Le 22 septembre, nous avons organisé notre premier mitap non standard pour les développeurs de systèmes très chargés. C'était très cool, beaucoup de retours positifs sur les rapports et a donc décidé non seulement de les télécharger, mais aussi de les décrypter pour Habr. Aujourd'hui, nous publions un discours d'Ivan Bubnov, DevOps de BIT.GAMES. Il a parlé de la mise en œuvre du service de découverte Consul dans un projet à forte charge déjà en cours pour la possibilité de mise à l'échelle rapide et de basculement de services avec état. Et aussi sur l'organisation d'un espace de noms flexible pour les applications backend et les pièges. Maintenant un mot à Ivan.J'administre l'infrastructure de production du studio BIT.GAMES et raconte l'histoire de l'introduction du consul de Hashicorp dans notre projet "Guild of Heroes" - RPG fantastique avec pvp asynchrone pour appareils mobiles. Disponible sur Google Play, App Store, Samsung, Amazon. DAU environ 100 000, en ligne de 10 à 13 mille. Nous créons le jeu dans Unity, nous écrivons donc le client en C # et utilisons notre propre langage de script BHL pour la logique du jeu. Nous écrivons la partie serveur dans Golang (qui y est passée de PHP). Vient ensuite l'architecture schématique de notre projet.
 En fait, il y a beaucoup plus de services, il n'y a que les bases de la logique du jeu.
En fait, il y a beaucoup plus de services, il n'y a que les bases de la logique du jeu.Alors ce que nous avons. Parmi les services apatrides, ce sont:
- nginx, que nous utilisons comme Frontend et Load Balancers et distribuons les clients à nos backends par coefficients de pondération;
- gamed - backends, applications compilées de Go. C'est l'axe central de notre architecture, ils effectuent la part du lion du travail et communiquent avec tous les autres services backend.
Parmi les services Stateful, les principaux que nous avons sont:
- Redis, que nous utilisons pour mettre en cache les informations chaudes (nous l'utilisons également pour organiser le chat en jeu et stocker les notifications pour nos joueurs);
- Percona Server for Mysql est un référentiel d'informations persistantes (probablement le plus grand et le plus lent de toute architecture). Nous utilisons le fork de MySQL et nous en parlerons plus en détail aujourd'hui.
Au cours du processus de conception, nous (comme tout le monde) espérions que le projet serait couronné de succès et prévoyions un mécanisme de partage. Il se compose de deux entités de base de données MAINDB et des fragments eux-mêmes.

MAINDB est une sorte de table des matières - il stocke des informations sur quelles données de tesson particulières sur la progression du joueur sont stockées. Ainsi, la chaîne complète de récupération d'informations ressemble à ceci: le client accède au frontend, qui à son tour le redistribue en poids à l'un des backends, le backend va à MAINDB, localise le fragment du lecteur, puis sélectionne les données directement à partir du fragment lui-même.
Mais quand nous avons conçu, nous n'étions pas un gros projet, nous avons donc décidé de faire des tessons des tessons uniquement nominalement. Ils étaient tous situés sur le même serveur physique et très probablement sur un partitionnement de base de données au sein du même serveur.
Pour la sauvegarde, nous avons utilisé la réplication maître-esclave classique. Ce n'était pas une très bonne solution (je dirai pourquoi un peu plus tard), mais le principal inconvénient de cette architecture était que tous nos backends connaissaient les autres services backend exclusivement par des adresses IP. Et en cas d'un autre accident ridicule dans le centre de données du type "
désolé, notre ingénieur a touché le câble sur votre serveur pendant qu'il en réparait un autre et nous avons mis très longtemps à comprendre pourquoi votre serveur ne nous contactait pas ", des mouvements considérables étaient nécessaires de notre part. Tout d'abord, il s'agit de la reconstruction et de la pré-installation de backends à partir du serveur de sauvegarde IP pour l'emplacement de celui qui a échoué. Deuxièmement, après l'incident, il est nécessaire de restaurer notre maître à partir de la sauvegarde de la réserve, car il était dans un état incohérent et de le mettre dans un état coordonné en utilisant la même réplication. Ensuite, nous avons à nouveau remonté les backends et rechargé. Tout cela, bien sûr, a provoqué des temps d'arrêt.
Il y a eu un moment où notre directeur technique (dont je le remercie beaucoup) a dit: "Les gars, arrêtez de souffrir, nous devons changer quelque chose, cherchons des solutions." Tout d'abord, nous voulions parvenir à un processus simple, compréhensible et surtout - facilement géré de mise à l'échelle et de migration d'un endroit à l'autre de nos bases de données si nécessaire. De plus, nous voulions atteindre une haute disponibilité en automatisant les basculements.
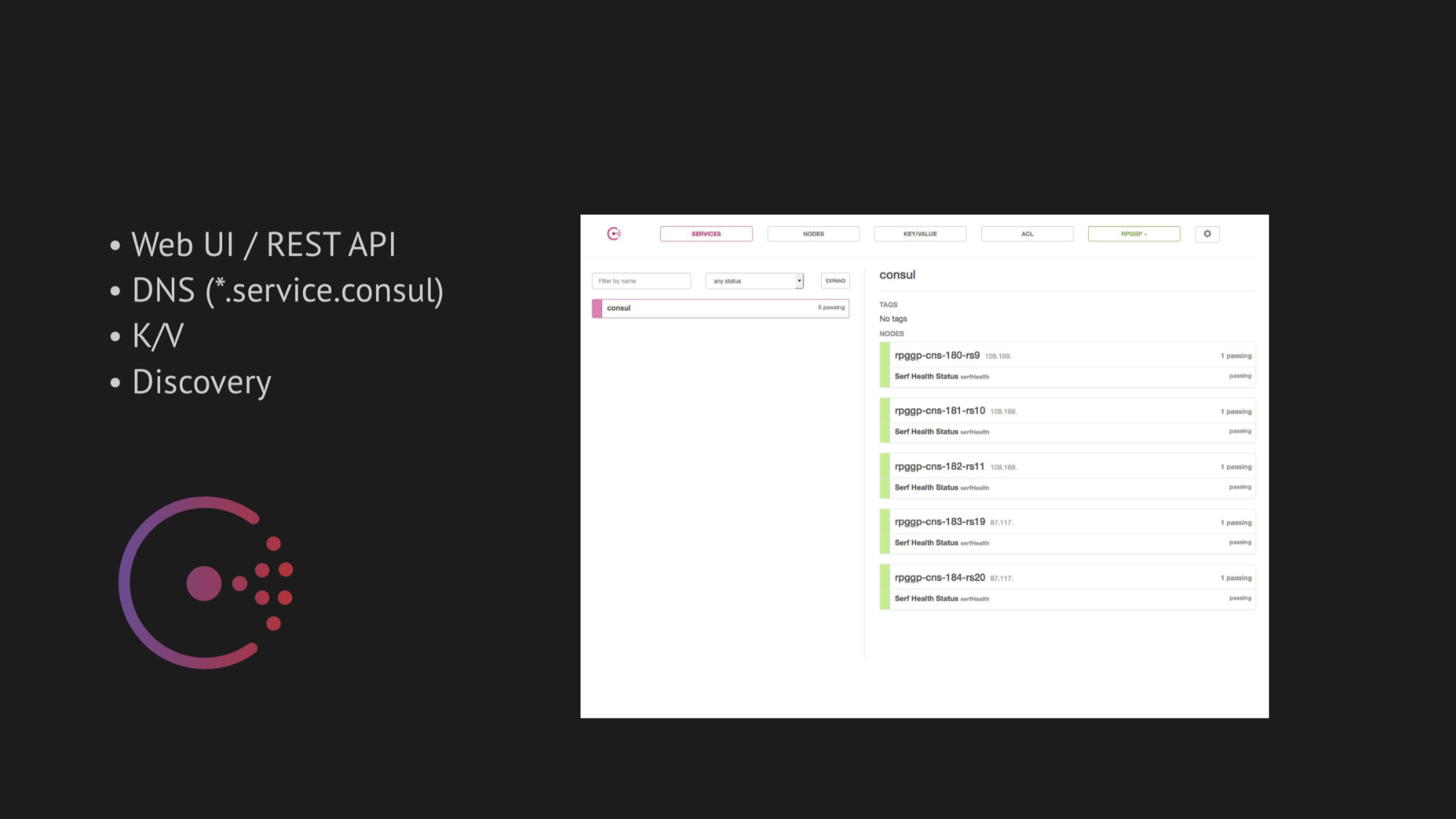
L'axe central de notre recherche est devenu Consul de Hashicorp. Premièrement, nous avons été informés, et deuxièmement, nous avons été très attirés par sa simplicité, sa convivialité et son excellente pile technologique dans une seule boîte: service de découverte avec contrôle de santé, stockage de valeur-clé et la chose la plus importante que nous voulions utiliser était DNS qui nous résout les adresses du domaine service.consul.
Consul fournit également d'excellentes interfaces utilisateur Web et API REST pour gérer tout cela.
Quant à la haute disponibilité, nous avons choisi deux utilitaires pour le basculement automatique:
- MHA pour MySQL
- Redis-sentinel

Dans le cas de MHA pour MySQL, nous avons versé des agents dans des nœuds avec des bases de données et ceux-ci ont surveillé leur état. Il y a eu un certain délai avec l'échec du maître, après quoi un esclave d'arrêt a été créé pour maintenir la cohérence et notre maître de sauvegarde du maître apparu dans un état incohérent n'a pas récupéré les données. Et nous avons ajouté un hook Web à ces agents, qui y ont enregistré la nouvelle IP du maître de sauvegarde dans Consul lui-même, après quoi il est entré dans la délivrance du DNS.
Avec Redis-sentinel, tout est encore plus simple. Puisqu'il réalise lui-même la part du lion du travail, il ne nous restait plus qu'à prendre en compte dans le bilan de santé que Redis-sentinel devait se dérouler exclusivement sur le nœud maître.
Au début, tout fonctionnait parfaitement, comme une horloge. Nous n'avons eu aucun problème au banc d'essai. Mais cela valait la peine de pénétrer dans l'environnement naturel du transfert de données d'un centre de données chargé, en pensant à certains OOM-kills (c'est hors de la mémoire, dans lequel le processus est tué par le noyau du système) et en restaurant le service ou des choses plus sophistiquées qui affectent la disponibilité du service - comment avons-nous immédiatement obtenu un risque sérieux de faux positifs ou aucune réponse garantie du tout (si vous essayez de tordre certains contrôles pour tenter d'échapper aux faux positifs).

Tout d'abord, tout dépend de la difficulté à rédiger le bon bilan de santé. Il semble que la tâche soit assez banale - vérifiez que le service fonctionne sur votre serveur et le port pingani. Mais, comme l'a montré la pratique ultérieure, la rédaction d'un bilan de santé lors de la mise en œuvre de Consul est un processus extrêmement complexe et long. Parce que tant de facteurs qui affectent la disponibilité de votre service dans le centre de données ne peuvent pas être prévus - ils ne sont détectés qu'après un certain temps.
En outre, le centre de données n'est pas une structure statique qui vous submerge et il fonctionne comme prévu. Mais nous, malheureusement (ou heureusement), ne l'avons découvert que plus tard, mais pour l'instant nous étions inspirés et confiants de pouvoir tout mettre en œuvre en production.

En ce qui concerne la mise à l'échelle, je dirai brièvement: nous avons essayé de trouver un vélo fini, mais ils sont tous conçus pour des architectures spécifiques. Et, comme dans le cas de Jetpants, nous n'avons pas pu remplir les conditions qu'il imposait à l'architecture d'un stockage persistant des informations.
Par conséquent, nous avons pensé à notre propre liaison de script et reporté cette question. Nous avons décidé d'agir de manière cohérente et de commencer par la mise en place du Consul.

Consul est un cluster décentralisé et distribué qui fonctionne sur la base du protocole Gossip et de l'algorithme de consensus Raft.
Nous avons un equorum indépendant de cinq serveurs (cinq pour éviter la situation de split-brain). Pour chaque nœud, nous renversons l'agent Consul en mode agent et renversons tous les contrôles de santé (c'est-à-dire qu'il n'y en avait pas de tels que nous téléchargions un contrôle de santé sur un serveur spécifique et d'autres sur des serveurs spécifiques). Le bilan de santé a été rédigé de manière à ne passer que là où il y a un service.
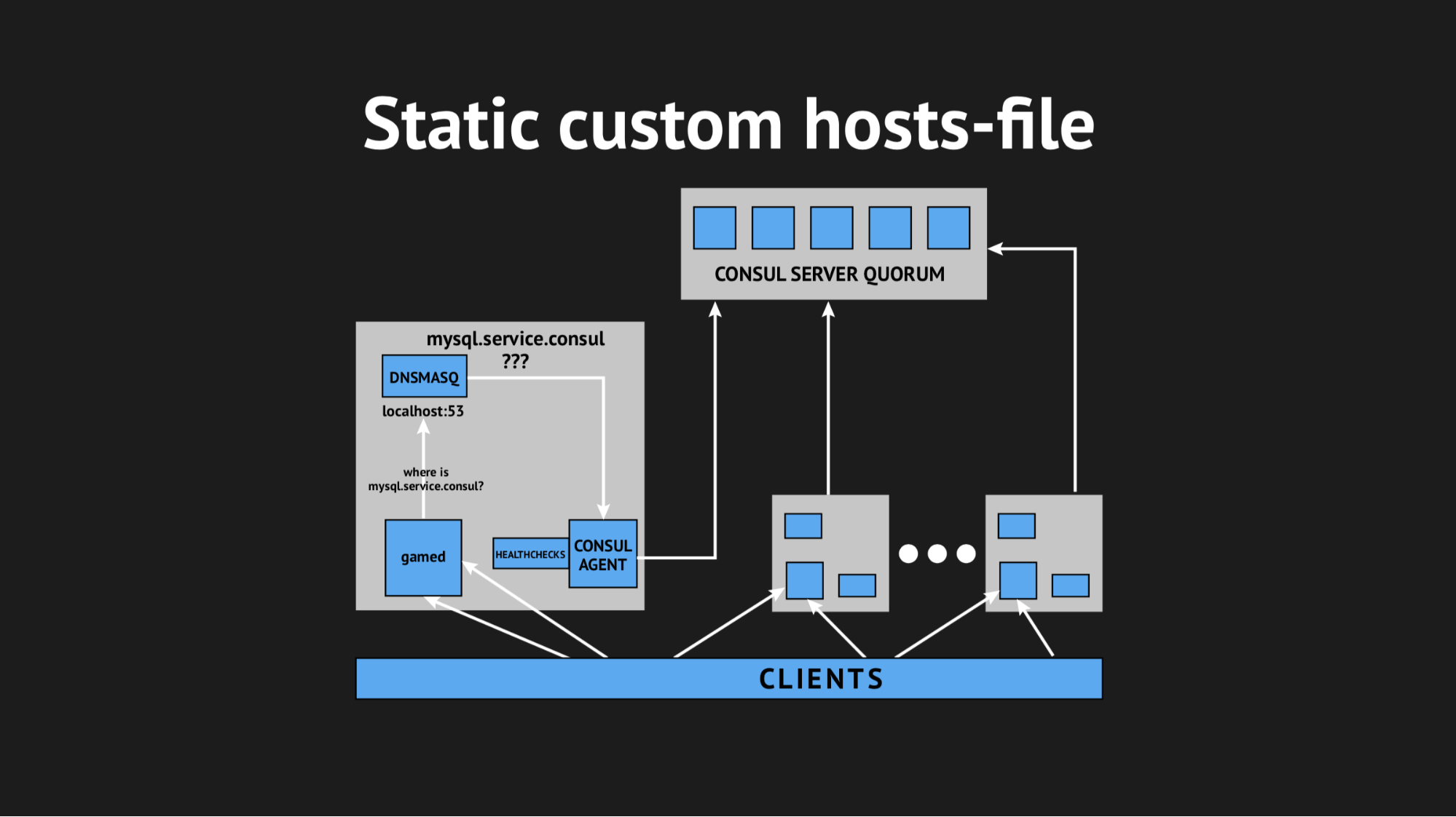
Nous avons également utilisé un autre utilitaire afin de ne pas avoir à apprendre notre backend pour résoudre les adresses d'un domaine spécifique sur un port non standard. Nous avons utilisé Dnsmasq - il offre la possibilité de résoudre de manière totalement transparente les adresses sur les nœuds de cluster dont nous avons besoin (qui, pour ainsi dire, n'existent pas, mais existent exclusivement au sein du cluster). Nous avons préparé un script automatique pour remplir Ansible, téléchargé le tout en production, optimisé l'espace de noms, vérifié que tout était terminé. Et, en croisant les doigts, nous avons rechargé nos backends, auxquels on accédait non pas par des adresses IP, mais par ces noms du domaine server.consul.
Tout a commencé la première fois, notre joie n'a pas de limites. Mais il était trop tôt pour se réjouir, car en une heure, nous avons remarqué que sur tous les nœuds où se trouvent nos backends, l'indicateur de charge moyenne est passé de 0,7 à 1,0, ce qui est un indicateur plutôt gras.
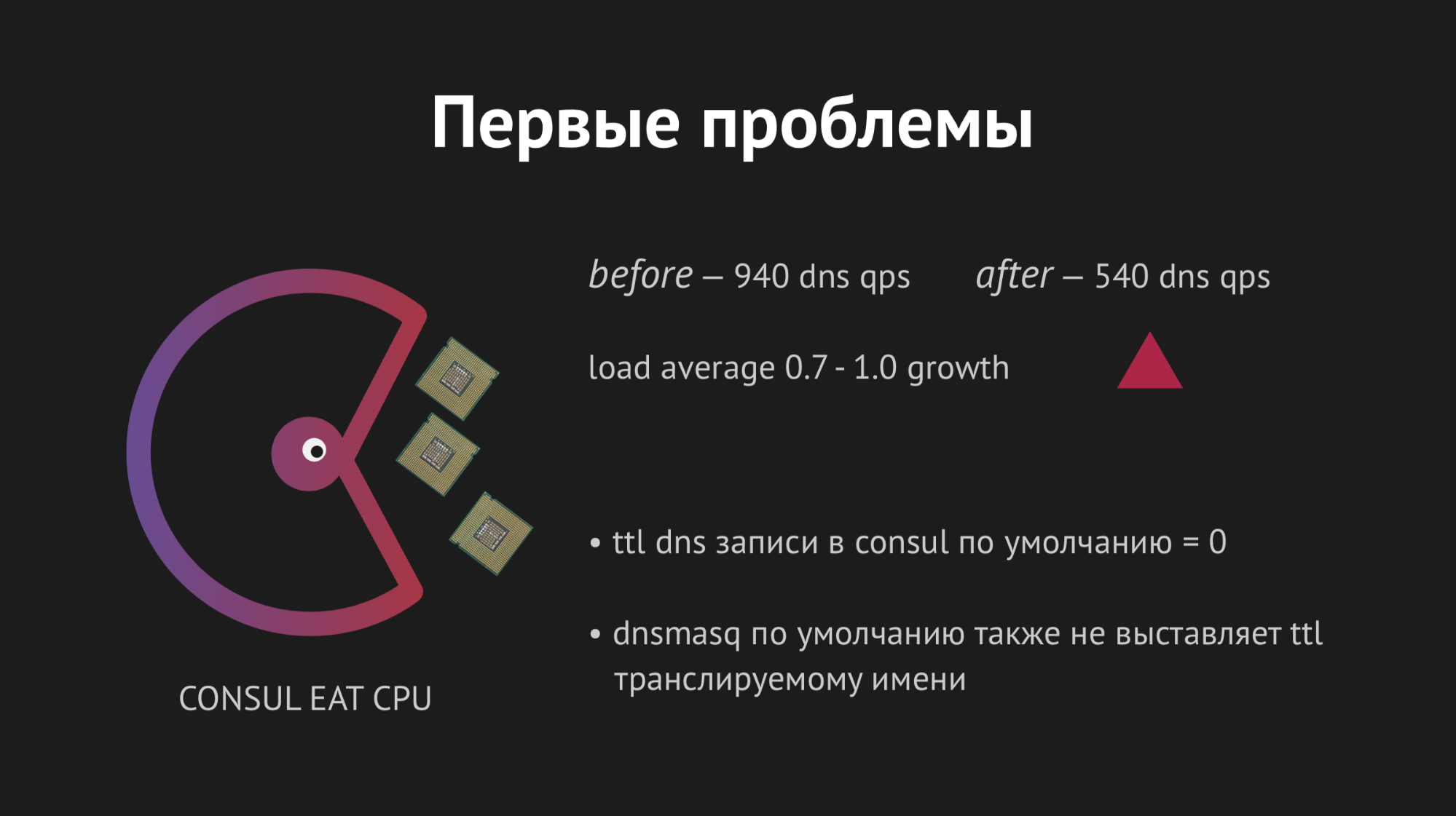
Je suis monté sur le serveur pour voir ce qui se passait et il est devenu évident que le CPU mangeait Consul. Ici, nous avons commencé à comprendre, à commencer à chamaniser avec strace (un utilitaire pour les systèmes Unix qui vous permet de suivre quel syscall le processus est en cours d'exécution), à vider les statistiques Dnsmasq pour comprendre ce qui se passe sur ce nœud, et il s'est avéré que nous avons manqué un point très important. Lors de la planification de l'intégration, nous avons manqué la mise en cache des enregistrements DNS et il s'est avéré que notre backend a tiré Dnsmasq pour chacun de ses mouvements, et que, à son tour, s'est tourné vers Consul et tout cela a entraîné 940 requêtes DNS maladives par seconde.
La sortie semblait évidente - il suffit de tordre ttl et tout ira mieux. Mais ici, il était impossible d'être fanatique, car nous voulions implémenter cette structure afin d'obtenir un espace de noms dynamique facilement contrôlé et changeant rapidement (par conséquent, nous ne pouvions pas définir, par exemple, 20 minutes). Nous avons tordu ttl aux valeurs optimales maximales pour nous, nous avons réussi à réduire le taux de requête par seconde à 540, mais cela n'a pas affecté l'indicateur de consommation du processeur.
Ensuite, nous avons décidé de sortir de manière délicate, en utilisant un fichier d'hôtes personnalisé.
C'est bien que nous ayons tout pour cela: un excellent système de modèles de Consul, qui, basé sur l'état du cluster et le script de modèle, génère un fichier de toute sorte, n'importe quelle configuration est tout ce que vous voulez. De plus, Dnsmasq possède un paramètre de configuration addn-hosts qui vous permet d'utiliser un fichier d'hôtes non système comme le même fichier d'hôtes supplémentaire.
Ce que nous avons fait, encore une fois préparé le script dans Ansible, l'a téléchargé en production et il a commencé à ressembler à ceci:
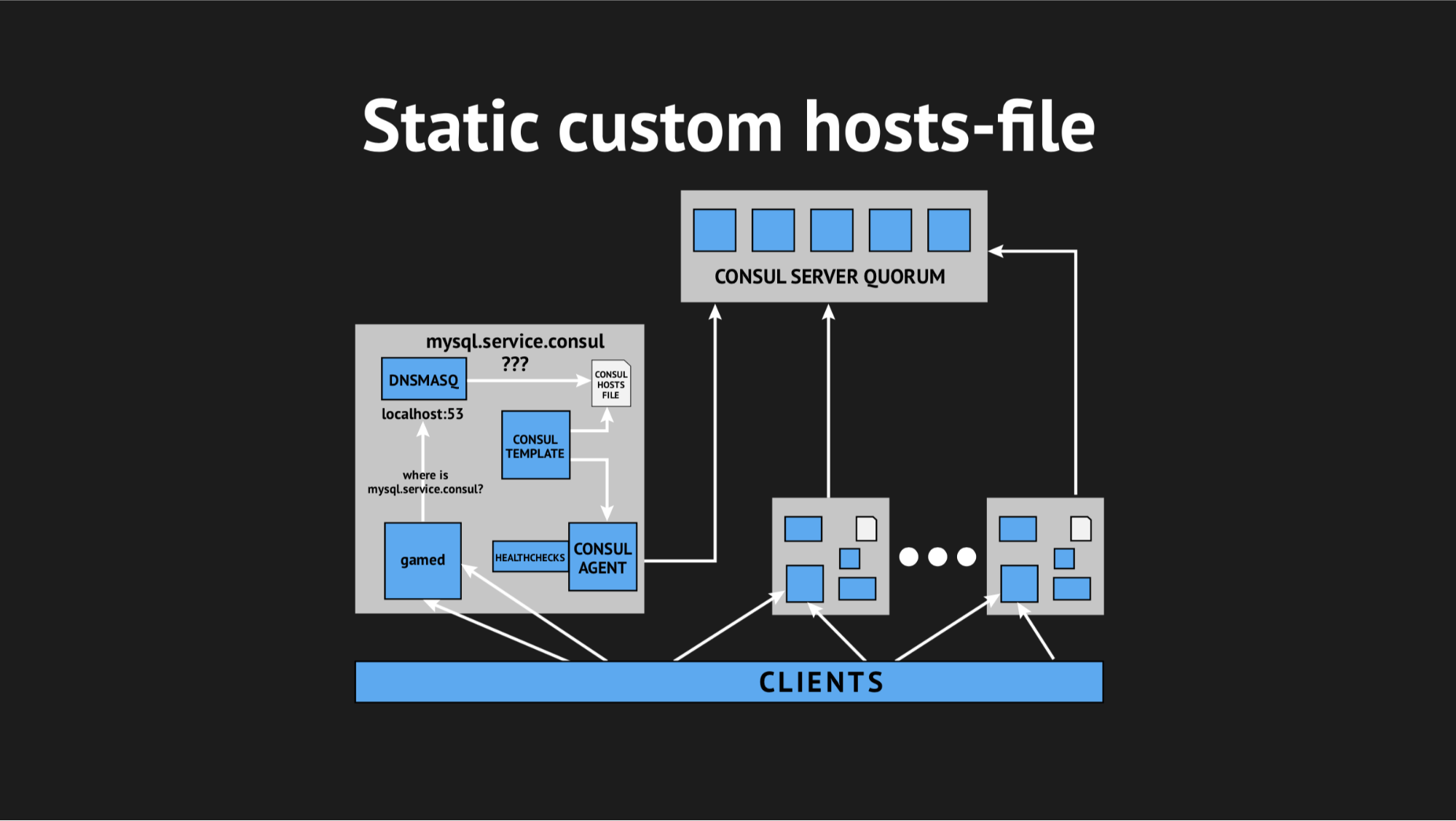
Il y avait un élément supplémentaire et un fichier statique sur le disque, qui est assez rapidement régénéré. Maintenant, la chaîne semblait assez simple: gamed s'est tourné vers Dnsmasq, et cela à son tour (au lieu de tirer sur l'agent Consula, qui demanderait aux serveurs où nous avions tel ou tel nœud) a simplement regardé le fichier. Cela a résolu le problème de consommation du processeur par Consul.
Maintenant, tout a commencé à ressembler à ce que nous avions prévu - absolument transparent pour notre production, pratiquement sans consommer de ressources.
Nous étions assez tourmentés ce jour-là et avec une grande appréhension, nous sommes rentrés chez nous. Ils n'ont pas eu peur en vain, car la nuit, une alerte de la surveillance m'a réveillé et m'a informé que nous avions une explosion d'erreurs assez importante (quoique à court terme).
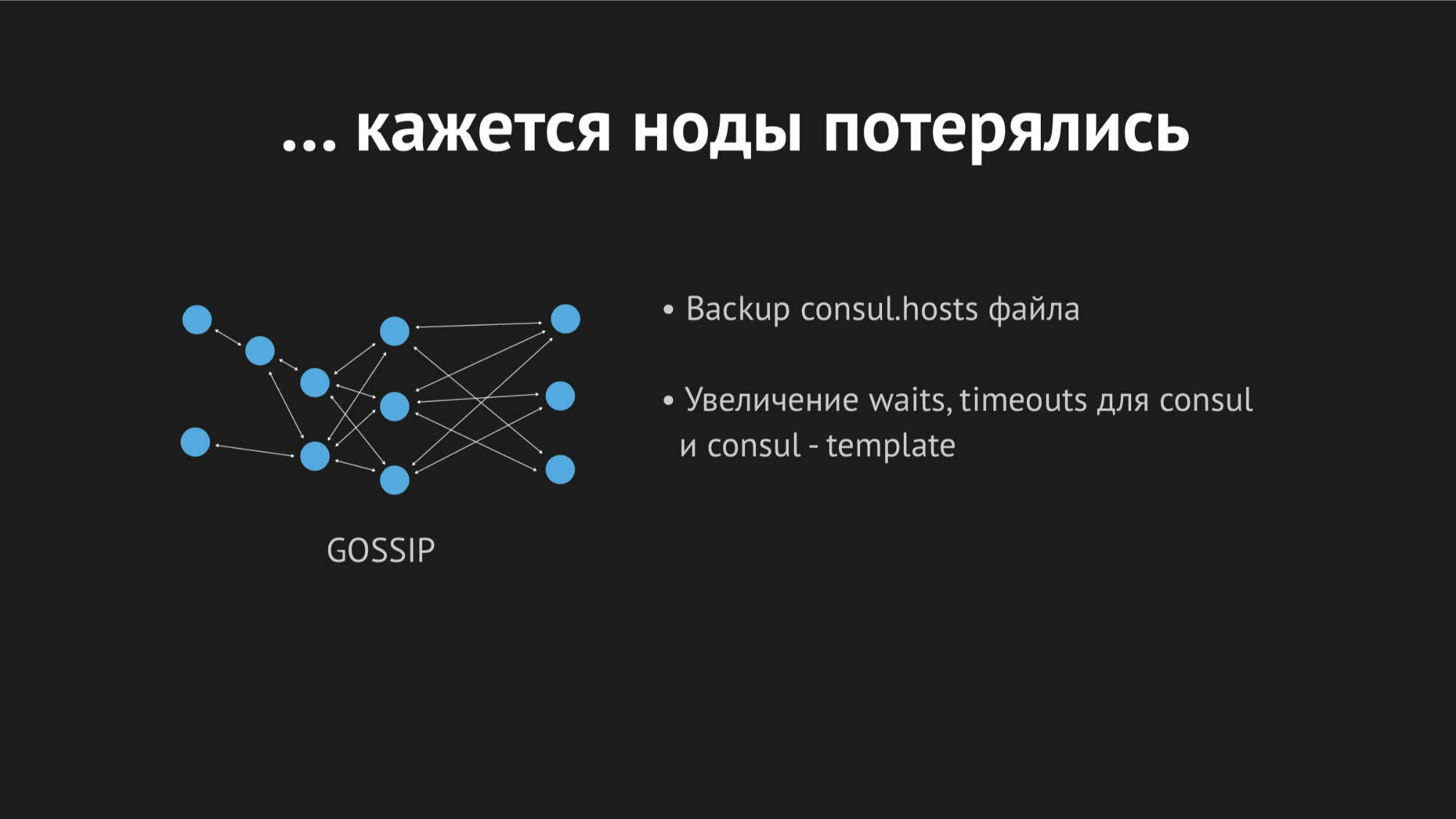
En traitant les journaux le matin, j'ai vu que toutes les erreurs étaient du même type d'hôte inconnu. On ne savait pas pourquoi Dnsmasq ne pouvait pas utiliser l'un ou l'autre service à partir d'un fichier - il semblait qu'il n'existait pas du tout. Pour essayer de comprendre ce qui se passait, j'ai ajouté une mesure personnalisée pour recréer le fichier - maintenant je savais exactement l'heure à laquelle il serait régénéré. De plus, le modèle Consul lui-même dispose d'une excellente option de sauvegarde, c'est-à-dire Vous pouvez voir l'état précédent du fichier régénéré.
Au cours de la journée, l'incident s'est répété plusieurs fois et il est devenu clair qu'à un moment donné (bien qu'il soit de nature sporadique et non systématique), le fichier des hôtes sans services spécifiques serait restitué. Il s'est avéré que dans un centre de données particulier (je ne ferai pas d'anti-publicité), il y a des réseaux plutôt instables - en raison des réseaux qui s'effondrent, nous avons cessé de façon imprévisible de passer des contrôles de santé, ou même les nœuds sont tombés du cluster. Cela ressemblait à ceci:
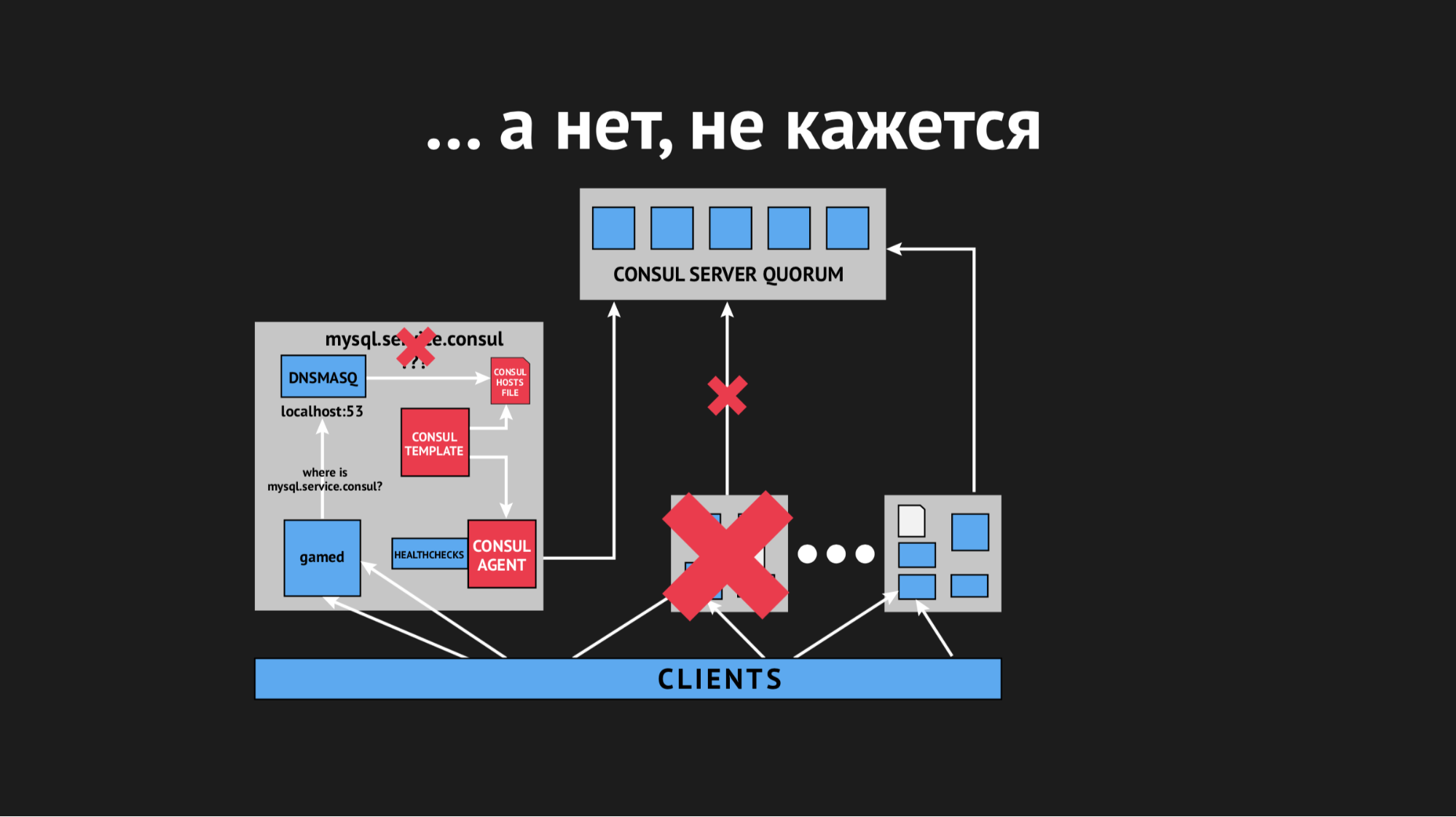
Le nœud est tombé hors du cluster, l'agent Consul en a été immédiatement informé et le modèle Consul a immédiatement régénéré le fichier hosts sans le service dont nous avions besoin. C'était généralement inacceptable, car le problème est ridicule: si le service n'est pas disponible pendant quelques secondes, configurez des délais d'attente et des retraits (ils ne se sont pas connectés une fois, mais la deuxième fois, il s'est avéré). Mais nous avons provoqué une nouvelle structure chez le vendeur lorsque le service disparaît tout simplement de la vue et qu'il n'y avait aucun moyen de s'y connecter.
Nous avons commencé à penser à quoi faire et à tordre le paramètre de délai d'expiration dans Consul, après quoi il est identifié après combien le nœud tombe. Nous avons réussi à résoudre ce problème avec un indicateur assez petit, les nœuds ont cessé de tomber, mais cela n'a pas aidé avec le contrôle de santé.
Nous avons commencé à penser à choisir différents paramètres pour le bilan de santé, essayant de comprendre en quelque sorte quand et comment cela se produit. Mais étant donné que tout s'est produit de façon sporadique et imprévisible, nous n'avons pas pu le faire.
Ensuite, nous sommes allés au modèle Consul et avons décidé de lui donner un délai d'attente, après quoi il réagit à un changement d'état du cluster. Encore une fois, il était impossible d'être fanatique, car nous pouvions arriver à une situation où le résultat ne serait pas meilleur que le DNS classique, lorsque nous visions un tout autre.
Et une fois de plus, notre directeur technique est venu à la rescousse et a déclaré: «Les gars, essayons de renoncer à toute cette interactivité, nous sommes tous en production et il n'y a pas de temps pour la recherche, nous devons résoudre ce problème. Profitons de choses simples et compréhensibles. » Nous sommes donc arrivés à l'idée d'utiliser le stockage de valeurs-clés comme source pour générer un fichier d'hôtes.
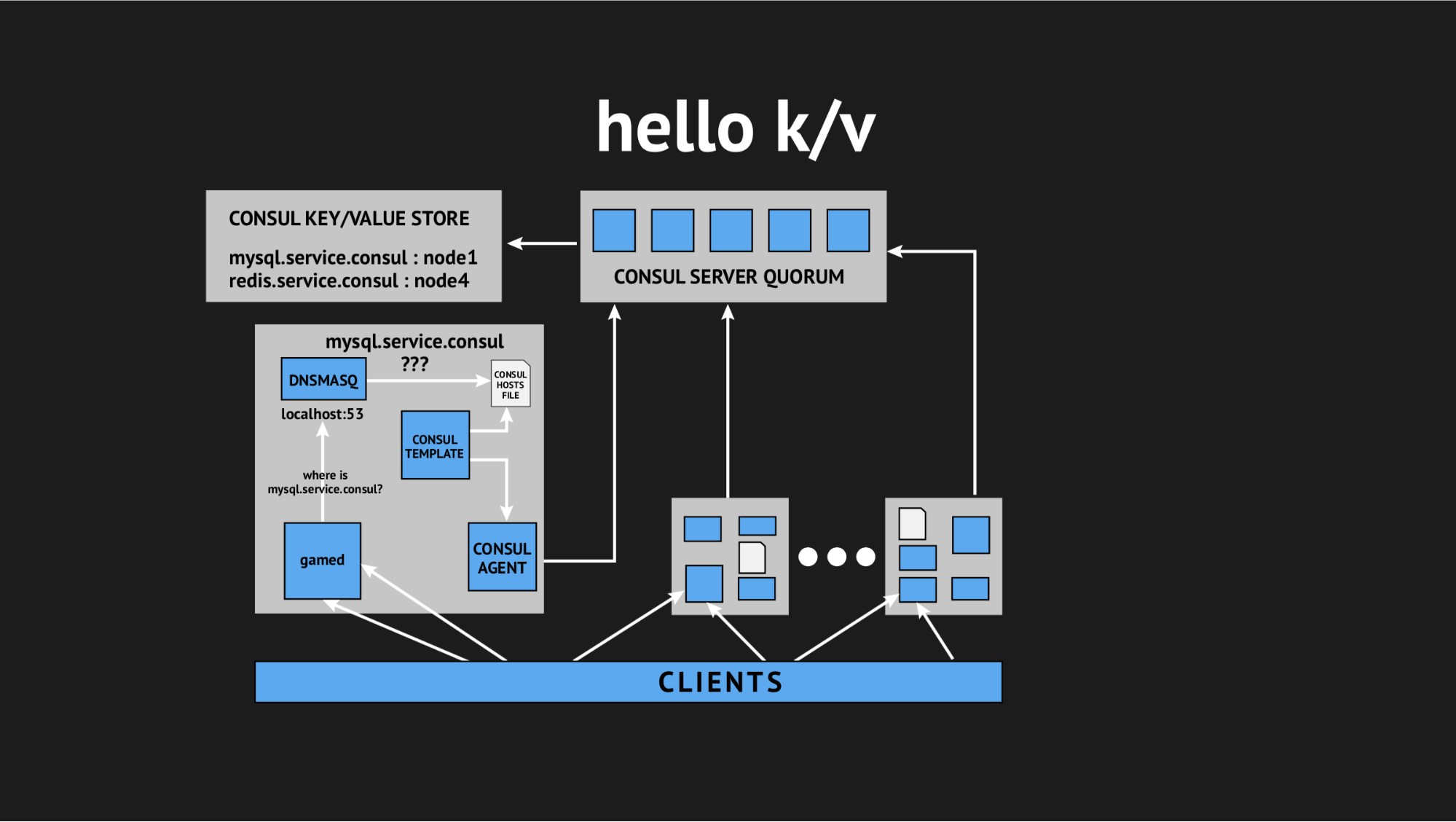
À quoi cela ressemble: nous refusons tous les contrôles de santé dynamiques, réécrivons notre modèle-script afin qu'il génère un fichier basé sur les données enregistrées dans le stockage de valeurs-clés. Dans le stockage de valeur-clé, nous décrivons l'ensemble de notre infrastructure sous la forme du nom de clé (c'est le nom du service dont nous avons besoin) et de la valeur de clé (c'est le nom du nœud dans le cluster). C'est-à-dire si le nœud est présent dans le cluster, alors nous obtenons très facilement son adresse IP et l'écrivons dans le fichier hosts.
Nous avons tout testé, rempli en production et c'est devenu une solution miracle dans une situation spécifique. Encore une fois, nous avons été assez tourmentés pendant toute la journée, nous sommes rentrés chez nous, mais nous sommes revenus déjà reposés, enthousiastes, car ces problèmes ne se reproduisaient plus et n'ont pas été répétés dans la soumission depuis un an. D'où je conclus personnellement que c'était la bonne décision (spécialement pour nous).
Alors. Nous avons finalement obtenu ce que nous voulions et organisé un espace de noms dynamique pour nos backends. De plus, nous sommes allés vers une haute disponibilité.

Mais le fait est que nous avons assez peur de l'intégration de Consul et en raison des problèmes que nous avons rencontrés, nous avons pensé et décidé que l'implémentation du basculement automatique n'était pas une bonne solution, car là encore nous risquons de faux positifs ou échecs. Ce processus est opaque et incontrôlable.
Par conséquent, nous avons suivi une voie plus simple (ou complexe): nous avons décidé de laisser le basculement à la conscience de l'administrateur de service, mais nous lui avons donné un autre outil supplémentaire. Nous avons remplacé la réplication maître esclave par la réplication maître maître en mode lecture seule. Cela supprime une énorme quantité de maux de tête dans le processus de failover'ov - lorsque vous obtenez un assistant, tout ce que vous devez faire est de modifier la valeur dans le stockage k / v à l'aide de l'interface utilisateur Web ou de la commande dans l'API et avant de supprimer le mode lecture seule maître de sauvegarde.
Une fois l'incident terminé, le maître contacte et revient automatiquement à un état coordonné sans aucune action inutile. Nous nous sommes arrêtés à cette option et nous l'utilisons comme auparavant - pour nous, c'est aussi pratique que possible, et surtout aussi simple, clair et contrôlé que possible.
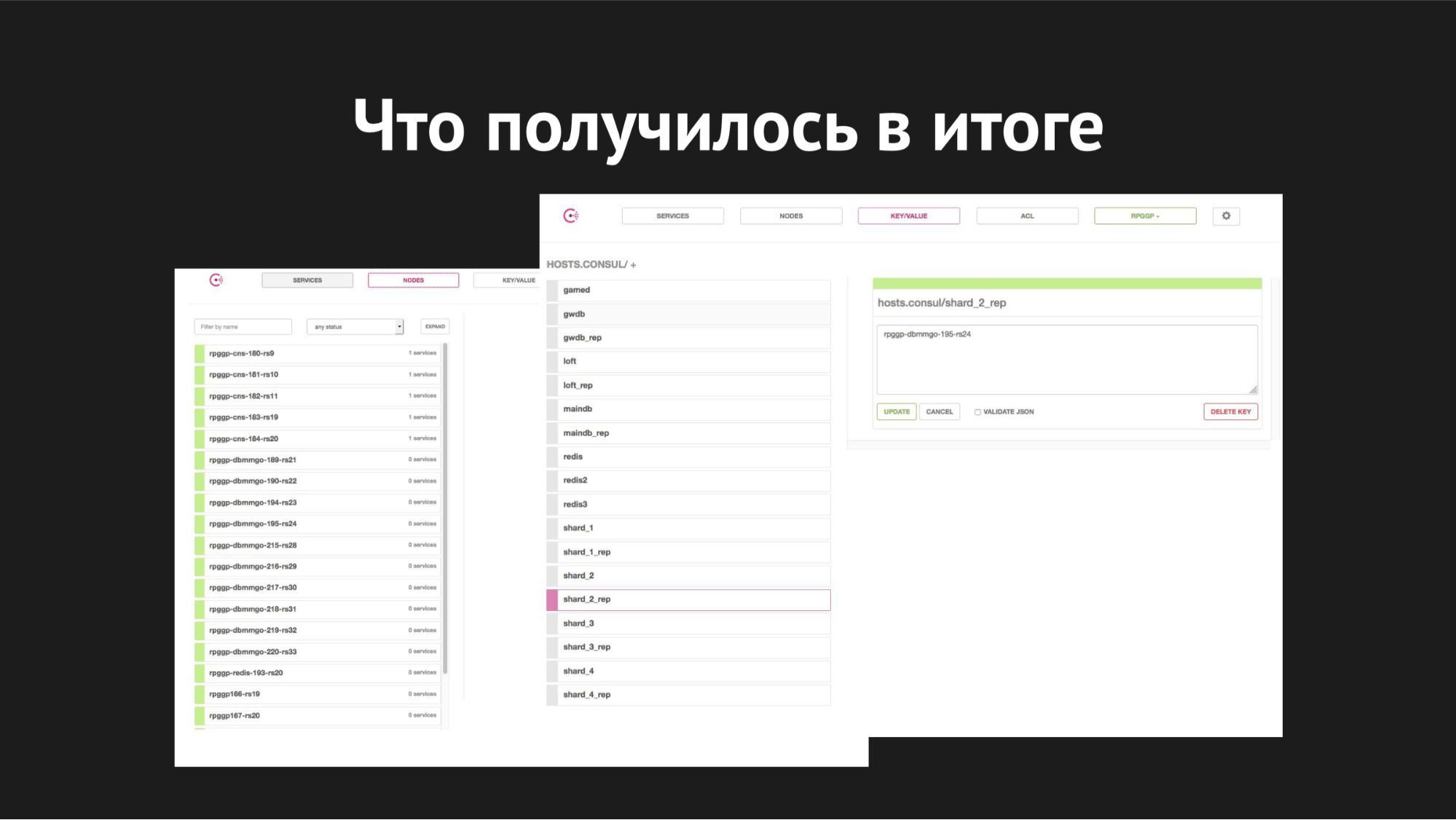 Interface Web du Consul
Interface Web du ConsulÀ droite se trouve le stockage k / v et nos services sont visibles, que nous utilisons dans le jeu; valeur est le nom du nœud.
Quant à la mise à l'échelle, nous avons commencé à l'implémenter lorsque les fragments étaient déjà encombrés sur un serveur, les bases ont augmenté, sont devenues lentes, le nombre de joueurs a augmenté, nous avons échangé et nous avons eu la tâche de distribuer tous les fragments à nos différents serveurs distincts.

À quoi cela ressemblait: en utilisant l'utilitaire XtraBackup, nous avons restauré notre sauvegarde sur une nouvelle paire de serveurs, après quoi le nouveau maître a été suspendu avec un esclave sur l'ancien. Il est venu à un état cohérent, nous avons changé la valeur de clé dans k / v-storage du nom du nœud de l'ancien maître au nom du nœud du nouveau maître. Ensuite (lorsque nous avons cru que tout s'était bien passé et que tous jouaient avec leurs sélections, mises à jour, insertions, ils étaient allés au nouveau maître), nous n'avions qu'à tuer la réplication et créer la base de données très recherchée en production, comme nous aimons tous le faire avec des bases de données inutiles.

Nous avons donc fait éclater les éclats. L'ensemble du processus de déplacement a pris de 40 minutes à une heure et n'a causé aucun temps d'arrêt à personne, il était complètement transparent pour nos backends et en lui-même était complètement transparent pour les joueurs (sauf que dès qu'ils se déplaçaient, il devenait plus facile et plus agréable pour eux de jouer).

En ce qui concerne les processus de basculement, le temps de commutation est ici de 20 à 40 secondes, plus le temps de réaction de l'administrateur système en service. Voilà à quoi tout cela ressemble avec nous maintenant.
Ce que je voudrais dire en conclusion - malheureusement, nos espoirs d'une automatisation absolue et complète se sont effondrés dans la dure réalité du support de transmission de données dans un centre de données chargé et des facteurs aléatoires que nous ne pouvions pas prévoir.
Deuxièmement, il nous a une fois de plus appris qu'une mésange simple et éprouvée entre les mains de votre administrateur système est meilleure qu'une grue à réaction automatique à échelle réduite quelque part au-delà des nuages, que vous ne comprenez même pas si elle se désagrège, ou vraiment commencé à évoluer.
L'introduction de toute infrastructure, l'automatisation de votre production ne devraient pas causer de maux de tête inutiles au personnel qui la dessert; cela ne devrait pas augmenter de manière significative le coût de la maintenance de la production de l'infrastructure - la solution doit être simple, claire, transparente pour vos clients, pratique et contrôlée.
Questions du public
Comment écrivez-vous k / v avec des serveurs - un script ou le corrigez-vous simplement?K/v- Consul- - , http- RESTful API Web UI.
, - , , .
, Redis?, - .
-, backend. -, backend', — . C'est-à-dire , MAINDB , . . - , .
- , inmemory key-value -.
?MySQL — Percona server.
? Maria, MHA for MySQL, Galera.Galera. - « » Galera , . , .
, — , , - , , , .
Pixonic DevGAMM Talks