Salut, Habr, dans cet article, je vais parler de la bibliothèque ignite , avec laquelle vous pouvez facilement former et tester des réseaux de neurones en utilisant le framework PyTorch.
Avec ignite, vous pouvez écrire des cycles pour entraîner le réseau en quelques lignes, ajouter un calcul de métriques standard dans la boîte, enregistrer le modèle, etc. Eh bien, pour ceux qui sont passés de TF à PyTorch, nous pouvons dire que la bibliothèque enflammée est Keras pour PyTorch.
L'article examinera en détail un exemple de formation d'un réseau de neurones pour une tâche de classification utilisant ignite.

Ajoutez plus de feu à PyTorch
Je ne perdrai pas de temps à parler de la fraîcheur du framework PyTorch. Quiconque l'a déjà utilisé comprend de quoi je parle. Mais, avec tous ses avantages, il reste de bas niveau en termes de cycles d'écriture pour la formation, les tests, les tests des réseaux de neurones.
Si nous regardons des exemples officiels d' utilisation du framework PyTorch, nous verrons au moins deux cycles d'itérations par époque et par lots de l'ensemble d'apprentissage dans le code d'apprentissage de la grille:
for epoch in range(1, epochs + 1): for batch_idx, (data, target) in enumerate(train_loader):
L'idée principale de la bibliothèque ignite est de factoriser ces boucles dans une seule classe, tout en permettant à l'utilisateur d'interagir avec ces boucles à l'aide de gestionnaires d'événements.
Par conséquent, dans le cas de tâches d'apprentissage approfondi standard, nous pouvons économiser beaucoup sur le nombre de lignes de code. Moins de lignes - moins d'erreurs!
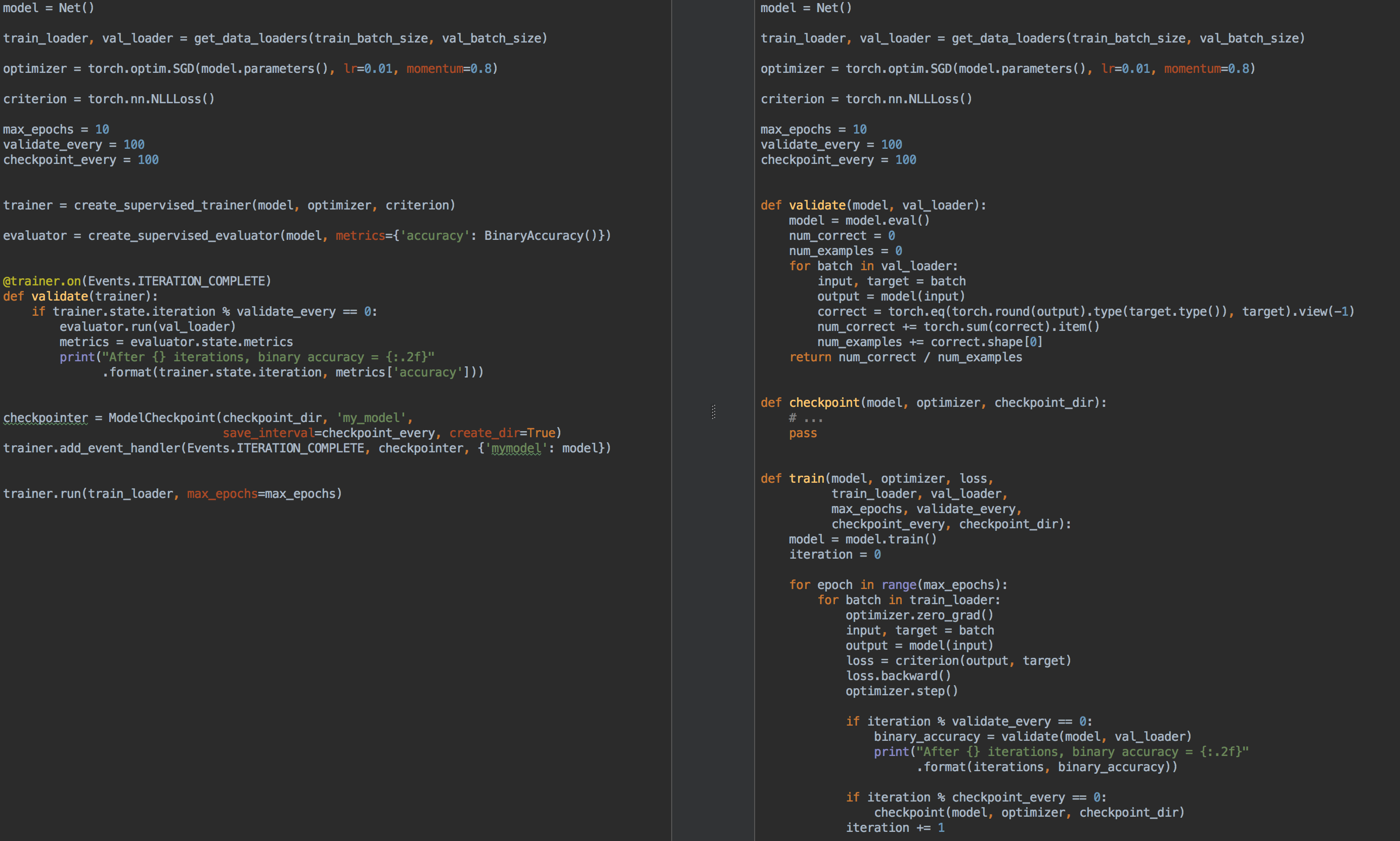
Par exemple, à titre de comparaison, à gauche se trouve le code de formation et de validation de modèle à l'aide de Ignite , et à droite, PyTorch pur:
Encore une fois, à quoi sert l' allumage ?
- vous n'avez plus besoin d'écrire pour chaque boucle de tâche
for epoch in range(n_epochs) et for batch in data_loader . - vous permet de mieux factoriser le code
- vous permet de calculer les métriques de base hors de la boîte
- fournit des "petits pains" comme
- enregistrer les derniers et meilleurs modèles (également optimiseur et programmateur de taux d'apprentissage) pendant la formation,
- arrêter tôt l'apprentissage
- etc.
- s'intègre facilement aux outils de visualisation: tensorboardX, visdom, ...
Dans un sens, comme déjà mentionné, la bibliothèque enflammée peut être comparée à tous les célèbres Keras et à son API pour la formation et les tests de réseaux. De plus, la bibliothèque ignite à première vue est très similaire à la bibliothèque tnt , car au départ, les deux bibliothèques avaient des objectifs communs et des idées similaires pour leur mise en œuvre.
Alors, allumez:
pip install pytorch-ignite
ou
conda install ignite -c pytorch
Ensuite, avec un exemple spécifique, nous nous familiariserons avec l' API de la bibliothèque ignite .
Tâche de classification avec ignite
Dans cette partie de l'article, nous considérerons un exemple scolaire de formation d'un réseau neuronal pour le problème de classification à l'aide de la bibliothèque ignite .
Prenons donc un simple ensemble de données avec des images de fruits avec kaggle . La tâche consiste à associer une classe correspondante à chaque image de fruit.
Avant d'utiliser ignite , définissons les principaux composants:
Flux de données
- chargeur d'échantillons de formation,
train_loader - checkout batch downloader,
val_loader
Modèle:
- prenez la petite grille
torchvision de torchvision
Algorithme d'optimisation:
Fonction de perte:
Code from pathlib import Path import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torch.utils.data.dataset import Subset from torchvision.datasets import ImageFolder from torchvision.transforms import Compose, RandomResizedCrop, RandomVerticalFlip, RandomHorizontalFlip from torchvision.transforms import ColorJitter, ToTensor, Normalize FRUIT360_PATH = Path(".").resolve().parent / "input" / "fruits-360_dataset" / "fruits-360" device = "cuda" train_transform = Compose([ RandomHorizontalFlip(), RandomResizedCrop(size=32), ColorJitter(brightness=0.12), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) val_transform = Compose([ RandomResizedCrop(size=32), ToTensor(), Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) ]) batch_size = 128 num_workers = 8 train_dataset = ImageFolder((FRUIT360_PATH /"Training").as_posix(), transform=train_transform, target_transform=None) val_dataset = ImageFolder((FRUIT360_PATH /"Test").as_posix(), transform=val_transform, target_transform=None) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device) val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
import torch.nn as nn from torchvision.models.squeezenet import squeezenet1_1 model = squeezenet1_1(pretrained=False, num_classes=81) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device)
import torch.nn as nn from torch.optim import SGD optimizer = SGD(model.parameters(), lr=0.01, momentum=0.5) criterion = nn.CrossEntropyLoss()
Alors maintenant, il est temps de lancer Ignite :
from ignite.engine import Engine, _prepare_batch def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item() trainer = Engine(process_function)
Voyons ce que ce code signifie.
Moteur Engine
La classe ignite.engine.Engine est le framework de bibliothèque, et l'objet de cette classe est trainer :
trainer = Engine(process_function)
Il est défini avec la fonction d'entrée process_function pour traiter un lot et sert à implémenter des passes pour l'échantillon d'apprentissage. Dans la classe ignite.engine.Engine , les ignite.engine.Engine suivants se produisent:
while epoch < max_epochs:
Retour à la fonction process_function :
def process_function(engine, batch): model.train() optimizer.zero_grad() x, y = _prepare_batch(batch, device=device) y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() return loss.item()
Nous voyons qu'à l'intérieur de la fonction, comme d'habitude dans le cas de la formation sur modèle, nous calculons les prédictions y_pred , calculons la fonction de loss , la loss et les gradients. Ces derniers vous permettent de mettre à jour le poids du modèle: optimizer.step() .
En général, il n'y a aucune restriction sur le code de la fonction process_function . Nous notons seulement qu'il prend deux arguments en entrée: l'objet Engine (dans notre cas, trainer ) et le lot du chargeur de données. Par conséquent, par exemple, pour tester un réseau de neurones, nous pouvons définir un autre objet de la classe ignite.engine.Engine , dans lequel la fonction d'entrée calcule simplement les prédictions et implémenter une passe d'échantillonnage de test une fois. Lisez à ce sujet plus tard.
Ainsi, le code ci-dessus définit uniquement les objets nécessaires sans démarrer la formation. Fondamentalement, dans un exemple minimal, vous pouvez appeler la méthode:
trainer.run(train_loader, max_epochs=10)
et ce code suffit pour "tranquillement" (sans dérivation de résultats intermédiaires) former le modèle.
Une noteNotez également que pour les tâches de ce type, la bibliothèque dispose d'une méthode pratique pour créer l'objet trainer :
from ignite.engine import create_supervised_trainer trainer = create_supervised_trainer(model, optimizer, criterion, device)
Bien sûr, dans la pratique, l'exemple ci-dessus est de peu d'intérêt, alors ajoutons les options suivantes pour le «coach»:
- affichage de la valeur de la fonction de perte toutes les 50 itérations
- début du calcul des métriques sur l'ensemble de formation avec un modèle fixe
- début du calcul des métriques sur l'échantillon de test après chaque ère
- enregistrement des paramètres du modèle après chaque ère
- préservation des trois meilleurs modèles
- changement de la vitesse d'apprentissage en fonction de l'ère (programmation du rythme d'apprentissage)
- formation d'arrêt précoce (arrêt précoce)
Événements et gestionnaires d'événements
Pour ajouter les options ci-dessus pour le «formateur», la bibliothèque ignite fournit un système d'événements et le lancement de gestionnaires d'événements personnalisés. Ainsi, l'utilisateur peut contrôler un objet de la classe Engine à chaque étape:
- lancement du moteur démarré / terminé
- l'ère a commencé / s'est terminée
- itération par lots commencée / terminée
et exécutez votre code à chaque événement.
Affiche les valeurs de la fonction de perte
Pour ce faire, il vous suffit de déterminer la fonction dans laquelle la sortie sera affichée à l'écran et de l'ajouter au "trainer":
from ignite.engine import Events log_interval = 50 @trainer.on(Events.ITERATION_COMPLETED) def log_training_loss(engine): iteration = (engine.state.iteration - 1) % len(train_loader) + 1 if iteration % log_interval == 0: print("Epoch[{}] Iteration[{}/{}] Loss: {:.4f}" .format(engine.state.epoch, iteration, len(train_loader), engine.state.output))
Il existe en fait deux façons d'ajouter un gestionnaire d'événements: via add_event_handler ou via on décorateur on. La même chose que ci-dessus peut être effectuée comme ceci:
from ignite.engine import Events log_interval = 50 def log_training_loss(engine):
Notez que tous les arguments peuvent être transmis à la fonction de gestion des événements. En général, une telle fonction ressemblera à ceci:
def custom_handler(engine, *args, **kwargs): pass trainer.add_event_handler(Events.ITERATION_COMPLETED, custom_handler, *args, **kwargs)
Commençons donc à nous entraîner sur une ère et voyons ce qui se passe:
output = trainer.run(train_loader, max_epochs=1)
Epoch[1] Iteration[50/322] Loss: 4.3459 Epoch[1] Iteration[100/322] Loss: 4.2801 Epoch[1] Iteration[150/322] Loss: 4.2294 Epoch[1] Iteration[200/322] Loss: 4.1467 Epoch[1] Iteration[250/322] Loss: 3.8607 Epoch[1] Iteration[300/322] Loss: 3.6688
Pas mal! Allons plus loin.
Démarrage du calcul des métriques sur les échantillons de formation et de test
Calculons les métriques suivantes: précision moyenne, exhaustivité moyenne après chaque ère de la part de la formation et échantillon de test complet. Notez que nous calculerons les métriques de la partie de l'échantillon de formation après chaque période de formation, et non pendant la formation. Ainsi, la mesure de l'efficacité sera plus précise, puisque le modèle ne change pas pendant le calcul.
Nous définissons donc les métriques:
from ignite.metrics import Loss, CategoricalAccuracy, Precision, Recall metrics = { 'avg_loss': Loss(criterion), 'avg_accuracy': CategoricalAccuracy(), 'avg_precision': Precision(average=True), 'avg_recall': Recall(average=True) }
Ensuite, nous allons créer deux moteurs pour évaluer le modèle en utilisant ignite.engine.create_supervised_evaluator :
from ignite.engine import create_supervised_evaluator
Nous créons deux moteurs afin d'attacher davantage de gestionnaires d'événements supplémentaires à l'un d'eux ( val_evaluator ) pour enregistrer le modèle et arrêter l'apprentissage tôt (à propos de tout cela ci-dessous).
Examinons également de plus près comment le moteur d'évaluation du modèle est défini, à savoir, comment la fonction d'entrée process_function définie pour traiter un lot:
def create_supervised_evaluator(model, metrics={}, device=None): if device: model.to(device) def _inference(engine, batch): model.eval() with torch.no_grad(): x, y = _prepare_batch(batch, device=device) y_pred = model(x) return y_pred, y engine = Engine(_inference) for name, metric in metrics.items(): metric.attach(engine, name) return engine
Nous continuons plus loin. Choisissons au hasard la partie de l'échantillon d'apprentissage sur laquelle nous allons calculer les métriques:
import numpy as np from torch.utils.data.dataset import Subset indices = np.arange(len(train_dataset)) random_indices = np.random.permutation(indices)[:len(val_dataset)] train_subset = Subset(train_dataset, indices=random_indices) train_eval_loader = DataLoader(train_subset, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True, pin_memory="cuda" in device)
Ensuite, déterminons à quel moment de la formation nous allons commencer le calcul des métriques et afficher à l'écran:
@trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_offline_train_metrics(engine): epoch = engine.state.epoch print("Compute train metrics...") metrics = train_evaluator.run(train_eval_loader).metrics print("Training Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall'])) @trainer.on(Events.EPOCH_COMPLETED) def compute_and_display_val_metrics(engine): epoch = engine.state.epoch print("Compute validation metrics...") metrics = val_evaluator.run(val_loader).metrics print("Validation Results - Epoch: {} Average Loss: {:.4f} | Accuracy: {:.4f} | Precision: {:.4f} | Recall: {:.4f}" .format(engine.state.epoch, metrics['avg_loss'], metrics['avg_accuracy'], metrics['avg_precision'], metrics['avg_recall']))
Vous pouvez courir!
output = trainer.run(train_loader, max_epochs=1)
Nous montons à l'écran
Epoch[1] Iteration[50/322] Loss: 3.5112 Epoch[1] Iteration[100/322] Loss: 2.9840 Epoch[1] Iteration[150/322] Loss: 2.8807 Epoch[1] Iteration[200/322] Loss: 2.9285 Epoch[1] Iteration[250/322] Loss: 2.5026 Epoch[1] Iteration[300/322] Loss: 2.1944 Compute train metrics... Training Results - Epoch: 1 Average Loss: 2.1018 | Accuracy: 0.3699 | Precision: 0.3981 | Recall: 0.3686 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 2.0519 | Accuracy: 0.3850 | Precision: 0.3578 | Recall: 0.3845
Déjà mieux!
Quelques détails
Regardons un peu le code précédent. Le lecteur a peut-être remarqué la ligne de code suivante:
metrics = train_evaluator.run(train_eval_loader).metrics
et il y avait probablement une question sur le type d'objet obtenu de train_evaluator.run(train_eval_loader) , qui a l'attribut train_evaluator.run(train_eval_loader) .
En fait, la classe Engine contient une structure appelée state (type State ) afin de pouvoir transférer des données entre des gestionnaires d'événements. Cet attribut d' state contient des informations de base sur l'ère actuelle, l'itération, le nombre d'époques, etc. Il peut également être utilisé pour transférer toutes les données utilisateur, y compris les résultats du calcul des métriques.
state = train_evaluator.run(train_eval_loader) metrics = state.metrics
Calcul des métriques pendant la formation
Si la tâche comporte un énorme échantillon de formation et que le calcul des métriques après chaque période de formation est coûteux, mais que vous souhaitez toujours voir certaines métriques changer pendant la formation, vous pouvez utiliser le gestionnaire d'événements RunningAverage suivant dans la boîte. Par exemple, nous voulons calculer et afficher la précision du classificateur:
acc_metric = RunningAverage(CategoryAccuracy(...), alpha=0.98) acc_metric.attach(trainer, 'running_avg_accuracy') @trainer.on(Events.ITERATION_COMPLETED) def log_running_avg_metrics(engine): print("running avg accuracy:", engine.state.metrics['running_avg_accuracy'])
Pour utiliser la fonctionnalité RunningAverage , vous devez installer ignite à partir des sources:
pip install git+https:
Planification du taux d'apprentissage
Il existe plusieurs façons de modifier la vitesse d'apprentissage en utilisant ignite . Ensuite, considérez la méthode la plus simple en appelant la fonction lr_scheduler.step() au début de chaque ère.
from torch.optim.lr_scheduler import ExponentialLR lr_scheduler = ExponentialLR(optimizer, gamma=0.8) @trainer.on(Events.EPOCH_STARTED) def update_lr_scheduler(engine): lr_scheduler.step()
Enregistrement des meilleurs modèles et autres paramètres pendant la formation
Pendant la formation, il serait formidable d'enregistrer les poids du meilleur modèle sur le disque, ainsi que de sauvegarder périodiquement les poids du modèle, les paramètres d'optimisation et les paramètres pour changer la vitesse d'apprentissage. Ce dernier peut être utile pour reprendre l'apprentissage à partir du dernier état enregistré.
Ignite a une classe ModelCheckpoint spéciale pour cela. ModelCheckpoint un ModelCheckpoint événements ModelCheckpoint et enregistrons le meilleur modèle en termes de précision dans l'ensemble de test. Dans ce cas, nous définissons une fonction score_function qui donne la valeur de précision au gestionnaire d'événements et qui décide d'enregistrer ou non le modèle:
from ignite.handlers import ModelCheckpoint def score_function(engine): val_avg_accuracy = engine.state.metrics['avg_accuracy'] return val_avg_accuracy best_model_saver = ModelCheckpoint("best_models", filename_prefix="model", score_name="val_accuracy", score_function=score_function, n_saved=3, save_as_state_dict=True, create_dir=True)
Créez maintenant un autre ModelCheckpoint événement ModelCheckpoint afin de maintenir l'état d'apprentissage toutes les 1000 itérations:
training_saver = ModelCheckpoint("checkpoint", filename_prefix="checkpoint", save_interval=1000, n_saved=1, save_as_state_dict=True, create_dir=True) to_save = {"model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler} trainer.add_event_handler(Events.ITERATION_COMPLETED, training_saver, to_save)
Donc, presque tout est prêt, ajoutez le dernier élément:
Entraînement à l'arrêt précoce (arrêt précoce)
Ajoutons un autre gestionnaire d'événements qui cessera d'apprendre s'il n'y a pas d'amélioration de la qualité du modèle sur 10 époques. Nous évaluerons à nouveau la qualité du modèle en utilisant la score_function score_function.
from ignite.handlers import EarlyStopping early_stopping = EarlyStopping(patience=10, score_function=score_function, trainer=trainer) val_evaluator.add_event_handler(Events.EPOCH_COMPLETED, early_stopping)
Commencer la formation
Pour commencer l'entraînement, il nous suffit d'appeler la méthode run() . Nous formerons le modèle pendant 10 époques:
max_epochs = 10 output = trainer.run(train_loader, max_epochs=max_epochs)
Sortie écran Learning rate: 0.01 Epoch[1] Iteration[50/322] Loss: 2.7984 Epoch[1] Iteration[100/322] Loss: 1.9736 Epoch[1] Iteration[150/322] Loss: 4.3419 Epoch[1] Iteration[200/322] Loss: 2.0261 Epoch[1] Iteration[250/322] Loss: 2.1724 Epoch[1] Iteration[300/322] Loss: 2.1599 Compute train metrics... Training Results - Epoch: 1 Average Loss: 1.5363 | Accuracy: 0.5177 | Precision: 0.5477 | Recall: 0.5178 Compute validation metrics... Validation Results - Epoch: 1 Average Loss: 1.5116 | Accuracy: 0.5139 | Precision: 0.5400 | Recall: 0.5140 Learning rate: 0.008 Epoch[2] Iteration[50/322] Loss: 1.4076 Epoch[2] Iteration[100/322] Loss: 1.4892 Epoch[2] Iteration[150/322] Loss: 1.2485 Epoch[2] Iteration[200/322] Loss: 1.6511 Epoch[2] Iteration[250/322] Loss: 3.3376 Epoch[2] Iteration[300/322] Loss: 1.3299 Compute train metrics... Training Results - Epoch: 2 Average Loss: 3.2686 | Accuracy: 0.1977 | Precision: 0.1792 | Recall: 0.1942 Compute validation metrics... Validation Results - Epoch: 2 Average Loss: 3.2772 | Accuracy: 0.1962 | Precision: 0.1628 | Recall: 0.1918 Learning rate: 0.006400000000000001 Epoch[3] Iteration[50/322] Loss: 0.9016 Epoch[3] Iteration[100/322] Loss: 1.2006 Epoch[3] Iteration[150/322] Loss: 0.8892 Epoch[3] Iteration[200/322] Loss: 0.8141 Epoch[3] Iteration[250/322] Loss: 1.4005 Epoch[3] Iteration[300/322] Loss: 0.8888 Compute train metrics... Training Results - Epoch: 3 Average Loss: 0.7368 | Accuracy: 0.7554 | Precision: 0.7818 | Recall: 0.7554 Compute validation metrics... Validation Results - Epoch: 3 Average Loss: 0.7177 | Accuracy: 0.7623 | Precision: 0.7863 | Recall: 0.7611 Learning rate: 0.005120000000000001 Epoch[4] Iteration[50/322] Loss: 0.8490 Epoch[4] Iteration[100/322] Loss: 0.8493 Epoch[4] Iteration[150/322] Loss: 0.8100 Epoch[4] Iteration[200/322] Loss: 0.9165 Epoch[4] Iteration[250/322] Loss: 0.9370 Epoch[4] Iteration[300/322] Loss: 0.6548 Compute train metrics... Training Results - Epoch: 4 Average Loss: 0.7047 | Accuracy: 0.7713 | Precision: 0.8040 | Recall: 0.7728 Compute validation metrics... Validation Results - Epoch: 4 Average Loss: 0.6737 | Accuracy: 0.7778 | Precision: 0.7955 | Recall: 0.7806 Learning rate: 0.004096000000000001 Epoch[5] Iteration[50/322] Loss: 0.6965 Epoch[5] Iteration[100/322] Loss: 0.6196 Epoch[5] Iteration[150/322] Loss: 0.6194 Epoch[5] Iteration[200/322] Loss: 0.3986 Epoch[5] Iteration[250/322] Loss: 0.6032 Epoch[5] Iteration[300/322] Loss: 0.7152 Compute train metrics... Training Results - Epoch: 5 Average Loss: 0.5049 | Accuracy: 0.8282 | Precision: 0.8393 | Recall: 0.8314 Compute validation metrics... Validation Results - Epoch: 5 Average Loss: 0.5084 | Accuracy: 0.8304 | Precision: 0.8386 | Recall: 0.8328 Learning rate: 0.0032768000000000007 Epoch[6] Iteration[50/322] Loss: 0.4433 Epoch[6] Iteration[100/322] Loss: 0.4764 Epoch[6] Iteration[150/322] Loss: 0.5578 Epoch[6] Iteration[200/322] Loss: 0.3684 Epoch[6] Iteration[250/322] Loss: 0.4847 Epoch[6] Iteration[300/322] Loss: 0.3811 Compute train metrics... Training Results - Epoch: 6 Average Loss: 0.4383 | Accuracy: 0.8474 | Precision: 0.8618 | Recall: 0.8495 Compute validation metrics... Validation Results - Epoch: 6 Average Loss: 0.4419 | Accuracy: 0.8446 | Precision: 0.8532 | Recall: 0.8442 Learning rate: 0.002621440000000001 Epoch[7] Iteration[50/322] Loss: 0.4447 Epoch[7] Iteration[100/322] Loss: 0.4602 Epoch[7] Iteration[150/322] Loss: 0.5345 Epoch[7] Iteration[200/322] Loss: 0.3973 Epoch[7] Iteration[250/322] Loss: 0.5023 Epoch[7] Iteration[300/322] Loss: 0.5303 Compute train metrics... Training Results - Epoch: 7 Average Loss: 0.4305 | Accuracy: 0.8579 | Precision: 0.8691 | Recall: 0.8596 Compute validation metrics... Validation Results - Epoch: 7 Average Loss: 0.4262 | Accuracy: 0.8590 | Precision: 0.8685 | Recall: 0.8606 Learning rate: 0.002097152000000001 Epoch[8] Iteration[50/322] Loss: 0.4867 Epoch[8] Iteration[100/322] Loss: 0.3090 Epoch[8] Iteration[150/322] Loss: 0.3721 Epoch[8] Iteration[200/322] Loss: 0.4559 Epoch[8] Iteration[250/322] Loss: 0.3958 Epoch[8] Iteration[300/322] Loss: 0.4222 Compute train metrics... Training Results - Epoch: 8 Average Loss: 0.3432 | Accuracy: 0.8818 | Precision: 0.8895 | Recall: 0.8817 Compute validation metrics... Validation Results - Epoch: 8 Average Loss: 0.3644 | Accuracy: 0.8713 | Precision: 0.8784 | Recall: 0.8707 Learning rate: 0.001677721600000001 Epoch[9] Iteration[50/322] Loss: 0.3557 Epoch[9] Iteration[100/322] Loss: 0.3692 Epoch[9] Iteration[150/322] Loss: 0.3510 Epoch[9] Iteration[200/322] Loss: 0.3446 Epoch[9] Iteration[250/322] Loss: 0.3966 Epoch[9] Iteration[300/322] Loss: 0.3451 Compute train metrics... Training Results - Epoch: 9 Average Loss: 0.3315 | Accuracy: 0.8954 | Precision: 0.9001 | Recall: 0.8982 Compute validation metrics... Validation Results - Epoch: 9 Average Loss: 0.3559 | Accuracy: 0.8818 | Precision: 0.8876 | Recall: 0.8847 Learning rate: 0.0013421772800000006 Epoch[10] Iteration[50/322] Loss: 0.3340 Epoch[10] Iteration[100/322] Loss: 0.3370 Epoch[10] Iteration[150/322] Loss: 0.3694 Epoch[10] Iteration[200/322] Loss: 0.3409 Epoch[10] Iteration[250/322] Loss: 0.4420 Epoch[10] Iteration[300/322] Loss: 0.2770 Compute train metrics... Training Results - Epoch: 10 Average Loss: 0.3246 | Accuracy: 0.8921 | Precision: 0.8988 | Recall: 0.8925 Compute validation metrics... Validation Results - Epoch: 10 Average Loss: 0.3536 | Accuracy: 0.8731 | Precision: 0.8785 | Recall: 0.8722
Vérifiez maintenant les modèles et les paramètres enregistrés sur le disque:
ls best_models/ model_best_model_10_val_accuracy=0.8730994.pth model_best_model_8_val_accuracy=0.8712978.pth model_best_model_9_val_accuracy=0.8818188.pth
et
ls checkpoint/ checkpoint_lr_scheduler_3000.pth checkpoint_optimizer_3000.pth checkpoint_model_3000.pth
Prédictions par un modèle formé
Tout d'abord, créez un chargeur de données de test (par exemple, prenez un échantillon de validation) afin que le lot de données soit composé d'images et de leurs indices:
class TestDataset(Dataset): def __init__(self, ds): self.ds = ds def __len__(self): return len(self.ds) def __getitem__(self, index): return self.ds[index][0], index test_dataset = TestDataset(val_dataset) test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, drop_last=False, pin_memory="cuda" in device)
En utilisant ignite, nous allons créer un nouveau moteur de prédiction pour les données de test. Pour ce faire, nous définissons la fonction inference_update , qui retourne le résultat de la prédiction et l'index de l'image. Pour augmenter la précision, nous utiliserons également l'astuce bien connue «augmentation du temps de test» (TTA).
import torch.nn.functional as F from ignite._utils import convert_tensor def _prepare_batch(batch): x, index = batch x = convert_tensor(x, device=device) return x, index def inference_update(engine, batch): x, indices = _prepare_batch(batch) y_pred = model(x) y_pred = F.softmax(y_pred, dim=1) return {"y_pred": convert_tensor(y_pred, device='cpu'), "indices": indices} model.eval() inferencer = Engine(inference_update)
Ensuite, créez des gestionnaires d'événements qui vous informeront de l'étape des prédictions et enregistrer les prédictions dans un tableau dédié:
@inferencer.on(Events.EPOCH_COMPLETED) def log_tta(engine): print("TTA {} / {}".format(engine.state.epoch, n_tta)) n_tta = 3 num_classes = 81 n_samples = len(val_dataset) # y_probas_tta = np.zeros((n_samples, num_classes, n_tta), dtype=np.float32) @inferencer.on(Events.ITERATION_COMPLETED) def save_results(engine): output = engine.state.output tta_index = engine.state.epoch - 1 start_index = ((engine.state.iteration - 1) % len(test_loader)) * batch_size end_index = min(start_index + batch_size, n_samples) batch_y_probas = output['y_pred'].detach().numpy() y_probas_tta[start_index:end_index, :, tta_index] = batch_y_probas
Avant de commencer le processus, téléchargeons le meilleur modèle:
model = squeezenet1_1(pretrained=False, num_classes=64) model.classifier[-1] = nn.AdaptiveAvgPool2d(1) model = model.to(device) model_state_dict = torch.load("best_models/model_best_model_10_val_accuracy=0.8730994.pth") model.load_state_dict(model_state_dict)
Nous lançons:
inferencer.run(test_loader, max_epochs=n_tta) > TTA 1 / 3 > TTA 2 / 3 > TTA 3 / 3
Ensuite, de manière standard, nous prenons la moyenne des prédictions TTA et calculons l'indice de classe avec la plus forte probabilité:
y_probas = np.mean(y_probas_tta, axis=-1) y_preds = np.argmax(y_probas, axis=-1)
Et maintenant, nous pouvons à nouveau calculer la précision du modèle en fonction des prédictions:
from sklearn.metrics import accuracy_score y_test_true = [y for _, y in val_dataset] accuracy_score(y_test_true, y_preds) > 0.9310369676443035
, , . , , , ignite .
.
github
- fast neural transfer
- reinforcement learning
- dcgan
Conclusion
, ignite Facebook (. ). 0.1.0, API (Engine, State, Events, Metric, ...) . , , , pull request- github .
Merci de votre attention!