L'un est nul en faveur du cerveau humain. Dans une
nouvelle étude , des informaticiens ont découvert que les systèmes d'intelligence artificielle ne réussissent pas le test de reconnaissance visuelle des objets que tout enfant peut facilement manipuler.
«Cette étude qualitative et importante nous rappelle que le« deep learning »lui-même ne peut pas se vanter de la profondeur qui lui est attribuée», explique Gary Marcus, neuroscientifique à l'Université de New York qui n'est pas associé à ce travail.
Les résultats de l'étude concernent le domaine de la vision par ordinateur, lorsque les systèmes d'intelligence artificielle tentent de détecter et de catégoriser des objets. Par exemple, on peut leur demander de trouver tous les piétons dans la scène de rue ou simplement de distinguer un oiseau d'un vélo - une tâche qui est déjà devenue célèbre pour sa complexité.
L'enjeu est de taille: les ordinateurs commencent progressivement à effectuer des opérations importantes pour les personnes, comme la vidéosurveillance automatique et la conduite autonome. Et pour un travail réussi, il est nécessaire que la capacité de l'IA au traitement visuel ne soit au moins pas inférieure à celle de l'homme.
La tâche n'est pas facile.
La nouvelle étude se concentre sur la sophistication de la vision humaine et les difficultés à créer des systèmes d'imitation. Les scientifiques ont testé la précision d'un système de vision par ordinateur en utilisant l'exemple d'un salon. AI a bien fait, identifiant correctement la chaise, la personne et les livres sur l'étagère. Mais lorsque les scientifiques ont ajouté un objet inhabituel à la scène - l'image d'un éléphant - le fait même de son apparence a fait oublier au système tous les résultats précédents. Soudain, elle a commencé à appeler la chaise un canapé, l'éléphant une chaise et à ignorer tous les autres objets.
«Il y avait une variété de bizarreries qui montraient la fragilité des systèmes modernes de détection d'objets», explique Amir Rosenfeld, scientifique de l'Université York à Toronto et co-auteur d'une étude que lui et ses collègues
John Totsotsos , également de York, et
Richard Zemel de l'Université de Toronto.
Les chercheurs tentent toujours de clarifier les raisons pour lesquelles le système de vision par ordinateur est si facilement dérouté, et ils ont déjà une bonne supposition. Le point de compétence humaine, que l'IA n'a pas, est la capacité de réaliser que la scène est incompréhensible, et nous devons y réfléchir de plus près.
Éléphant dans la chambre
En regardant le monde, nous percevons une quantité stupéfiante d'informations visuelles. Le cerveau humain le traite en déplacement. «Nous ouvrons les yeux et tout se passe tout seul», explique Totsotsos.
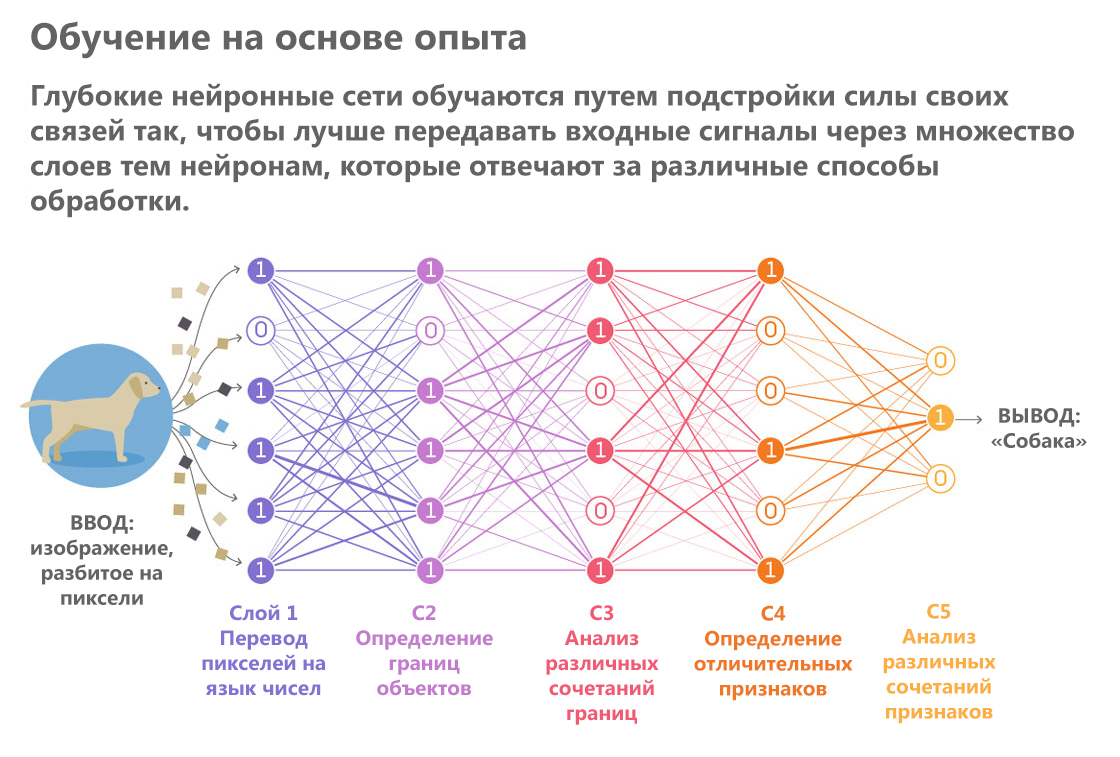
L'intelligence artificielle, en revanche, crée une impression visuelle minutieusement, comme si elle lisait une description en braille. Il parcourt le bout de ses doigts algorithmiques à travers les pixels, en formant progressivement à partir d'eux des représentations de plus en plus complexes. Une variété de systèmes d'IA qui exécutent des processus similaires sont les réseaux de neurones. Ils passent une image à travers une série de «couches». Au fur et à mesure que chaque couche passe, des détails d'image individuels, tels que la couleur et la luminosité de pixels individuels, sont traités et une description de plus en plus abstraite de l'objet est formée sur la base de cette analyse.
«Les résultats du traitement de la couche précédente sont transférés à la suivante, et ainsi de suite, comme sur un convoyeur», explique Totsotsos.
 Publié par: Lucy Reading-Ikkanda / Quanta Magazine
Publié par: Lucy Reading-Ikkanda / Quanta MagazineLes réseaux de neurones sont des experts dans des tâches de routine spécifiques dans le domaine du traitement visuel. Ils sont meilleurs que les humains pour faire face à des tâches hautement spécialisées telles que la détermination de la race de chiens et d'autres tri d'objets en catégories. Ces exemples réussis ont fait naître l'espoir que les systèmes de vision par ordinateur deviendront bientôt si intelligents qu'ils pourront conduire une voiture dans les rues bondées de la ville.
Cela a également incité des experts à explorer leurs vulnérabilités. Au cours des dernières années, les chercheurs ont tenté à plusieurs reprises de simuler des attaques hostiles - ils ont proposé des scénarios qui obligent les réseaux de neurones à commettre des erreurs. Dans une expérience, des informaticiens ont
trompé le réseau, l'obligeant à prendre la tortue pour une arme à feu. Une autre histoire de tricherie réussie était que, à côté d'objets ordinaires comme une banane, les chercheurs ont
placé un grille-pain peint en couleurs psychédéliques sur l'image.
Dans le nouveau travail, les scientifiques ont choisi la même approche. Trois chercheurs ont montré une photographie du réseau neuronal d'un salon. Il capture un homme qui joue à un jeu vidéo, assis sur le bord d'une vieille chaise et se penchant en avant. "Digérant" cette scène, AI a rapidement reconnu plusieurs objets: une personne, un canapé, une télévision, une chaise et quelques livres.
Ensuite, les chercheurs ont ajouté un objet inhabituel pour des scènes similaires: une image d'un éléphant dans un demi-profil. Et le réseau neuronal est confus. Dans certains cas, l'apparition d'un éléphant l'a forcée à prendre une chaise pour un canapé, et parfois le système a cessé de voir certains objets, avec la reconnaissance de qui auparavant il n'y avait pas de problèmes. Ceci, par exemple, est une série de livres. De plus, des échecs sont survenus même avec des objets situés loin de l'éléphant.
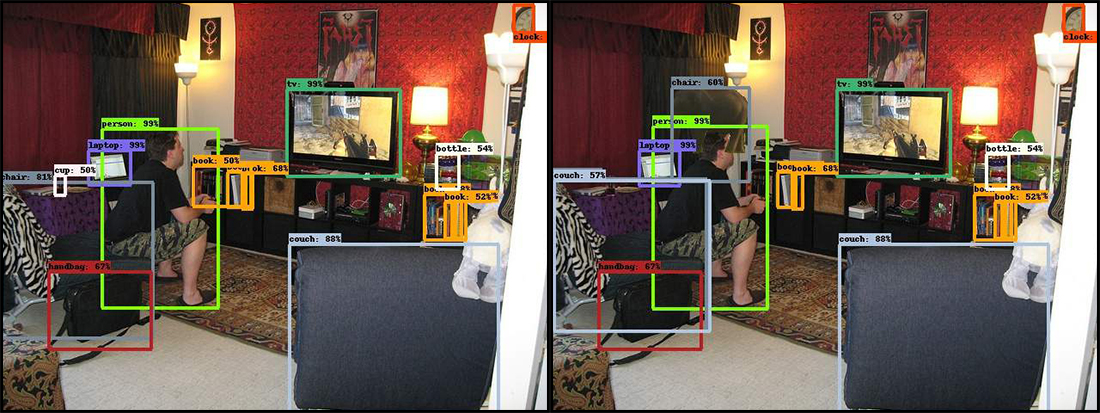 Sur l'original à gauche, le réseau de neurones a identifié correctement et avec une grande confiance de nombreux objets situés dans le salon plein de choses diverses. Mais dès que l'éléphant a été ajouté (image à droite), le programme a commencé à planter. La chaise dans le coin inférieur gauche s'est transformée en canapé, la tasse à côté d'elle a disparu et l'éléphant est devenu une chaise.
Sur l'original à gauche, le réseau de neurones a identifié correctement et avec une grande confiance de nombreux objets situés dans le salon plein de choses diverses. Mais dès que l'éléphant a été ajouté (image à droite), le programme a commencé à planter. La chaise dans le coin inférieur gauche s'est transformée en canapé, la tasse à côté d'elle a disparu et l'éléphant est devenu une chaise.Des erreurs de système similaires sont totalement inacceptables pour la même conduite autonome. L'ordinateur ne pourra pas conduire la voiture s'il ne remarque pas les piétons simplement parce que quelques secondes auparavant il a vu une dinde sur le bord de la route.
Quant à l'éléphant lui-même, les résultats de sa reconnaissance diffèrent également d'une tentative à l'autre. Le système l'a ensuite déterminé correctement, parfois appelé mouton, puis ne l'a pas remarqué du tout.
"Si un éléphant apparaît vraiment dans la pièce, n'importe qui le remarquera probablement", explique Rosenfeld. "Et le système n'a même pas enregistré sa présence."
Relation étroite
Lorsque les gens voient quelque chose d'inattendu, ils le regardent mieux. Aussi simple que cela puisse paraître, «regardez de plus près», cela a de réelles conséquences cognitives et explique pourquoi l'IA se trompe quand quelque chose d'inhabituel apparaît.
Lors du traitement et de la reconnaissance d'objets, les meilleurs réseaux de neurones modernes ne transmettent les informations d'eux-mêmes que vers l'avant. Ils commencent par sélectionner des pixels à l'entrée, puis passent aux courbes, formes et scènes, et font les suppositions les plus probables à chaque étape. Toute idée fausse dans les premières étapes du processus conduit à des erreurs à la fin lorsque le réseau neuronal rassemble ses «pensées» pour deviner ce qu'il regarde.
"Dans les réseaux de neurones, tous les processus sont étroitement interconnectés les uns aux autres, il est donc toujours possible que n'importe quelle fonctionnalité n'importe où puisse affecter n'importe quel résultat possible", explique Totsosos.
L'approche humaine est meilleure. Imaginez que l'on vous donne un rapide coup d'œil sur une image qui a un cercle et un carré, l'un rouge, l'autre bleu. Après cela, on vous a demandé de nommer la couleur du carré. Un bref coup d'œil peut ne pas être suffisant pour se souvenir correctement des couleurs. Vient immédiatement la compréhension que vous n'êtes pas sûr et que vous devez regarder à nouveau. Et, ce qui est très important, lors de la deuxième visualisation, vous saurez déjà sur quoi vous devez vous concentrer.
"Le système visuel humain dit:" Je ne peux toujours pas donner la bonne réponse, je vais donc revenir en arrière et vérifier où l'erreur aurait pu se produire ", explique Totsotsos, qui développe une théorie appelée"
harmonisation sélective "qui explique cette caractéristique de la perception visuelle.
La plupart des réseaux de neurones n'ont pas la possibilité de revenir en arrière. Cette fonctionnalité est très difficile à concevoir. L'un des avantages des réseaux unidirectionnels est qu'ils sont relativement faciles à former - il suffit de «passer» les images à travers les six couches mentionnées et d'obtenir le résultat. Mais si les réseaux de neurones doivent «regarder de près», ils doivent également faire la distinction entre une ligne fine, quand il vaut mieux revenir en arrière et quand continuer à travailler. Le cerveau humain bascule facilement et naturellement entre ces différents processus. Et les réseaux de neurones ont besoin d'une nouvelle base théorique pour pouvoir faire de même.
D'éminents chercheurs du monde entier travaillent dans ce sens, mais ils ont également besoin d'aide. Récemment, le projet Google AI a
annoncé un concours pour les classificateurs d'images de crowdsourcing qui peuvent distinguer les cas de distorsion d'image intentionnelle. La solution qui permet de distinguer clairement l'image de l'oiseau de l'image du vélo l'emportera. Ce sera une première étape modeste mais très importante.
