Beaucoup de gens utilisent le terme ADN. Mais il n'y a presque pas d'articles décrivant normalement comment cela fonctionne (incompréhensible pour les biologistes). J'ai déjà décrit en termes généraux la
structure de la cellule et les fondements mêmes de ses
processus énergétiques . Passons maintenant à l'ADN.
L'ADN stocke les informations. Tout le monde le sait. Mais voici comment elle le fait?
Commençons par où il est stocké dans la cellule. Environ 98% sont stockés dans le noyau. Le reste est dans les mitochondries et les chloroplastes (la photosynthèse a lieu chez ces gars-là). L'ADN est un énorme polymère composé d'unités monomères. Cela ressemble à ceci.
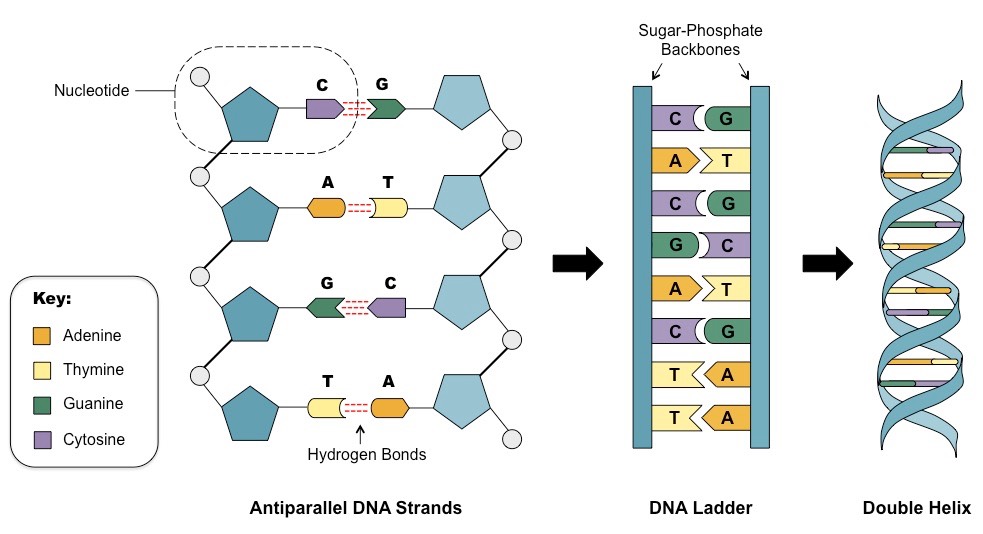
Que voyons-nous ici? Tout d'abord, l'ADN est une molécule double brin. Pourquoi est-ce si important - un peu plus tard. Ensuite, nous voyons les pentagones bleus. Ce sont des molécules de
désoxy ribose (ce sucre, un peu moins de glucose. Il diffère du ribose par l'absence d'un groupe OH, ce qui donne de la stabilité à la molécule d'ADN, contrairement à l'ARN, dans lequel le ribose est utilisé. Ensuite, pour plus de simplicité, je vais omettre le préfixe désoxy et je dirai juste ribose, oui des camarades scrupuleux nous pardonneront). Petits cercles - les restes d'acide phosphorique. Eh bien, en fait, il y a des bases azotées. Il y en a 5, mais ils se trouvent principalement dans l'ADN 4. Il s'agit de l'adénine, de la guanine, du timin et de la cytosine. C'est-à-dire qu'il existe un ribose auquel une base azotée est associée. Ensemble, ils forment les soi-disant nucléosides, qui se lient les uns aux autres en utilisant des résidus d'acide phosphorique. On obtient ainsi une longue chaîne constituée de monomères. Regardez maintenant la chaîne gauche agrandie. Voir C et G reliés par trois lignes pointillées, et T et A par deux. Qu'est-ce que cela signifie? Oui, l'ADN a deux brins, mais qu'est-ce qui les maintient ensemble? Il existe une liaison hydrogène. Cela ressemble à ceci. Une charge négative partielle se forme sur les atomes d'oxygène (O) et d'azote (N) et une charge positive sur l'hydrogène (H). Cela conduit à la formation de liaisons faibles.

Les connexions sont vraiment très faibles. Leur énergie peut être 200 fois inférieure à l'énergie des liaisons covalentes (elles se forment en raison du chevauchement d'une paire de nuages d'électrons, par exemple, une liaison dans une molécule de CO2). Cependant, il existe de nombreux liens de ce type. Dans chacune de nos cellules, les chaînes d'ADN sont liées par près de 16 milliards de liaisons faibles, pas un peu, d'accord?
Mais revenons au nombre de connexions entre les bases. La cytosine et la guanine sont connectées par trois liaisons, et l'adénine et la timin sont deux. Cela conduit au fait que G et C sont connectés beaucoup plus fortement que A et T. Certains organismes ont besoin d'une stabilité particulière des liaisons ADN, par exemple, vivant à des températures élevées. Lorsqu'il est chauffé, l'ADN contenant plus de paires HC est plus stable. Donc, vous voulez vivre dans un geyser - avoir beaucoup de paires HZ. Bien que des études récentes indiquent qu'il n'y a pas de lien clair entre la composition du GC (% de paires HC de toutes les paires) et la température de l'habitat. Il vaut la peine de dire qu'il varie considérablement. Ainsi, chez Candidatus Carsonella ruddii PV (endosymbionte intracellulaire), il est d'environ 16%, nous en avons près de 41%, et chez Anaeromyxobacter K (une bactérie de taille assez moyenne) il atteint 75%.
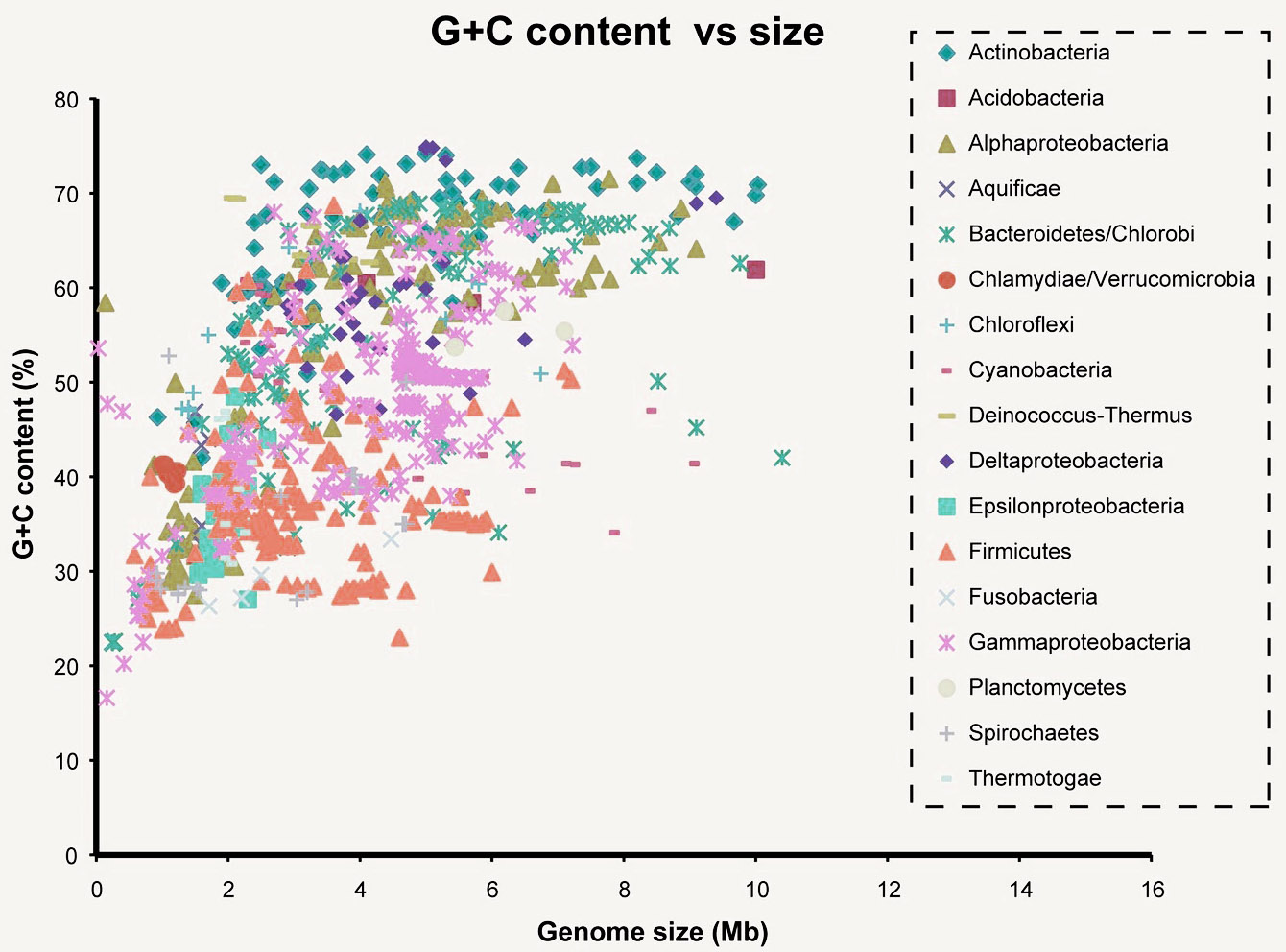
Ici, vous pouvez voir la relation de la composition GC avec la taille du génome bactérien. Mb est un million de paires de nucléotides. L'indicateur est assez variable. Soit dit en passant, il est souvent utilisé comme fonctionnalité lors de l'enseignement de divers types de classificateurs. J'ai moi-même récemment écrit un classificateur pour reconnaître les agents pathogènes sur la base de données de séquençage brutes, et il s'est avéré que la composition GC peut être utilisée même pour un ryd.
Je n'ai pas encore oublié. Pourquoi est-il important que l'ADN soit à double brin? Sur la base d'une chaîne, vous pouvez en restaurer une autre. Si un morceau opposé à la séquence Adenine-Adenine-Cytosine est endommagé dans une chaîne, alors nous savons avec certitude qu'avant les dommages il y avait Timin-Timin-Guanin. Ainsi, la présence du deuxième circuit permet un stockage plus fiable des informations.
Cool! Revenons maintenant à la molécule d'ADN elle-même. Il s'agit d'une chaîne de 4 types de maillons. Mais combien de temps? Candidatus Carsonella ruddii PV ne possède que 160 000 nucléotides comme mentionné ci-dessus. Vous et moi en avons 3,2 milliards (dans une cellule haploïde, c'est-à-dire avec un ensemble de chromosomes. La plupart de nos cellules en ont deux). Cela semble beaucoup, non? Pas vraiment. Dans une amibe unicellulaire (Amoeba dubia), elle compte environ 670 milliards de paires de nucléotides. Cela semble être une chaîne infiniment longue, alors traduisons la taille en nos mètres préférés. Si tous nos chromosomes (46 d'entre eux, n'oubliez pas; 23 deux exemplaires chacun) sont étendus et étirés sur une seule ligne, nous obtenons environ une chaîne de 2 mètres. L'ADN d'une amibe suffit pour encercler un stade de football. Mais vers quoi je mène? Le noyau dans lequel l'ADN est stocké n'est pas très grand. Nous l'avons en moyenne avec un diamètre de 6 microns. Pas beaucoup, si vous voulez rouler un fil de 2 mètres, bien que très fin. Et vous devez non seulement pousser le fil dans le noyau. Il est nécessaire de s'effondrer pour qu'à tout moment il soit possible de donner accès à n'importe quelle partie de celui-ci. La tâche est difficile. Et les protéines spécialisées y font face avec succès. Ils créent une série de spirales et de boucles qui fournissent des niveaux d'emballage de plus en plus élevés et ne permettent pas à l'ADN d'être emmêlé dans le nœud gordien. Parlons de la façon dont il est conditionné.
Je dois dire qu'il est conditionné de manière très différente. Mais si vous jetez l'exotisme, il y a deux façons. Le premier est caractéristique des bactéries, le second des eucaryotes (ou autrement nucléaires).
Emballage d'ADN dans les bactéries
Commençons par nos petits frères. Les bactéries elles-mêmes n'ont pas un très grand génome, en moyenne de 1 à 5 millions de paires de nucléotides. La différence la plus caractéristique entre eux et nous est qu'ils n'ont pas de noyau et que l'ADN flotte dans la cellule. Il ne nage pas tout à fait, il est partiellement attaché à la membrane cellulaire et est également plié, mais pas autant que le nôtre.
Le deuxième. L'ADN bactérien est le plus souvent circulaire. Il est donc plus facile de copier (aucune extrémité ne peut être perdue lors de la copie et vous n'avez pas besoin de trouver des mécanismes pour enregistrer les extrémités). Habituellement, un tel anneau en est un, mais certaines bactéries peuvent en avoir 2 ou 3. Il y a encore moins d'anneaux (de quelques milliers à quelques centaines de milliers de résidus). Leur nom est un plasmide, et c'est une autre histoire.
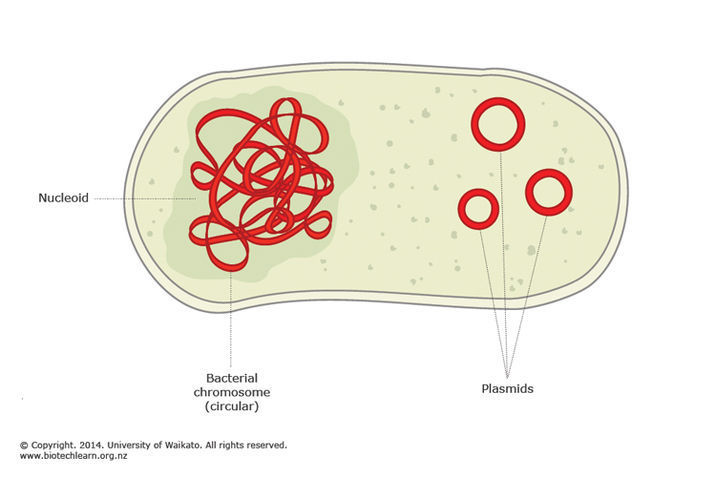
Retour au paquet ADN. L'ADN est rempli de protéines histones (il existe également des protéines de type histone). L'ADN est l'acide désoxyribonucléique.
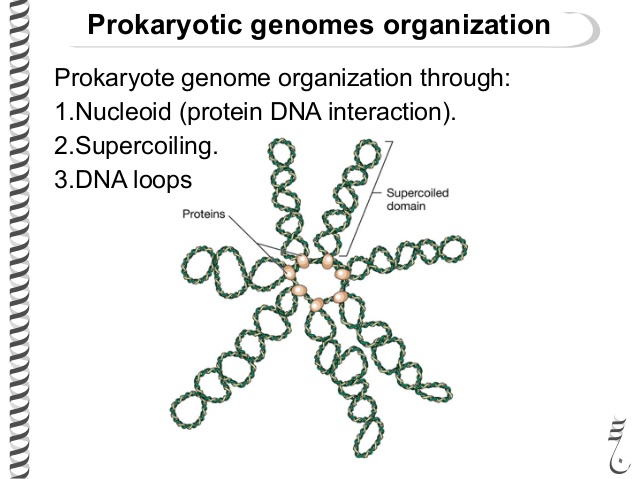
Acide . Cela signifie qu'il est chargé négativement (en raison des résidus d'acide phosphorique). Par conséquent, les protéines qui le lient sont chargées positivement. De cette façon, ils peuvent se lier à l'ADN. L'ADN bactérien et ses protéines d'emballage forment un nucléoïde, 80% de sa masse étant de l'ADN. Cela ressemble à ceci. Autrement dit, l'ADN du cycle est divisé en domaines de 40 000 paires de nucléotides. Ensuite, il y a une torsion. La torsion se produit également à l'intérieur des domaines, mais son degré diffère selon les domaines. En moyenne, le degré de conditionnement de l'ADN bactérien varie de cent à mille fois.
Il y a toujours une
vidéo sympa .
Emballage d'ADN chez les eucaryotes
Tout est beaucoup plus intéressant ici. Notre ADN est bien emballé et caché à l'intérieur du noyau. Et il est beaucoup plus efficace que les bactéries. Pendant la mitose (division cellulaire), la taille du 22e chromosome est de 2 microns. S'il est démêlé et retiré, il fera déjà 1,5 cm, ce qui correspond au degré d'emballage par 10 000 fois. Il s'agit du degré maximum d'emballage de notre ADN. Pendant la division, vous devez emballer l'ADN autant que possible afin de le diviser efficacement entre les cellules filles. Dans la vie quotidienne, le degré de compactage est d'environ 500 fois. Trop d'ADN est difficile à lire.
Il existe plusieurs niveaux de conditionnement d'ADN eucaryote
Le premier est le niveau nucléosomique. 8 protéines d'histones forment une particule sur laquelle l'ADN est enroulé. Puis une autre protéine le corrige. Cela ressemble à ceci.
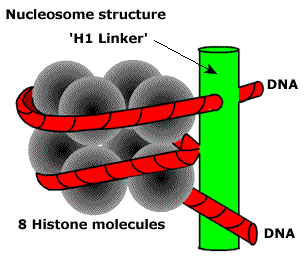

Il se révèle une sorte de perles. Pour cette raison, la densité d'emballage augmente de 7 à 10 fois. Ensuite, les nucléosomes sont emballés dans des fibrilles. Un peu comme un cornichon. Ici, le degré total d'emballage peut atteindre 60 fois.

L'étape suivante du compactage de l'ADN est associée à la formation de structures en boucle appelées chromomères. La fibrille est divisée en sections de 10 à 80 000 paires de bases azotées. Aux sites de dégradation se trouvent des globules de protéines non histoniques. Les protéines de liaison à l'ADN reconnaissent les globules de protéines non histoniques et les rassemblent. L'embouchure de la boucle est formée. La longueur moyenne d'une boucle comprend environ 50 000 bases. Cette structure est appelée chromonème interphase. Et c'est en elle que se situe la plupart du temps notre ADN. Le niveau d'emballage atteint ici 500 à 1500 fois.
Si nécessaire, la cellule peut encore compacter le matériel génétique. La formation de plus grandes boucles de fibrilles chromomères. Ces boucles forment à leur tour de nouvelles boucles (boucles en boucles ... et ce n'est pas du tricot). Qui forment finalement un chromosome.
En général, le processus d'emballage peut être décrit comme suit.

En conséquence, à partir de brins d'ADN, nous obtenons, lors de la division, des structures super enroulées qui peuvent être vues au microscope. Nous les appelons chromosomes.
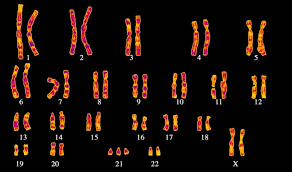
La substance des chromosomes elle-même est appelée chromatine. Et le degré de son emballage diffère selon le site chromosomique. Il y a l'euchromatine et l'hétérochromatine. L'euchromatine est une région plutôt non nettoyée de la chromatine, en elle l'ADN est au niveau chromomérique (emballage de 500 à 1000 fois). Voici une lecture active des informations. Par exemple, si une cellule synthétise activement la protéine A maintenant, alors la région d'ADN qui la code sera dans un état d'euchromatine afin que les enzymes qui lisent l'ADN puissent l'atteindre. L'hétérochromatine contient la partie de l'ADN dont la cellule n'a plus vraiment besoin à l'heure actuelle. Autrement dit, l'ADN est emballé aussi étroitement que possible afin de ne pas passer sous vos pieds. Selon les besoins de la cellule, certaines régions de la chromatine peuvent se défaire partiellement, tandis que d'autres peuvent s'entrelacer. Ainsi, une régulation est également effectuée (une approximation très grossière), car on ne peut pas atteindre une région tordue, et donc ne peut pas être lu.
En fait, c'est tout pour l'instant. Nous avons discuté de la façon dont le support de stockage est stocké. Nous allons faire une courte pause et dans quelques jours, nous parlerons du codage des informations.