Enron Corporation est l'une des figures les plus célèbres des affaires américaines dans les années 2000. Cela n'a pas été facilité par leur domaine d'activité (électricité et contrats de fourniture), mais par la résonance due à la fraude. Depuis 15 ans, les revenus des entreprises ont augmenté rapidement et leur emploi leur a promis un bon salaire. Mais tout s'est terminé de manière tout aussi fugace: dans la période 2000-2001. le cours de l'action est tombé de 90 $ / unité à presque zéro en raison d'une fraude révélée sur les revenus déclarés. Depuis lors, le mot «Enron» est devenu un mot familier et agit comme un label pour les entreprises qui fonctionnent dans un modèle similaire.
Au cours du procès, 18 personnes (dont les plus grands accusés dans cette affaire: Andrew Fastov, Jeff Skilling et Kenneth Lay) ont été condamnées.
![image! [image] (http: // https: //habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)](https://habrastorage.org/webt/te/rh/1l/terh1lsenbtg26n8nhjbhv3opfi.jpeg)
Dans le même temps, une archive de correspondance électronique entre les employés de l'entreprise, mieux connue sous le nom d'Enron Email Dataset, et des informations privilégiées sur les revenus des employés de cette entreprise ont été publiées.
L'article examinera les sources de ces données et construira un modèle basé sur celles-ci pour déterminer si une personne est suspectée de fraude. Cela semble intéressant? Alors, bienvenue à habrakat.
Description de l'ensemble de données
Le jeu de données Enron (jeu de données) est un ensemble composite de données ouvertes qui contient des enregistrements de personnes travaillant dans une société mémorable avec le nom correspondant.
Il peut distinguer 3 parties:
- paiements_fonctionnalités - un groupe qui caractérise les mouvements financiers;
- stock_features - un groupe qui reflète les signes associés aux stocks;
- email_features - un groupe qui reflète les informations sur les e-mails d'une personne particulière sous une forme agrégée.
Bien entendu, il existe également une variable cible qui indique si la personne est soupçonnée de fraude (signe «poi» ).
Téléchargez nos données et commencez à travailler avec elles:
import pickle with open("final_project/enron_dataset.pkl", "rb") as data_file: data_dict = pickle.load(data_file)
Après cela, nous transformons l'ensemble data_dict en un cadre de données Pandas pour un travail plus pratique avec les données:
import pandas as pd import warnings warnings.filterwarnings('ignore') source_df = pd.DataFrame.from_dict(data_dict, orient = 'index') source_df.drop('TOTAL',inplace=True)
Nous regroupons les panneaux selon les types indiqués précédemment. Cela devrait faciliter le travail avec les données par la suite:
payments_features = ['salary', 'bonus', 'long_term_incentive', 'deferred_income', 'deferral_payments', 'loan_advances', 'other', 'expenses', 'director_fees', 'total_payments'] stock_features = ['exercised_stock_options', 'restricted_stock', 'restricted_stock_deferred','total_stock_value'] email_features = ['to_messages', 'from_poi_to_this_person', 'from_messages', 'from_this_person_to_poi', 'shared_receipt_with_poi'] target_field = 'poi'
Données financières
Dans cet ensemble de données, il existe un NaN connu de beaucoup, et il exprime l'écart habituel dans les données. En d'autres termes, l'auteur de l'ensemble de données n'a pu trouver aucune information sur un attribut particulier associé à une ligne particulière dans le bloc de données. En conséquence, nous pouvons supposer que NaN est 0, car il n'y a aucune information sur un trait particulier.
payments = source_df[payments_features] payments = payments.replace('NaN', 0)
Vérification des données
Lors de la comparaison avec le PDF d'origine sous-jacent à l'ensemble de données, il s'est avéré que les données sont légèrement déformées, car pour toutes les lignes du cadre de données de paiement , le champ total_payments est la somme de toutes les transactions financières de cette personne. Vous pouvez le vérifier comme suit:
errors = payments[payments[payments_features[:-1]].sum(axis='columns') != payments['total_payments']] errors.head()

Nous constatons que BELFER ROBERT et BHATNAGAR SANJAY ont des montants de paiement incorrects.
Vous pouvez corriger cette erreur en déplaçant les données dans les lignes d'erreur vers la gauche ou la droite et en comptant à nouveau la somme de tous les paiements:
import numpy as np shifted_values = payments.loc['BELFER ROBERT', payments_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) payments.loc['BELFER ROBERT', payments_features] = shifted_values shifted_values = payments.loc['BHATNAGAR SANJAY', payments_features[:-1]].values payments.loc['BHATNAGAR SANJAY', payments_features] = np.insert(shifted_values, 0, 0)
Données de stock
stocks = source_df[stock_features] stocks = stocks.replace('NaN', 0)
Effectuez également une vérification de validation dans ce cas:
errors = stocks[stocks[stock_features[:-1]].sum(axis='columns') != stocks['total_stock_value']] errors.head()

Nous corrigerons également l'erreur dans les stocks:
shifted_values = stocks.loc['BELFER ROBERT', stock_features[1:]].values expected_payments = shifted_values.sum() shifted_values = np.append(shifted_values, expected_payments) stocks.loc['BELFER ROBERT', stock_features] = shifted_values shifted_values = stocks.loc['BHATNAGAR SANJAY', stock_features[:-1]].values stocks.loc['BHATNAGAR SANJAY', stock_features] = np.insert(shifted_values, 0, shifted_values[-1])
Correspondance par courriel
Si pour ces finances ou stocks, NaN était équivalent à 0, et cela correspond au résultat final pour chacun de ces groupes, dans le cas du courrier électronique, NaN est plus raisonnable à remplacer par une valeur par défaut. Pour ce faire, vous pouvez utiliser Imputer:
from sklearn.impute import SimpleImputer imp = SimpleImputer()
Dans le même temps, nous considérerons séparément la valeur par défaut pour chaque catégorie (que nous suspections une personne frauduleuse):
target = source_df[target_field] email_data = source_df[email_features] email_data = pd.concat([email_data, target], axis=1) email_data_poi = email_data[email_data[target_field]][email_features] email_data_nonpoi = email_data[email_data[target_field] == False][email_features] email_data_poi[email_features] = imp.fit_transform(email_data_poi) email_data_nonpoi[email_features] = imp.fit_transform(email_data_nonpoi) email_data = email_data_poi.append(email_data_nonpoi)
Jeu de données final après correction:
df = payments.join(stocks) df = df.join(email_data) df = df.astype(float)
Les émissions
À la dernière étape de cette étape, nous supprimerons toutes les valeurs aberrantes, ce qui peut fausser la formation. Dans le même temps, la question se pose toujours: combien de données pouvons-nous supprimer de l'échantillon et ne pas perdre en tant que modèle formé? J'ai suivi les conseils d'un des professeurs du cours ML (Machine Learning) sur l'Udacity - «Retirez 10 et vérifiez à nouveau les émissions».
first_quartile = df.quantile(q=0.25) third_quartile = df.quantile(q=0.75) IQR = third_quartile - first_quartile outliers = df[(df > (third_quartile + 1.5 * IQR)) | (df < (first_quartile - 1.5 * IQR))].count(axis=1) outliers.sort_values(axis=0, ascending=False, inplace=True) outliers = outliers.head(10) outliers
Dans le même temps, nous ne supprimerons pas les enregistrements aberrants et soupçonnés de fraude. La raison en est qu'il n'y a que 18 lignes avec de telles données, et nous ne pouvons pas les sacrifier, car cela peut conduire à un manque d'exemples de formation. En conséquence, nous supprimons uniquement ceux qui ne sont pas soupçonnés de fraude, mais qui ont en même temps un grand nombre de signes par lesquels des émissions sont observées:
target_for_outliers = target.loc[outliers.index] outliers = pd.concat([outliers, target_for_outliers], axis=1) non_poi_outliers = outliers[np.logical_not(outliers.poi)] df.drop(non_poi_outliers.index, inplace=True)
Finaliser
Nous normalisons nos données:
from sklearn.preprocessing import scale df[df.columns] = scale(df)
Permet de cibler la variable cible sur une vue compatible:
target.drop(non_poi_outliers.index, inplace=True) target = target.map({True: 1, False: 0}) target.value_counts()

En conséquence, 18 suspects et 121 personnes qui n'ont pas été soupçonnées.
Sélection des fonctionnalités
Peut-être l'un des points les plus importants avant d'apprendre un modèle est la sélection des fonctionnalités les plus importantes.
Test de multicolinéarité
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline sns.set(style="whitegrid") corr = df.corr() * 100 # Select upper triangle of correlation matrix mask = np.zeros_like(corr, dtype=np.bool) mask[np.triu_indices_from(mask)] = True # Set up the matplotlib figure f, ax = plt.subplots(figsize=(15, 11)) # Generate a custom diverging colormap cmap = sns.diverging_palette(220, 10) # Draw the heatmap with the mask and correct aspect ratio sns.heatmap(corr, mask=mask, cmap=cmap, center=0, linewidths=1, cbar_kws={"shrink": .7}, annot=True, fmt=".2f")
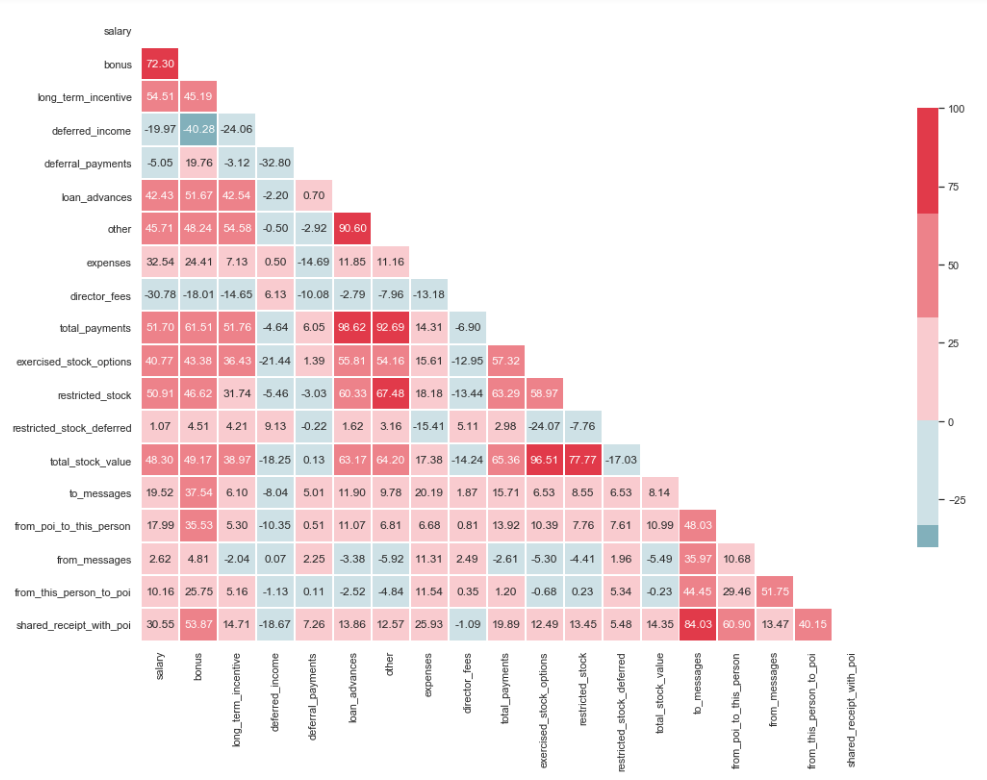
Comme vous pouvez le voir sur l'image, nous avons une relation prononcée entre «loan_advanced» et «total_payments», ainsi qu'entre «total_stock_value» et «restricted_stock». Comme mentionné précédemment, «total_payments» et «total_stock_value» sont simplement le résultat de l'addition de tous les indicateurs d'un groupe particulier. Par conséquent, ils peuvent être supprimés:
df.drop(columns=['total_payments', 'total_stock_value'], inplace=True)
Créer de nouvelles caractéristiques
Il y a également l'hypothèse que les suspects ont écrit plus souvent aux complices qu'aux employés qui n'y étaient pas impliqués. Et par conséquent, la proportion de ces messages devrait être supérieure à la proportion de messages adressés aux employés ordinaires. Sur la base de cette déclaration, vous pouvez créer de nouveaux signes qui reflètent le pourcentage d'entrées / sorties liées aux suspects:
df['ratio_of_poi_mail'] = df['from_poi_to_this_person']/df['to_messages'] df['ratio_of_mail_to_poi'] = df['from_this_person_to_poi']/df['from_messages']
Éliminer les signes inutiles
Dans la boîte à outils des personnes associées au ML, il existe de nombreux excellents outils pour sélectionner les fonctionnalités les plus importantes (SelectKBest, SelectPercentile, VarianceThreshold, etc.). Dans ce cas, RFECV sera utilisé, car il comprend une validation croisée, qui vous permet de calculer les fonctionnalités les plus importantes et de les vérifier sur tous les sous-ensembles de l'échantillon:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(df, target, test_size=0.2, random_state=42)
from sklearn.feature_selection import RFECV from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(random_state=42) rfecv = RFECV(estimator=forest, cv=5, scoring='accuracy') rfecv = rfecv.fit(X_train, y_train) plt.figure() plt.xlabel("Number of features selected") plt.ylabel("Cross validation score of number of selected features") plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_, '--o') indices = rfecv.get_support() columns = X_train.columns[indices] print('The most important columns are {}'.format(','.join(columns)))
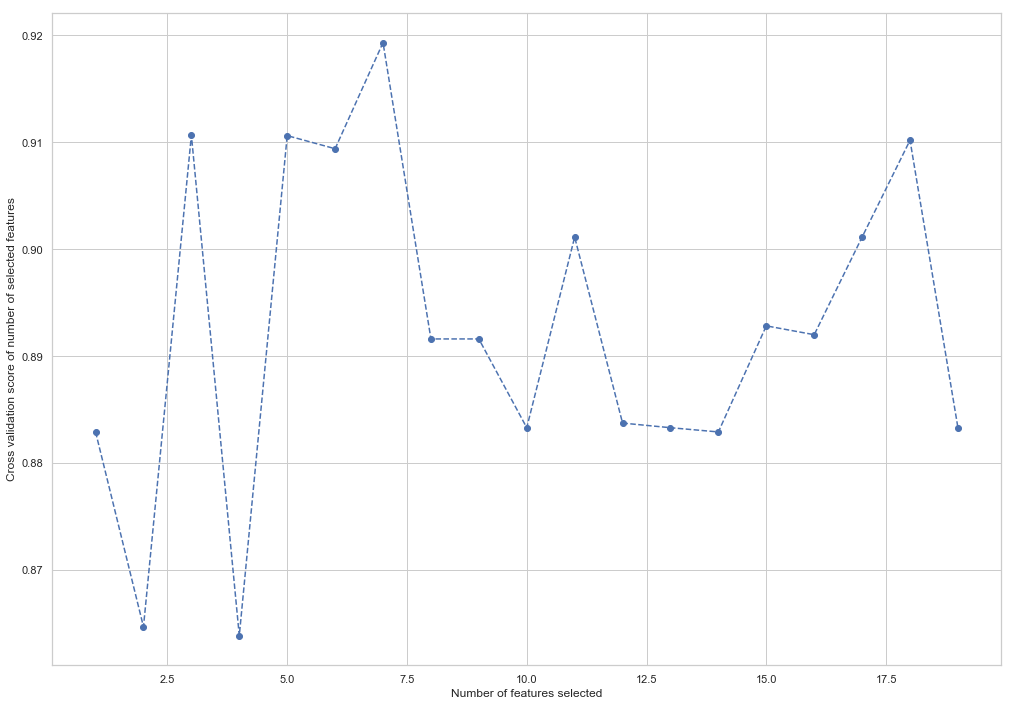
Comme vous pouvez le voir, RandomForestClassifier a calculé que seuls 7 des 18 attributs comptent. L'utilisation du reste entraîne une diminution de la précision du modèle.
The most important columns are bonus, deferred_income, other, exercised_stock_options, shared_receipt_with_poi, ratio_of_poi_mail, ratio_of_mail_to_poi
Ces 7 fonctionnalités seront utilisées à l'avenir afin de simplifier le modèle et de réduire les risques de reconversion:
- bonus
- revenu_différé
- autre
- exercised_stock_options
- shared_receipt_with_poi
- ratio_of_poi_mail
- ratio_of_mail_to_poi
Modifiez la structure de la formation et testez les échantillons pour la formation future du modèle:
X_train = X_train[columns] X_test = X_test[columns]
Ceci est la fin de la première partie décrivant l'utilisation du jeu de données Enron comme exemple de tâche de classification en ML. Basé sur le matériel du cours Introduction à l'apprentissage automatique sur l'Udacity. Il y a aussi un cahier python reflétant toute la séquence d'actions.
La deuxième partie est ici