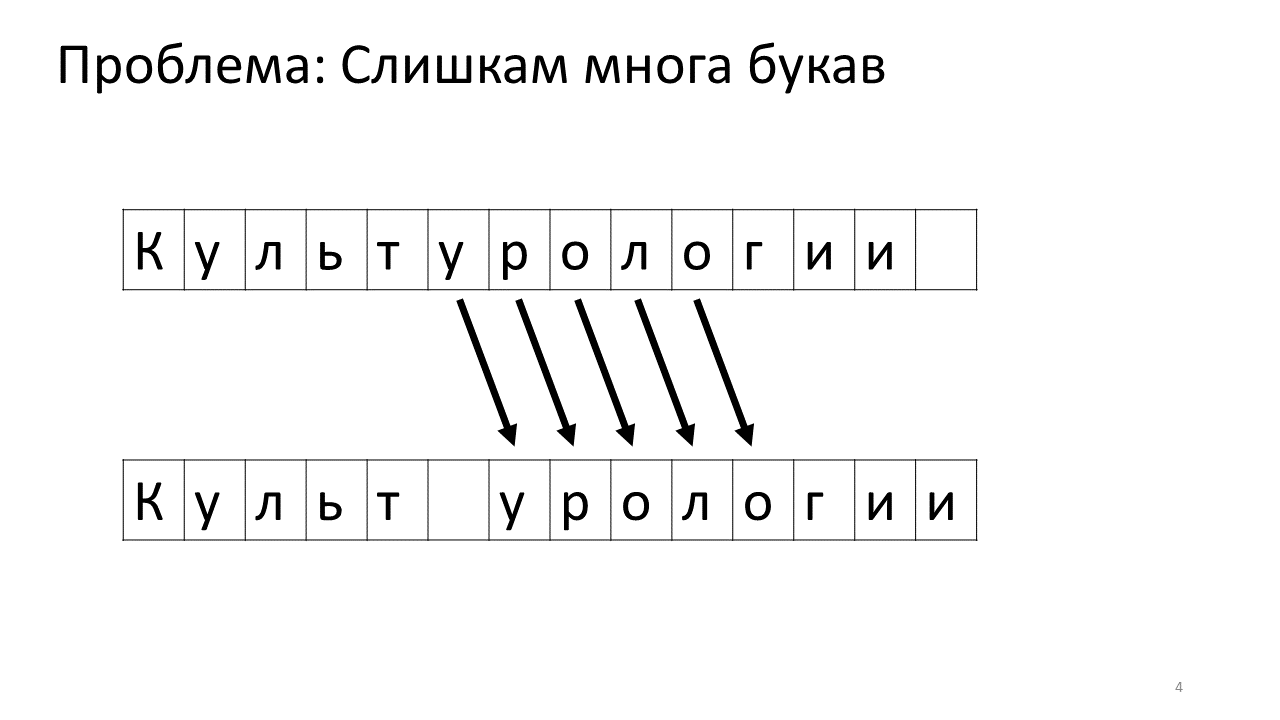
Décaler tous ces mégaoctets n'est pas très bon: c'est lent. Bien sûr, pour un ordinateur moderne, c'est une affaire insignifiante - une sorte de mégaoctets pathétiques pour se déplacer d'avant en arrière. Mais pour un changement de texte très actif, cela peut être perceptible.
Pour résoudre ce problème d'insertion d'un personnage au milieu, il y a longtemps est venu une solution de contournement appelée "Gap Buffer".
Tampon d'espace
L'écart est l'écart. Le tampon est, comme vous pouvez l'imaginer, un tampon. La structure de données Gap Buffer est un tel tampon vide que nous gardons au milieu de notre texte, juste au cas où. Si nous avions besoin d'imprimer quelque chose, nous utilisons ce petit tampon de texte pour une saisie rapide.

La structure des données a un peu changé - le tableau est resté en place, mais deux pointeurs sont apparus: au début du tampon et à sa fin. Pour prendre un caractère de l'éditeur à un certain décalage, nous devons comprendre s'il se trouve avant ou après ce tampon et corriger légèrement le décalage. Et pour insérer un personnage, nous devons d'abord déplacer le Gap Buffer à cet endroit et le remplir avec ces caractères. Et, bien sûr, si nous allons au-delà de notre tampon, recréez-le d'une manière ou d'une autre. Voici à quoi cela ressemble dans l'image.

Comme vous pouvez le voir, nous nous déplaçons d'abord pendant longtemps sur un petit tampon d'espace (rectangle bleu) vers l'emplacement d'édition (en échangeant simplement les caractères à partir de ses bords gauche et droit à leur tour). Ensuite, nous utilisons ce tampon, en tapant des caractères là-bas.
Comme vous pouvez le constater, il n'y a pas de mouvement de mégaoctets de caractères, l'insert est très rapide, pendant un temps constant, et il semble que tout le monde soit content. Tout semble aller bien, mais si notre processeur est très lent, un temps assez important est perdu pour déplacer le tampon d'écart et le texte d'avant en arrière. Cela était particulièrement visible lors de très petits mégahertz.
Table des pièces
Juste à ce moment-là, une société appelée Microsoft a écrit un éditeur de texte Word. Ils ont décidé d'appliquer une autre idée pour accélérer l'édition appelée «Tableau de pièces», c'est-à-dire «Tableau de pièces». Et ils ont proposé de sauvegarder le texte de l'éditeur dans le même tableau de caractères le plus simple, qui ne changera pas, et de mettre toutes ses modifications dans un tableau séparé de ces pièces très modifiées.

Ainsi, si nous avons besoin de trouver un caractère par décalage, nous devons trouver cette pièce que nous avons éditée et en extraire ce personnage, et s'il n'est pas là, alors aller au texte d'origine. L'insertion d'un symbole devient plus facile, il suffit de créer et d'ajouter cette nouvelle pièce au tableau. Voici à quoi cela ressemble dans l'image:
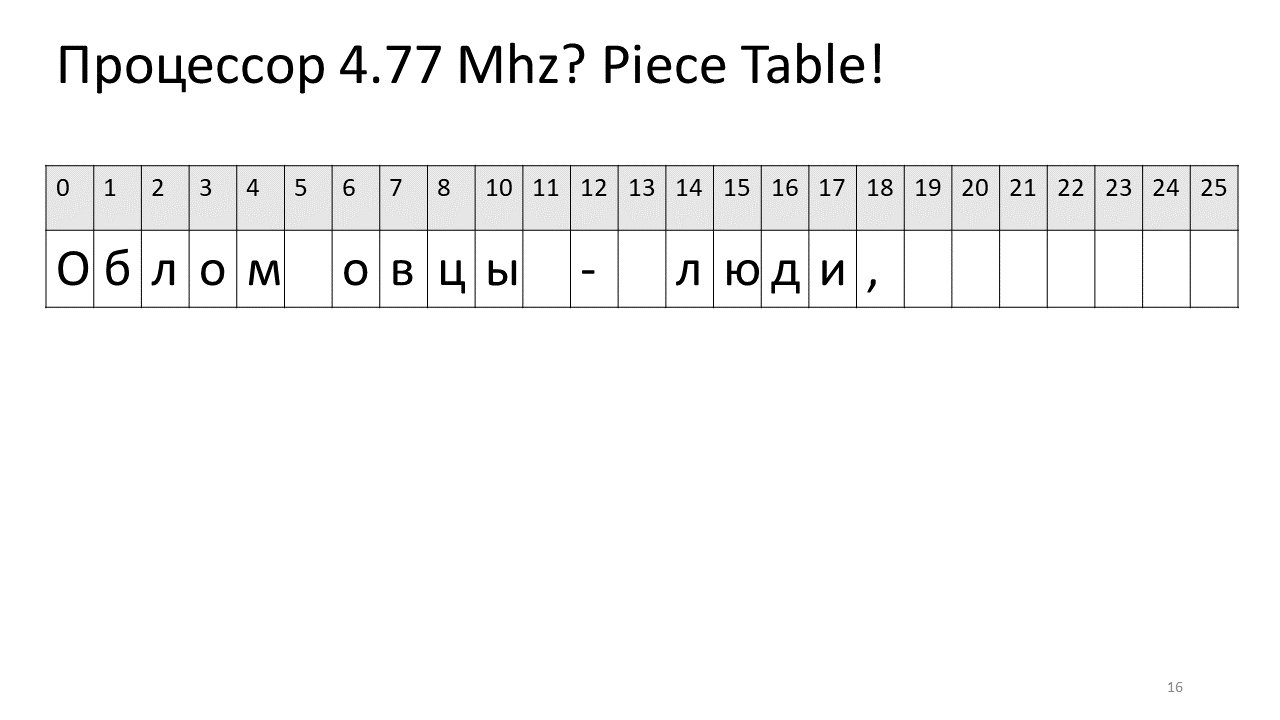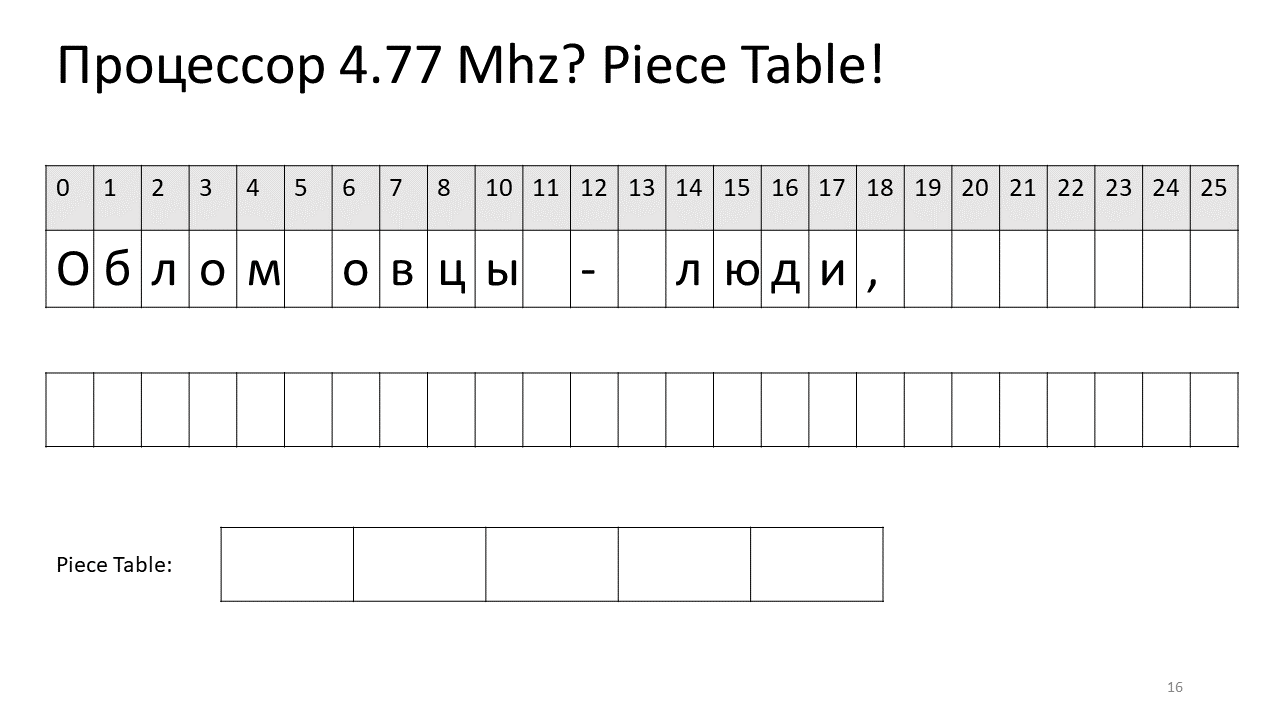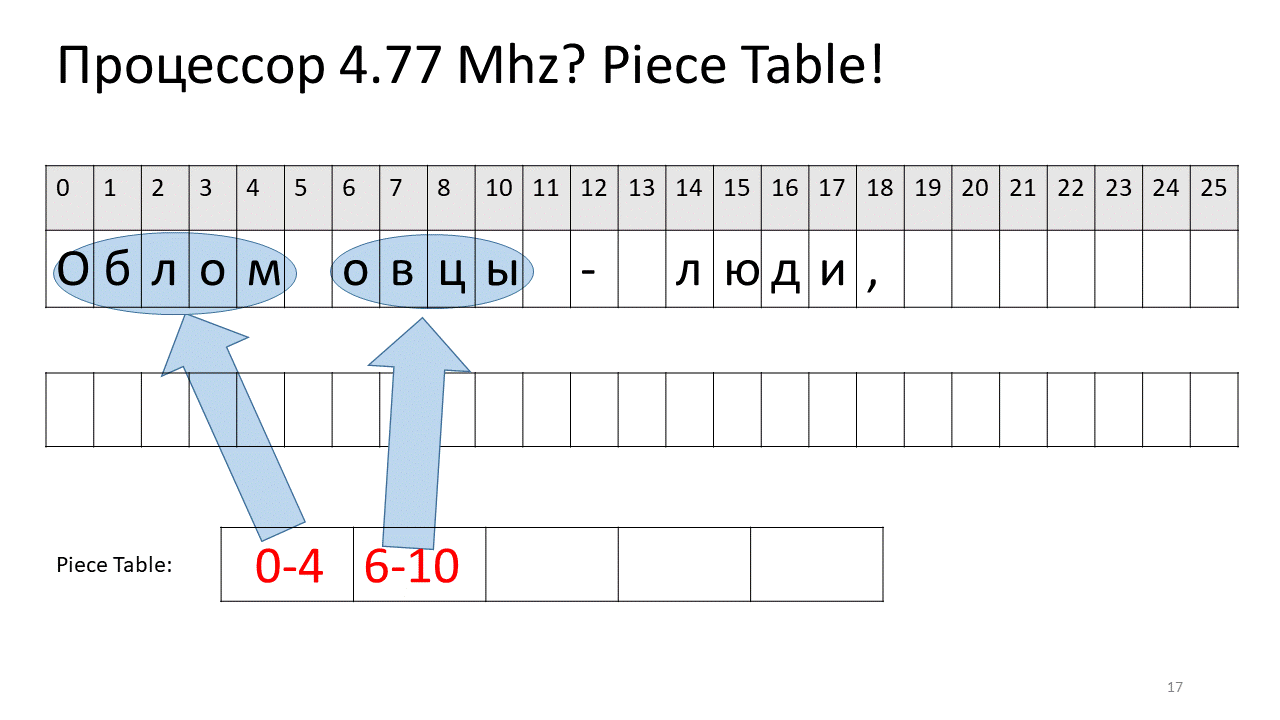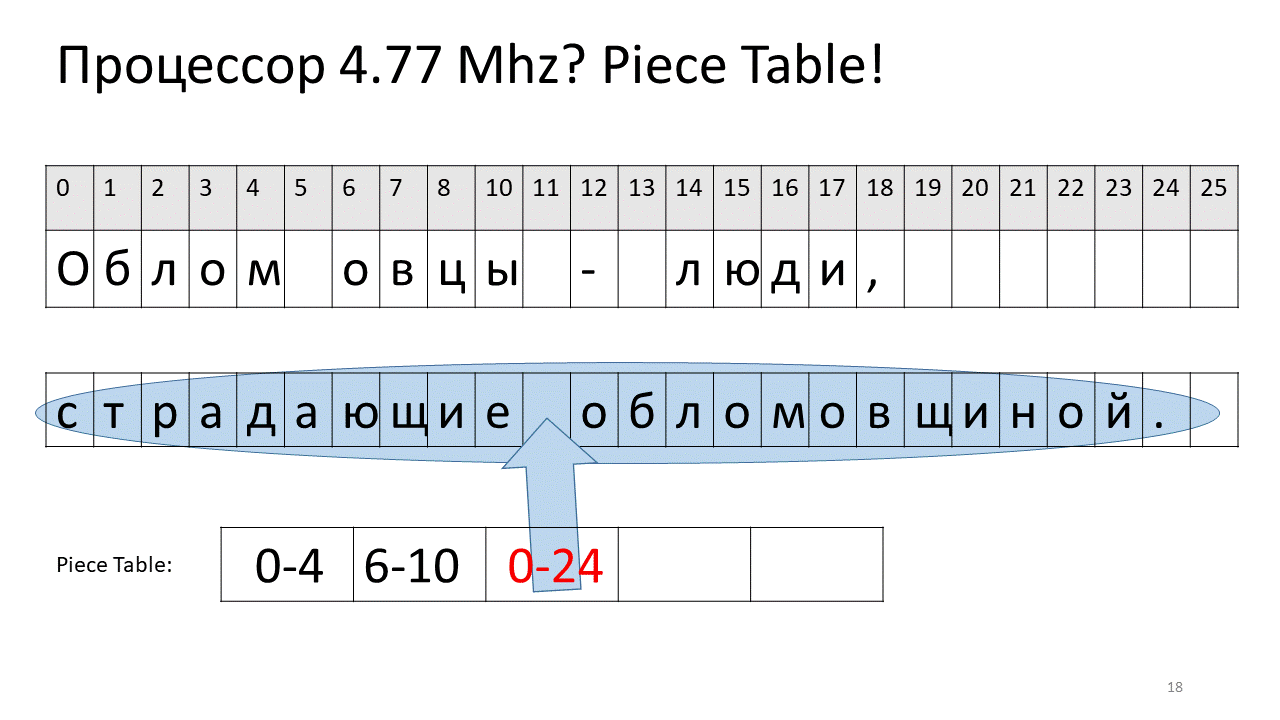
Ici, nous voulions supprimer l'espace au décalage 5. Pour ce faire, nous ajoutons deux nouveaux morceaux à la table des tranches: l'un indique le premier fragment ("Bummer"), et le second indique le fragment après modification ("mouton"). Il s'avère que l'écart entre eux disparaît, ces deux pièces sont collées ensemble, et nous obtenons déjà un nouveau texte sans espace: «Oblomovtsy». Ensuite, nous ajoutons le nouveau texte ("souffrant d'oblomovisme") à la fin. Utilisez un tampon supplémentaire et ajoutez une nouvelle tranche à la table des pièces qui pointe vers ce texte le plus récent ajouté.
Comme vous pouvez le voir, il n'y a pas de mouvement de va-et-vient, tout le texte reste en place. La mauvaise nouvelle est qu'il devient de plus en plus difficile d'accéder au symbole, car trier toutes ces pièces est assez difficile.
Pour résumer.
Ce qui est bien avec
Piece Table :
- Intégrez rapidement;
- Annulation facile;
- Ajouter uniquement.
Ce qui est mauvais:
- Il est terriblement difficile d'accéder à un document;
- C'est terriblement difficile à mettre en œuvre.
Voyons qui nous utilisons habituellement quoi.
NetBeans, Eclipse et Emacs utilisent Gap Buffer - bravo! Vi ne dérange pas et utilise juste une liste de lignes. Word utilise la table des pièces (ils ont récemment présenté leurs anciennes sortes et là vous pouvez même comprendre quelque chose).
Atom est plus intéressant. Jusqu'à récemment, ils ne se gênaient pas et utilisaient une liste de lignes JavaScript. Et puis ils ont décidé de tout réécrire en C ++ et ont accumulé une structure assez compliquée, qui semble être similaire à la table des morceaux. Mais ces pièces ne sont pas stockées dans la liste, mais dans l'arborescence et dans ce que l'on appelle l'arborescence splay - il s'agit d'une arborescence qui s'auto-ajuste lorsqu'elle est insérée dans celle-ci, afin que les insertions récentes soient plus rapides. Ils ont fait une chose très compliquée.
Qu'est-ce qu'Intellij IDEA utilise?
Non, pas de tampon d'écart. Non, vous vous trompez aussi, pas une table à pièces.
Oui, tout à fait, votre propre vélo.
Le fait est que les exigences de l'EDI pour le stockage de texte sont légèrement différentes de celles d'un éditeur de texte standard. L'IDE a besoin de support pour diverses choses délicates comme la compétitivité, c'est-à-dire l'accès parallèle au texte depuis l'éditeur. Par exemple, afin que de nombreux produits de boulangerie différents puissent le lire et faire quelque chose. (L'inspection est un petit morceau de code qui analyse le programme d'une manière ou d'une autre - par exemple, à la recherche d'endroits qui lèvent une exception NullPointerException). IDE a également besoin d'un support de version texte modifiable. Plusieurs versions sont simultanément en mémoire pendant que vous travaillez avec un document afin que ces longs processus continuent d'analyser l'ancienne version.
Les problèmes
Compétitivité / versioning
Afin de maintenir le parallélisme, les opérations de texte sont généralement enveloppées de «synchronisé» ou de verrous de lecture / écriture. Malheureusement, cela n'évolue pas très bien. Une autre approche est le texte immuable, c'est-à-dire un référentiel de texte immuable.

Voici à quoi ressemble un éditeur avec un document immuable comme structure de données de support.
Comment fonctionne la structure des données?
Au lieu d'un tableau de caractères, nous aurons un nouvel objet de type ImmutableText, qui stocke du texte sous la forme d'un arbre, où de petites sous-chaînes sont stockées dans les feuilles. En accédant à un certain décalage, il essaie d'atteindre la toute dernière feuille de cet arbre, et on lui demandera déjà le symbole auquel nous faisions référence. Et lorsque vous insérez du texte, il crée un nouvel arbre et l'enregistre à l'ancien emplacement.

Par exemple, nous avons un document avec le texte «sans calories». Il est implémenté comme un arbre avec deux feuilles de substitutions "Démon" et "hypercalorique". Lorsque nous voulons insérer la ligne «jolie» au milieu, une nouvelle version de notre document est créée. Et précisément, une nouvelle racine est créée, à laquelle trois feuilles sont déjà attachées: «Démon», «assez» et «hypercalorique». De plus, deux de ces nouvelles fiches peuvent faire référence à la première version de notre document. Et pour la feuille dans laquelle nous avons inséré la ligne «jolie», un nouveau sommet est alloué. Ici, la première version et la deuxième version sont disponibles en même temps et elles sont toutes immuables, immuables. Tout a l'air bien.
Qui utilise quelles structures délicates?

Par exemple, dans GNOME, certains de leurs widgets standard utilisent une structure appelée Rope. Xi-Editor, le nouvel éditeur brillant de
Raf Levien , utilise Persistent Rope. Et Intellij IDEA utilise cet arbre immuable. Derrière tous ces noms, en fait, se trouve plus ou moins la même structure de données avec une représentation arborescente du texte. Sauf que GtkTextBuffer utilise Mutable Rope, c'est-à-dire un arbre avec des sommets mutables, et Intellij IDEA et Xi-Editor - Immutable.
La prochaine chose à considérer lors du développement d'un référentiel de caractères dans les IDE modernes est appelée multicats. Cette fonction vous permet d'imprimer à plusieurs endroits à la fois, en utilisant plusieurs chariots.

Nous pouvons imprimer quelque chose et en même temps, à plusieurs endroits du document, nous insérons ce que nous y avons imprimé. Si nous regardons comment nos structures de données, que nous avons examinées, réagissent aux multicarets, nous verrons quelque chose d'intéressant.
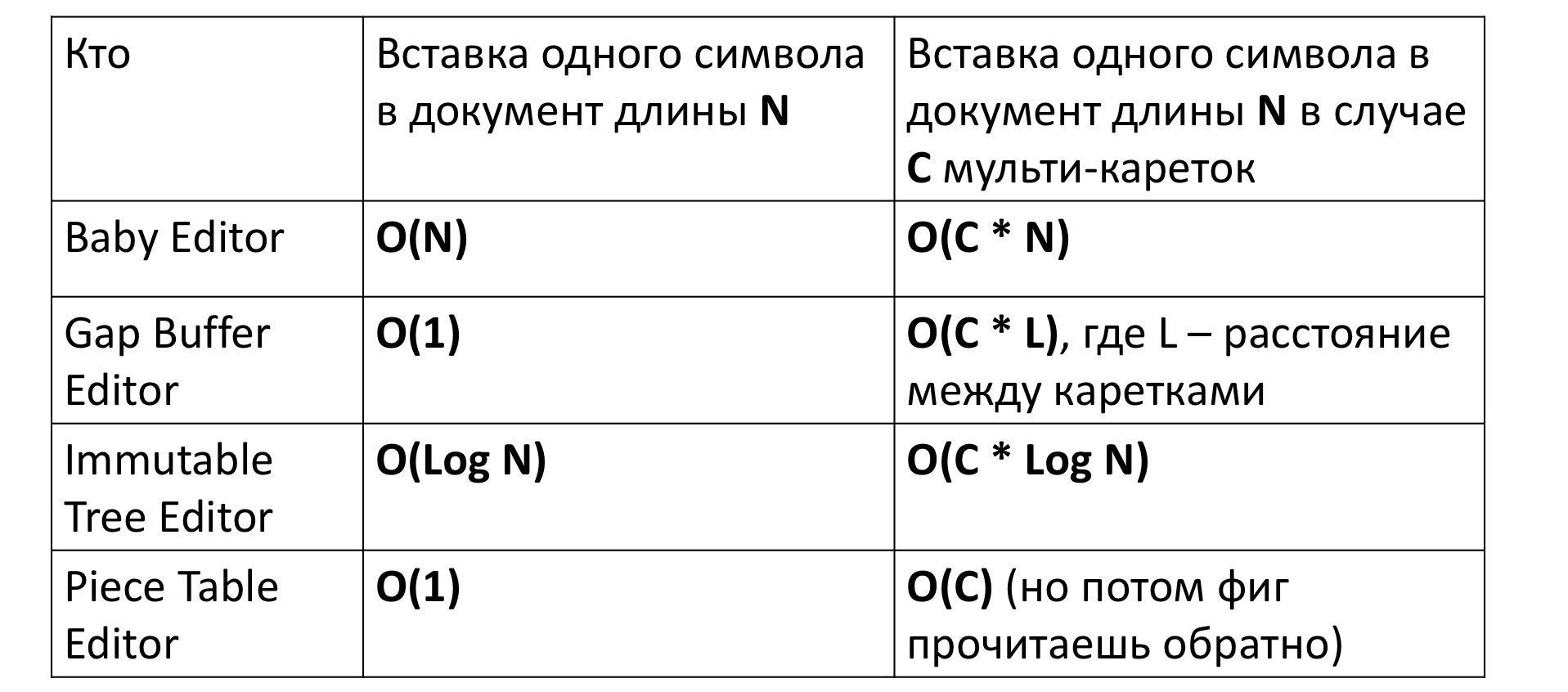
Si nous insérons un caractère dans notre tout premier éditeur primitif, il faudra naturellement un temps linéaire pour déplacer un groupe de caractères dans les deux sens. Ceci est écrit comme O (N). Pour l'éditeur basé sur Gap Buffer, à son tour, un temps constant est nécessaire, pour lequel il a été inventé.
Pour un arbre immuable, le temps dépend logarithmiquement de la taille, car vous devez d'abord aller du haut de l'arbre à sa feuille - c'est le logarithme, puis pour tous les sommets sur le chemin pour créer de nouveaux sommets pour le nouvel arbre - c'est encore le logarithme. Le tableau des pièces nécessite également une constante.
Mais tout change un peu si nous essayons de mesurer le temps d'insertion d'un personnage dans un éditeur à plusieurs chariots, c'est-à-dire l'insertion simultanée à plusieurs endroits. À première vue, le temps semble augmenter proportionnellement d'un facteur C - le nombre d'endroits où le symbole est inséré. C'est exactement ce qui se passe, à l'exception de Gap Buffer. Dans son cas, le temps, au lieu de C fois, augmente de façon inattendue des temps C * L incompréhensibles, où L est la distance moyenne entre les chariots. Pourquoi cela se produit-il?
Imaginez que nous devons insérer la ligne «, on» à deux endroits dans notre document.
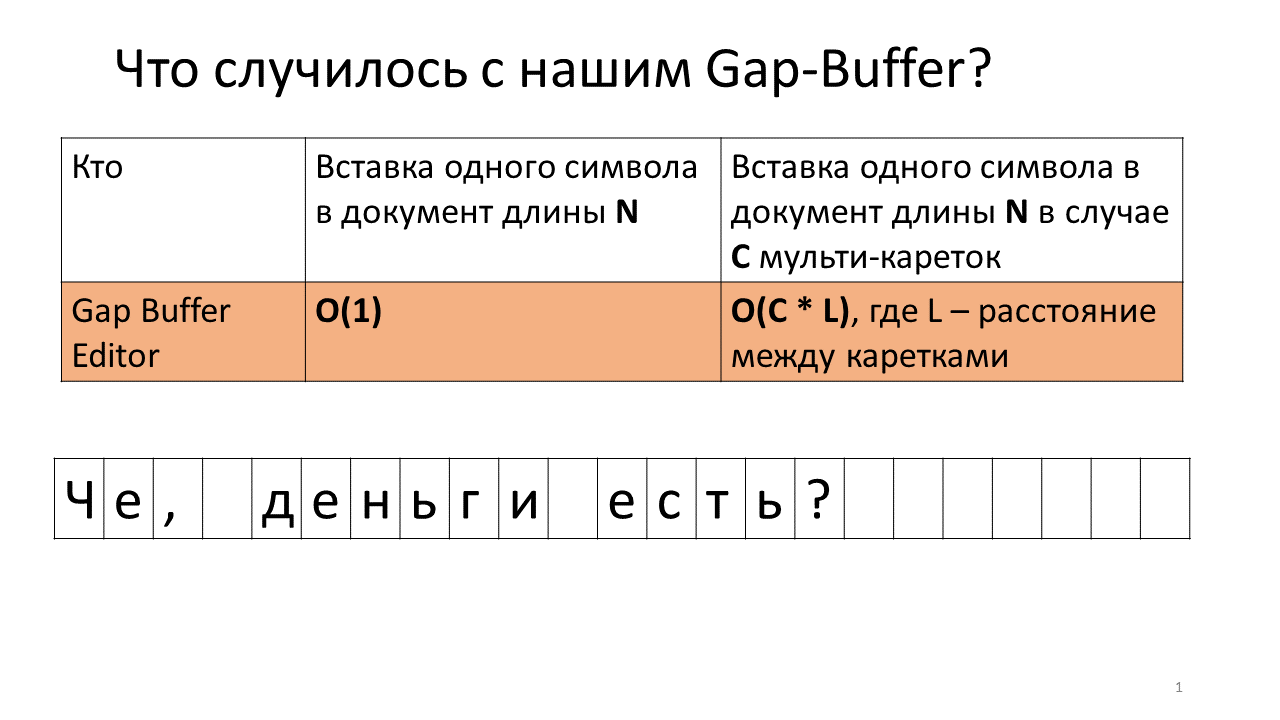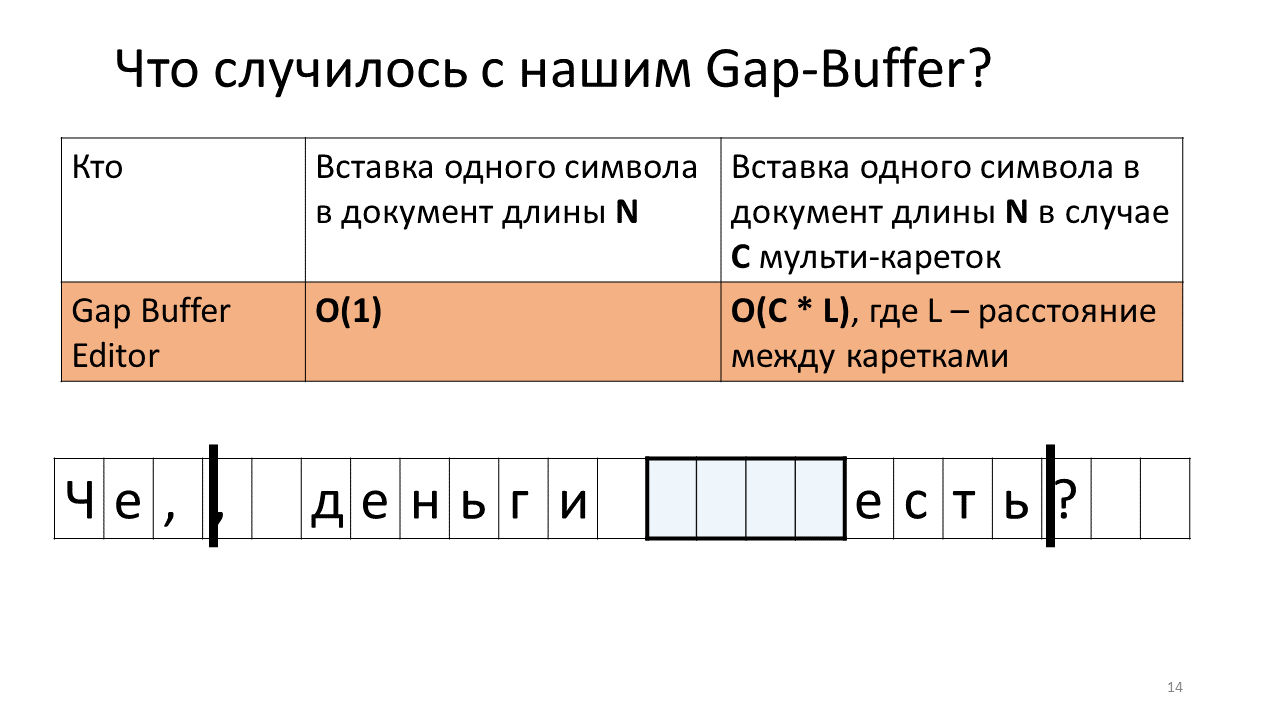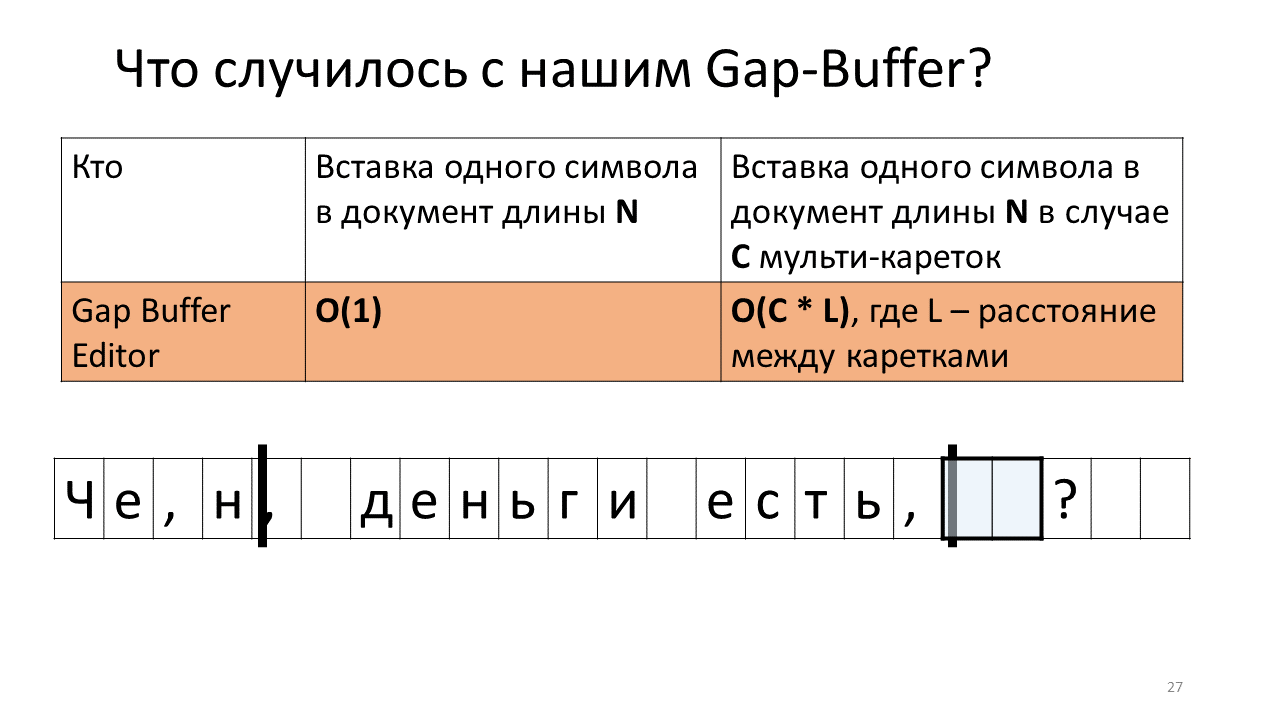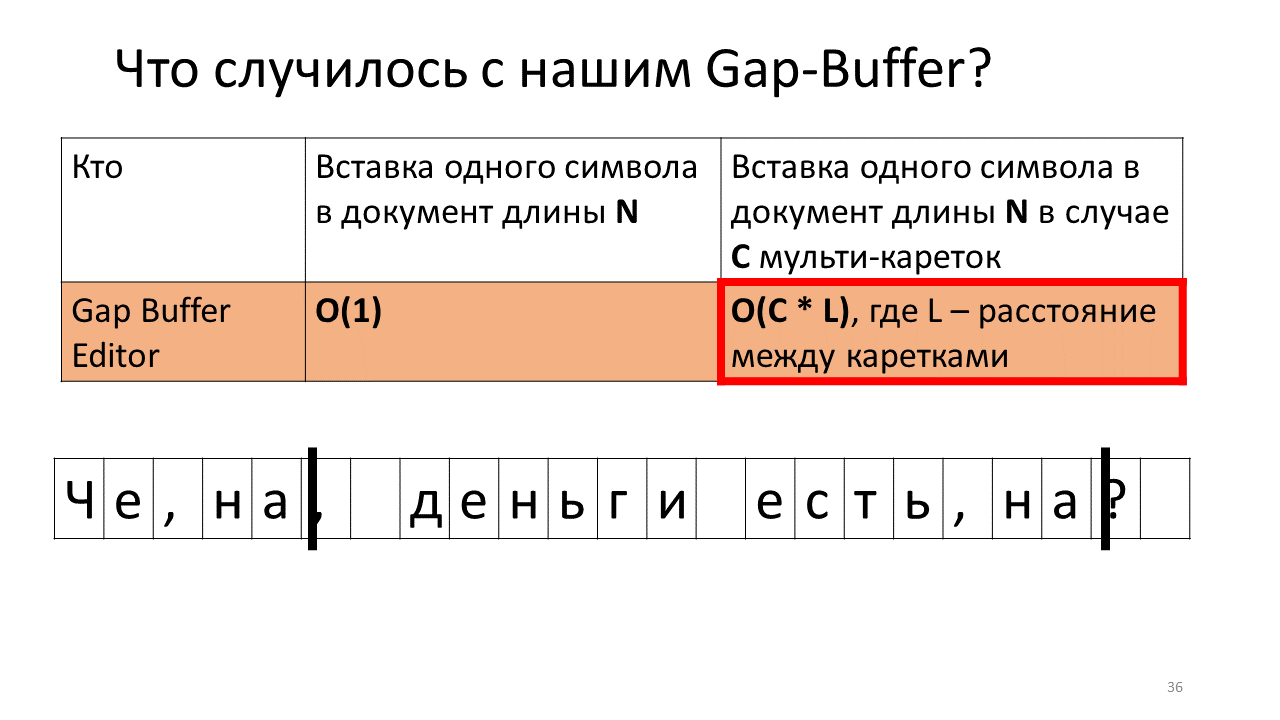
C'est ce qui se passe dans l'éditeur en ce moment.
- Créez un tampon d'espace dans l'éditeur (un petit rectangle bleu dans l'image);
- Nous commençons deux voitures (lignes verticales noires en gras);
- Nous essayons d'imprimer;
- Insérez une virgule dans notre tampon d'espace;
- Vous devez maintenant l'insérer à la place du deuxième chariot;
- Pour ce faire, nous devons déplacer notre tampon d'espace à la position du chariot suivant;
- Imprime une virgule à la deuxième place;
- Vous devez maintenant insérer le caractère suivant à la position du premier chariot;
- Et nous devons repousser notre Gap Buffer;
- Insérez la lettre "n";
- Et nous déplaçons notre tampon de longue souffrance à la place de la deuxième voiture;
- Nous y insérons notre "n";
- Reculez le tampon pour insérer le caractère suivant.
Sentez-vous où tout va?
Oui, il s'avère qu'en raison de ces nombreux mouvements de va-et-vient du tampon, notre temps total augmente. Honnêtement, ce n'est pas qu'il soit directement horrifié car il a augmenté - déplacer des mégaoctets pathétiques, des gigaoctets d'avant en arrière pour un ordinateur moderne n'est pas un problème, mais il est intéressant de noter que cette structure de données fonctionne radicalement différemment dans le cas des multicats.
Trop de lignes? LineSet!
Quels sont les autres problèmes dans un éditeur de texte classique? Le problème le plus difficile est le défilement, c'est-à-dire le redessin de l'éditeur tout en déplaçant le chariot sur la ligne suivante.

Lorsque l'éditeur défile, nous devons comprendre à partir de quelle ligne, à partir de quel symbole nous devons commencer à dessiner le texte dans notre petite fenêtre. Pour ce faire, nous devons comprendre rapidement quelle ligne correspond à quel décalage.
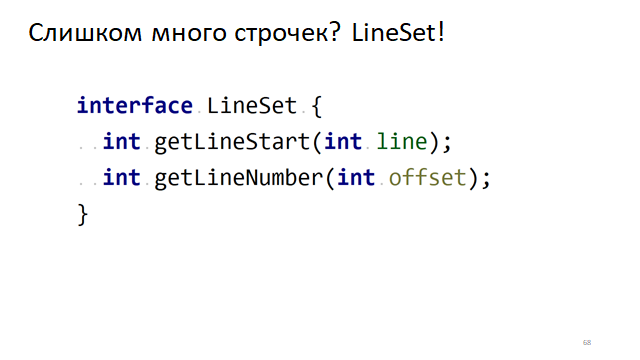
Il existe une interface évidente pour cela, lorsque nous devons comprendre son décalage dans le texte par numéro de ligne. Et vice versa, par le décalage dans le texte pour comprendre dans quelle ligne il se trouve. Comment cela peut-il se faire rapidement?
Par exemple, comme ceci:
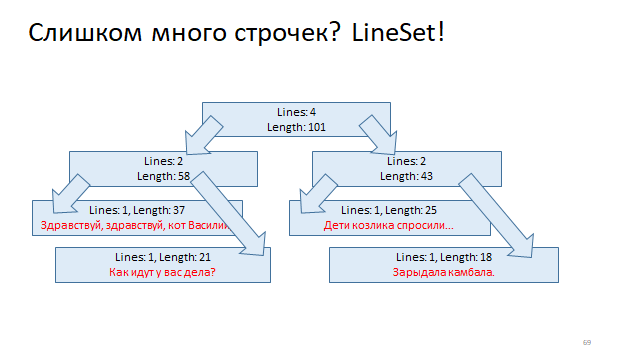
Organisez ces lignes en un arbre et marquez chaque sommet de cet arbre en décalant le début de la ligne et en décalant la fin de la ligne. Et puis, afin de comprendre par le décalage dans quelle ligne il se trouve, il vous suffit d'exécuter une recherche logarithmique dans cet arbre et de le trouver.
Une autre façon est encore plus simple.
Écrivez dans le tableau le décalage du début des lignes et de la fin des lignes. Et puis, pour trouver le décalage du début et de la fin par le numéro de ligne, vous devrez accéder à l'index.
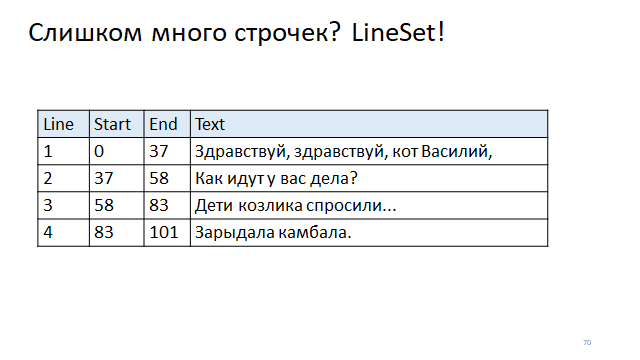
Fait intéressant, dans le monde réel, les deux méthodes sont utilisées.

Par exemple, Eclipse utilise une telle structure en bois qui, comme vous pouvez le voir, fonctionne dans un temps logarithmique pour la lecture et la mise à jour. Et IDEA utilise une structure de table, pour laquelle la lecture est une constante rapide, c'est une inversion d'index dans une table, mais la reconstruction est plutôt lente, car vous devez reconstruire la table entière lorsque vous modifiez la longueur d'une ligne.
Encore trop de lignes? Des plis!
Quoi d'autre est mauvais qui tombe sur les éditeurs de texte? Par exemple, des pliages. Ce sont des morceaux de texte que vous pouvez «réduire» et montrer à la place.

Ces points sur un fond vert dans l'image cachent beaucoup de symboles derrière nous, mais si nous ne sommes pas intéressés à les regarder (comme dans le cas, par exemple, des documents Java ou des listes d'importation les plus longs et ennuyeux), nous les masquons, les réduisons ellipses.
Et là encore, vous devez comprendre quand elle se termine et quand la région que nous devons montrer commence, et comment la mettre à jour rapidement? Comment cela est organisé, je le dirai un peu plus tard.
Trop longues lignes? Enveloppement doux!

De plus, les éditeurs modernes ne peuvent pas vivre sans enveloppe souple. L'image montre que le développeur a ouvert le fichier JavaScript après la minimisation et l'a immédiatement regretté. Cette énorme ligne JavaScript, lorsque nous essayons de l'afficher dans l'éditeur, ne rentrera dans aucun écran. Par conséquent, un emballage doux le déchire de force en plusieurs lignes et le pousse dans l'écran.
Comment c'est organisé - plus tard.
Trop peu de beauté

Et enfin, je veux aussi apporter de la beauté aux éditeurs de texte. Par exemple, mettez en surbrillance certains mots. Dans l'image ci-dessus, les mots clés sont mis en évidence en bleu gras, certaines méthodes statiques en italique, certaines annotations - également dans une couleur différente.
Alors, comment conservez-vous et traitez-vous encore les pliages, les emballages souples et les surlignages?
Il s'avère que tout cela, en principe, est une seule et même tâche.
Trop peu de beauté? Surligneurs de gamme!

Pour prendre en charge toutes ces fonctionnalités, tout ce que nous devons être en mesure de faire est de coller certains attributs de texte à un décalage donné dans le texte, par exemple, la couleur, la police ou le texte à plier. De plus, ces attributs de texte doivent être mis à jour tout le temps à cet endroit afin qu'ils survivent à toutes sortes d'insertions et de suppressions.
Comment cela est-il généralement mis en œuvre? Naturellement, sous la forme d'un arbre.
Problème: trop de beauté? Arbre d'intervalle!

Par exemple, nous avons ici plusieurs reflets jaunes que nous voulons conserver dans le texte. Nous ajoutons les intervalles de ces faits saillants dans un arbre de recherche, le soi-disant arbre d'intervalle. Il s'agit du même arbre de recherche, mais un peu plus délicat car nous devons stocker des intervalles plutôt que des nombres.
Et comme il y a des intervalles sains et petits, comment les trier, les comparer les uns aux autres et les mettre dans un arbre est une tâche plutôt simple. Bien que très connu en informatique. Ensuite, regardez à votre guise comment cela fonctionne. Donc, nous prenons et mettons tous nos intervalles dans un arbre, puis chaque changement de texte quelque part au milieu conduit à un changement logarithmique dans cet arbre. Par exemple, l'insertion d'un caractère devrait entraîner la mise à jour de tous les intervalles à droite de ce caractère. Pour ce faire, nous trouvons tous les sommets dominants de ce symbole et indiquons que tous leurs sommets doivent être déplacés d'un symbole vers la droite.
Toujours envie de beauté? Ligatures!

Il y a encore une chose si terrible - les ligatures, que je voudrais également soutenir. Ce sont des beautés différentes, comme le signe «! =» Est dessiné sous la forme d'un grand glyphe «pas égal» et ainsi de suite. Heureusement, nous comptons ici sur un mécanisme de swing pour supporter ces ligatures. Et, selon notre expérience, il travaille apparemment de la manière la plus simple. À l'intérieur de la police, une liste de toutes ces paires de caractères est stockée, qui, lorsqu'elles sont combinées ensemble, forment une sorte de ligature délicate. Ensuite, lors du tracé de la ligne, Swing itère simplement sur toutes ces paires, trouve celles nécessaires et les dessine en conséquence. Si vous avez beaucoup de ligatures dans la police, alors, apparemment, son affichage ralentira proportionnellement.
Basculement des freins
Et le plus important - un autre problème rencontré dans les éditeurs complexes modernes est l'optimisation du basculement, c'est-à-dire l'appui sur les touches et l'affichage du résultat.

Si vous entrez dans Intellij IDEA et voyez ce qui se passe lorsque vous appuyez sur un bouton, il se trouve que l'horreur suivante se produit:
- En cliquant sur un bouton, nous devons voir si nous sommes dans la fenêtre de complétion pour fermer le menu de fin si, par exemple, nous tapons du "Enter".
- Vous devez voir si le fichier est sous un système de contrôle de version délicat, comme Perforce, qui doit prendre des mesures pour commencer la modification.
- Vérifiez s'il y a une région spéciale dans le document qui ne peut pas être imprimée, comme certains textes générés automatiquement.
- Si le document est bloqué par une opération qui n'est pas terminée, vous devez terminer la mise en forme et continuer ensuite.
- injected-, , , - .
- auto popup handler, , , .
- info , , . selection remove, selection , . selection , .
- typed handler, , .
- .
- undo, virtual space' write action.
- , .
Hourra!
, , . , . , listener , , - . editor view. - listener'.
, , - DocumentListener?
Editor.documentChanged() :
- error stripe;
- gutter size, ;
- editor component size, ;
- ;
- soft wrap, ;
- repaint().
repaint() — Swing, . , Repaint Swing.
- , repaint , :

paint-, , .
, , ?

, , . Intellij IDEA .

, - - , , , . ! , , , - — ! , - . . «Zero latency typing».
— .
? , — , Google Docs - - .
:
, , .
- . , , . . — , «intention preservation». , - , , , . — . , - , .
Operation transformation
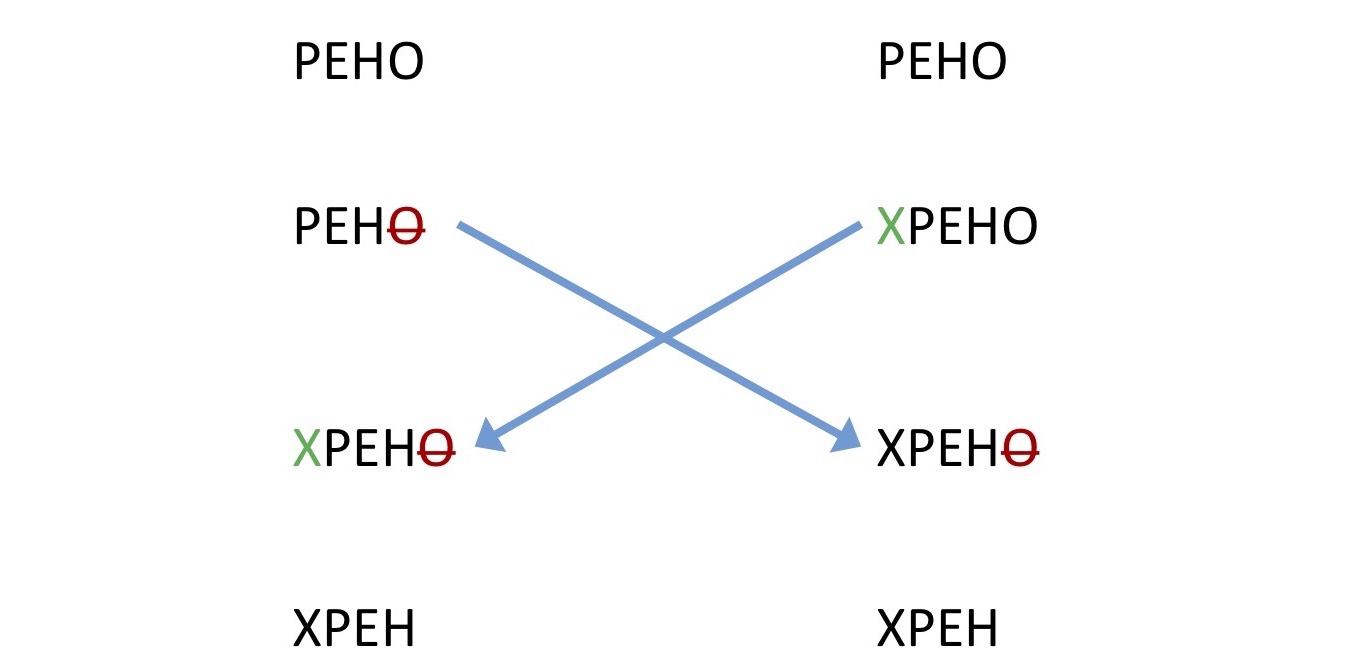
, , «operation transformation». . , - : , . Operation transformation . , , , - . , . , - . , , .
, , , . «TP2 puzzle».
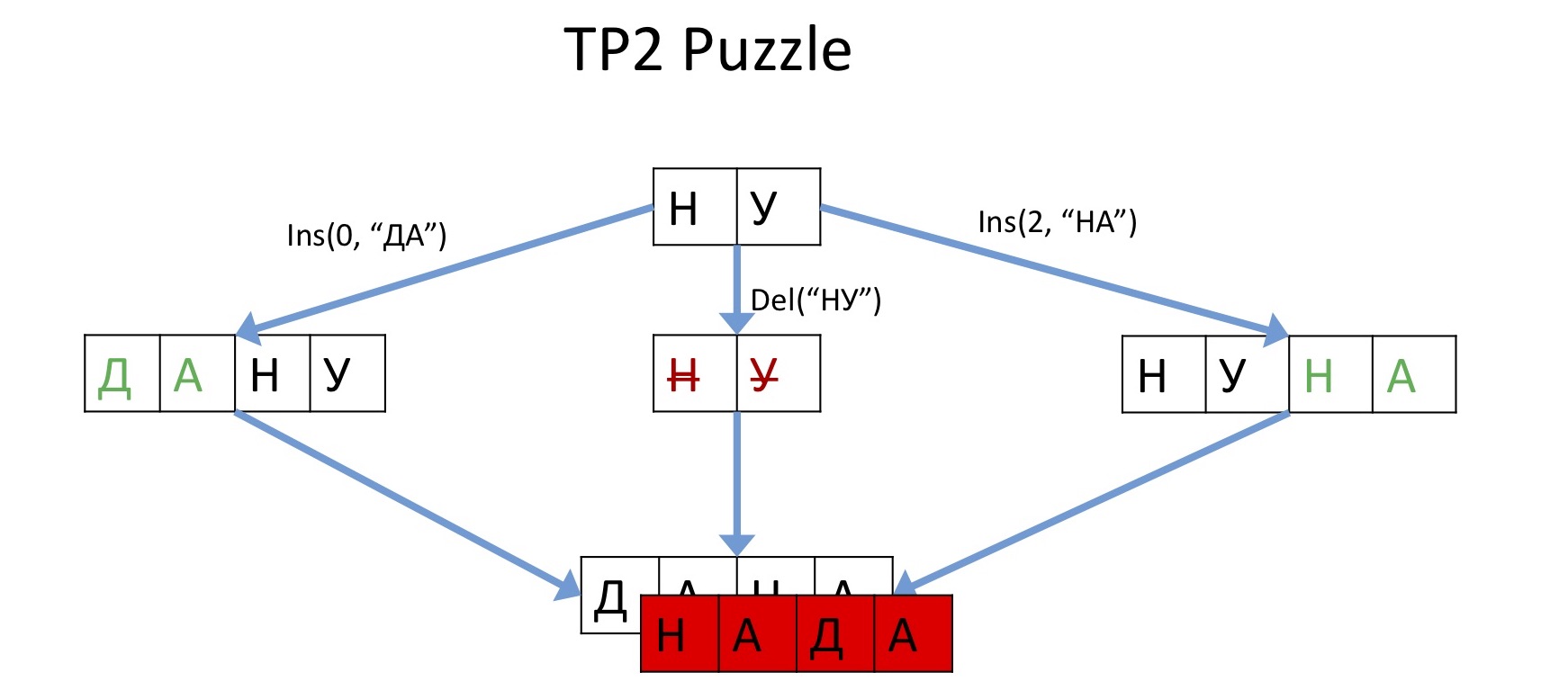
- , , . , Operation transformation , , , («»). («»). , . , Operation transformation, - .
, Google Docs, Google Wave - Etherpad. Operation transformation .
Conflict-free replicated data type
: « , OT!» , , . , , , , 100% . «CRDT» (Conflict-free replicated data type).

, , . , , , . , . - ( ), () ( ).

?
Oui , G-counter', , . , . «+1» , «+1» , , — «2». , , . G-counter, , . G-counter, . , , . . — . , CRDT. , .
Conflict-free replicated inserts
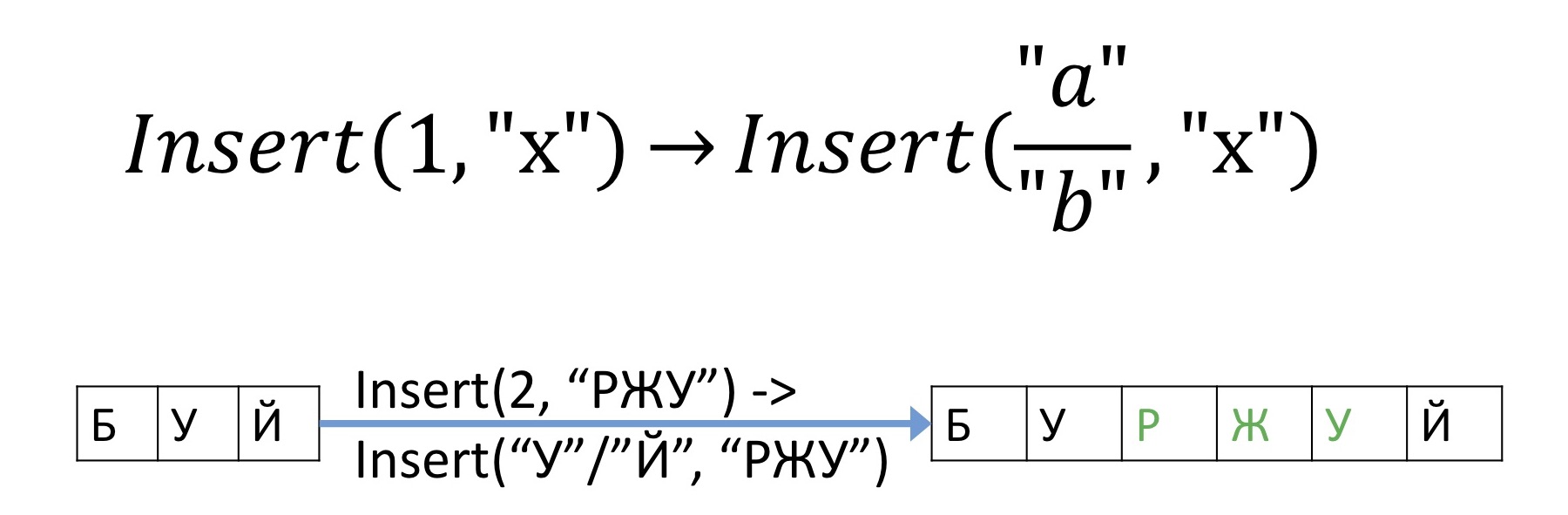
, , , . , , .
, , - - , , , , . , , , , . , , , , 2 «», , «» «» «».
Conflict-free replicated deletes
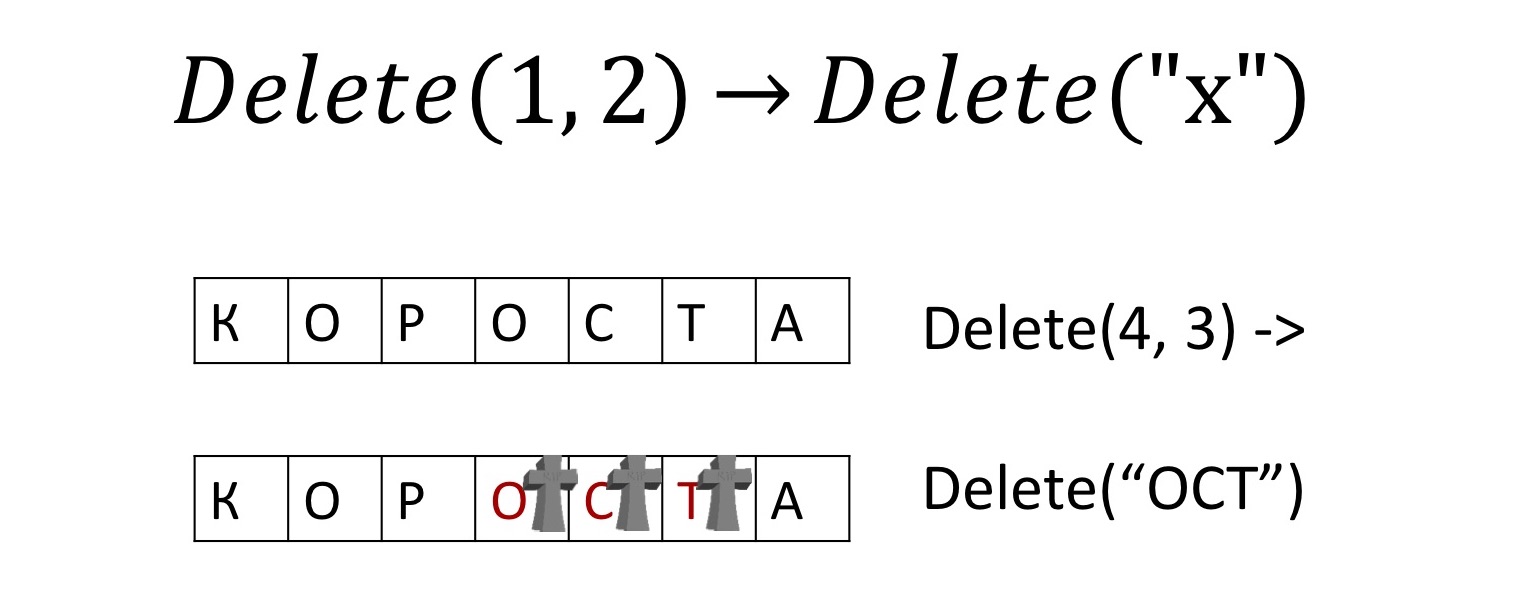
. , , , - . , , . , , , .
, .
Conflict-free replicated edits
, , CRDT - , , Xi-Editor, Fuchsia. , , .
Fermeture éclair
, «Zipper». , , . , , . , ( «» , , « »). , - . , - , . Zipper.
, . .
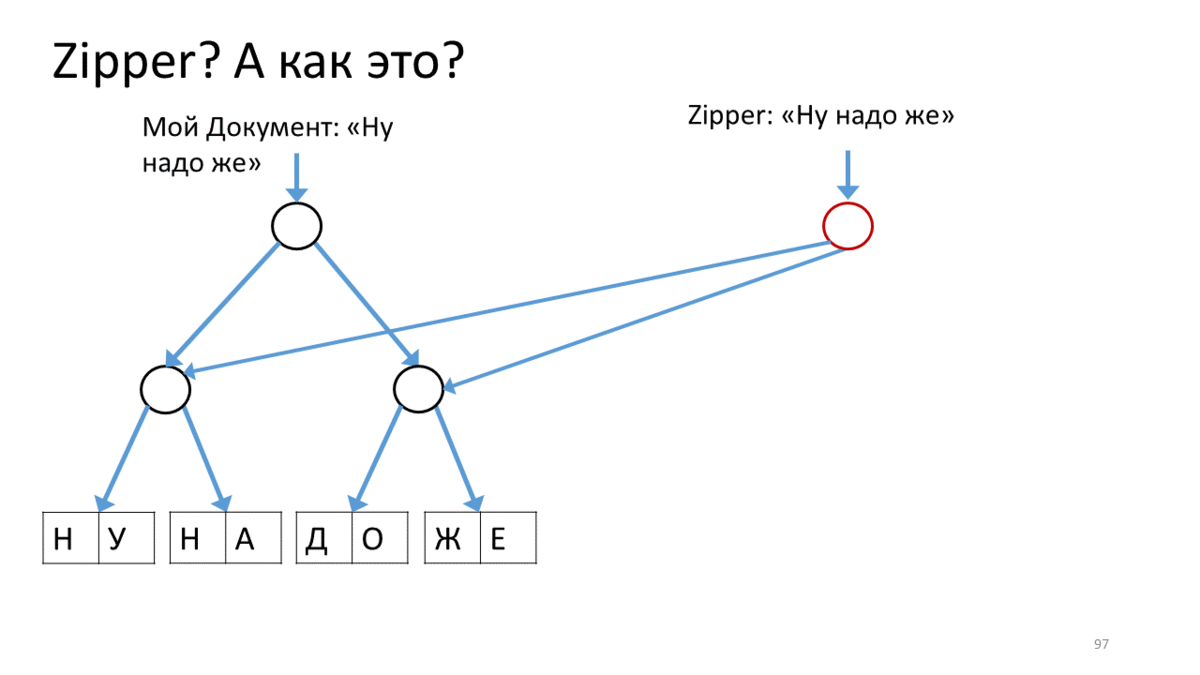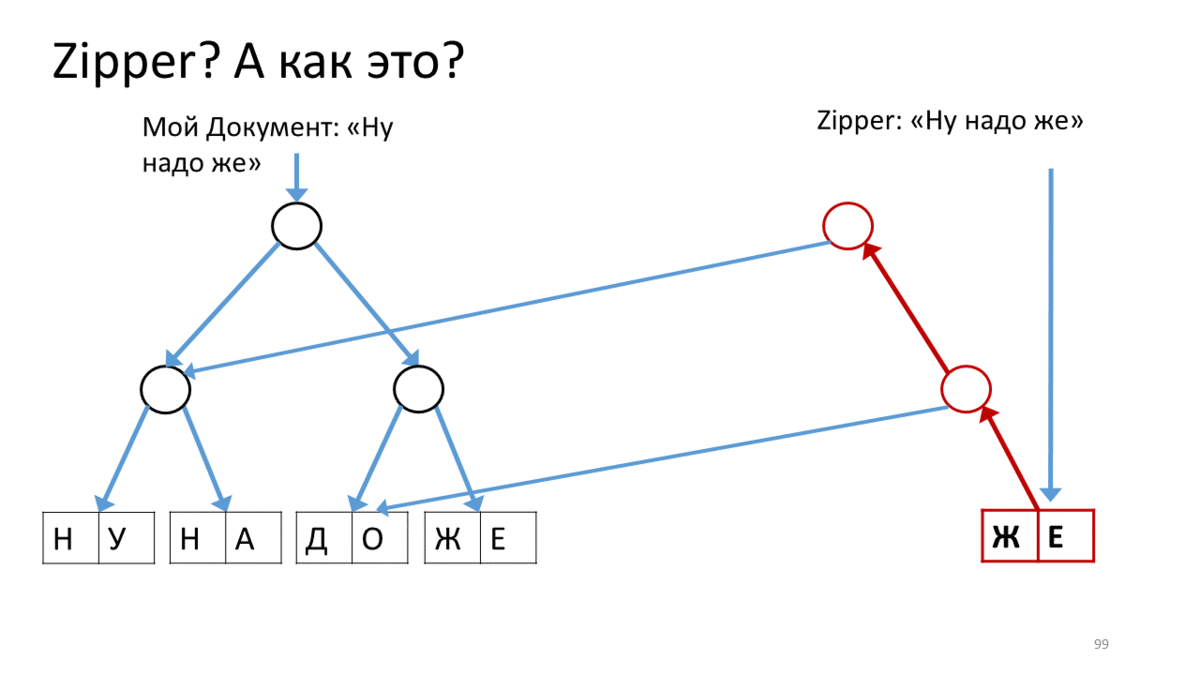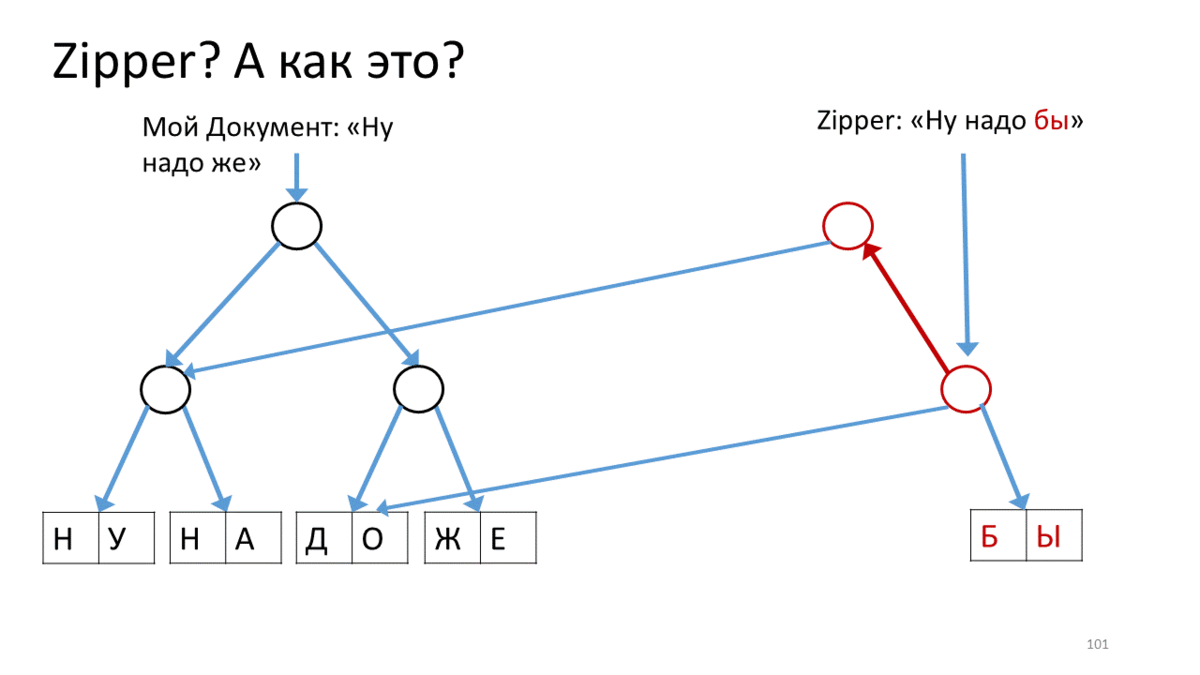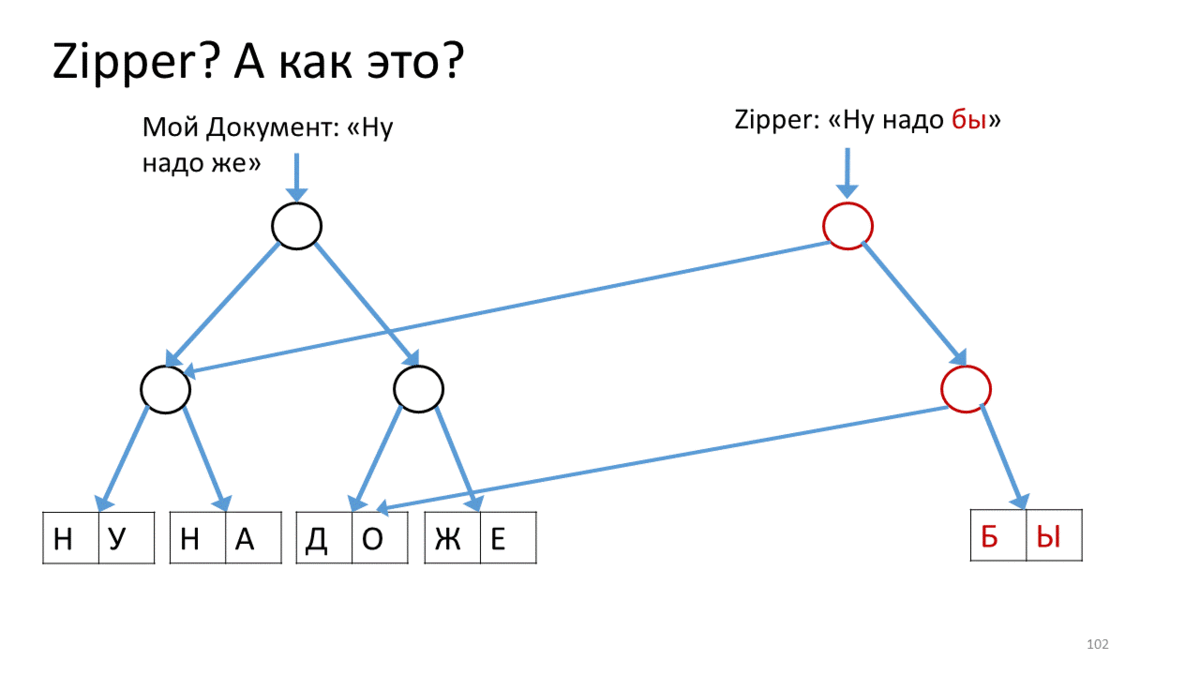
Zipper , (« »). Zipper' . — . (), , . , Zipper, - , . , , , ( ). , ( ). , . , .
, .
? -, , , , . , , . -, , . . Je vous remercie
→
→
Les références
Zipper data structureCRDT in Xi Editor,
Visual Studio Code editor Piece Table .
, -
.
Vous voulez des rapports encore plus puissants, y compris Java 11? Ensuite, nous vous attendons au Joker 2018 . Intervenants cette année: Josh Long, John McClean, Marcus Hirth, Robert Scholte et d'autres intervenants tout aussi cool. Il reste 17 jours avant la conférence. Billets sur le site.