L'article décrit l'expérience de l'organisation du stockage budgétaire d'une archive d'images pour un site avec des millions d'annonces.
Dans mon cas, les images sont comprises comme des photographies d'appartements, de maisons, de parcelles, etc. J'ai mon
propre projet qui est un site avec des annonces pour la vente et la location de biens immobiliers. Le site existe depuis environ 6 ans et pendant ce temps, un nombre assez important de publicités s'est accumulé. Sur chaque fiche objet, des photos sont affichées, en moyenne 8 photos par annonce. En fait, je vais stocker ces photos dans le cloud afin que plus tard je puisse les montrer aux visiteurs sur des fiches d'objets.
Comment les ai-je conservés auparavant? - pas question. Je n'ai pas conservé d'images, sauf celles qui ont été placées manuellement. Dans la plupart des cas, les annonces arrivent sur le site via des partenaires via le téléchargement automatique de flux. Dans le flux de chaque objet, il y a des liens vers des photos - je stocke les liens et donne au visiteur une photo directement du partenaire. Ce circuit fonctionne très bien et économise une tonne de ressources.
Les photos que les visiteurs voient dans la
sélection d'annonces ou dans la
fiche de l'
objet sont en fait chargées à partir de ressources tierces.
Il y a une mise en garde liée aux spécificités du site - les objets d'archive ne sont jamais supprimés. C'est-à-dire une fois l'annonce supprimée de la publication, elle disparaît certainement des résultats de recherche, mais le lien direct est toujours disponible (sans les contacts du vendeur). Depuis quelque temps, des liens vers des photographies existent toujours, parfois pendant des années, mais tôt ou tard ils meurent. Les objets archivés sont précieux car les visiteurs des moteurs de recherche continuent de les consulter. De plus,
une carte des prix est construite à partir des archives (j'ai déjà
écrit à ce sujet ) et j'ai accidentellement découvert une source supplémentaire de revenus pour le projet sous la forme de la vente des coordonnées des objets d'archives. Pourquoi ils les achètent, je ne sais pas avec certitude, mais je suppose que les visiteurs veulent obtenir des contacts parce qu'ils pensent que l'annonce a été supprimée de la publication par accident ou par erreur. Il arrive aussi probablement qu'ils veuillent apprendre quelque chose des propriétaires précédents. D'une manière ou d'une autre, une annonce avec des photos dans ce cas est plus susceptible d'être achetée. La valeur des photographies augmente après avoir pris conscience de cette nuance.
La quantité de données que je vais stocker dans le cloud est d'environ 3 à 4 téraoctets. Plus un gain quotidien de plusieurs gigaoctets. Étant donné que cette innovation n'apportera pas directement d'argent, elle ne peut qu'affecter indirectement la prise de décision par le visiteur, le budget dans lequel je voulais rencontrer un budget très modeste est de 1000-2000 r. par mois. Ce serait bien du tout gratuitement, mais je n'ai pas trouvé une telle opportunité.
Azure
J'ai en quelque sorte immédiatement regardé vers Azure parce que je travaille sur .net et que je vois souvent de beaux articles publicitaires sur ce sujet. De plus, je dois utiliser cette plate-forme pour mon travail principal, mais là mes capacités sont limitées par les exigences de l'entreprise et les souhaits de la direction.
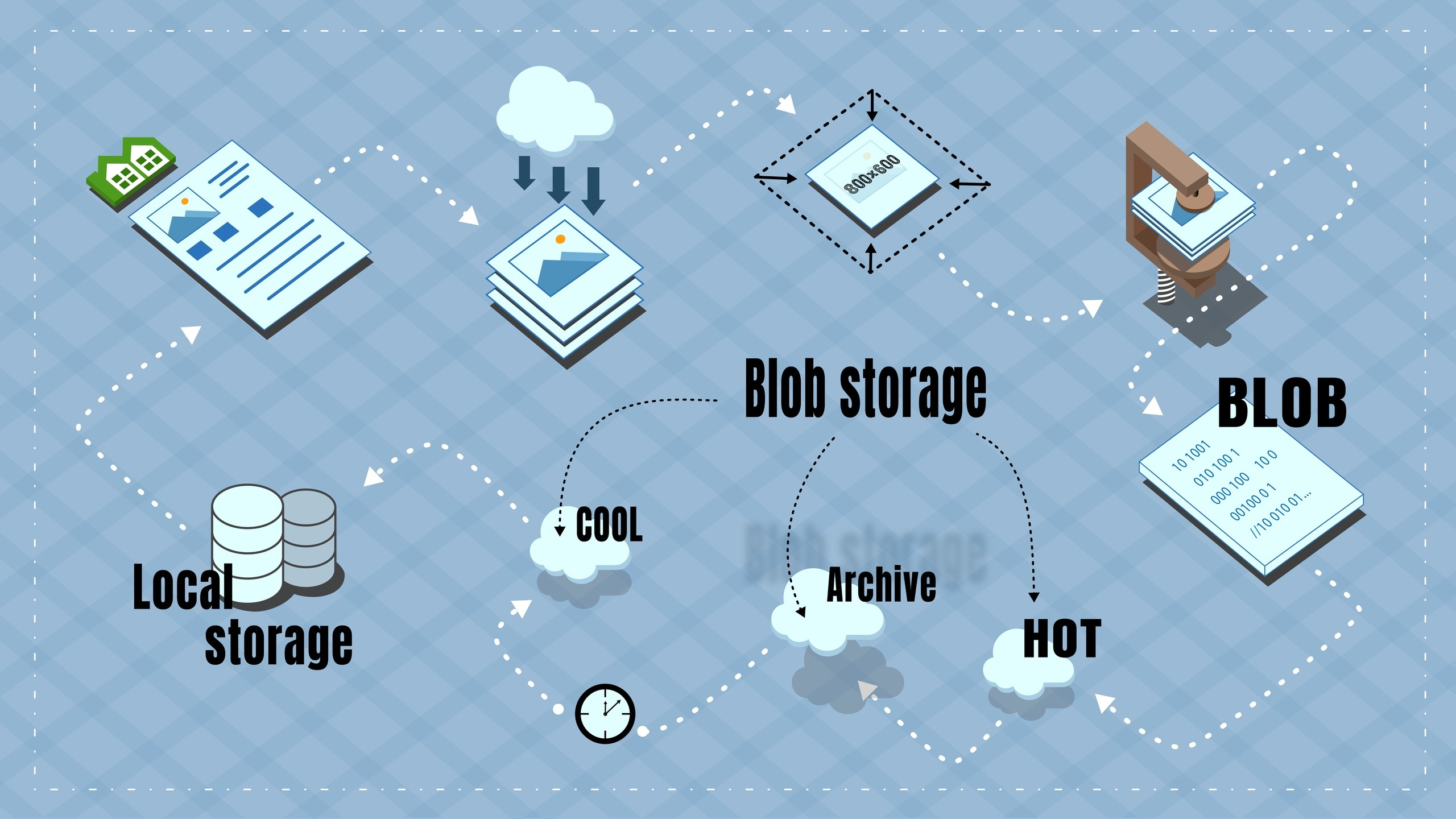
Azure propose un stockage BLOB avec trois niveaux de stockage: chaud, froid et archive. Les prix à tous les niveaux sont différents. En général, plus la lecture / l'écriture est coûteuse et moins les frais de stockage mensuels sont chers, et vice versa. Sur Hot - il est rentable d'écrire / lire et de supprimer beaucoup, mais il est coûteux de stocker pendant une longue période. Les archives sont bon marché à stocker mais coûteuses à lire / écrire. De plus, aux niveaux d'archivage et de froid, il y a des frais pour une suppression précoce - cela signifie que si je supprime (ou transfère à un autre niveau) un objet avant une certaine période, alors je serai toujours facturé pour toute cette période. Pour le niveau d'archive, c'est 180 jours, pour le froid - 30.
Les prix
Le coût de stockage est de 0,0023 $ par Go par mois au niveau de l'archive, 0,01 $ sur le froid et 0,0196 $ sur le chaud. Au taux actuel, cela représente respectivement environ 0,15, 0,65 et 1,28 roubles.
J'ai comparé au coût d'Amazon et de Google, il s'avère qu'Azure est moins cher.
En plus du coût de stockage, il est nécessaire de prendre en compte le coût des opérations - ils sont également différents à tous les niveaux. Les prix sont pour 10 000 transactions.
ChaudeLecture: 0,0043 $, écriture: 0,054 $
CoolLecture: 0,01 $, écriture: 0,10 $
ArchiveLecture: 6 $, écriture: 0,12 $
Logique de travail
Pendant que l'annonce est active, les photos qu'elle contient sont affichées par des liens provenant de ressources tierces (provenant de partenaires). Une fois l'annonce retirée de la publication, elle devient archivistique, mais les liens vers les photographies sont toujours d'actualité. Tôt ou tard, ils meurent, et vous devez vous assurer qu'à ce moment-là, il existe une copie d'archive.
Le processus de traitement des photos peut être décrit dans les étapes suivantes:
- Dès que l'annonce disparaît du fichier d'importation partenaire, c'est-à-dire le partenaire a cessé de le publier, une entrée est formée dans la file d'attente prioritaire, où la priorité est le nombre de vues par les visiteurs - plus il y a de vues, plus il est probable qu'il soit archivé, l'objet sera vu plus loin.
- Lors du traitement d'un enregistrement de la file d'attente, un objet BLOB est formé contenant des photos réduites (jusqu'à 800x600) pour la publicité. L'utilisation d'objets composites au lieu de photographies directes est également due à des économies - au lieu de 8 opérations d'enregistrement (en moyenne 8 photos par objet), une est effectuée et chaque opération coûte de l'argent.
- BLOB est d'abord chargé dans Hot, puis immédiatement transféré dans l'archive. Il n'y a aucune possibilité d'écrire directement dans l'archive, et puisque Cool a des frais pour une suppression précoce, il est moins cher d'utiliser Hot comme transit.
- L'archive BLOB est aussi longue que les liens vers les photos originales sont actifs (les photos sont jusqu'à présent affichées par des liens de partenaires).
- La fonctionnalité des liens est vérifiée lorsque le visiteur visite la carte de l’objet - s’ils y accèdent, alors l’objet est populaire et il est logique de restaurer les photos de l’archive.
- Si les liens vers les photos originales sont morts, je vérifie s'il existe une copie d'archive et, dans l'affirmative, j'envoie une demande de restauration à partir de l'archive vers Cool (cela peut prendre jusqu'à 15 heures pour restaurer un blob à partir de l'archive - cela s'appelle la réhydratation de Microsoft).
- Une fois le BLOB restauré à partir de l'archive, il est copié sur le stockage local et divisé en photos normales. Le stockage local est le disque dur de mon serveur.
- Les photos sur la carte d'annonce sont déjà données à partir du stockage local.
- Les photos sont stockées dans le stockage local pendant plusieurs jours. Si pendant ce temps il y a eu des analyses, la période de stockage local est prolongée. S'il n'y avait pas de vues, les photos sont supprimées du stockage local, mais restent au niveau Cool dans Azure.
- De Cool à Archive, ils sont copiés s'il n'y a pas eu de vues pendant deux mois - l'objet n'est clairement pas populaire et, en conséquence, cela n'a aucun sens de surpayer pour le stockage dans Cool.
Premier lancement
Lorsque le processus a été écrit et testé, il était temps de procéder à l'essai et il y avait des problèmes attendus. Dans la file d'attente à cette époque, il y avait environ 10 millions d'objets, j'ai décidé de démarrer la migration à partir de 30 000 objets par jour. Mettre en place de beaux graphiques sur le tableau de bord et a commencé à observer. Dans les statistiques, j'ai vu d'étranges «fentes» avec des demandes GetBlobProperties. Ils se produisent avec un intervalle approximativement égal d'une heure, commencent toujours environ une heure et demie après le début de la migration et durent un certain temps après son achèvement.
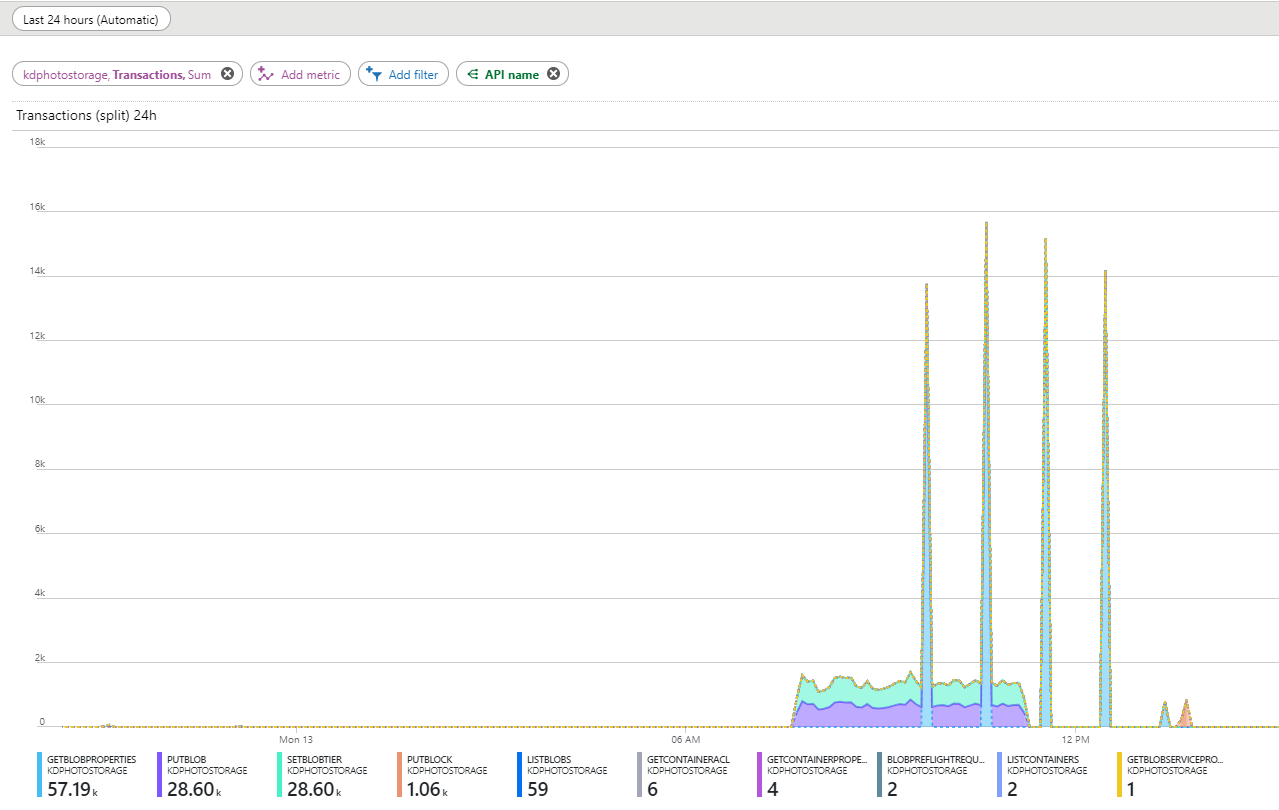
Le nombre de ces demandes était trop important pour les ignorer. J'ai regardé les journaux et j'ai vu que ces demandes ne provenaient pas de mon serveur mais d'adresses IP étrangères. Je ne voulais pas du tout les payer.
J'ai cherché sur la pile et dans la documentation, mais en vain. A écrit une
question sur Stackoverflow et le support technique. En conséquence, après une longue correspondance avec le support technique et en leur fournissant des journaux, ils m'ont dit qu'ils pouvaient reproduire la situation et c'est un bug de leur côté.
Une nuance intéressante est que ma question sur Stackoverflow a été répondue sans expliquer les raisons, mais confirmant seulement que je paierai pour ces demandes, mais la personne qui a donné la réponse m'a demandé avec insistance de la marquer comme correcte. Il a également laissé entendre en me passant qu'ils (à l'appui) ne sont pas les bienvenus pour diffuser des bogues dans leurs propres produits. Je lui ai fait savoir que je ne le ferais pas tant qu'il n'aurait pas écrit la vérité. Je pouvais écrire cela moi-même, mais je pensais que le personnel du support technique avait probablement mesuré le nombre de réponses confirmées, alors je lui ai demandé d'écrire la vraie raison et dans ce cas, j'ai marqué sa réponse comme correcte. Après quelques hésitations, il a accepté et complété son commentaire par un rapport de bug. En général, j'ai aimé le fonctionnement du support technique - j'ai même été transféré à une fille russe qui me tient toujours au courant des changements sur cette question.
Le fait que le bug ait été reconnu ne me satisfaisait que moralement, mais je voulais mettre le mécanisme en service, et en même temps ne pas payer d'argent pour les demandes gauchers. Surtout étant donné que je me trompais normalement afin de minimiser le nombre de demandes et donc le coût.
Dans le support technique, on m'a conseillé d'attendre le lancement et après quelques semaines, ils ont écrit que le bogue avait été corrigé, mais quand la version avec le correctif sera, elle n'est pas connue. Ils ont proposé d'activer la journalisation et de travailler comme ça, et après la publication, demander une compensation dans Microsoft. En fait, dans ce mode, cela fonctionne toujours. Chaque jour, je lance une migration d'un petit nombre d'objets et j'attends la sortie.
Conclusion
Le coût de 30 000 objets par jour est toujours de 900 p. par mois - et c'est tout à fait acceptable. La plupart des dépenses sont des opérations d'écriture. Ainsi, lorsque toute la file d'attente est traitée et que l'étape du travail planifié commence, il sera clair quel est le coût réel d'un tel stockage. Mais selon mes calculs, cela arrivera dans environ un an.
Lorsqu'il y aura une version dans Azure Blob-storage, j'ajouterai ici si j'ai réussi à obtenir une compensation. En ce qui concerne les dépenses mensuelles, cela représente environ 10% du coût.