Salut habr.
Le thème des "carrés magiques" est assez intéressant, car d'une part, ils sont connus depuis l'Antiquité, d'autre part, le calcul du "carré magique" est encore aujourd'hui une tâche de calcul très difficile. Rappelez-vous que pour construire un «carré magique» NxN, vous devez entrer les nombres 1..N * N de sorte que la somme de ses horizontales, verticales et diagonales soit égale au même nombre. Si vous triez simplement le nombre de toutes les options pour organiser les nombres pour un carré 4x4, nous obtenons 16! = 20 922 789 888 000 options.
Considérez comment cela peut être fait plus efficacement.

Pour commencer, nous répétons l'état du problème. Vous devez organiser les nombres dans un carré afin qu'ils ne se répètent pas, et la somme des horizontales, verticales et diagonales était égale au même nombre.
Il est facile de prouver que cette somme est toujours la même et est calculée par la formule pour tout n:
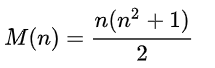
Nous considérerons des carrés 4x4, donc la somme = 34.
Désignons toutes les variables par X, notre carré ressemblera à ceci:
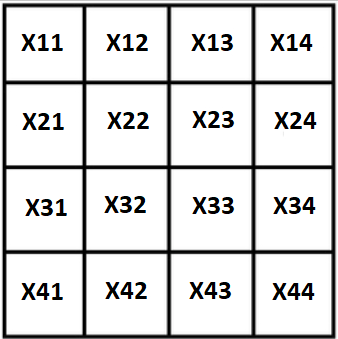
La première et évidente propriété: la somme du carré est connue, les stoblts extrêmes peuvent être exprimés par les 3 restants:
X14 = S - X11 - X12 - X13
X24 = S - X21 - X22 - X23
...
X41 = S - X11 - X21 - X31Ainsi, un carré 4x4 se transforme en fait en carré 3x3, ce qui réduit le nombre d'options de recherche de 16! jusqu'à 9!, soit 57 millions de fois. Sachant cela, nous commençons à écrire du code, voyez à quel point une recherche aussi exhaustive des ordinateurs modernes est compliquée.
C ++ - version simple thread
Le principe du programme est très simple. Nous prenons l'ensemble des nombres 1..16 et la boucle for sur cet ensemble, ce sera x11. Ensuite, nous prenons le deuxième ensemble, composé du premier à l'exception du nombre x11, et ainsi de suite.
Une forme approximative du programme ressemble à ceci:
int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; ... int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue;
Le texte complet du programme se trouve sous le spoiler.
Source entière #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); for (int x11 = 1; x11 <= MAX; x11++) { Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
Résultat: un total de
7040 options de «carrés magiques» 4x4 ont été trouvées, et le temps de recherche était de
102s .

Soit dit en passant, il est intéressant de vérifier si la liste des carrés contient la même que celle représentée sur la gravure de Durer. Bien sûr, car le programme affiche
tous les carrés 4x4:
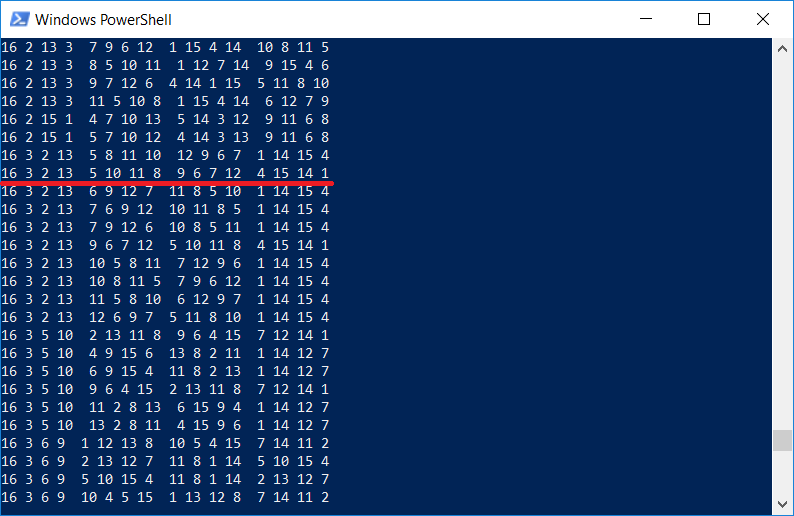
Il convient de noter que Dürer a inséré un carré dans l'image pour une raison, les chiffres
1514 indiquent également l'année de la gravure.
Comme vous pouvez le voir, le programme fonctionne (nous marquons la tâche comme vérifiée à 1514 par Albrecht Dürer;), cependant, le temps d'exécution n'est pas si petit pour un ordinateur avec un processeur Core i7. De toute évidence, le programme s'exécute dans un seul thread, et il est conseillé d'utiliser tous les autres noyaux.
C ++ - version multi-thread
La réécriture d'un programme à l'aide de flux est fondamentalement simple, quoique un peu lourde. Heureusement, il existe aujourd'hui une option presque oubliée: l'utilisation de la prise en charge d'
OpenMP (Open Multi-Processing). Cette technologie existe depuis 1998 et permet aux directives du processeur d'indiquer au compilateur les parties du programme à exécuter en parallèle. OpenMP est également pris en charge dans Visual Studio, donc pour transformer un programme en multi-thread, ajoutez simplement une ligne au code:
int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { ... } printf("CNT: %d\n", squares);
La
directive #pragma omp parallel for indique que la prochaine boucle for peut être exécutée en parallèle, et les carrés de paramètres supplémentaires définissent le nom de la variable, qui sera commun aux threads parallèles (sans cela, l'incrément ne fonctionne pas correctement).
Le résultat est évident: le temps d'exécution est passé de 102s à
18s .

Source entière #include <set> #include <stdio.h> #include <ctime> #include "stdafx.h" typedef std::set<int> Set; typedef Set::iterator SetIterator; #define N 4 #define MAX (N*N) #define S 34 int main(int argc, char *argv[]) { // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 const clock_t begin_time = clock(); int squares = 0; #pragma omp parallel for reduction(+: squares) for (int x11 = 1; x11 <= MAX; x11++) { int digits[] = { 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 }; Set mset(digits, digits + N*N); Set set12(mset); set12.erase(x11); for (SetIterator it12 = set12.begin(); it12 != set12.end(); it12++) { int x12 = *it12; Set set13(set12); set13.erase(x12); for (SetIterator it13 = set13.begin(); it13 != set13.end(); it13++) { int x13 = *it13; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) continue; if (x14 == x11 || x14 == x12 || x14 == x13) continue; Set set21(set13); set21.erase(x13); set21.erase(x14); for (SetIterator it21 = set21.begin(); it21 != set21.end(); it21++) { int x21 = *it21; Set set22(set21); set22.erase(x21); for (SetIterator it22 = set22.begin(); it22 != set22.end(); it22++) { int x22 = *it22; Set set23(set22); set23.erase(x22); for (SetIterator it23 = set23.begin(); it23 != set23.end(); it23++) { int x23 = *it23, x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; Set set31(set23); set31.erase(x23); set31.erase(x24); for (SetIterator it31 = set31.begin(); it31 != set31.end(); it31++) { int x31 = *it31; Set set32(set31); set32.erase(x31); for (SetIterator it32 = set32.begin(); it32 != set32.end(); it32++) { int x32 = *it32; Set set33(set32); set33.erase(x32); for (SetIterator it33 = set33.begin(); it33 != set33.end(); it33++) { int x33 = *it33, x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x41 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); squares++; } } } } } } } } } printf("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); return 0; }
C'est beaucoup mieux - car la tâche est presque parfaitement parallélisée (les calculs dans chaque branche sont indépendants les uns des autres), le temps est inférieur au nombre de fois égal au nombre de cœurs de processeur. Mais hélas, il
n'est pas possible de tirer le meilleur parti de ce code, même si quelques pour cent peuvent et peuvent être gagnés par certaines optimisations. On passe à l'artillerie plus lourde, calculs sur le GPU.
Calculer avec NVIDIA CUDA
Si vous n'entrez pas dans les détails, le processus de calcul qui est effectué sur la carte vidéo peut être représenté comme plusieurs blocs matériels parallèles (blocs), chacun exécutant plusieurs processus (threads).
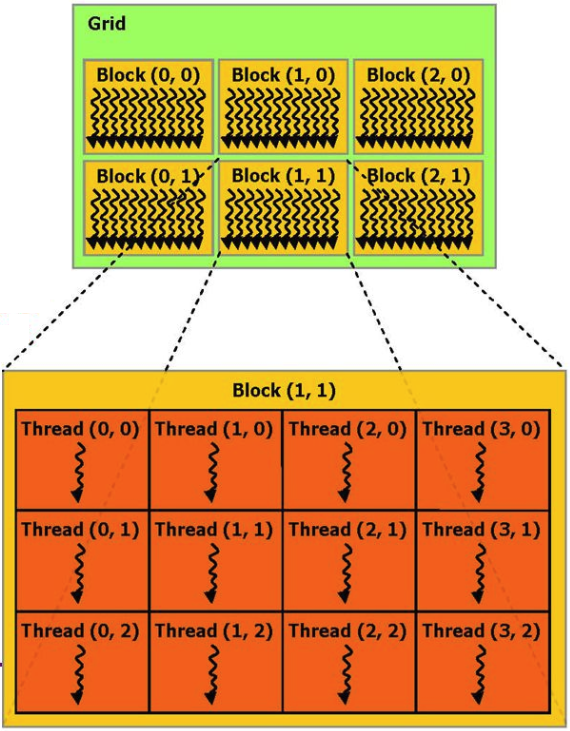
Par exemple, nous pouvons donner un exemple de la fonction d'ajout de 2 vecteurs de la documentation CUDA:
__global__ void add(int n, float *x, float *y) { int index = threadIdx.x; int stride = blockDim.x; for (int i = index; i < n; i += stride) y[i] = x[i] + y[i]; }
Les tableaux x et y sont communs à tous les blocs, et la fonction elle-même est donc exécutée simultanément sur plusieurs processeurs à la fois. La clé ici est le parallélisme - les processeurs de carte vidéo sont beaucoup plus simples qu'un processeur ordinaire, mais ils sont nombreux et se concentrent spécifiquement sur le traitement des données numériques.
Voilà ce dont nous avons besoin. Nous avons une matrice de nombres X11, X12, .., X44. Commençons le processus de 16 blocs, chacun exécutant 16 processus. Le numéro de bloc correspondra au numéro X11, le numéro de processus au numéro X12, et le code lui-même calculera tous les carrés possibles avec pour les X11 et X12 sélectionnés. C'est simple, mais il y a une subtilité - les données doivent non seulement être calculées, mais également transférées de la carte vidéo, pour cela, nous allons stocker le nombre de carrés trouvés dans l'élément zéro du tableau.
Le code principal est très simple:
#define N 4 #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) int main(int argc,char *argv[]) { const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
Nous sélectionnons le bloc de mémoire sur la carte vidéo en utilisant cudaMalloc, exécutons la fonction carrés, indiquant 2 paramètres 16.16 (le nombre de blocs et le nombre de threads) correspondant aux nombres 1..16 itérés, puis copions les données via cudaMemcpy.
La fonction carrés elle-même répète essentiellement le code de la partie précédente, à la différence près que l'incrément du nombre de carrés trouvés se fait en utilisant atomicAdd - cela garantit que la variable changera correctement lors d'appels simultanés.
Le résultat ne nécessite aucun commentaire - le temps d'exécution était de
2,7 s , ce qui est environ 30 fois meilleur que la version initiale à un seul thread:

Comme suggéré dans les commentaires, vous pouvez utiliser encore plus de blocs matériels de la carte vidéo, donc l'option de 256 blocs a été essayée. Changer le code est minime:
__global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX; ... } squares<<<MAX*MAX, 1>>>(gpu_out);
Cela a réduit le temps encore 2 fois, à
1,2 s . De plus, sur chaque bloc, 16 processus peuvent être démarrés, ce qui donne le meilleur temps de
0,44 s .
Code final #include <stdio.h> #include <ctime> #define N 4 #define MAX (N*N) #define SQ_MAX 8*1024 #define BLOCK_SIZE (SQ_MAX*N*N + 1) #define S 34 // Magic square: // x11 x12 x13 x14 // x21 x22 x23 x24 // x31 x32 x33 x34 // x41 x42 x43 x44 __global__ void squares(int *res_array) { int index1 = blockIdx.x/MAX, index2 = blockIdx.x%MAX, index3 = threadIdx.x; if (index1 + 1 > MAX || index2 + 1 > MAX || index3 + 1 > MAX) return; const int x11 = index1+1, x12 = index2+1, x13 = index3+1; if (x13 == x11 || x13 == x12) return; int x14 = S - x11 - x12 - x13; if (x14 < 1 || x14 > MAX) return; if (x14 == x11 || x14 == x12 || x14 == x13) return; for(int x21=1; x21<=MAX; x21++) { if (x21 == x11 || x21 == x12 || x21 == x13 || x21 == x14) continue; for(int x22=1; x22<=MAX; x22++) { if (x22 == x11 || x22 == x12 || x22 == x13 || x22 == x14 || x22 == x21) continue; for(int x23=1; x23<=MAX; x23++) { int x24 = S - x21 - x22 - x23; if (x24 < 1 || x24 > MAX) continue; if (x23 == x11 || x23 == x12 || x23 == x13 || x23 == x14 || x23 == x21 || x23 == x22) continue; if (x24 == x11 || x24 == x12 || x24 == x13 || x24 == x14 || x24 == x21 || x24 == x22 || x24 == x23) continue; for(int x31=1; x31<=MAX; x31++) { if (x31 == x11 || x31 == x12 || x31 == x13 || x31 == x14 || x31 == x21 || x31 == x22 || x31 == x23 || x31 == x24) continue; for(int x32=1; x32<=MAX; x32++) { if (x32 == x11 || x32 == x12 || x32 == x13 || x32 == x14 || x32 == x21 || x32 == x22 || x32 == x23 || x32 == x24 || x32 == x31) continue; for(int x33=1; x33<=MAX; x33++) { int x34 = S - x31 - x32 - x33; if (x34 < 1 || x34 > MAX) continue; if (x33 == x11 || x33 == x12 || x33 == x13 || x33 == x14 || x33 == x21 || x33 == x22 || x33 == x23 || x33 == x24 || x33 == x31 || x33 == x32) continue; if (x34 == x11 || x34 == x12 || x34 == x13 || x34 == x14 || x34 == x21 || x34 == x22 || x34 == x23 || x34 == x24 || x34 == x31 || x34 == x32 || x34 == x33) continue; const int x41 = S - x11 - x21 - x31, x42 = S - x12 - x22 - x32, x43 = S - x13 - x23 - x33, x44 = S - x14 - x24 - x34; if (x41 < 1 || x41 > MAX || x42 < 1 || x42 > MAX || x43 < 1 || x43 > MAX || x44 < 1 || x44 > MAX) continue; if (x41 == x11 || x41 == x12 || x41 == x13 || x41 == x14 || x41 == x21 || x41 == x22 || x41 == x23 || x41 == x24 || x41 == x31 || x41 == x32 || x41 == x33 || x41 == x34) continue; if (x42 == x11 || x42 == x12 || x42 == x13 || x42 == x14 || x42 == x21 || x42 == x22 || x42 == x23 || x42 == x24 || x42 == x31 || x42 == x32 || x42 == x33 || x42 == x34 || x42 == x41) continue; if (x43 == x11 || x43 == x12 || x43 == x13 || x43 == x14 || x43 == x21 || x43 == x22 || x43 == x23 || x43 == x24 || x43 == x31 || x43 == x32 || x43 == x33 || x43 == x34 || x43 == x41 || x43 == x42) continue; if (x44 == x11 || x44 == x12 || x44 == x13 || x44 == x14 || x44 == x21 || x44 == x22 || x44 == x23 || x44 == x24 || x44 == x31 || x44 == x32 || x44 == x33 || x44 == x34 || x44 == x41 || x44 == x42 || x44 == x43) continue; int sh1 = x11 + x12 + x13 + x14, sh2 = x21 + x22 + x23 + x24, sh3 = x31 + x32 + x33 + x34, sh4 = x41 + x42 + x43 + x44; int sv1 = x11 + x21 + x31 + x41, sv2 = x12 + x22 + x32 + x42, sv3 = x13 + x23 + x33 + x43, sv4 = x14 + x24 + x34 + x44; int sd1 = x11 + x22 + x33 + x44, sd2 = x14 + x23 + x32 + x41; if (sh1 != S || sh2 != S || sh3 != S || sh4 != S || sv1 != S || sv2 != S || sv3 != S || sv4 != S || sd1 != S || sd2 != S) continue; // Square found: save in array (MAX numbers for each square) int p = atomicAdd(res_array, 1); if (p >= SQ_MAX) continue; int i = MAX*p + 1; res_array[i] = x11; res_array[i+1] = x12; res_array[i+2] = x13; res_array[i+3] = x14; res_array[i+4] = x21; res_array[i+5] = x22; res_array[i+6] = x23; res_array[i+7] = x24; res_array[i+8] = x31; res_array[i+9] = x32; res_array[i+10] = x33; res_array[i+11] = x34; res_array[i+12]= x41; res_array[i+13]= x42; res_array[i+14] = x43; res_array[i+15] = x44; // Warning: printf from kernel makes calculation 2-3x slower // printf("%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d\n", x11, x12, x13, x14, x21, x22, x23, x24, x31, x32, x33, x34, x41, x42, x43, x44); } } } } } } } int main(int argc,char *argv[]) { int *gpu_out = NULL; cudaMalloc(&gpu_out, BLOCK_SIZE*sizeof(int)); const clock_t begin_time = clock(); int *results = (int*)malloc(BLOCK_SIZE*sizeof(int)); results[0] = 0; cudaMemcpy(gpu_out, results, BLOCK_SIZE*sizeof(int), cudaMemcpyHostToDevice); squares<<<MAX*MAX, MAX>>>(gpu_out); cudaMemcpy(results, gpu_out, BLOCK_SIZE*sizeof(int), cudaMemcpyDeviceToHost); // Print results int squares = results[0]; for(int p=0; p<SQ_MAX && p<squares; p++) { int i = MAX*p + 1; printf("[%d %d %d %d %d %d %d %d %d %d %d %d %d %d %d %d]\n", results[i], results[i+1], results[i+2], results[i+3], results[i+4], results[i+5], results[i+6], results[i+7], results[i+8], results[i+9], results[i+10], results[i+11], results[i+12], results[i+13], results[i+14], results[i+15]); } printf ("CNT: %d\n", squares); float diff_t = float(clock() - begin_time)/CLOCKS_PER_SEC; printf("T = %.2fs\n", diff_t); cudaFree(gpu_out); free(results); return 0; }
Très probablement, cela est loin d'être idéal, par exemple, vous pouvez exécuter encore plus de blocs sur le GPU, mais cela rendra le code plus confus et difficile à comprendre. Et bien sûr, les calculs ne sont pas «gratuits» - lorsque le GPU est chargé, l'interface Windows commence à ralentir sensiblement et la consommation électrique de l'ordinateur augmente presque 2 fois, de 65 à 130 W.
Edit : comme l'a
suggéré l' utilisateur
Bodigrim dans les commentaires, une égalité de plus vaut pour un carré 4x4: la somme de 4 cellules «internes» est égale à la somme des cellules «externes», c'est aussi S.

X22 + X23 + X32 + X33 = X11 + X41 + X14 + X44 = S, 1-2 , .
Conclusion
« » , . GPU 55 , 77 , .
, :
- « » N. 22 , 33 8 ( 1, ), 44 , 7040, . .
- , .
- . , NVIDIA Tesla , - , . , . , ;)
, .
PS: , , « ». , ? , .